简介
本文依赖于华中科技大学操作系统PKE实验代码,为lab1_challenge1、lab2_challenge1、lab3_challenge1的实验解析。
lab1_challenge1
实验目的
用户程序源代码user/app_print_backtrace.c如下,其中,print_backtrace()函数会触发系统调用,该系统调用的内核处理函数需要手动补全。
1. #include "user_lib.h"
2. #include "util/types.h"
3.
4. void f8() {
5. // print_backtrace(int n) 是一个系统调用,需要我们自己书写
6. print_backtrace(100);
7. }
8. void f7() { f8(); }
9. void f6() { f7(); }
10. void f5() { f6(); }
11. void f4() { f5(); }
12. void f3() { f4(); }
13. void f2() { f3(); }
14. void f1() { f2(); }
15.
16. int main(void) {
17. printu("back trace the user app in the following:\n");
18. f1();
19. exit(0);
20. return 0;
21. }
实验一挑战实验一需要完成一个系统调用的实现,即打印用户调用栈。在明确并完善系统调用路径的基础上,需要掌握elf文件中.symtab和.strtab等节的知识。在进入系统调用陷入内核之后,需要能够通过掌握的elf文件结果找到用户调用栈所对应的函数的函数名称,并递归打印出来。
实验内容
在syscall.c文件中的do_syscall中增加一个case,然后补全一些细节即可完善该函数的系统调用。由于需要使用elf文件中的符号表等内容并结合系统调用栈打印被调用函数的名称,所以内核系统调用函数sys_user_print_backtrace需要依赖elf.c文件中elf_user_print_backtrace函数来完成。
1. ssize_t sys_user_print_backtrace(uint64 recursion_depth) {
2. // TODO: implement to satisfy the experimental requirements
3. // how to get the user stack information in tht kernel?
4. // sprint("shstrndx is %d", current->trapframe);
5. // elf_user_print_backtrace is defined in elf.c
6. elf_user_print_backtrace(recursion_depth);
7. return 0;
8. }
elf_user_print_backtrace函数会对elf文件进行相关操作,首先需要对elf格式文件有一些了解。
elf文件主要是由两个视角组成,一个是链接时的视角,还有一个执行时的视角,两个视角组成不同的两种组成。
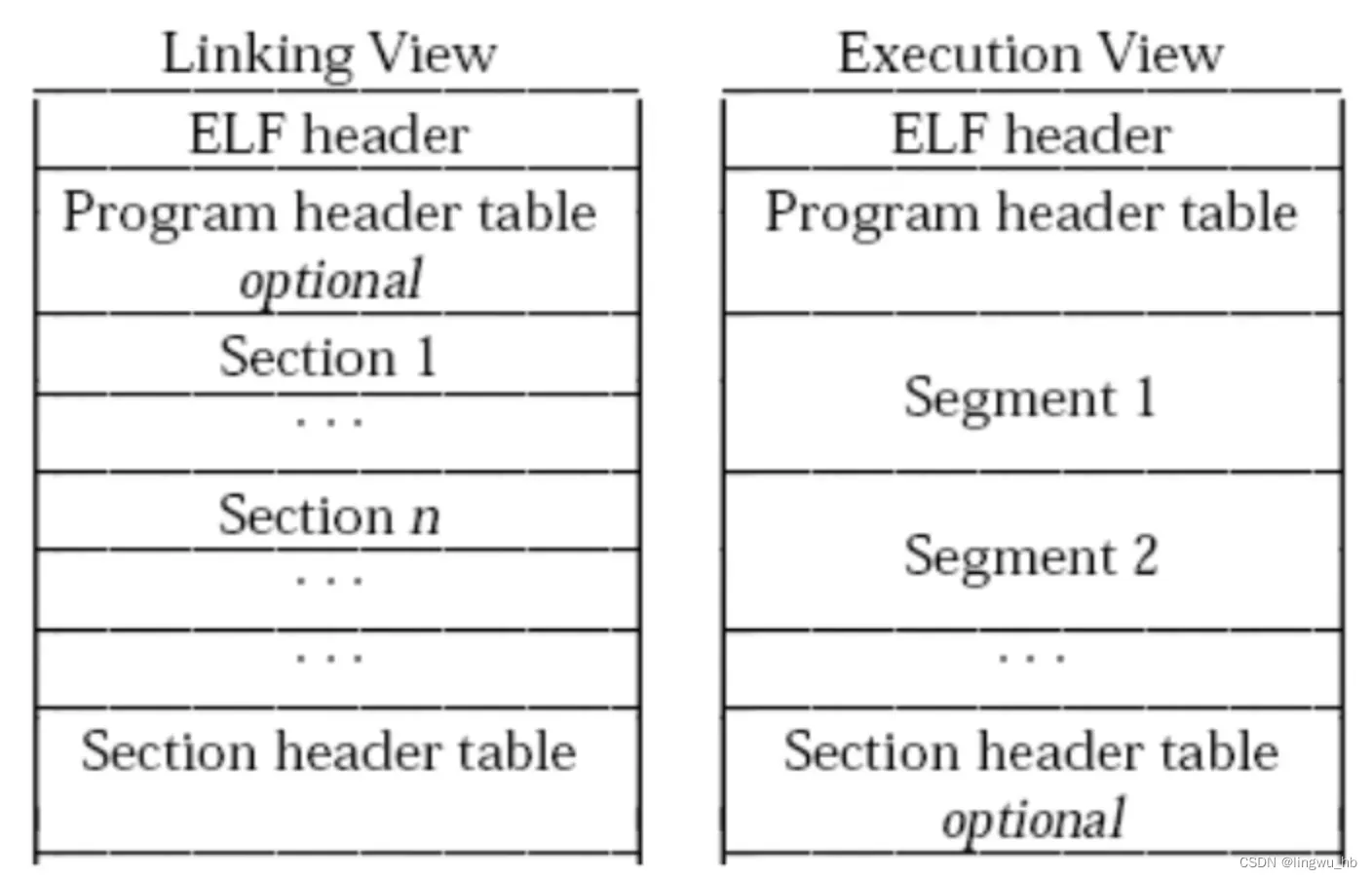
其中有三个非常关键的结构,一个是总结全部文件内容的ELF头部、节头部表以及程序头部表。节头部表是一个elf_sect_header类型的数组,数组中每一项保存了对应节的具体内容。程序头部表是一个elf_prog_header类型的数组,数组中每一项保存了对应段的具体内容。(elf_sect_header和elf_prog_header的具体结构在下文给出)
在链接的时候,文件主题内容被组织为多个相邻的节的形式,而在执行的时候,则被组织为多个相邻的段的形式。
首先是总的elf头部信息
1. // elf header structure
2. typedef struct elf_header_t {
3. uint32 magic;
4. uint8 elf[12];
5. uint16 type; /* Object file type */
6. uint16 machine; /* Architecture */
7. uint32 version; /* Object file version */
8. uint64 entry; /* Entry point virtual address */
9. uint64 phoff; /* Program header table file offset */
10. uint64 shoff; /* Section header table file offset */
11. uint32 flags; /* Processor-specific flags */
12. uint16 ehsize; /* ELF header size in bytes */
13. uint16 phentsize; /* Program header table entry size */
14. uint16 phnum; /* Program header table entry count */
15. uint16 shentsize; /* Section header table entry size */
16. uint16 shnum; /* Section header table entry count */
17. uint16 shstrndx; /* Section header string table index */
18. } elf_header;
在本实验中,主要有以下几个字段值比较重要。
- shoff、shentsize、shnum:描述节区头表的偏移、大小、数量(有多少个节首部)。
- shstrndx:这一项描述的是字符串表在节区头表中的索引,值17表示的是节区头表中第17项是字符串表(String Table)。在本实验中shstrndx值为17。
elf_prog_header类型表示一个段头表项中的具体内容,在实验代码elf.h中给出,如下所示:
1. // Program segment header.
2. typedef struct elf_prog_header_t {
3. uint32 type; /* Segment type */
4. uint32 flags; /* Segment flags */
5. uint64 off; /* Segment file offset */
6. uint64 vaddr; /* Segment virtual address */
7. uint64 paddr; /* Segment physical address */
8. uint64 filesz; /* Segment size in file */
9. uint64 memsz; /* Segment size in memory */
10. uint64 align; /* Segment alignment */
11. } elf_prog_header;
本实验中不太需要使用到该数据结构,所以不在此详细解释。
elf_sect_header类型表示了一个节头表项中的具体内容,在实验代码中并没有给出,需要我们自己定义如下:
1. // elf section header, in total 64 bytes
2. typedef struct elf_sect_header_t{
3. uint32 name;
4. uint32 type;
5. uint64 flags;
6. uint64 addr; /*the first byte of the section.*/
7. uint64 offset;/*此成员的取值给出节区的第一个字节与文件头之间的偏移*/
8. uint64 size;
9. uint32 link;
10. uint32 info;
11. uint64 addralign;
12. uint64 entsize;
13. } elf_sect_header;
每一个elf_sect_header值解释了该节的名称、类型、大小以及在整个ELF文件中的字节偏移位置等等。一个程序中有很多个节,在本实验中,我们需要重点关注.symtab和.strtab节以及.shstrtab节。
在完善elf.c中的函数之前,我们首先需要知道elf文件是如何保存各种符号的。(例如:.symtab这些节的名称以及各种函数和变量的名称)
在每一个elf_sect_header中都有一个uint32类型的name字段,该字段其实是一个数值,表示该节的名称的地址的偏移。既然是偏移,那具体相对于什么进行的偏移呢?答案就是elf头表中的shstrndx值所在的节的地址。通过shstrndx可以知道.shstrtab节的节头,然后获取到该节的具体内容——也就是所有节的名称保存的地方。
.shstrtab节中保存着以’\0’分割的所有节的名称的字符串。我们尝试测试打印出所有节的名称。某一个节的名称的起始地址计算方式如下:.shstrtab节头表.offset+该节的节头表.name。获取到起始地址之后,逐个字节往下获取,知道’\0’为止。具体代码如下:
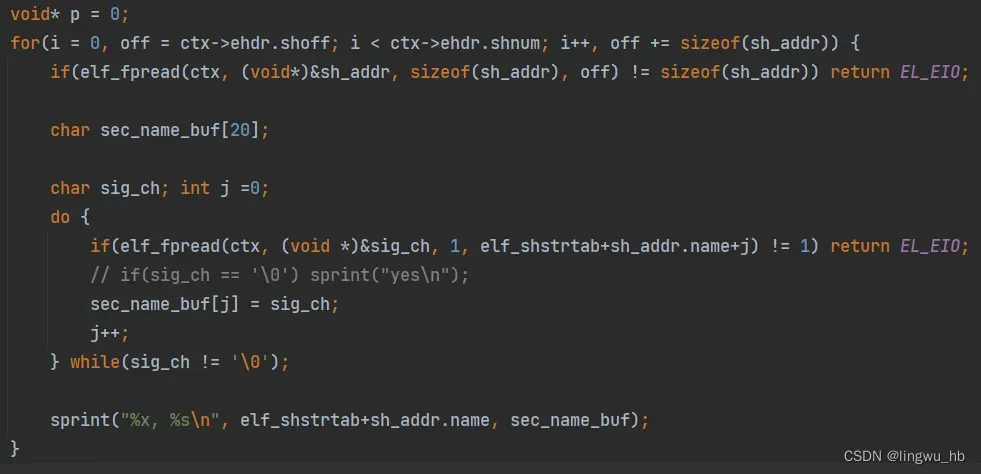
打印结果如下所示:
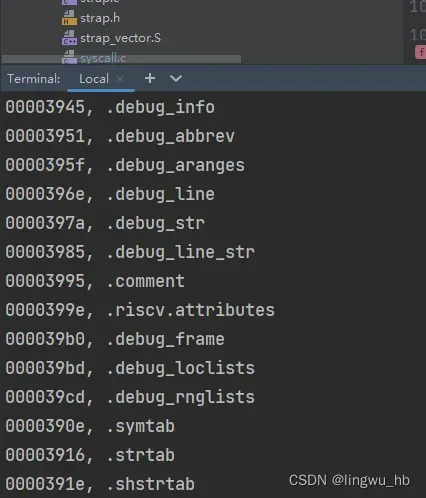
打印完.shstrtab节中的所有内容之后,我们发现一个问题,在.shstrtab节中只有各个节的名称,并没有我们实验需要的函数名称呀?那函数名称保存在哪里呢?就是需要提到我们上面说的.strtab节了,除了节名称外的所有符号都被保存到了.strtab节,该节和.shstrtab类似,也是保存着以’\0’分割的字符串,也就是我们需要的所有符号的名称。
对于每个节的节名称的地址,我们是通过节头表的name字段+.shstrtab节头表的offset字段进行获取的。现在我们需要找每个符号的地址,通过类比可以知道,我们需要符号的name字段+.strtab节头表的offset字段。但是我们此时只知道.strtab节头表的offset字段,并不知道符号的name字段。这个时候就需要我们上面提到的另外一个重要的节.symtab登场了。
.symtab保存了各个符号的基本信息,其中就有我们需要的name字段。.symtab节中的内容被组织为elf_sym结构的数组。Elf_sym结构实验代码并没有给出,需要我们查阅资料后自定义如下:
1. typedef struct elf_sym {
2. uint32 st_name; // symbol name, the index of string table
3. uint64 st_value; // symbol value, the virtual address
4. uint32 st_size;
5. uint8 st_info;
6. uint8 st_other;
7. uint16 st_shndx; // 符号相关节的节索引
8. } elf_sym;
在本实验中,我们只需要关注其中两个字段的值的含义即可。
- St_name:符号的名称,在.strtab节中的偏移地址
- St_value:符号的值,elf文件加载完毕后该给符号分配的虚拟地址
- St_size:符号的大小,如果该符号是函数名,则表示该函数所占的空间大小。在后续判断返回地址处于哪个函数中有很大作用。
了解完上述信息后,我们就可以很顺利得找到所有符号的虚拟地址以及对应的具体名称了。(打印方式与上文提到的打印节名称类似,在此略去)但是我们还需要知道我们需要打印的是哪个符号,也就是说,我们需要获得符号的虚拟地址。这要求我们熟悉函数调用过程以及调用过程中发生的栈帧变化。
在Riscv中,我们把栈的低地址端称作栈顶,相应的,把栈的高地址端称作栈底。在函数调用过程中,主要有以下几个重要的寄存器在发挥作用:pc、sp、fp(s0)、ra。它们的作用如下:
-
Pc:指示下一条指令的地址
-
Sp:指示当前处理机状态下对应的栈顶位置。一般在给ra和s0赋值时使用
-
Fp(s0):在发生函数调用时被赋值为sp的内容并压栈。在函数内部需要用到某一个数据时,一般使用s0进行指示其位置
-
Ra:函数的返回地址被保存在ra寄存器中
一个具体的函数栈帧示意图如下所示:
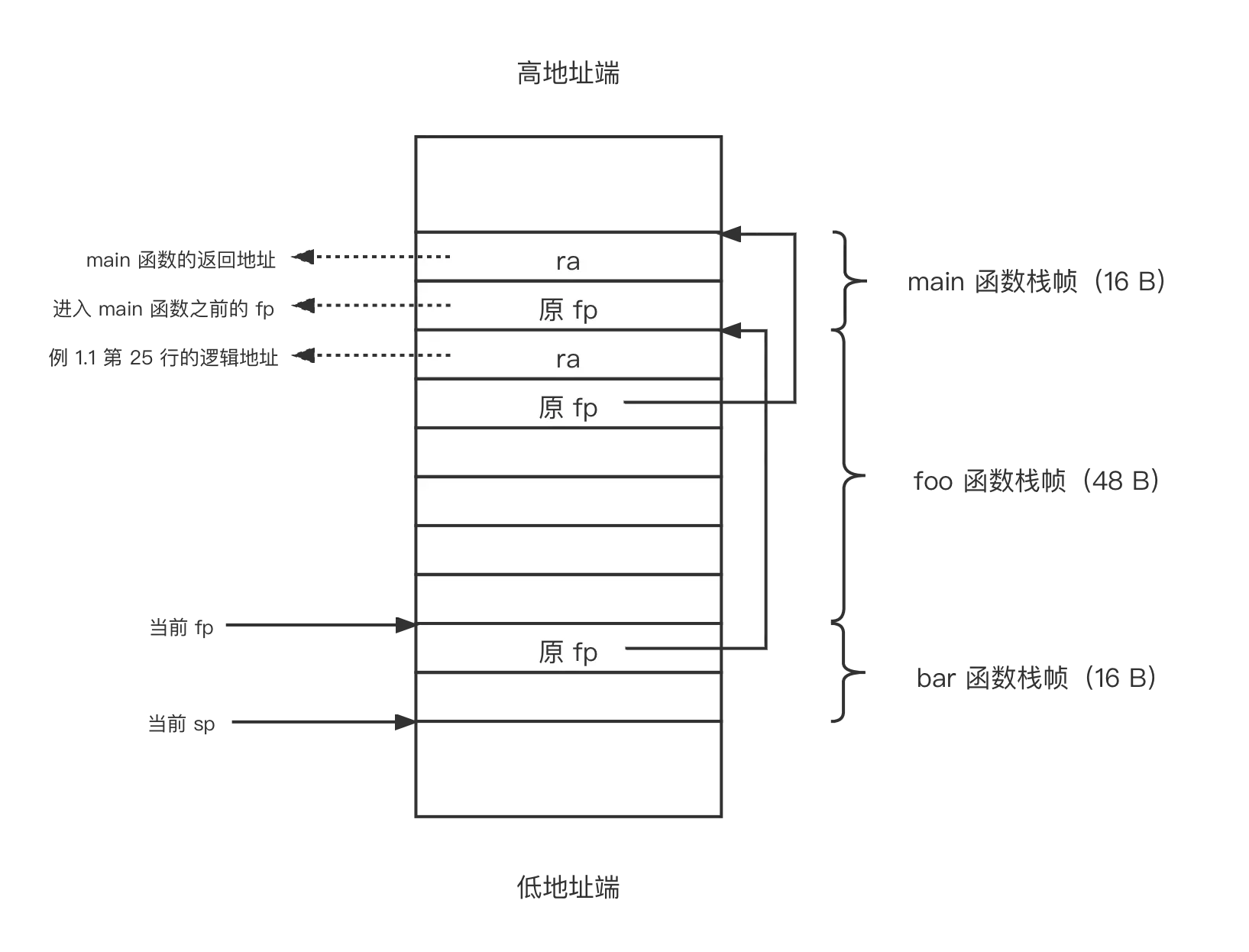
为了不修改寄存器中的值,我们用uint64类型的user_sp和user_s0以及user_ra分别表示上述三个寄存器的值,在函数回溯的过程中,需要做如下处理:
1. user_sp = user_s0;
2. user_s0 = *(uint64*)(user_s0-16);
3. user_ra = *(uint64*)(user_s0-8);
经过上述处理后,相当于退出当前函数,回到调用该函数的上一层函数。
最后,我们可以通过user_ra中的值(函数返回地址)判断当前在那个函数中,从而打印出该函数的名称,完成实验。具体操作为:回地址在函数起始地址到函数结束地址之间,说明就是该函数在被调用,直接输出该函数的符号名即可!代码如下:(symtab_entry为elf_sym类型的值,即符号的具体信息)
1. if(user_ra > symtab_entry.st_value && user_ra < symtab_entry.st_value + symtab_entry.st_size) {
2. sprint("%s\n", sym_name_buf);
3. }
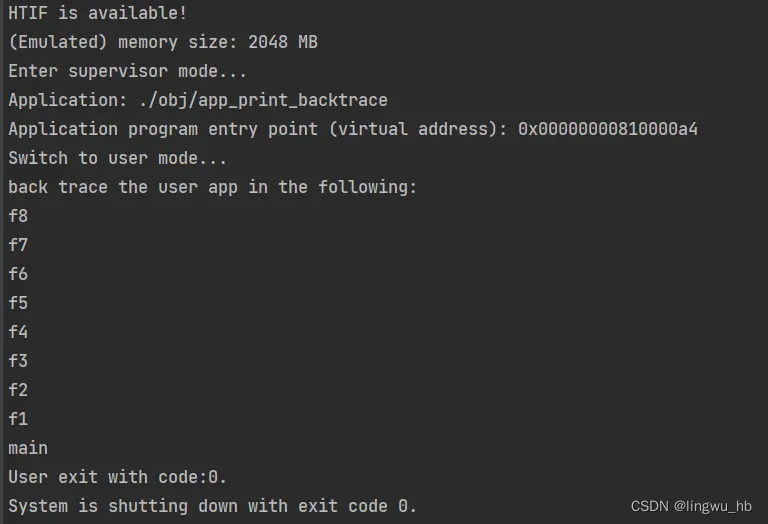
至此,完成了lab1_challenge1的全部实验流程,最终编译,运行的程序输出如下:
lab2_challenge1
实验目的
用户源代码user/app_sum_sequence.c如下,其中的sum_sequence函数递归到一定深度后,会触发数组访问越界异常,需要对该异常进行处理。
1. #include "user_lib.h"
2. #include "util/types.h"
3.
4. //
5. // compute the summation of an arithmetic sequence. for a given "n", compute
6. // result = n + (n-1) + (n-2) + ... + 0
7. // sum_sequence() calls itself recursively till 0. The recursive call, however,
8. // may consume more memory (from stack) than a physical 4KB page, leading to a page fault.
9. // PKE kernel needs to improved to handle such page fault by expanding the stack.
10. //
11. uint64 sum_sequence(uint64 n, int *p) {
12. if (n == 0)
13. return 0;
14. else
15. return *p=sum_sequence( n-1, p+1 ) + n;
16. }
17.
18. int main(void) {
19. // FIRST, we need a large enough "n" to trigger pagefaults in the user stack
20. uint64 n = 1024;
21.
22. // alloc a page size array(int) to store the result of every step
23. // the max limit of the number is 4kB/4 = 1024
24.
25. // SECOND, we use array out of bound to trigger pagefaults in an invalid address
26. int *ans = (int *)naive_malloc();
27.
28. printu("Summation of an arithmetic sequence from 0 to %ld is: %ld \n", n, sum_sequence(n+1, ans) );
29.
30. exit(0);
31. }
实验二挑战实验一需要补充完成对复杂缺页异常情况的处理。程序思路基本同lab2_3一致,对给定n计算0到n的和,但要求将每一步递归的结果保存在数组ans中。创建数组时,我们使用了当前的malloc函数申请了一个页面(4KB)的大小,对应可以存储的个数上限为1024。在函数调用时,我们试图计算1025求和,首先由于n足够大,所以在函数递归执行时会触发用户栈的缺页,你需要对其进行正确处理,确保程序正确运行;其次,1025在最后一次计算时会访问数组越界地址,由于该处虚拟地址尚未有对应的物理地址映射,因此属于非法地址的访问,这是不被允许的,对于这种缺页异常,应该提示用户并退出程序执行。
实验内容
根据lab2_3,我们知道,正常的缺页异常是发生在USER_STACK_TOP开始的后续用户栈部分,此时我们需要分配新的页面提供给程序使用。但是程序中使用naïve_malloc()分配的内存为g_ufree_page开始的内存部分。Naïve_malloc()的system call 最终会调用syscall.c中的sys_user_allocate_page函数,从该函数可以看出,该函数分配的内存从g_ufree_page部分开始。
1. uint64 sys_user_allocate_page() {
2. void* pa = alloc_page();
3. uint64 va = g_ufree_page;
4. g_ufree_page += PGSIZE;
5. user_vm_map((pagetable_t)current->pagetable, va, PGSIZE, (uint64)pa,
6. prot_to_type(PROT_WRITE | PROT_READ, 1));
7.
8. return va;
9. }
考虑到上述信息,那么我们可以在进行缺页异常处理的时候判断引起缺页异常的地址所在位置,如果该地址在naïve_malloc函数分配的空间部分,那么这部分地址空间理应是禁止访问的,所以程序输出错误信息然后退出即可。具体的处理函数如下:
1. void handle_user_page_fault(uint64 mcause, uint64 sepc, uint64 stval) {
2. sprint("handle_page_fault: %lx\n", stval);
3. switch (mcause) {
4. case CAUSE_STORE_PAGE_FAULT: {
5. // TODO (lab2_3): implement the operations that solve the page fault to
6. // dynamically increase application stack.
7. // hint: first allocate a new physical page, and then, maps the new page to the
8. // virtual address that causes the page fault.
9. // panic( "You need to implement the operations that actually handle the page fault in lab2_3.\n" );
10.
11. // check whether the exception is caused by the pagefault in heap memory
12. if(stval >= g_ufree_page && stval < g_ufree_page+PGSIZE) {
13. sprint("this address is not available!\n");
14. shutdown(-1);
15. break;
16. }
17.
18. int n = 1;
19. while (stval < USER_STACK_TOP - n * PGSIZE) n++;
20.
21. uint64
22. new_user_stack = (uint64)
23. alloc_page();
24.
25. user_vm_map(current->pagetable, USER_STACK_TOP - n * PGSIZE, PGSIZE, new_user_stack,
26. prot_to_type(PROT_WRITE | PROT_READ, 1));
27.
28. // niubility approach
29. // 更加高效的内存对齐的手段
30. // user_vm_map(current->pagetable, stval-stval%PGSIZE, PGSIZE, new_user_stack,
31. // prot_to_type(PROT_WRITE | PROT_READ, 1));
32. break;
33. }
34. default:
35. sprint("unknown page fault.\n");
36. break;
37. }
38. }
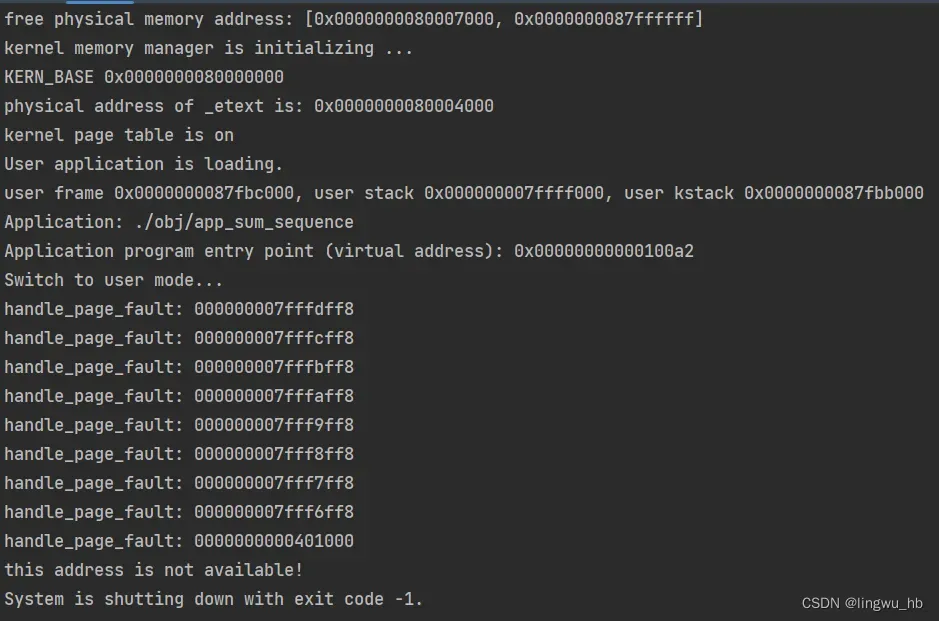
至此,完成了lab2_challenge1的全部实验流程,最终编译,运行的程序输出如下:
lab3_challenge1
实验目的
用户程序源代码user/app_wait.c如下:
1. #include "user/user_lib.h"
2. #include "util/types.h"
3.
4. int flag;
5. int main(void) {
6. flag = 0;
7. int pid = fork();
8. if (pid == 0) {
9. flag = 1;
10. pid = fork();
11. if (pid == 0) {
12. flag = 2;
13. printu("Grandchild process end, flag = %d.\n", flag);
14. } else {
15. wait(pid);
16. printu("Child process end, flag = %d.\n", flag);
17. }
18. } else {
19. wait(-1);
20. printu("Parent process end, flag = %d.\n", flag);
21. }
22. exit(0);
23. return 0;
24. }
实验三挑战实验一需要实现进程阻塞的功能。在lab3的基础实验中,并没有涉及到进程的阻塞状态,lab3_challengel1中父程序调用fork()函数创建子程序,然后子程序再调用fork()函数创建子函数,在他们的子函数执行完成之前,对应的父程序需要进入等待状态。
实验内容
首先我们需要将do_fork()函数补充完成,在lab3_1中只实现了代码段的复制,我们需要继续实现数据段的复制并保证fork后父子进行的数据段相互独立。因此,数据段的内容就需要针对每个进程去申请空间拷贝而不是像代码段一样进行简单的复制操作。Do_fork()函数补充内容具体如下:
1. case DATA_SEGMENT:{
2. void* child_pa = alloc_page();
3. if(child_pa == 0) panic("malloc mem alloc failed");
4. uint64 parent_pa = lookup_pa(parent->pagetable, parent->mapped_info[i].va);
5. // memcpy_s(child_pa, PGSIZE, (void*)parent_pa, PGSIZE);
6. memcpy(child_pa, (void*)parent_pa, PGSIZE);
7.
8. user_vm_map(child->pagetable, parent->mapped_info[i].va, PGSIZE, (uint64)child_pa,
9. prot_to_type(PROT_READ | PROT_WRITE, 1));
10.
11. // after mapping, register the vm region (do not delete codes below!)
12. child->mapped_info[child->total_mapped_region].va = parent->mapped_info[i].va;
13. child->mapped_info[child->total_mapped_region].npages =
14. parent->mapped_info[i].npages;
15. child->mapped_info[child->total_mapped_region].seg_type = DATA_SEGMENT;
16. child->total_mapped_region++;
17.
18. break;
然后我们需要补充完成对wait()函数的系统调用流程,然后在syscall.c中完成系统调用函数的实现,wait()函数接受一个参数pid:
-
当pid为-1时,父进程等待任意一个子进程退出即返回子进程的pid;
-
当pid大于0时,父进程等待进程号为pid的子进程退出即返回子进程的pid;
-
当pid不合法或者pid大于0且pid对应的进程不是当前进程的子进程,返回-1。
Wait()函数最终交付给sys_user_wait()函数进行处理,该函数具体代码如下:
1. ssize_t sys_user_wait(int pid) {
2. int flag = 1;
3. // prohibited format
4. if(pid == 0 || pid < -1 || pid >= NPROC) flag = 0;
5. if(pid > 0 && !is_parent(current->pid, pid)) flag = 0;
6. if(!flag) return -1;
7.
8. int exit_pid = 0;
9. if(pid == -1) {
10. if((exit_pid = one_child_exit(current->pid)) == 0) {
11. current->status = BLOCKED;
12. schedule();
13. }
14. } else {
15. exit_pid = pid;
16. if(!is_exit(exit_pid)) {
17. current->status = BLOCKED;
18. schedule();
19. }
20. }
21.
22. return exit_pid;
23. }
其中的is_parent()、one_child_exit()、is_exit()为process模块中对外提供的函数,功能分别为:判断两个进程是否为父子关系、判断该进程是否有子进程退出并返回退出的子进程进程号、该进程是否退出。
其中,当进程的状态被设置为BLOCKED后,该进程就进入等待状态。然后当某一个进程执行完毕退出的时候,我们在该程序退出前进行检查,检查该程序是否有对应的父程序在阻塞,如果有,将该进程转为就绪态。在exit()函数的对应部分进行处理,然后将对应的父进程的pid保存在a0寄存器中进行返回即可。具体的sys_user_exit()函数的实现如下:
1. ssize_t sys_user_exit(uint64 code) {
2. sprint("User exit with code:%d.\n", code);
3. // make current->parent READY added @lab3_challenge1
4. if(current->parent) {
5. int parent_pid = current->parent->pid;
6. if(procs[parent_pid].status == BLOCKED) {
7. procs[parent_pid].status = READY;
8. // return the child's pid
9. procs[parent_pid].trapframe->regs.a0 = current->pid;
10. insert_to_ready_queue(&procs[parent_pid]);
11. }
12. }
13. // reclaim the current process, and reschedule. added @lab3_1
14. free_process( current );
15. schedule();
16. return 0;
17. }
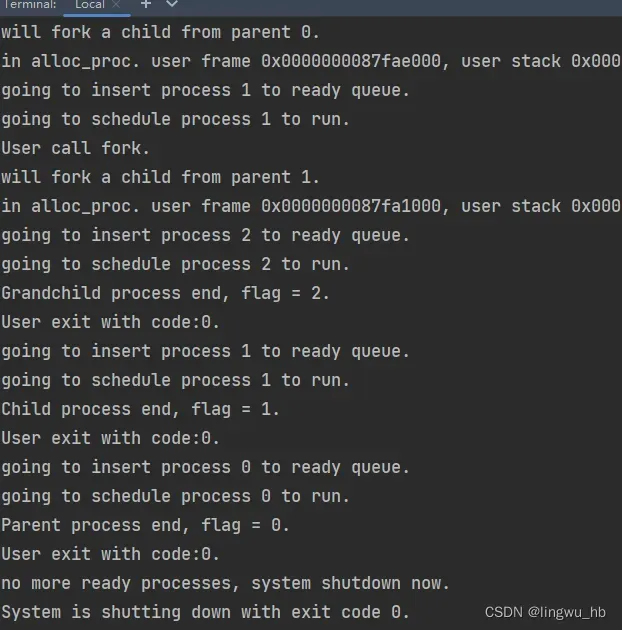
至此,完成了lab3_challenge1的全部实验流程,最终编译,运行的程序输出如下:
版权声明:本文为博主作者:lingwu_hb原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/lingwu_hb/article/details/128594785