目录
前言
对抗性学习已被嵌入到深层网络中,用于学习解纠缠和可转移的领域适应表示。在分类问题中,现有的对抗性域自适应方法可能无法有效地对齐多模态分布的不同域。作者指出当前一些对抗域适应方法仍存在三个问题:1.只考虑了特征对齐,没有考虑标签对齐。2.当数据分布体现出复杂的多模态结构时,对抗性自适应方法可能无法捕获这种多模态结构,也就是说即使判别器完全被混淆,也无法保证此时源域和目标域足够相似。并且这种风险不能通过单独的域鉴别器将特征和类的分布对齐来解决。3.条件域判别器中使用最大最小优化方法也许存在一定的问题,最大最小的对抗网络结构给所有的例子施加了相同的权重,但是有些比较难预测的例子可能会对网络的学习产生影响。
因此本文提出条件对抗域适应网络(CDAN)在一定程度上解决以上三个问题:1.通过对齐特征-类别的联合分布解决 2.使用了Multilinear Conditioning多线性调整的方法来解决 3.提出了在目标函数中添加Entropy Conditioning熵调整来解决
一、CDAN结构
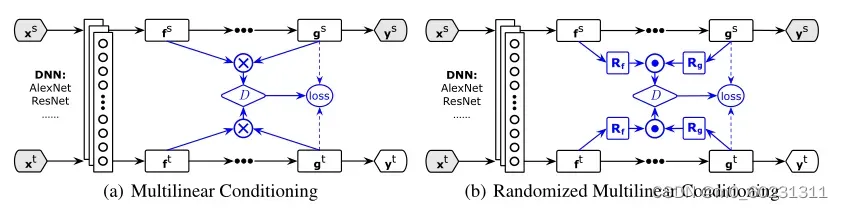
网络结构主要就是源域和目标域的数据通过深度神经网络Alexnet/ResNet对源域和目标域提取特征f,然后通过源分类器G得出预测标签g,与《Simultaneous Deep Transfer Across Domains and Tasks》相似,不过文中将预测结果g和特征f联合分布,多线性映射输入到与域判别器D中。
二、多线性调整
文中通过联合变量将域鉴别器D条件设定在分类器预测g上。这种条件域鉴别器可以潜在地解决对抗性域自适应的上述两个挑战。D的一个简单条件是)
,然而,对于级联策略,f和g彼此独立,无法完全捕捉特征表示和分类器预测之间的乘法相互作用,这对领域自适应至关重要。
因此,多线性映射被定义为多个随机向量的外积。给定两个随机向量x和y,联合分布可以通过互协方差
[
]来建模,其中φ是由一些再生核引起的特征图。这样的内核嵌入使得能够操纵多个随机变量之间的乘法相互作用。
假设线性映射φ(x)=x和具有C类别数的one-hot标签变量y,可以验证的是,均值映射分别独立计算x和y的平均值。相反,均值映射
计算每个C类条件分布
的均值。与f⨁g相比,多线性映射f⨂g的优点是可以完全捕捉复杂数据分布背后的多模态结构。然而有个劣势则是梯度爆炸,假如
/
分别表示f和g的维度,那么f⨂g的维度就是
∗
,二者的维度通常较大,因此很容易发生梯度爆炸。
因此文中通过随机方法来解决梯度爆炸的问题,即随机抽取f和g上的某些维度做多线性映射: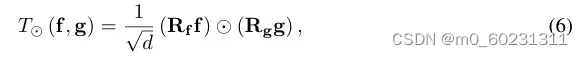
其中⨀表示逐元素运算,/
别表示随机矩阵,其只被采样一次并且在训练过程中固定。d则是需要采样的维度。经过作者论证,在
上进行内积近似等于
上进行内积,因此,可以直接采用
用于计算以方便效率。因此,我们将条件域鉴别器D使用的条件策略定义为:
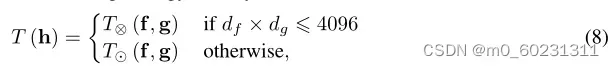
其中4096是典型深度网络(例如AlexNet)中的最大单元数,如果多线性映射的维数大于4096,则采用随机策略进行多线性映射,反之使用正常的多线性映射。
三、熵调整
条件域鉴别器的极大极小问题对不同的例子具有同等的重要性,而具有不确定预测的难以转移的例子可能会恶化条件对抗性自适应过程。为了实现安全转移,我们通过熵标准来量化分类器预测的不确定性,其中c是类的数量,
是将示例预测到类c的概率。我们通过将条件域鉴别器的每个训练示例重新加权熵感知权重
。用于提高可转移性的CDAN的熵调节变体(CDAN+E)被公式化为:
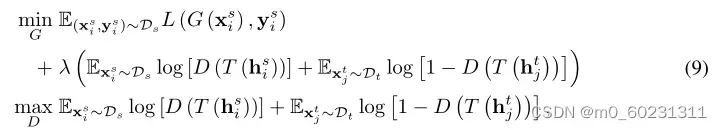
四、总体优化目标
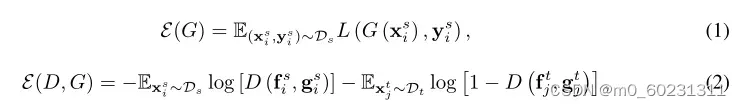

即联合最小化式子(1)中源分类器G和特征提取器F,最小化式子(2)中鉴别器D,即最大化特征提取器和源分类器G。即:
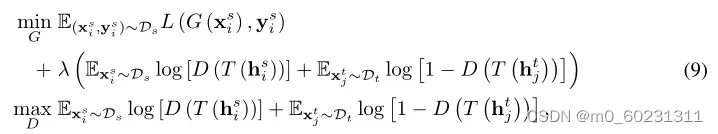
其中 是域特定特征表示f和分类器预测g的联合变量。通过将条件域鉴别器的每个训练示例重新加权熵感知权重后,最终优化目标是:
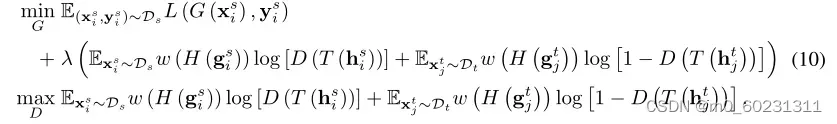
代码如下:
class ConditionalDomainAdversarialLoss(nn.Module):
def __init__(self, domain_discriminator: nn.Module, entropy_conditioning: Optional[bool] = False,
randomized: Optional[bool] = False, num_classes: Optional[int] = -1,
features_dim: Optional[int] = -1, randomized_dim: Optional[int] = 1024,
reduction: Optional[str] = 'mean', sigmoid=True):
super(ConditionalDomainAdversarialLoss, self).__init__()
self.domain_discriminator = domain_discriminator
self.grl = WarmStartGradientReverseLayer(alpha=1., lo=0., hi=1., max_iters=1000, auto_step=True)
self.entropy_conditioning = entropy_conditioning
self.sigmoid = sigmoid
self.reduction = reduction
#是否采用随机策略进行多线性映射
if randomized:
assert num_classes > 0 and features_dim > 0 and randomized_dim > 0
self.map = RandomizedMultiLinearMap(features_dim, num_classes, randomized_dim)
else:
self.map = MultiLinearMap()
self.bce = lambda input, target, weight: F.binary_cross_entropy(input, target, weight,
reduction=reduction) if self.entropy_conditioning \
else F.binary_cross_entropy(input, target, reduction=reduction)
self.domain_discriminator_accuracy = Nonedef forward(self, g_s: torch.Tensor, f_s: torch.Tensor, g_t: torch.Tensor, f_t: torch.Tensor) -> torch.Tensor:
#将f和g进行联合分布,多线性映射后传给域分类器d计算域分类损失
f = torch.cat((f_s, f_t), dim=0)
g = torch.cat((g_s, g_t), dim=0)
g = F.softmax(g, dim=1).detach()
h = self.grl(self.map(f, g))
d = self.domain_discriminator(h)
#熵调整
weight = 1.0 + torch.exp(-entropy(g))
batch_size = f.size(0)
weight = weight / torch.sum(weight) * batch_size
#是否采用二分类交叉熵损失函数
if self.sigmoid:
d_label = torch.cat((
torch.ones((g_s.size(0), 1)).to(g_s.device),
torch.zeros((g_t.size(0), 1)).to(g_t.device),
))
self.domain_discriminator_accuracy = binary_accuracy(d, d_label)
if self.entropy_conditioning:
return F.binary_cross_entropy(d, d_label, weight.view_as(d), reduction=self.reduction)
else:
return F.binary_cross_entropy(d, d_label, reduction=self.reduction)
else:
d_label = torch.cat((
torch.ones((g_s.size(0), )).to(g_s.device),
torch.zeros((g_t.size(0), )).to(g_t.device),
)).long()
self.domain_discriminator_accuracy = accuracy(d, d_label)
if self.entropy_conditioning:
raise NotImplementedError("entropy_conditioning")
return F.cross_entropy(d, d_label, reduction=self.reduction)
#随机策略多线性映射
class RandomizedMultiLinearMap(nn.Module):
def __init__(self, features_dim: int, num_classes: int, output_dim: Optional[int] = 1024):
super(RandomizedMultiLinearMap, self).__init__()
self.Rf = torch.randn(features_dim, output_dim)
self.Rg = torch.randn(num_classes, output_dim)
self.output_dim = output_dim
def forward(self, f: torch.Tensor, g: torch.Tensor) -> torch.Tensor:
f = torch.mm(f, self.Rf.to(f.device))
g = torch.mm(g, self.Rg.to(g.device))
output = torch.mul(f, g) / np.sqrt(float(self.output_dim))
return
#正常多线性映射
class MultiLinearMap(nn.Module):
def __init__(self):
super(MultiLinearMap, self).__init__()
def forward(self, f: torch.Tensor, g: torch.Tensor) -> torch.Tensor:
batch_size = f.size(0)
output = torch.bmm(g.unsqueeze(2), f.unsqueeze(1))
return output.view(batch_size, -1)版权声明:本文为博主作者:羊驼不驼a原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/m0_60231311/article/details/129654573