单链表
- 1、链表的概念
- 2、链表的结构
- 3、链表的分类
- 4、单链表的实现
-
- 4.1、头文件包含和结构定义
- 4.2、初始化单链表
- 4.3、销毁单链表
- 4.4、打印单链表
- 4.5、增加数据
- 4.6、头插数据
- 4.7、尾插数据
- 4.8、头删数据
- 4.9、尾删数据
- 4.10、查询数据
- 4.11、在pos位置之后插入数据
- 4.12、删除pos位置之后的数据
- 5、代码汇总
- 总结
1、链表的概念
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
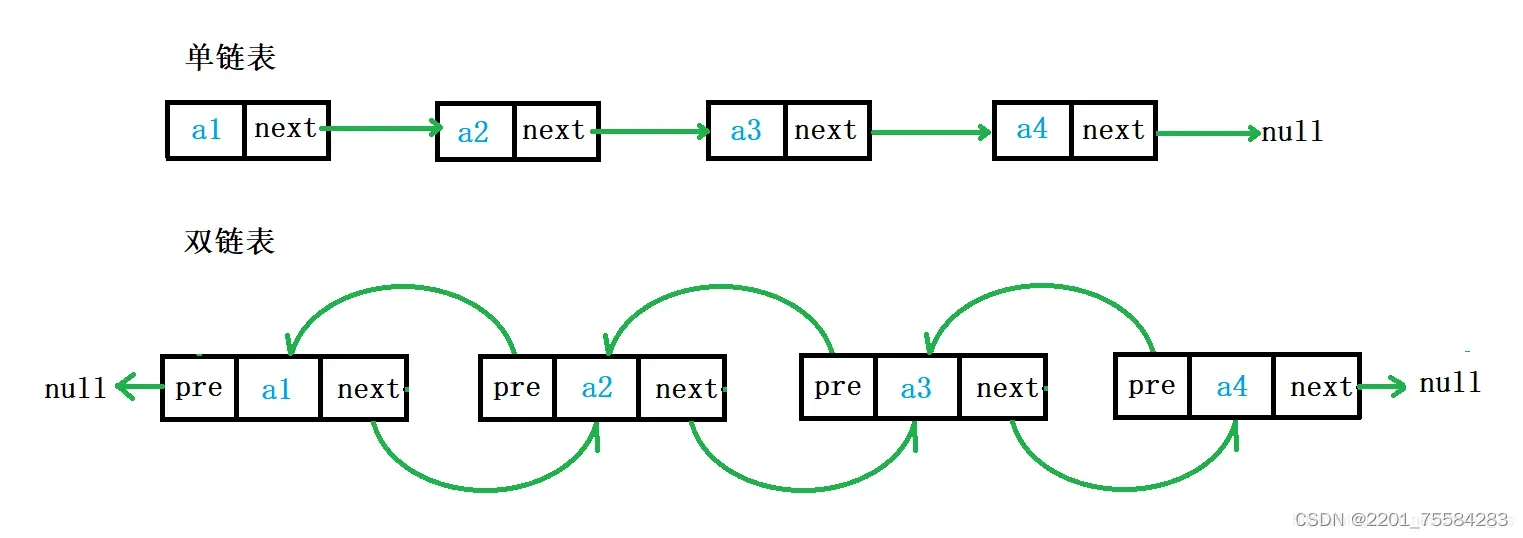
2、链表的结构

注意:
1、从上图可看出,链式结构在逻辑上是连续的,但是在物理上不一定连续
2、现实中的结点一般都是在堆上申请出来的
3、从堆上申请空间,还按照一定的策略分配的,两次申请可能连续,也可能不连续
注:
物理结构:数据实际存储在内存中的结构
逻辑结构:想象出来的结构
3、链表的分类
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
1. 单向或者双向
单向:只有一个指向下一个结点的指针
双向:有一个指向下一个结点的指针和指向前一个结点的指针
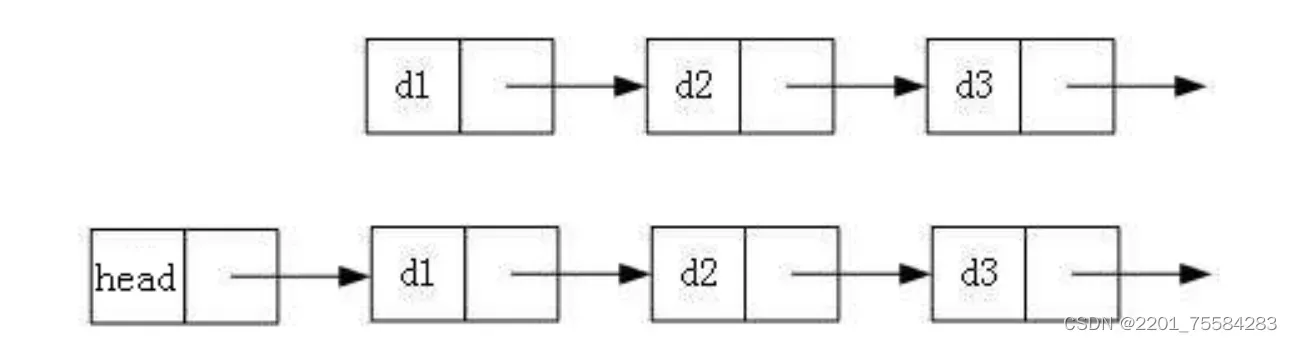
2. 带头或者不带头
带头:链表的头结点不存储数据,头结点不变化
不带头:链表的头结点直接存储数据,头结点时常变化
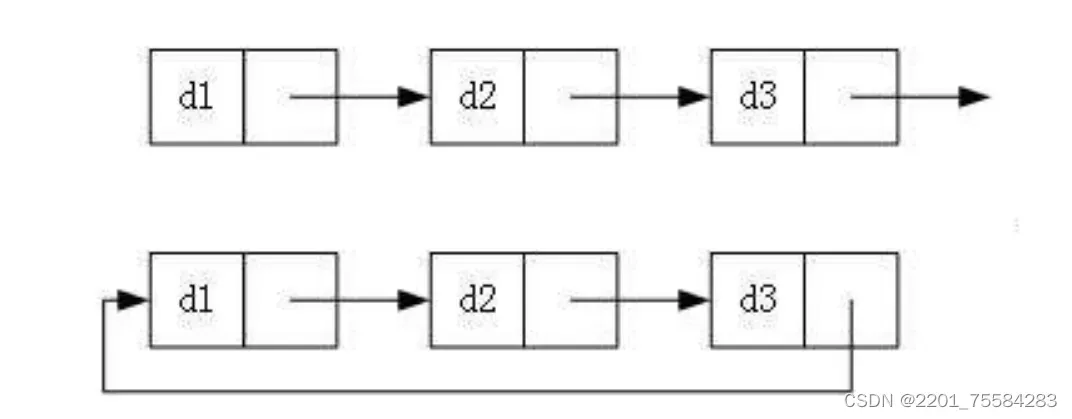
3. 循环或者非循环
循环:链表的尾结点指向头结点
非循环:链表的尾结点指向NULL
虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:
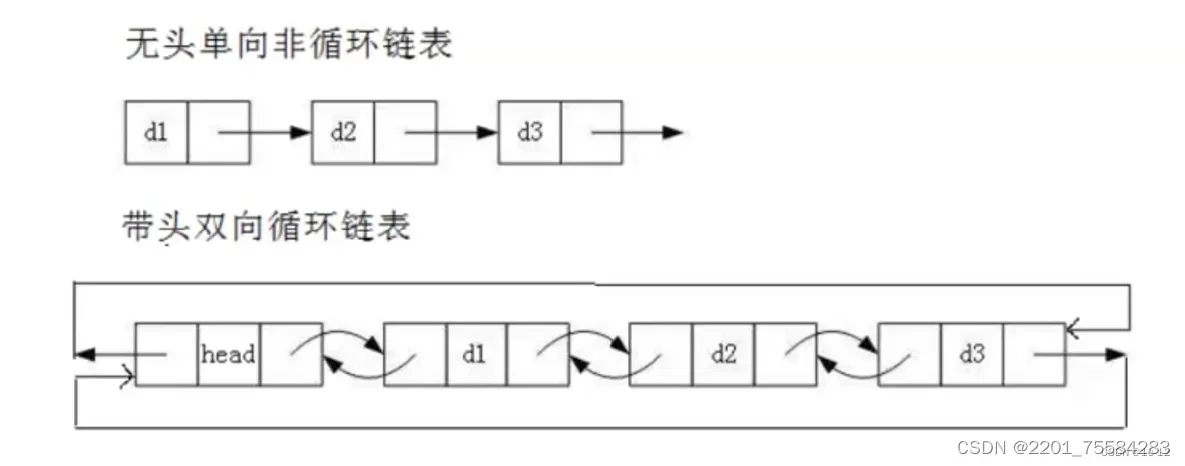
- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
- 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。
4、单链表的实现
实现一个单链表首先得创建一个工程。(下图为vs 2022)
SList.h(带头双向循环链表的类型定义、接口函数声明、引用的头文件)
SList.c(带头双向循环链表接口函数的实现)
test.c (主函数、测试顺序表各个接口功能)
4.1、头文件包含和结构定义
实现一个数据结构头文件是必不可少的,那么实现单链表可能用到的头文件有哪些呢?以下是实现单链表常见的头文件包含。
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
要实现一个单链表,首先得有一个单链表的结构,那个这个结构应该怎么创建呢?根据定义需要存储一个数据和一个指向下一个结点的指针。根据顺序表的经验,我们存储数据的类型链表结构的名字用typedef定义。
//单链表
typedef int SLDataType;//定义数据类型,可以根据需要更改
typedef struct SList
{
SLDataType data; //数据域 存储数据
struct SList* next;//指针域 存储指向下一个结点的指针
}SList;
4.2、初始化单链表
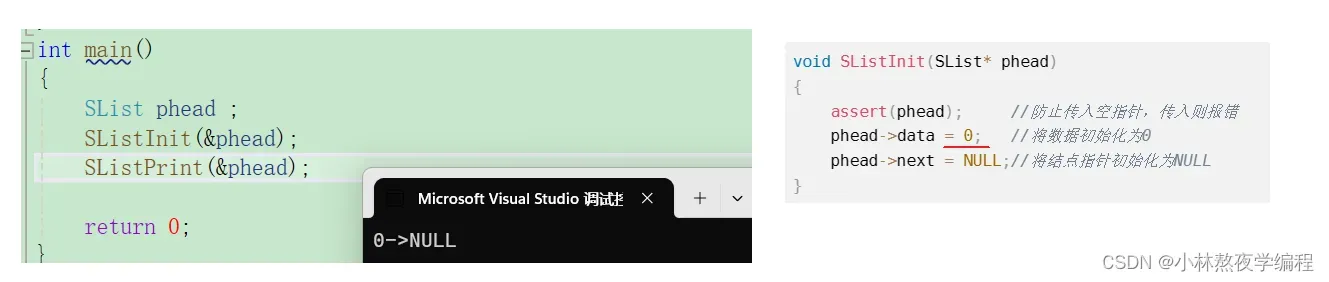
因为创建一个变量实质是给变量开辟一块内存空间,但是这块内存空间可能有遗留的数据,所以在创建变量之后需要进行初始化。
注:单链表不初始化也不会有影响,因为此单链表是不带头结点的,添加数据也是重新开辟的空间,所以不会有影响。
void SListInit(SList* phead)
{
assert(phead); //防止传入空指针,传入则报错
phead->data = 0; //将数据初始化为0
phead->next = NULL;//将结点指针初始化为NULL
}
测试
4.3、销毁单链表
因为单链表是动态开辟内存的,用完之后需要将内存还给操作系统,也就是我们常说销毁。
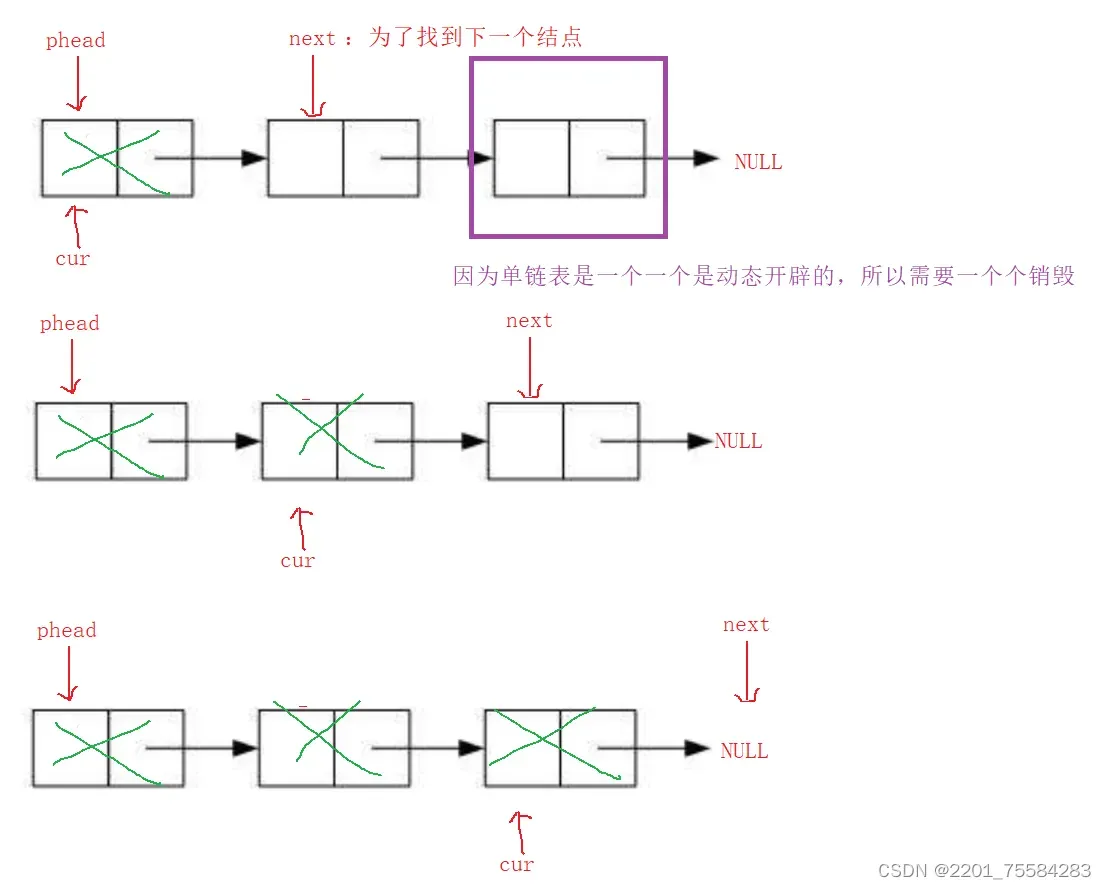
void SListDestroy(SList* phead)
{
assert(phead);
SList* cur = phead;//为了能在后序找到头结点,所以新创建一个变量指向头结点
while (cur != NULL)
{
SList* next = cur->next;
free(cur);
cur = next;
}
}
4.4、打印单链表
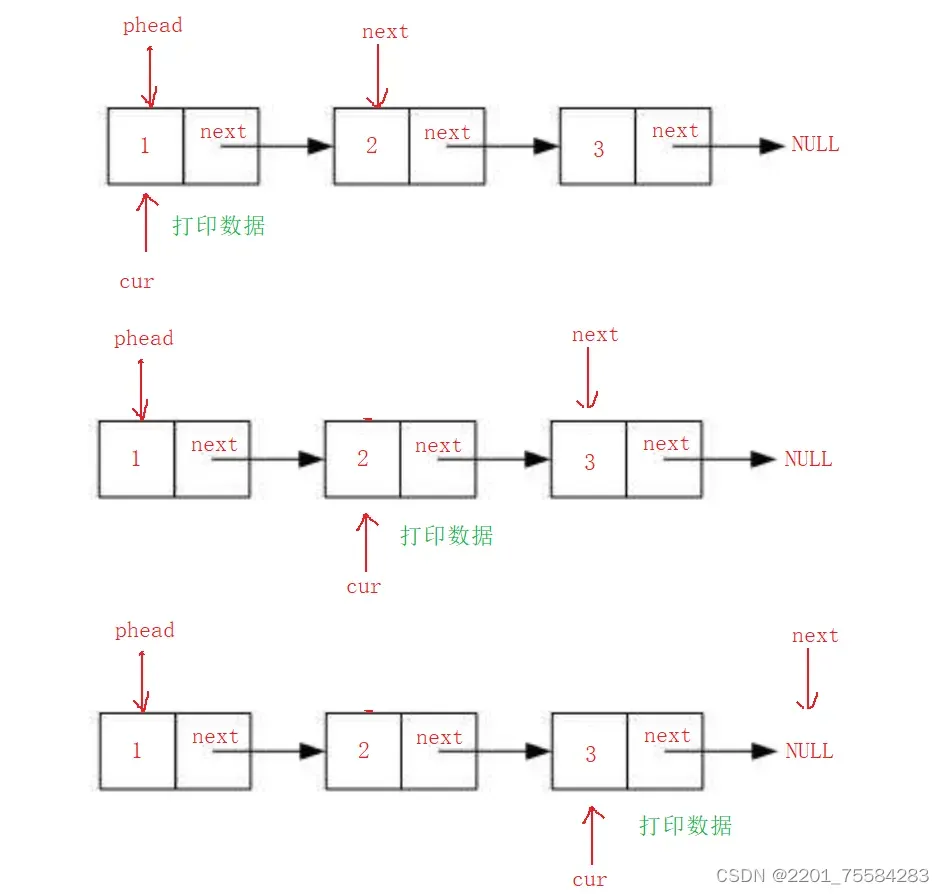
void SListPrint(SList* phead)
{
assert(phead);
SList* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
4.5、增加数据
因为在下面的函数中,时常会增加数据,所以将增加数据封装成一个函数,让代码更结构化。
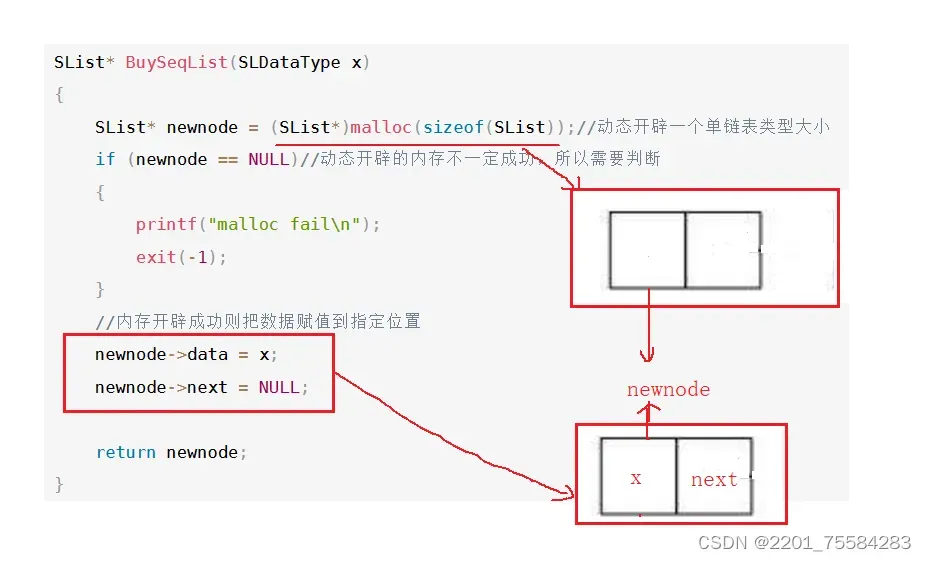
SList* BuySeqList(SLDataType x)
{
SList* newnode = (SList*)malloc(sizeof(SList));//动态开辟一个单链表类型大小
if (newnode == NULL)//动态开辟的内存不一定成功,所以需要判断
{
printf("malloc fail\n");
exit(-1);
}
//内存开辟成功则把数据赋值到指定位置
newnode->data = x;
newnode->next = NULL;
return newnode;
}
4.6、头插数据
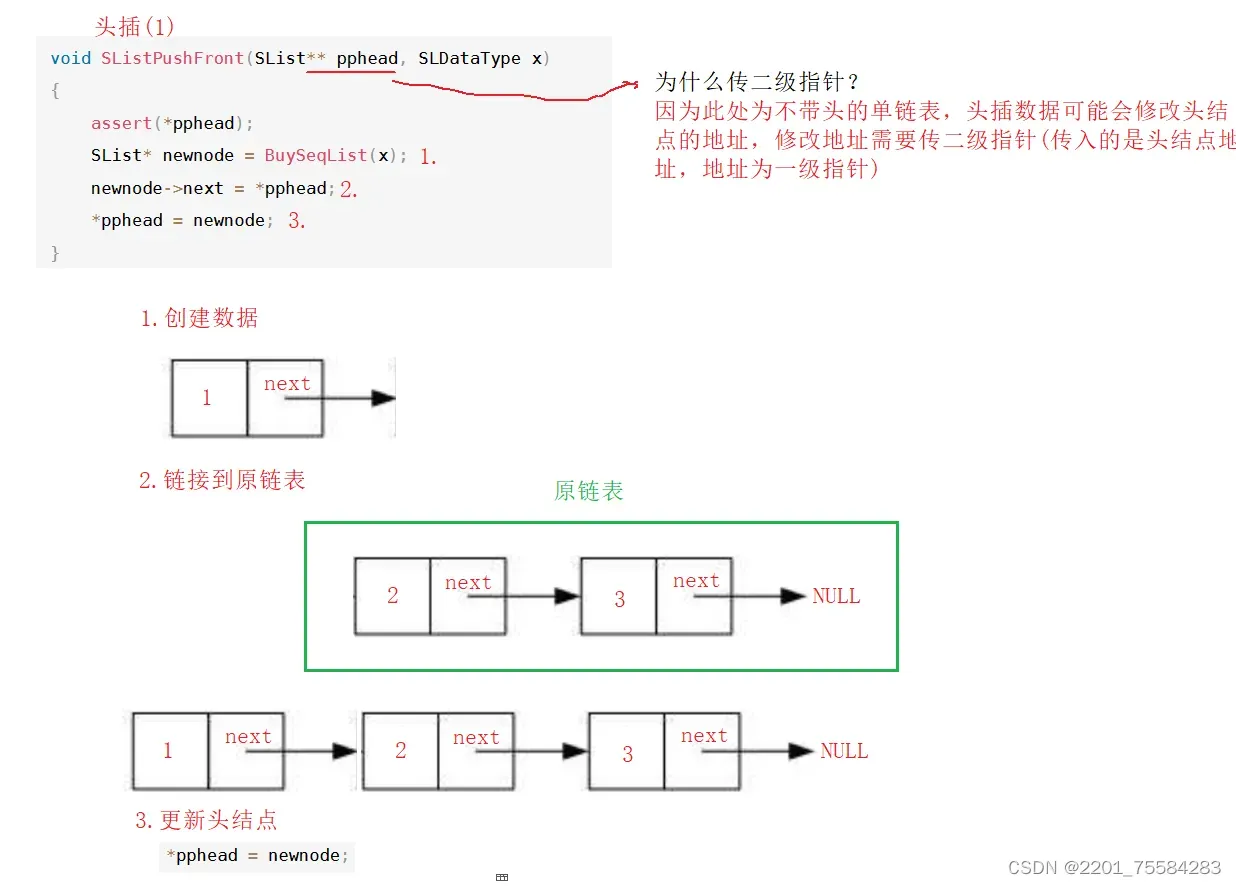
没有数据的头插也适用
void SListPushFront(SList** pphead, SLDataType x)
{
SList* newnode = BuySeqList(x);
newnode->next = *pphead;
*pphead = newnode;
}
测试
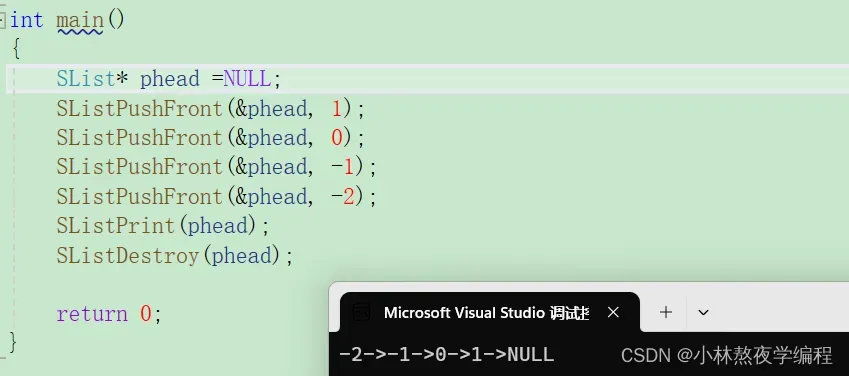
4.7、尾插数据
void SListPushBack(SList** pphead, SLDataType x)
{
SList* newnode = BuySeqList(x);
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
SList* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
测试
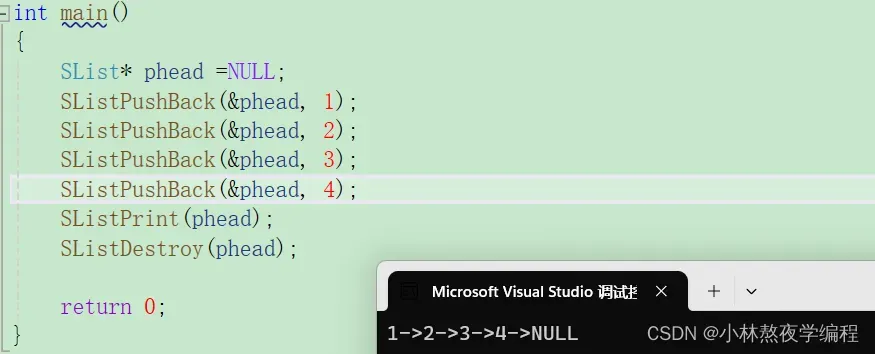
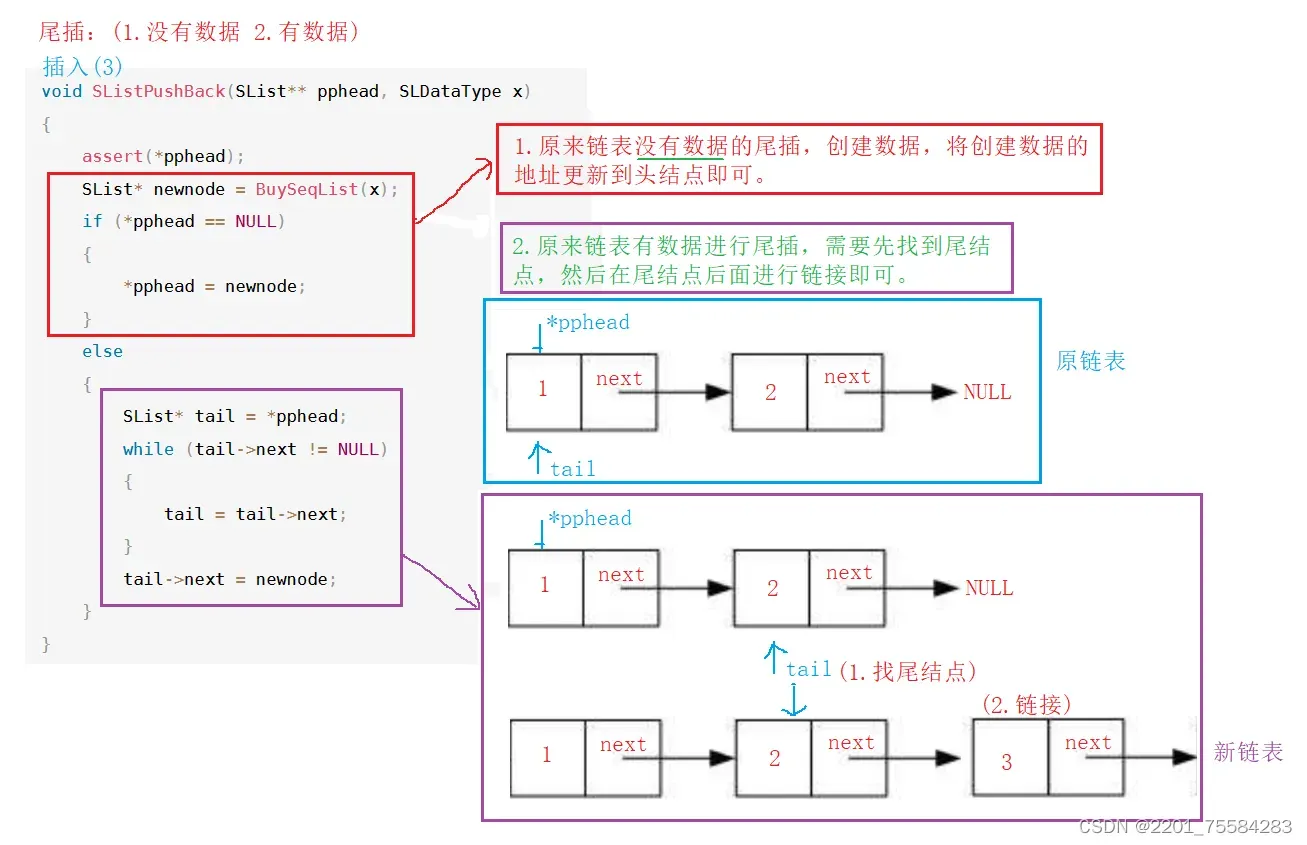
没有数据的图可看4.5增加数据的图。
4.8、头删数据
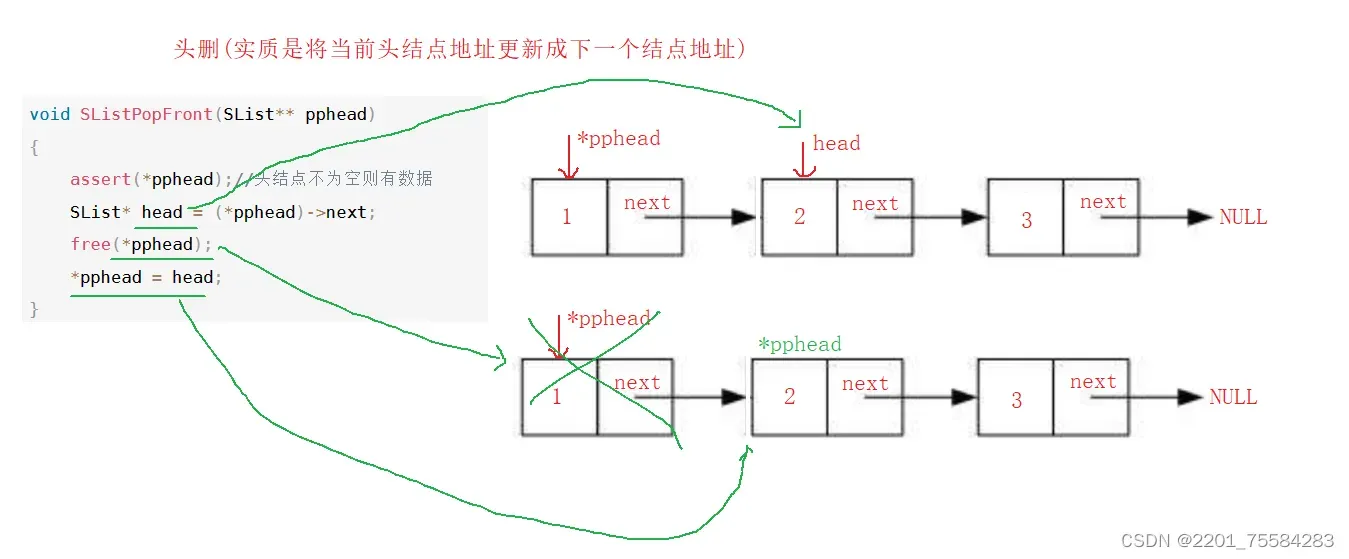
void SListPopFront(SList** pphead)
{
assert(*pphead);//头结点不为空则有数据
SList* head = (*pphead)->next;
free(*pphead);
*pphead = head;
}
测试
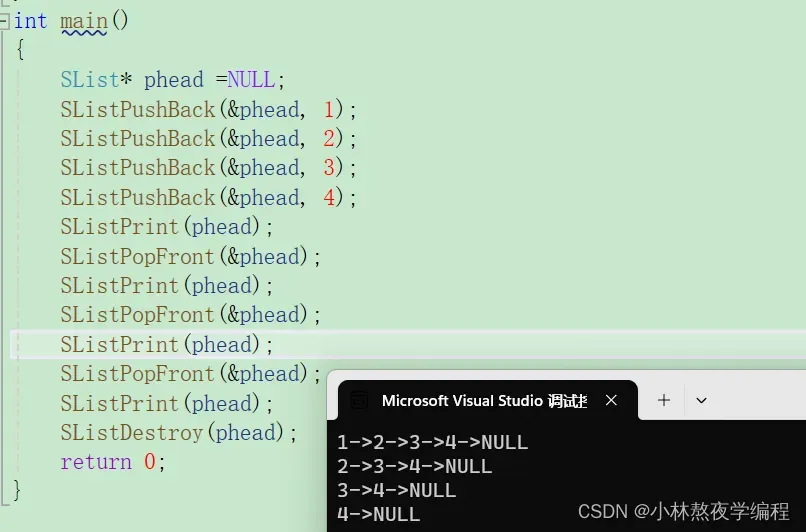
4.9、尾删数据
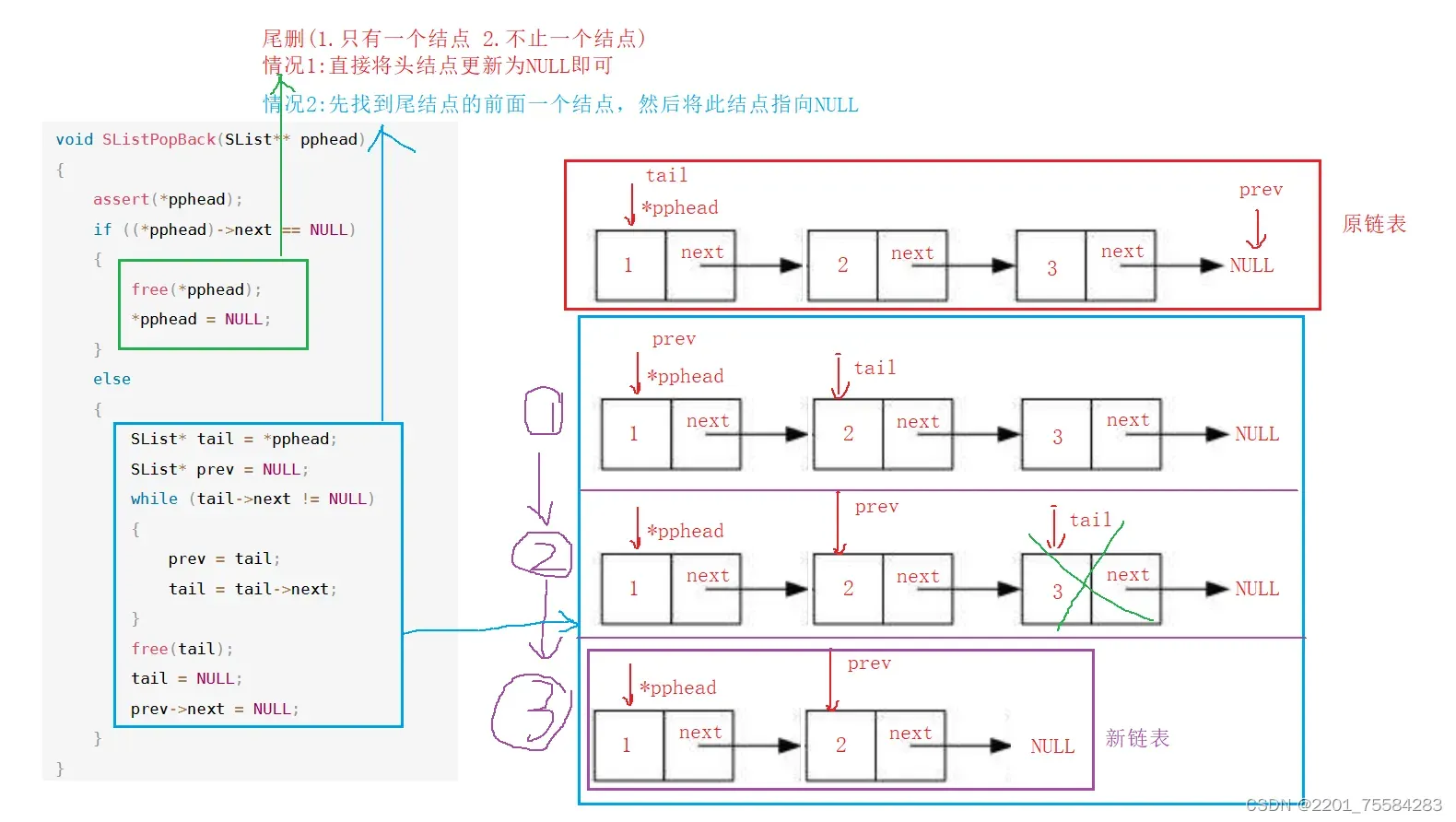
void SListPopBack(SList** pphead)
{
assert(*pphead);
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SList* tail = *pphead;
SList* prev = NULL;
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
prev->next = NULL;
}
}
测试

4.10、查询数据
找到则返回当前当前数据结点地址,没找到则返回空地址
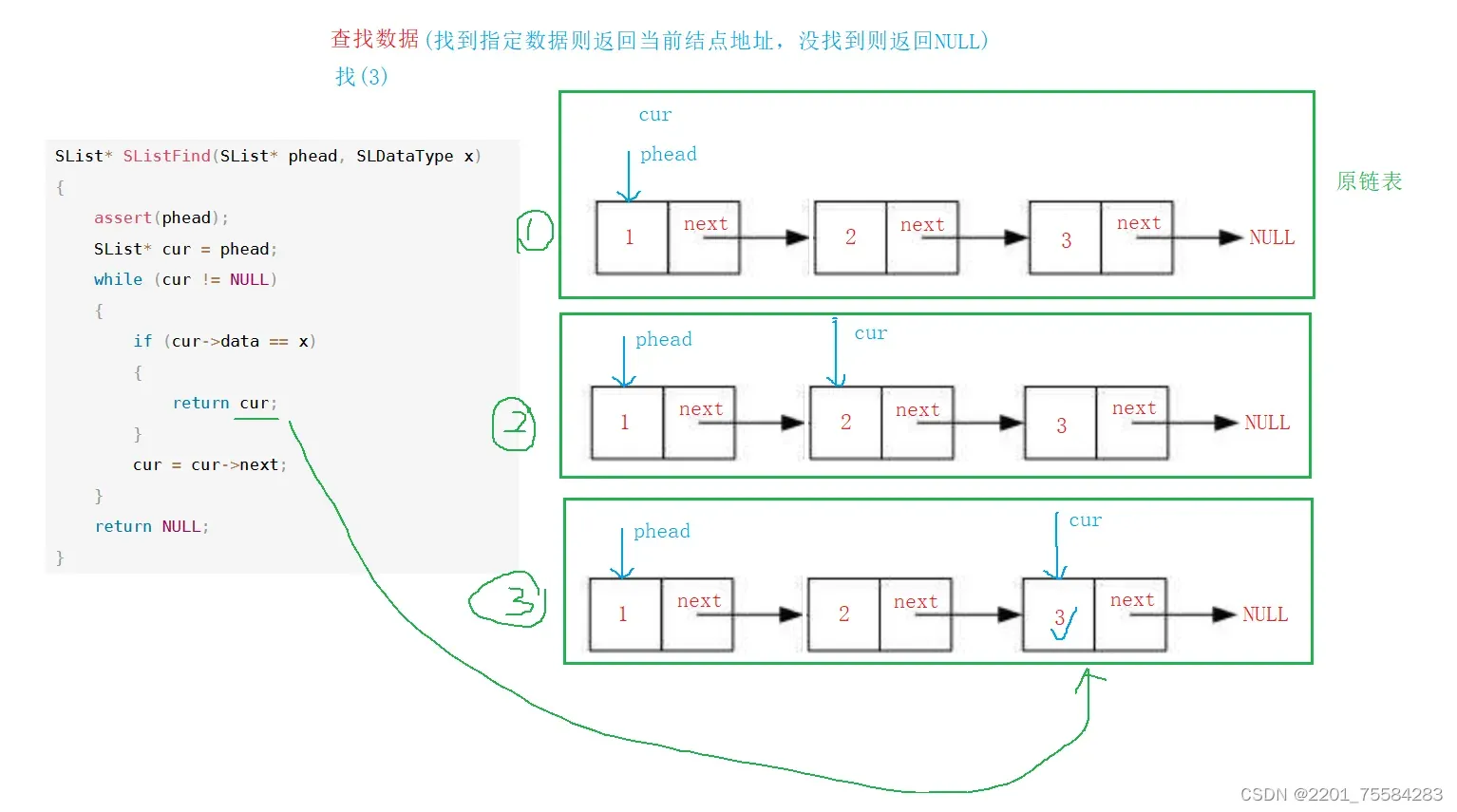
SList* SListFind(SList* phead, SLDataType x)
{
assert(phead);
SList* cur = phead;
while (cur != NULL)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
测试
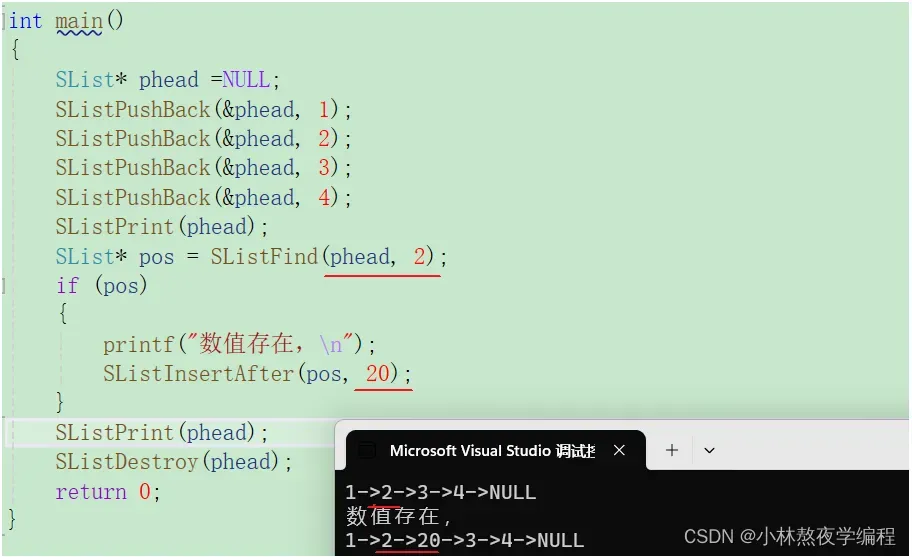
4.11、在pos位置之后插入数据
pos位置是地址,跟上面查找数据相对应
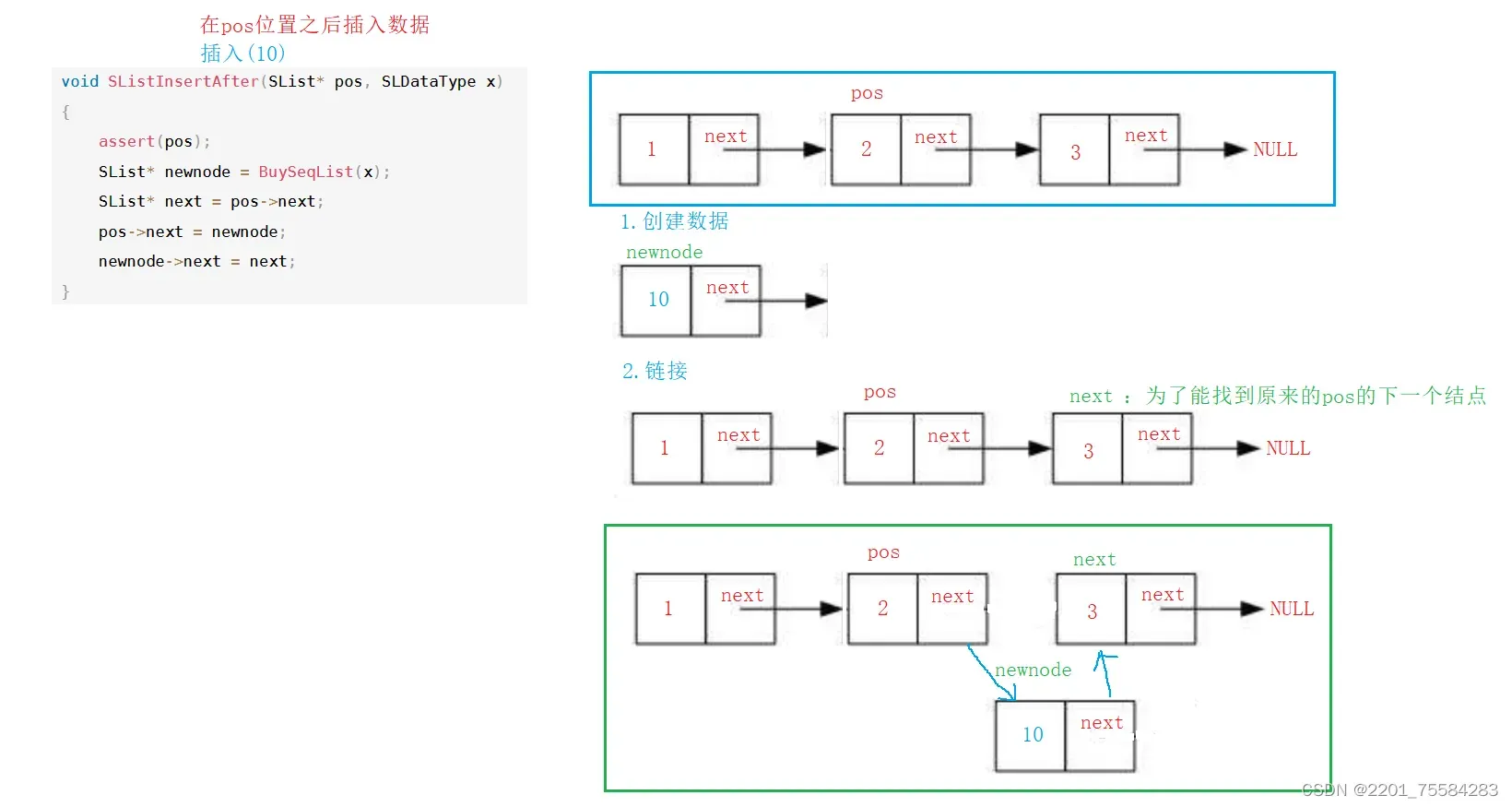
void SListInsertAfter(SList* pos, SLDataType x)
{
assert(pos);
SList* newnode = BuySeqList(x);
SList* next = pos->next;
pos->next = newnode;
newnode->next = next;
}
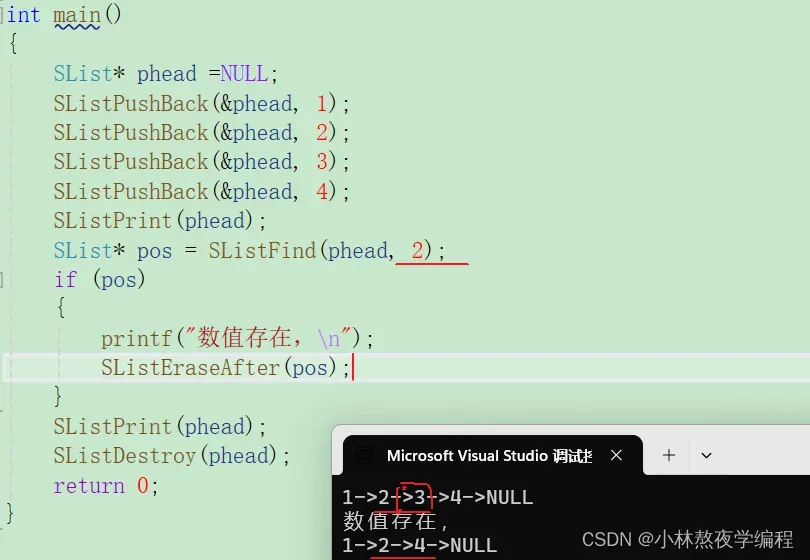
4.12、删除pos位置之后的数据
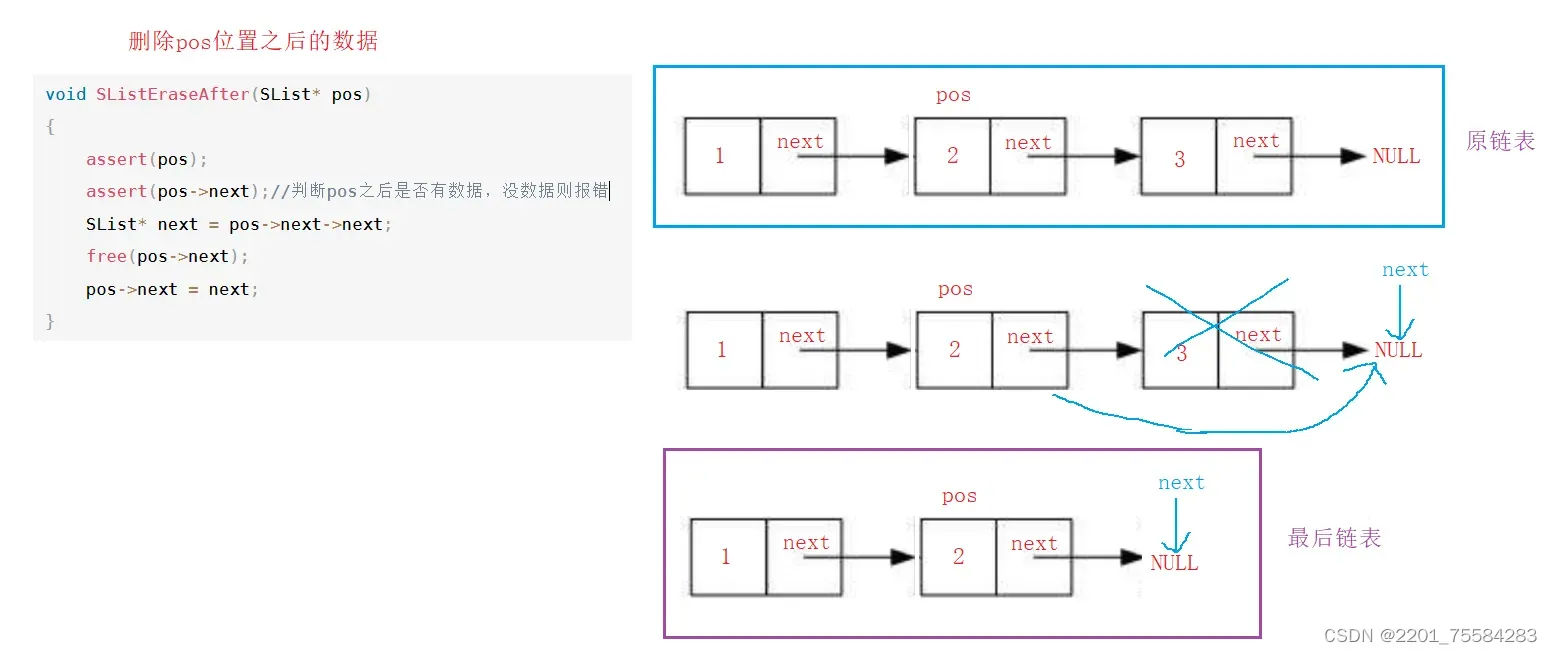
void SListEraseAfter(SList* pos)
{
assert(pos);
assert(pos->next);//判断pos之后是否有数据,没数据则报错
SList* next = pos->next->next;
free(pos->next);
pos->next = next;
}
最后如果uu们想深入学习单链表可以自己实现一些其他的接口函数和测试函数喔,建议实现一个接口函数测试一个函数
5、代码汇总
以下是SList.h的代码,其中有一些函数没有实现还有几个问题没有解答,有兴趣的uu可以思考思考喔。
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
//单链表
typedef int SLDataType;
typedef struct SList
{
SLDataType data;//数据域 存储数据
struct SList* next;//指针域 存储指向下一个结点的指针
}SList;
//初始化
void SListInit(SList* phead);
//创建新数据
SList* BuySeqList(SLDataType x);
//打印
void SListPrint(SList* phead);
//尾插
void SListPushBack(SList** pphead, SLDataType x);
//尾删
void SListPopBack(SList** pphead);
//头插
void SListPushFront(SList** pphead, SLDataType x);
//头删
void SListPopFront(SList** pphead);
//查询数据 按地址查询
SList* SListFind(SList* phead, SLDataType x);
//按地址插入数据 pos之前插入
void SListInsert(SList** pphead, SList* pos, SLDataType x);
// 删除pos位置
void SListErase(SList** pphead, SList* pos);
// 单链表在pos位置之后插入x
// 分析思考为什么不在pos位置之前插入?
void SListInsertAfter(SList* pos, SLDataType x);
// 单链表删除pos位置之后的值
// 分析思考为什么不删除pos位置?
void SListEraseAfter(SList* pos);
void SListDestroy(SList* phead);
以下是SList.c代码
#define _CRT_SECURE_NO_WARNINGS
#include "SList.h"
void SListInit(SList* phead)
{
assert(phead);
phead->data = 0;//将数据初始化为0
phead->next = NULL;//将结点指针初始化为NULL
}
//销毁
void SListDestroy(SList* phead)
{
assert(phead);
SList* cur = phead;
while (cur != NULL)
{
SList* next = cur->next;
free(cur);
cur = next;
}
}
//创建新数据
SList* BuySeqList(SLDataType x)
{
SList* newnode = (SList*)malloc(sizeof(SList));
if (newnode == NULL)
{
printf("malloc fail\n");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
//打印
void SListPrint(SList* phead)
{
assert(phead);
SList* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
//尾插
void SListPushBack(SList** pphead, SLDataType x)
{
SList* newnode = BuySeqList(x);
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
SList* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
//尾删
void SListPopBack(SList** pphead)
{
assert(*pphead);
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SList* tail = *pphead;
SList* prev = NULL;
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
prev->next = NULL;
}
}
//头插
void SListPushFront(SList** pphead, SLDataType x)
{
SList* newnode = BuySeqList(x);
newnode->next = *pphead;
*pphead = newnode;
}
//头删
void SListPopFront(SList** pphead)
{
assert(*pphead);
assert((*pphead)->next);
SList* head = (*pphead)->next;
free(*pphead);
*pphead = head;
}
//查询数据 按地址查询
SList* SListFind(SList* phead, SLDataType x)
{
assert(phead);
SList* cur = phead;
while (cur != NULL)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
//在pos之前插入数据
void SListInsert(SList** pphead, SList* pos, SLDataType x)
{
assert(*pphead);
SList* newnode = BuySeqList(x);
if (*pphead == pos)
{
SListPushFront(pphead, x);
}
else
{
SList* tail = *pphead;
SList* prev = NULL;
while (tail != pos)
{
prev = tail;
tail = tail->next;
}
prev->next = newnode;
newnode->next = pos;
}
}
// 删除pos位置 新加下面同
void SListErase(SList** pphead, SList* pos)
{
assert(*pphead);
assert(pos);
SList* cur = *pphead;
SList* prev = NULL;
while (cur != pos)
{
prev = cur;
cur = cur->next;
}
prev->next = pos->next;
free(pos);
pos = NULL;
}
// 单链表在pos位置之后插入x
// 分析思考为什么不在pos位置之前插入?
//因为在pos之前插入元素需要先找到插入位置前面的结点 需要进行一次遍历 效率不高
void SListInsertAfter(SList* pos, SLDataType x)
{
assert(pos);
SList* newnode = BuySeqList(x);
SList* next = pos->next;
pos->next = newnode;
newnode->next = next;
}
// 分析思考为什么不删除pos位置?
//因为删除之后的位置可以直接进行释放然后置空 不需要找到该结点的前面结点进行链接
//而删除pos之前位置需要先找到pos前一个位置结点 然后再释放和置空
// 单链表删除pos位置之后的值
void SListEraseAfter(SList* pos)
{
assert(pos);
assert(pos->next);
SList* next = pos->next->next;
free(pos->next);
pos->next = next;
}
总结
本篇博客就结束啦,谢谢大家的观看,如果公主少年们有好的建议可以留言喔,谢谢大家啦!
版权声明:本文为博主作者:小林熬夜学编程原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/2201_75584283/article/details/135278566