首先,一个比较广泛的模型下载地址为:Civitai Models | Discover Free Stable Diffusion Models
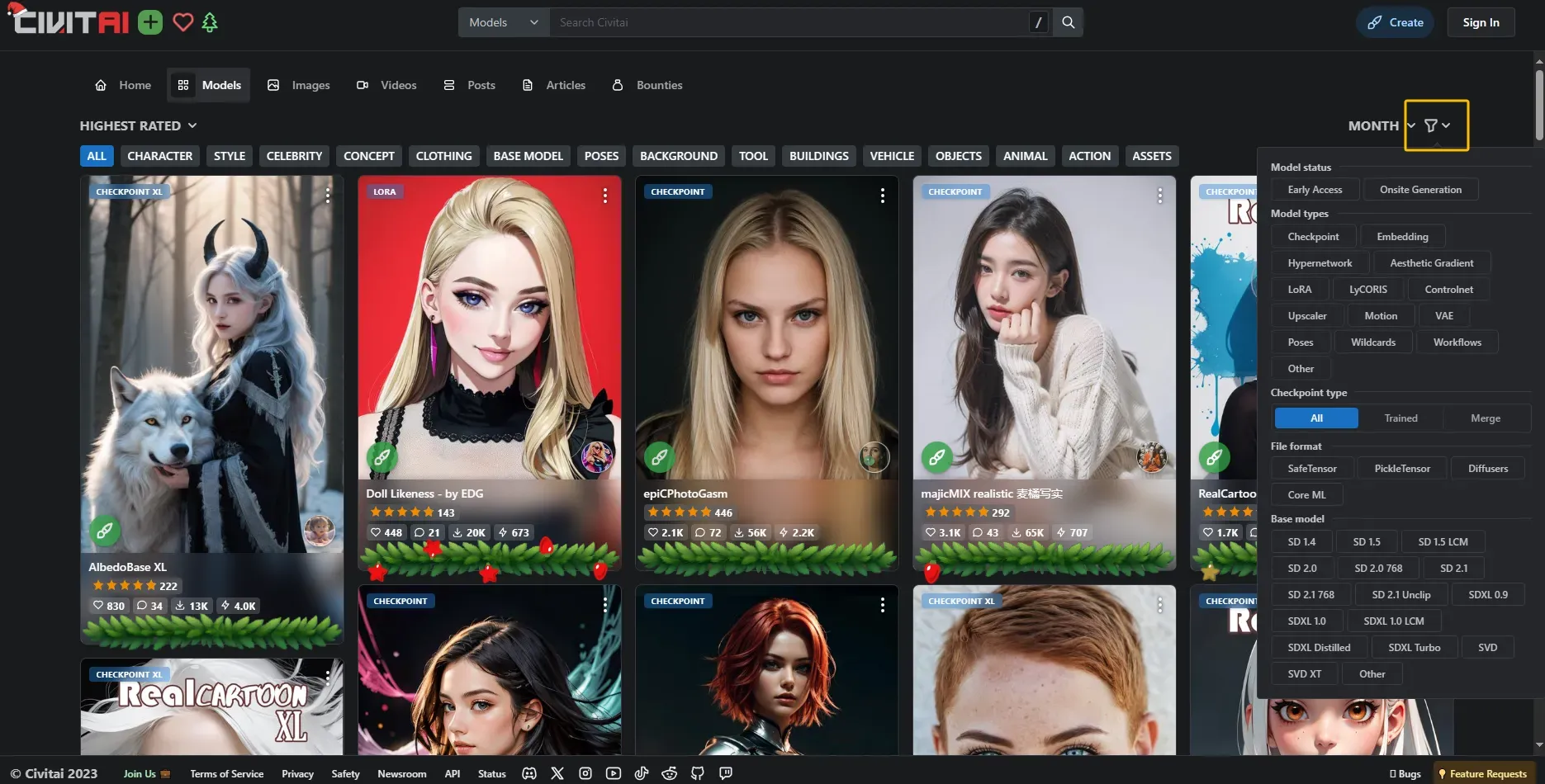
黄框是一些过滤器,比如checkpoints可以理解为比如把1.5版本的SD模型拷贝一份后交叉识别新的画风或场景后得到的模型,可以单独拿出来使用。 Hypernetwork和lora在特定场景下都非常好用。我们以majicMIX realistic 麦橘写实模型为例子,点开:
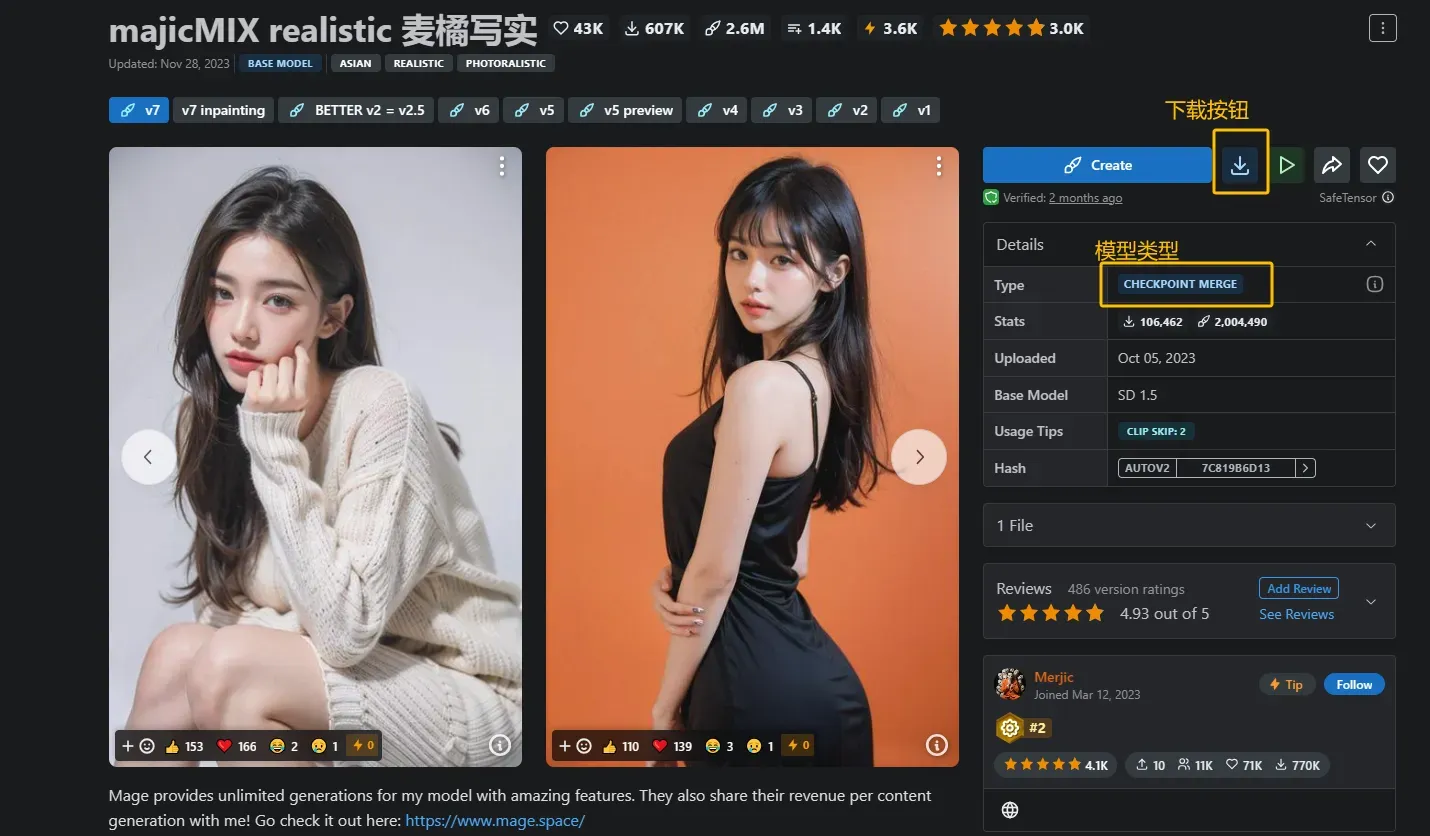
点开一张照片,我们能看到生成这张照片的提示词和负提示词以及cfg scale,甚至往下拉还有推荐的优质参数和评论区。下载好模型后,将其放到stablediffusion-webui —> models —> Stable-diffusion 目录下。随后在webUI中点击大模型的下拉框,即可切换(需要等待一定时间)。
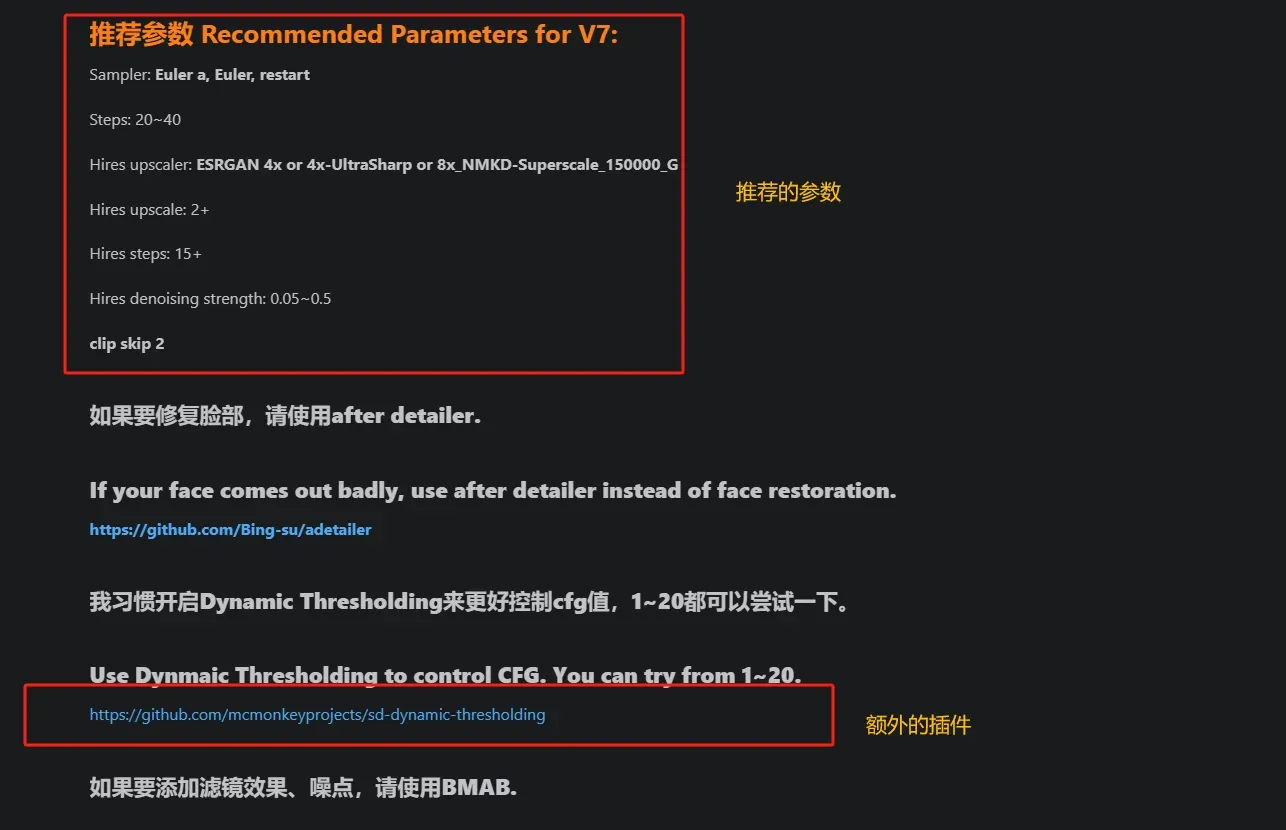
实际使用中,我们发现生成的和网页给我们的感觉差距是非常大的,其中有很重要的一点是没有阅读模型的说明书。 其在模型页面下方,
LoRA训练
环境:秋叶大佬的安装包 LoRA WebUI 提取码:p8uy。
数据集:图片和标签。如何做:
- 打开Web UI。点击训练,再点击图像预处理:复制存放图像的文件夹到源目录,复制标签和预处理后的图像需要存放的文件夹到目标目录。宽度高度根据自己的需要去设置,这代表着预处理后的图像大小。
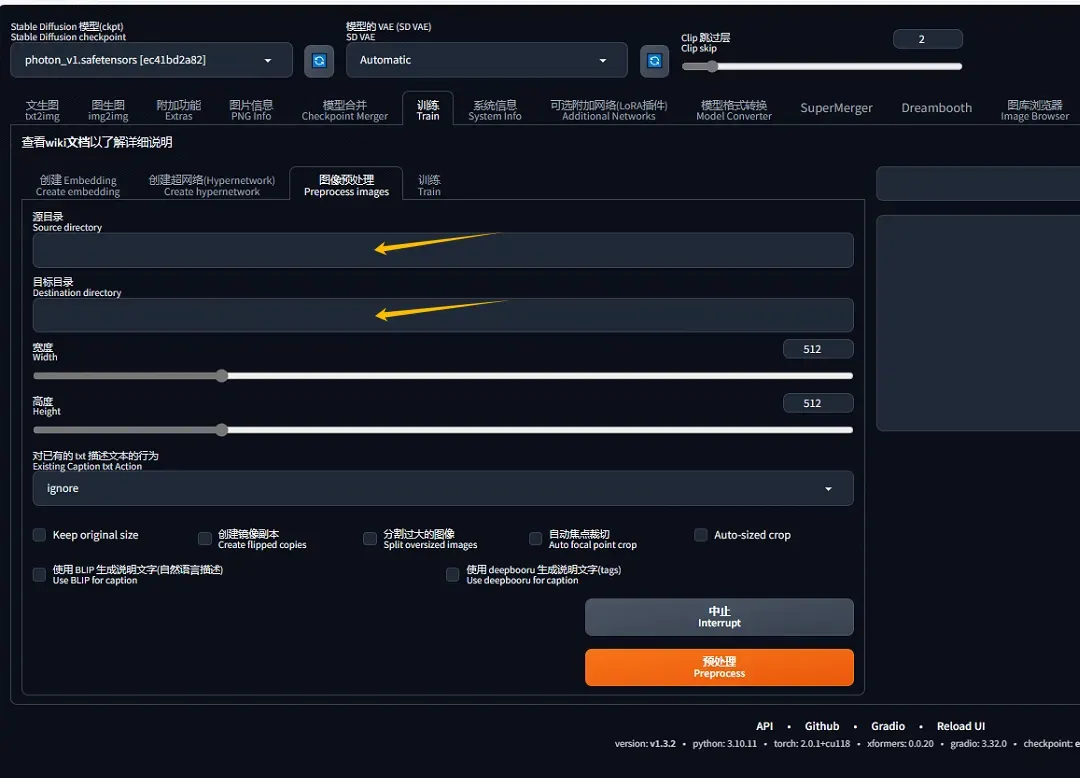
- 勾选使用deepbooru生成说明文字tag。点击预处理,自动处理完成后即可得到标签文件。
- 对标签进行修改。由于标签是deepbooru图生文模型生成的,不一定那么准确。因此需要去对生成的标签做处理。这里先不讲如何打Tag,直接进行下一步。
- 进入秋叶大佬的炼丹器,点击LORA训练-新手(本节只过新手场)。添加底模路径(再SD的模型文件夹中添加一个大模型即可。)
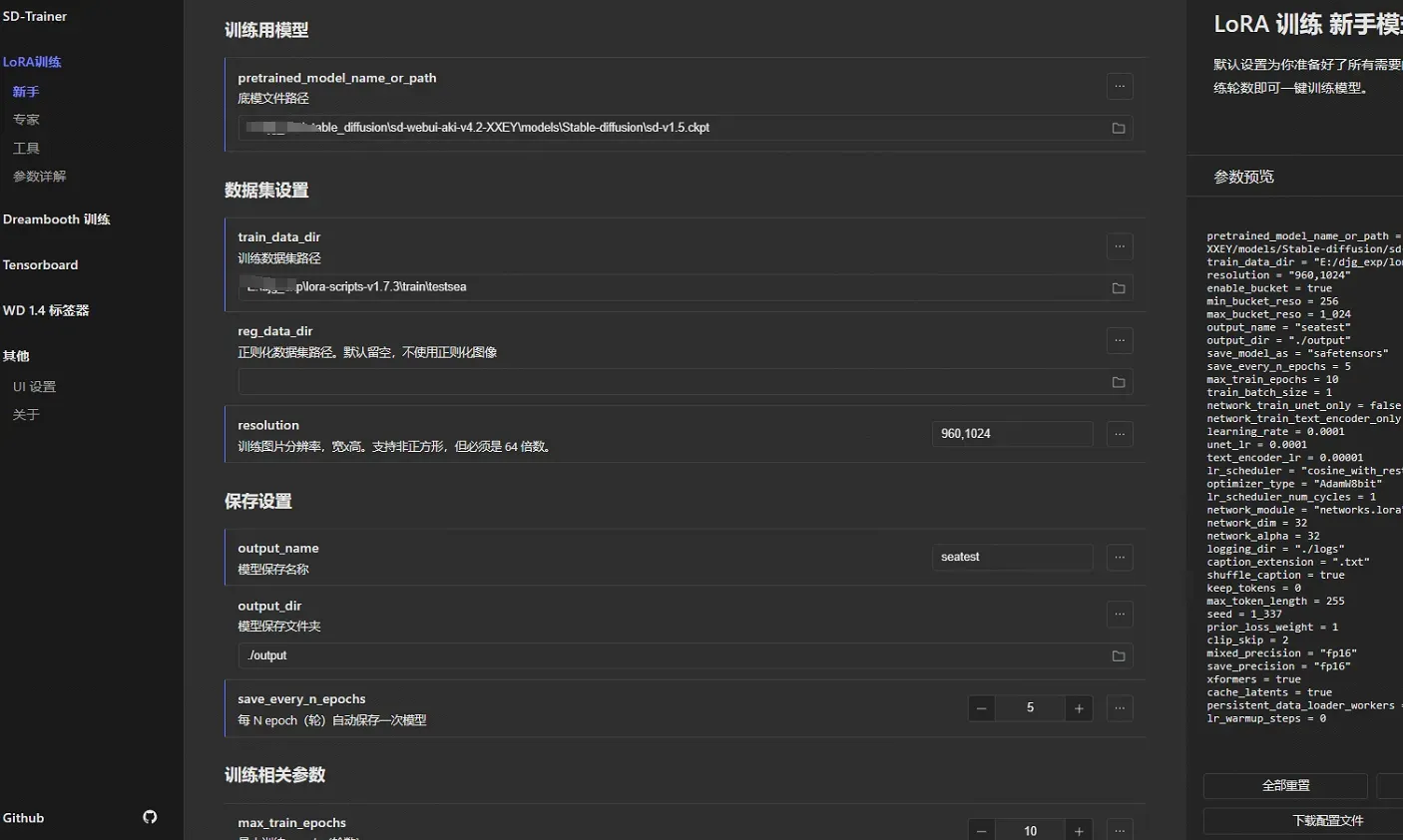
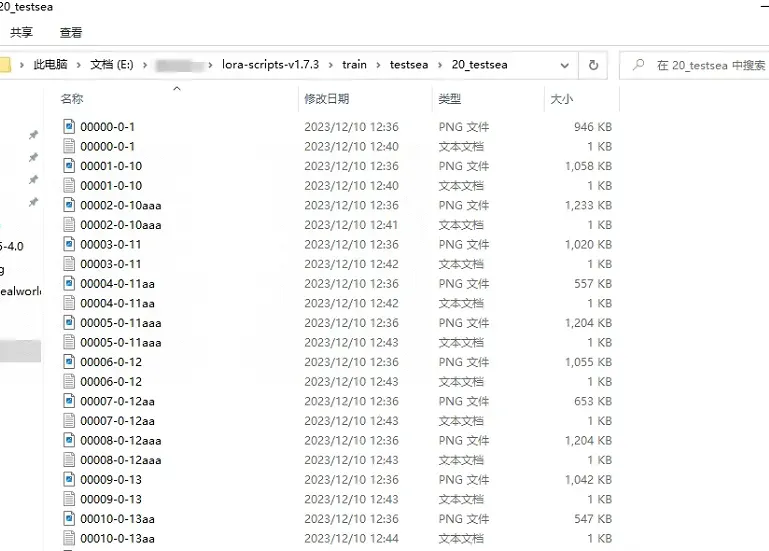
- 添加训练数据集路径: 最好将你的数据集放到lora-scripts-v1.7.3\train\下。在这个目录中创建一个文件夹为你数据集名称,随后再创建一个文件夹为 数字_数据集名称。如上图所示。20代表每一个epoch中单张图片的训练次数,比如epoch=10,则一张图像的实际训练次数是10×20=200次。在train_data_dir中只填前一级目录。
- 其他参数尽量先不调,直接开始训练。
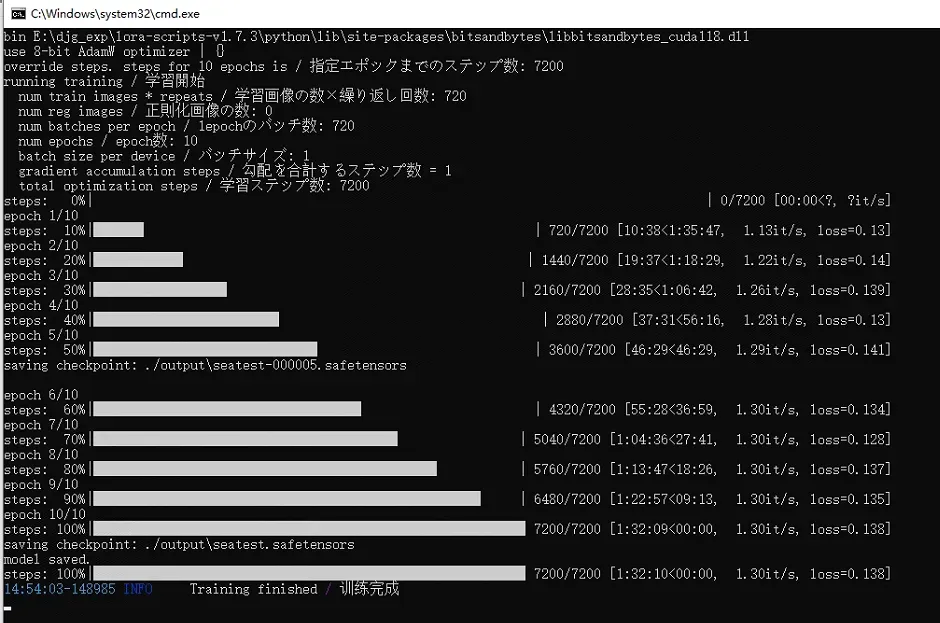
- 复制lora模型:将Output文件夹中的lora模型文件拷贝到SD WebUI的models/Lora文件夹中。没有数字的代表最终结果,有数字的代表不同阶段的结果。
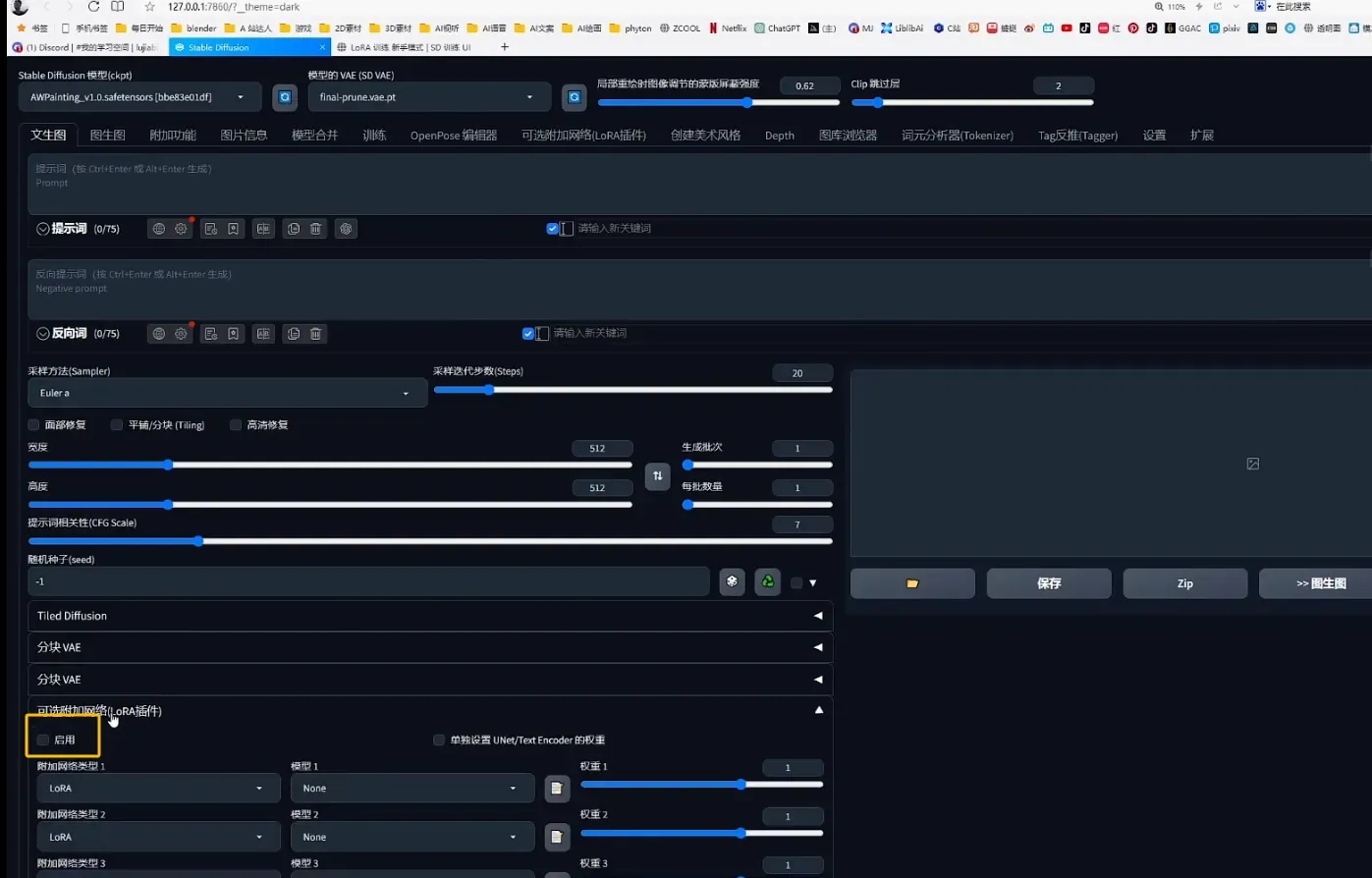
- 加载lora模型:在文生图这一页点击“启用”LoRA。随后选择刚才复制过来的LoRA模型。就可以生成啦。(权重建议调到0.8)
注:,我们直接对txt中的tag处理是非常不方便的,因此就需要:题词管理工具(毛子开发) 。链接我放到下方:链接:https://pan.baidu.com/s/1dAhvm-DBI9o62aWd1T1Csw 提取码:zub1
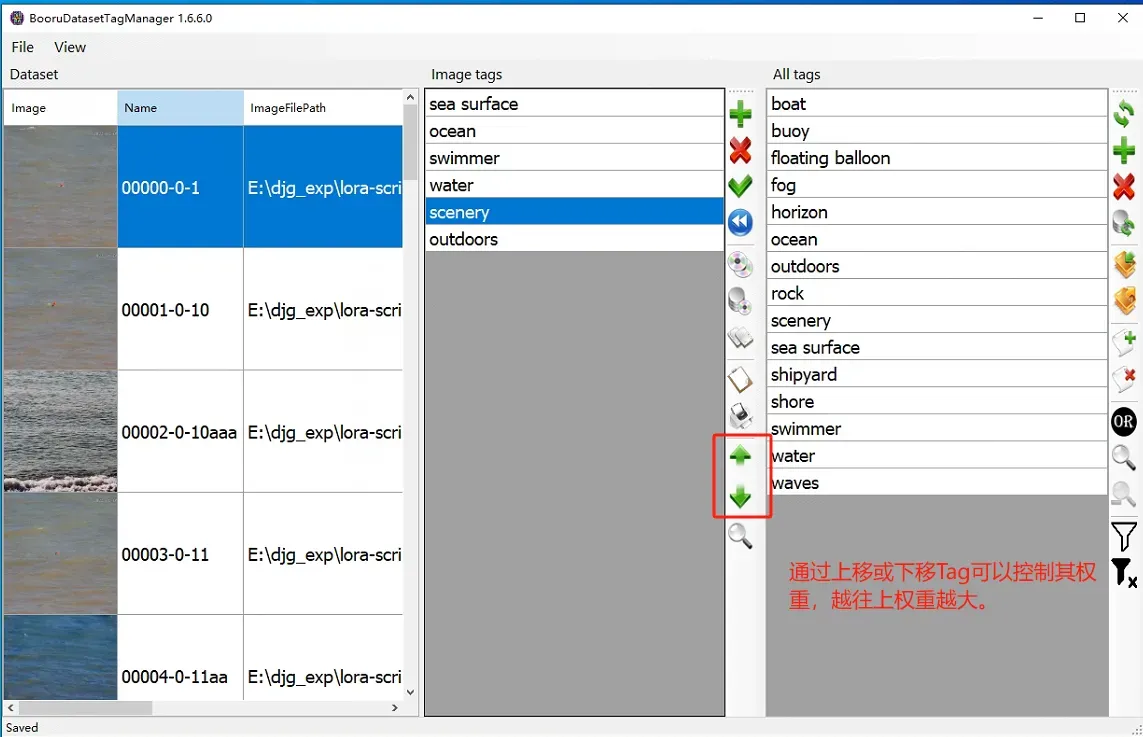
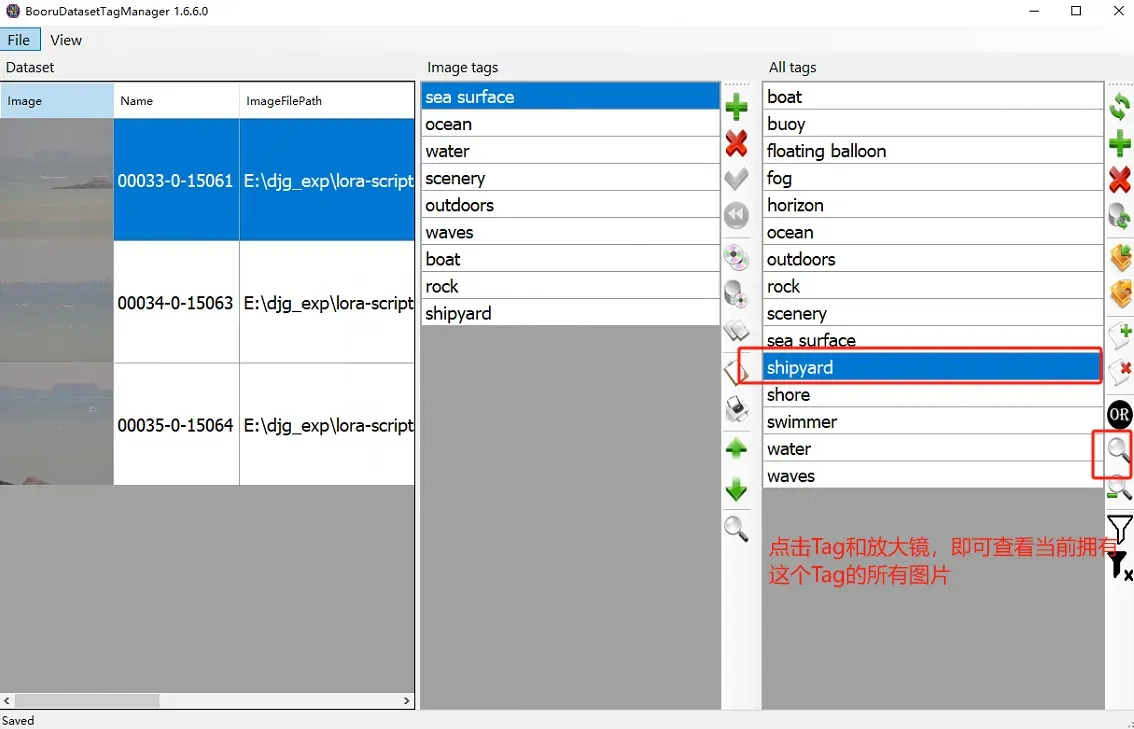
打开exe, 左上角File打开训练集目录,就可以看到当前图片和当前图片的标签。最右侧为所有图片的Tag。我们可以通过中间栏调整单个图片的Tag,也可以通过右边这一栏添加或删除所有图片中相同的Tag。双击图像可以查看细节。,修改完全部后再次点击左上角的Save。
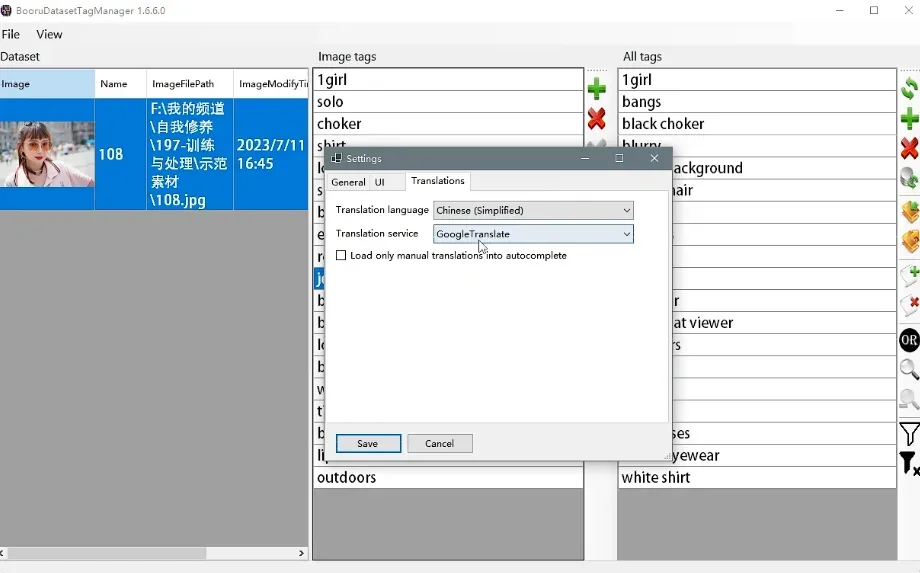
此外,还能有翻译功能,在左上角File的setting中:
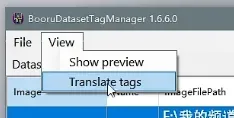
点击下方,即可进行自动翻译:
版权声明:本文为博主作者:@会飞的毛毛虫原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_42308217/article/details/134833073