文章目录
ChatGPT is not all you need,一文看尽SOTA生成式AI模型:6大公司9大类别21个模型全回顾(一)
近两个月我们都被 ChatGPT 刷屏,说它的发展速度犹如坐火箭也毫不夸张。凭借其出色的性能,自从 Stable Diffusion 开源和 ChatGPT 开放接口后,业界对生成式模型更加热情了。然而,生成式SOTA模型发布速度之快,种类之多,我们很难做到不错过每一个模型。
上月,来自西班牙科米利亚斯主教大学(Comillas Pontifical University)的研究人员提交了一篇综述论文《ChatGPT is not all you need. A State of the Art Review of large Generative AI models》,将生成式模型按照任务模态、领域分成9大类,并总结了2022年发布的21个生成式模型的能力和局限性。这些局限性包括缺少特定任务下的大型数据集,以及需要高昂的计算资源等。

论文:ChatGPT is not all you need. A State of the Art Review of large Generative AI models
机构:Quantitative Methods Department, Universidad Pontificia Comillas, Madrid, Spain
作者:Roberto Gozalo-Brizuela, Eduardo C. Garrido-Merch´an
地址:https://arxiv.org/pdf/2301.04655.pdf
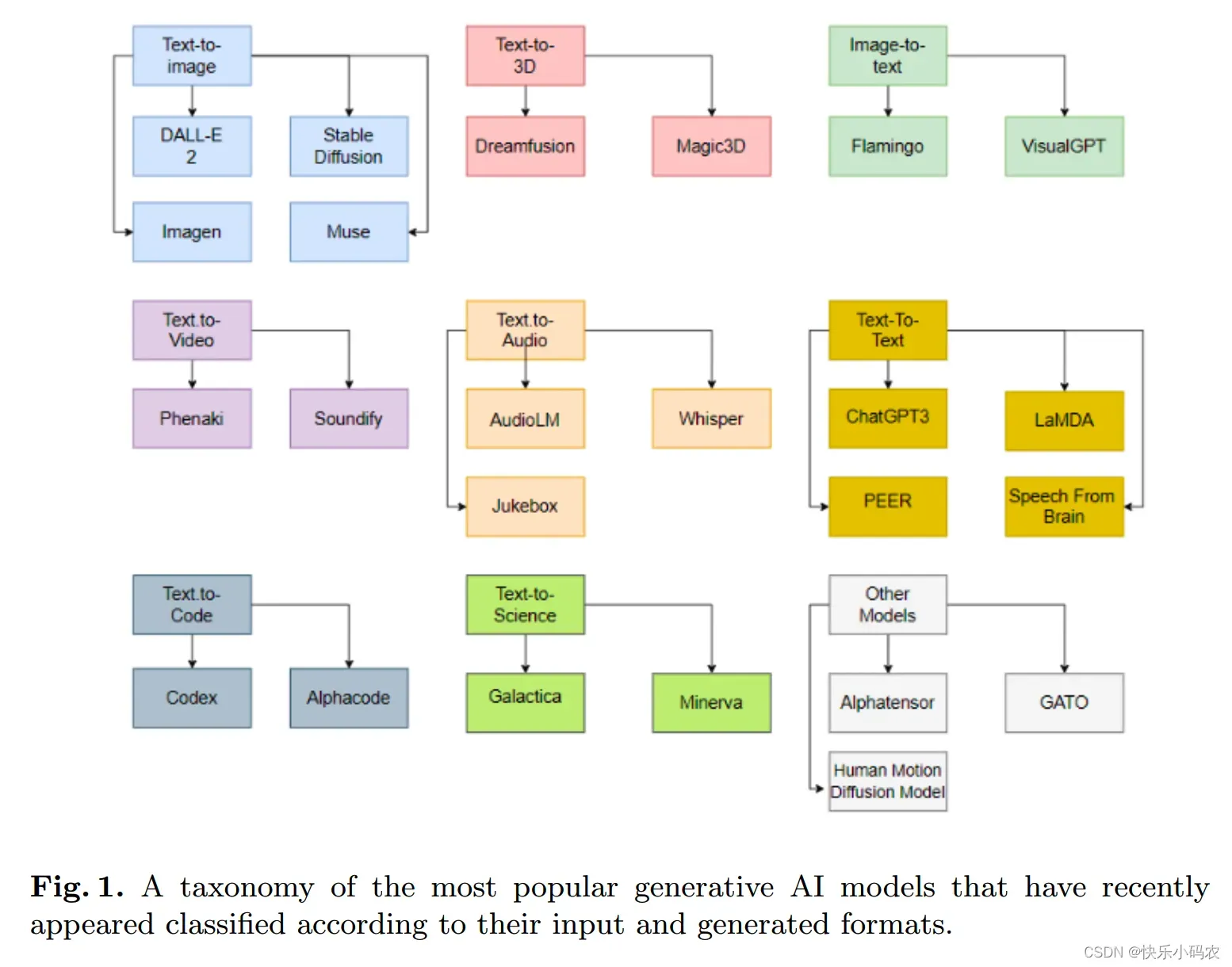
首先,模型可以按照输入和输出的数据类型分成9个大类,如下图 1 所示。
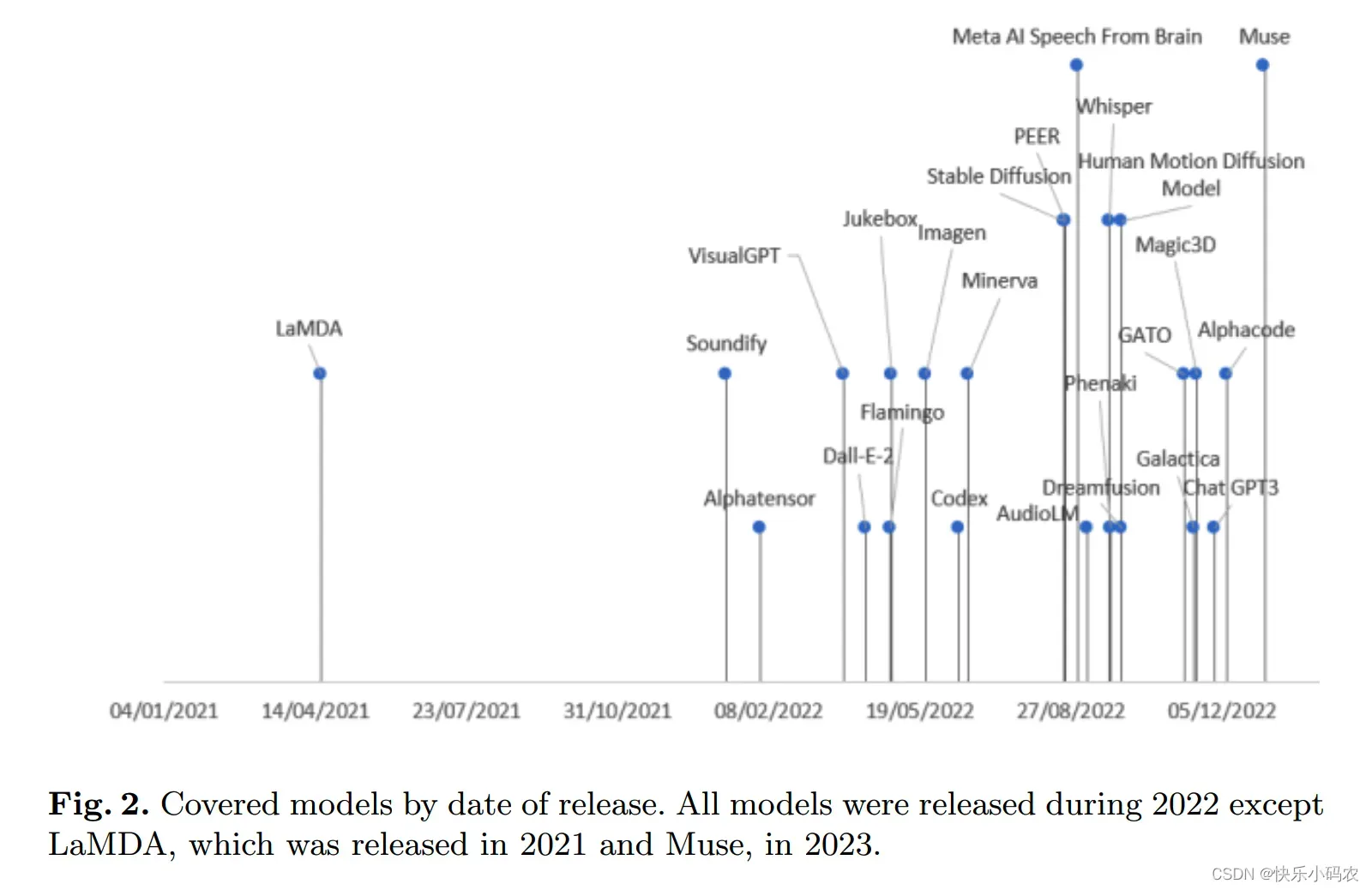
文章主要关注点是描述生成式 AI 模型的最新进展,为让读者能有整体认识,在图 2 中给出了所有已发布的模型。
另外,在这些已发布大模型的背后,只有如下图 3 所示的6个公司(OpenAl,Google,DeepMind,Meta,runway,Nvidia),在收购的初创公司和与学术界合作的帮助下,成功地部署了这些最先进的生成式AI模型。这一事实背后的主要原因是,为了能够估计这些模型的参数,必须拥有强大的计算能力以及在数据科学和数据工程方面技术精湛、经验丰富的团队。
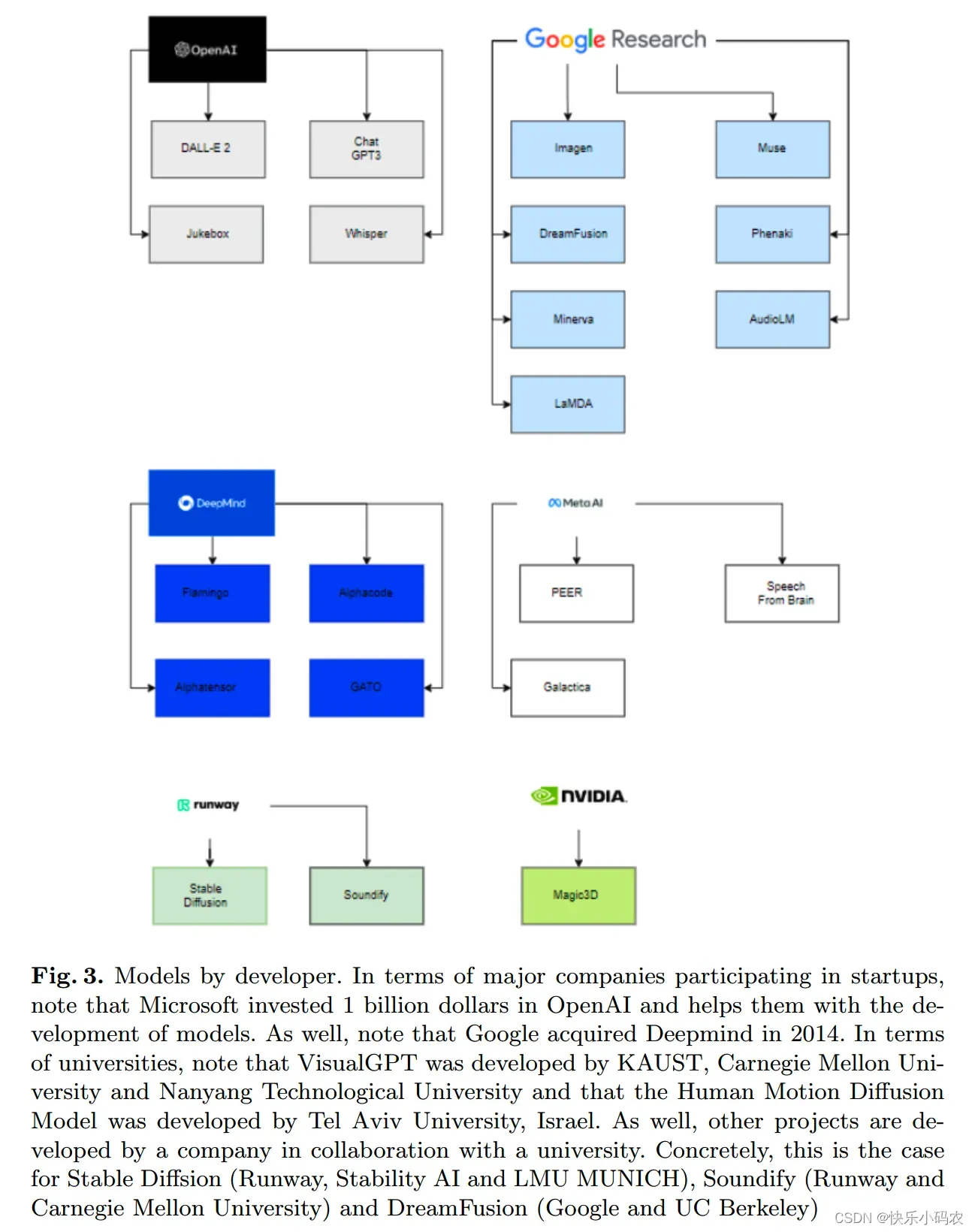
在参与创业的主要公司层面,微软向OpenAI投资了100亿美元,并帮助他们开发模型。此外,谷歌在2014年收购了Deepmind。
在大学方面,VisualGPT是由阿卜杜拉国王科技大学 (KAUST)、卡耐基梅隆大学和南洋理工大学开发的;Human Motion Diffusion模型是由以色列特拉维夫大学开发的。
在公司和大学合作层面,如Stable Diffusion由Runway, Stability AI和慕尼黑大学合作开发;Soundify由Runway和卡内基梅隆大学合作开发;DreamFusion由谷歌和加州大学伯克利分校合作。
文章从第三章开始详细介绍了图 1 描述的9个类别,对于每个类别,都相应地展示模型的详细信息。
Text-to-Image 模型
我们首先来看 Text-to-Image 模型,即输入是文本提示而输出是图像的模型。
DALL-E 2
由 OpenAI 开发的DALL-E 2能够从由文本描述组成的提示中生成原始、真实、逼真的图像和艺术,相比DALL-E 1,其分辨率提高了 4 倍。OpenAI 已经对外提供了API来访问该模型。
DALL-E 2特别之处在于它能够将概念、属性和不同风格结合起来,其能力源于语言-图像预训练模型CLIP神经网络,从而可以用自然语言来指示最相关的文本片段。
CLIP 是 OpenAI 在2021年初的一篇工作:《Learning Transferable Visual Models From Natural Language Supervision》。CLIP 是一组模型,有 9 个图像编码器、5 个卷积编码器和 4 个 transformer 编码器。它是一个 zero-shot 的视觉分类模型,预训练的模型在没有微调的情况下在下游任务上取得了很好的迁移效果。作者在30多个数据集上做了测试,涵盖了 OCR、视频中的动作检测、坐标定位等任务。详见 https://github.com/openai/CLIP.
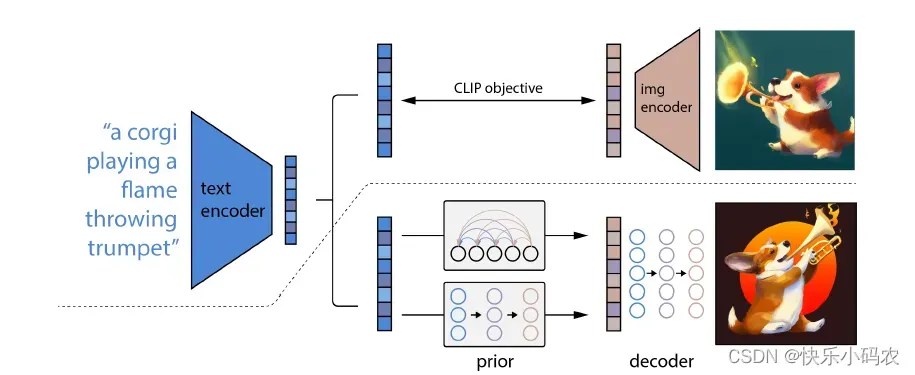
具体来说,CLIP embedding有几个理想的属性:能够对图像分布进行稳定的转换;具有强大的zero-shot能力;并且在微调后实现了最先进的结果。为了获得一个完整的图像生成模型,CLIP图像embedding解码器模块与一个先验模型相结合,从一个给定的文本标题中生成相关CLIP图像embedding。
因此,DALL-E 2 生成的图像在语义上巧妙地将不同且不相关的元素组合起来,例如输入 prompt:a bowl of soup that is a portal to another dimension as digital art,便生成了下面的图像。

IMAGEN
Imagen 是一种文本到图像的扩散模型,能够生成较为真实的图片。这是建立在大型的transformer语言模型上。谷歌已经对外提供了API来访问该模型。
Imagen 主要利用了 T5 模型作为预训练模型,同时使用800GB的训练语料来进行预训练。预训练结束后,然后进行冻结,输入到Text-to-Image diffusion Model中,然后通过上采样,使得图片生成高清图像。具体的模型结构如下:
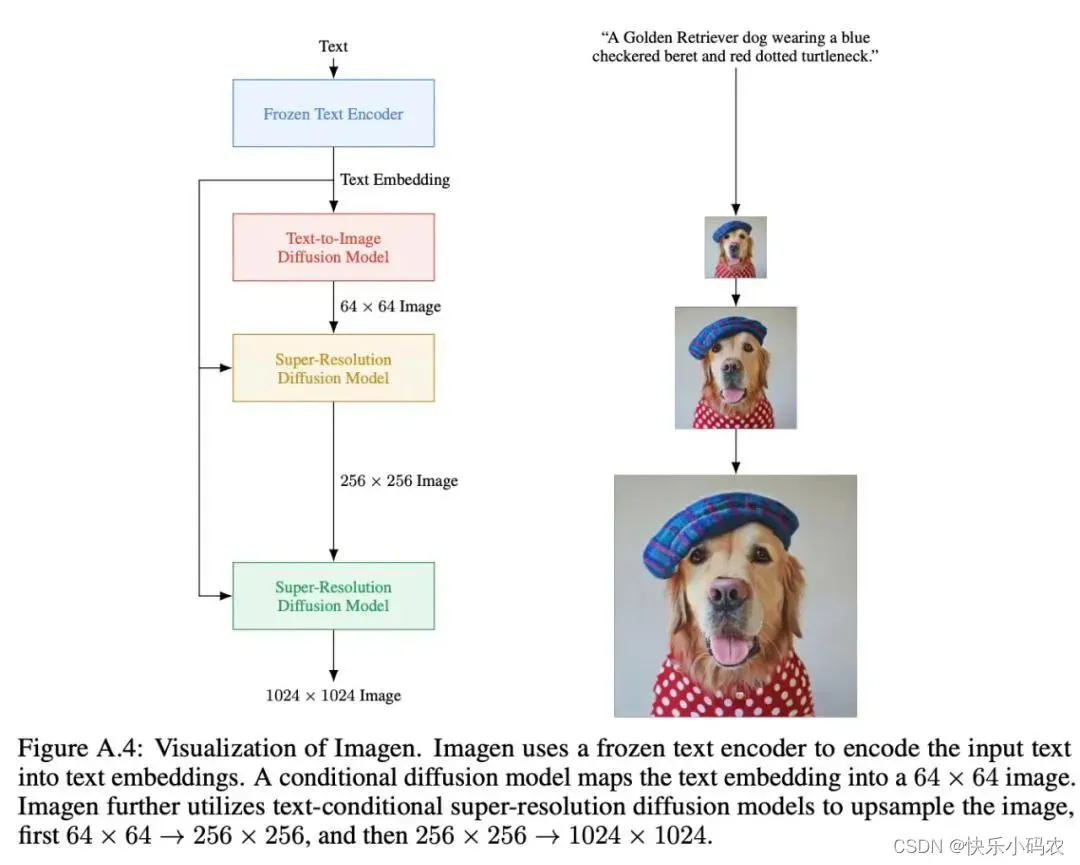
同时谷歌发现,在纯文本语料库上预训练的通用大型语言模型(如T5)在为图像合成编码文本方面出人意料地有效。不增加diffusion model的大小,而去增加语言模型的大小,生成的效果会更加逼真。
总结起来看,使用 Imagen 有这几个主要发现:
- 大型预训练冻结文本编码器对于文本到图像生成任务非常有效。
- 增加语言模型的大小比增加图像扩散模型的大小更能提高样本保真度和图像文本对齐。
- 引入一个新的高效U-Net体系结果,它具有更高的计算效率、更高的内存效率和更快的收敛速度。
- 模型在没有用到COCO数据集训练情况下,达到了最高的效果。
此外,谷歌研究者推出了比COCO更有挑战性的测试基准 DrawBench ,包含各种刁钻的提示词。DrawBench 是对图像到文本(text to image)模型进行多维评估。其中包含11个类别,大约200个文本提示,旨在探索模型的不同语义属性。
Stable Diffusion
Stable Diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。如果想要更深入了解Stable Diffusion的技术原理,可以阅读论文《High-Resolution Image Synthesis with Latent Diffusion Models》,它发表于CVPR2022,由德国慕尼黑大学机器视觉与学习研究小组开发。Stability AI 官方实践了开源承诺,目前已经发布了Stable Diffusion 2.0 版本,项目地址:https://github.com/Stability-AI/stablediffusion.
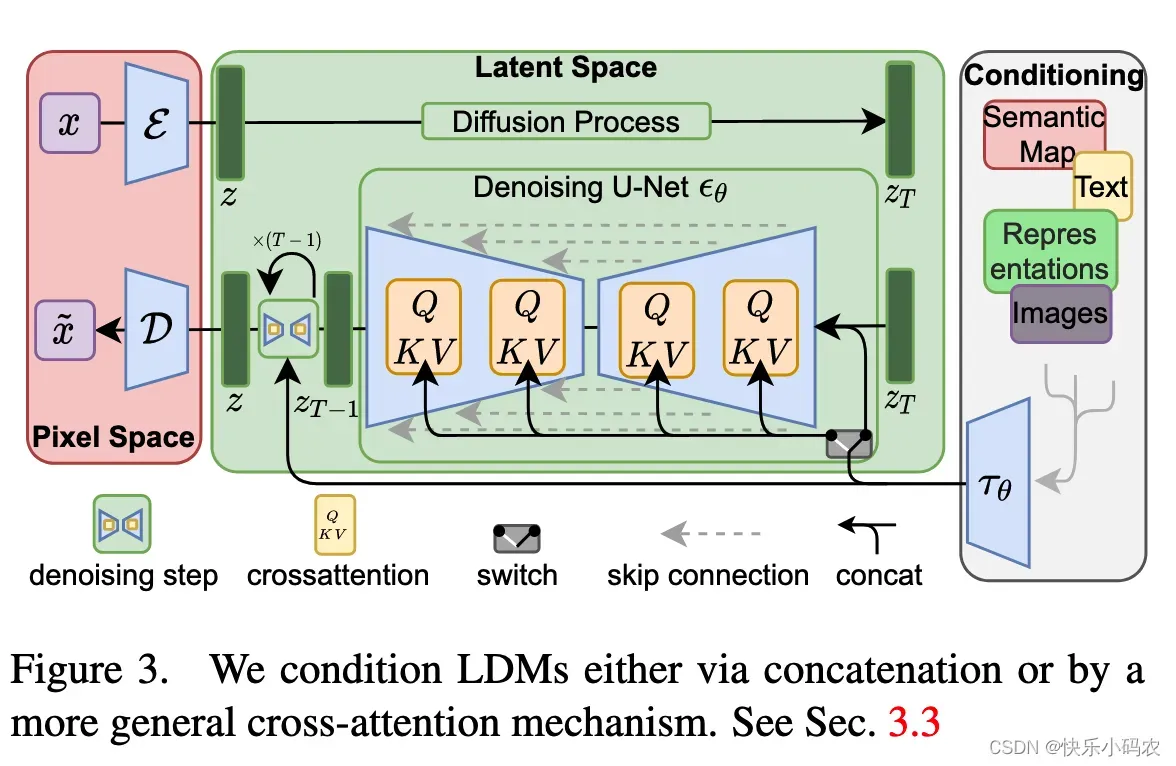
与其他模型相比,Stable Diffusion的主要区别在于使用了Latent Diffusion Models,通过在一个潜在表示空间中迭代“去噪”数据来生成图像,然后将表示结果解码为完整的图像,让文图生成能够在消费级GPU上,在10秒级别时间生成图片,大大降低了落地门槛,也带来了文图生成领域的大火。
Latent Diffusion Models整体框架如下图,首先需要训练好一个自编码模型(AutoEncoder),这样就可以利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后再用解码器恢复到原始像素空间即可,论文将这个方法称之为感知压缩(Perceptual Compression)。
Muse
谷歌发布的文本-图像生成模型 Muse,没有采用当下大火的扩散模型(diffusion model),而是采用了经典的 Transformer 模型就实现了最先进的图像生成性能,相比扩散或自回归(autoregressive)模型,Muse模型的效率也提升非常多。
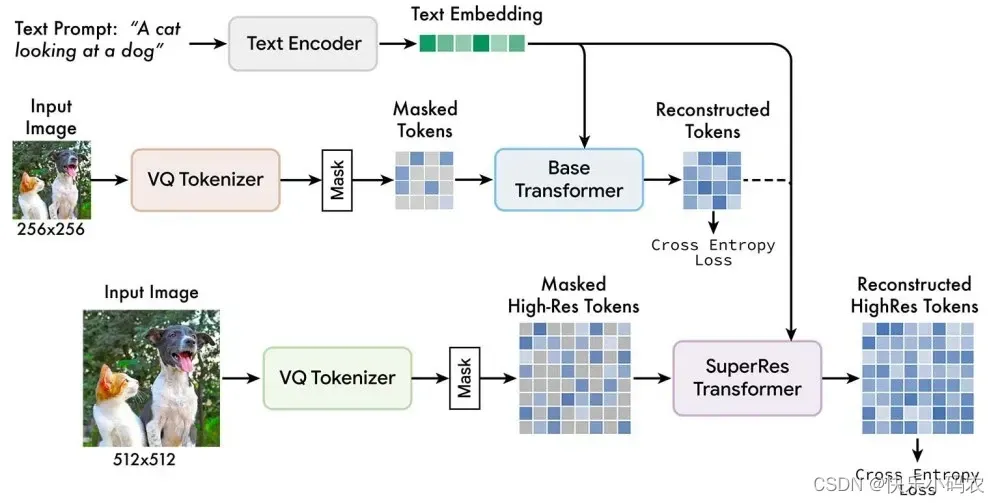
Muse 以 masked modeling 任务在离散token空间上进行训练:给定从预训练的大型语言模型(LLM)中提取的文本嵌入,Muse 的训练过程就是预测随机masked掉的图像token。
与像素空间的扩散模型(如Imagen和DALL-E 2)相比,由于 Muse 使用了离散的token,只需要较少的采样迭代,所以效率得到了明显提高。与Parti(一种自回归模型)相比,Muse由于并行解码而更有效。Muse在推断时间上比 Imagen-3B 或 Parti-3B 快10倍,比 Stable Diffusion v1.4 快3倍。
Muse模型的框架包含多个组件,训练pipeline由T5-XXL预训练文本编码器,基础模型(base model)和超分辨率模型组成,如下图所示。
Text-to-3D 模型
目前的文本图像生成模型如DALL-E 2, Imagen等仍然停留在二维创作(即图片),无法生成360度无死角的3D模型。想要直接训练一个text-to-3D的模型非常困难,因为DALL-E 2等模型的训练需要吞噬数十亿个图像-文本对,但三维合成并不存在如此大规模的标注数据,也没有一个高效的模型架构对3D数据进行降噪。
但是现在用2D数据训练出来的模型,也能生成3D图像了。只要输入简单的文本提示,就能生成具备具有密度、颜色等元素的3D模型。
Dreamfusion
DreamFusion 由Google Research开发,使用预先训练好的2D文本到图像的扩散模型来进行文本到3D的合成。具体地,DreamFusion 先使用一个预训练2D扩散模型基于文本提示生成一张二维图像,然后引入一个基于概率密度蒸馏的损失函数,通过梯度下降法优化一个随机初始化的神经辐射场NeRF模型。它用了一个新的损失计算方法来代替CLIP:通过文本到图像的Imagen扩散模型来计算损失。
训练后的模型可以在任意角度、任意光照条件、任意三维环境中基于给定的文本提示生成模型,整个过程既不需要3D训练数据,也无需修改图像扩散模型,完全依赖预训练扩散模型作为先验。

相比其他方法主要是对像素进行采样,在参数空间的采样比在像素空间的采样要难得多,DreamFusion使用了一个可微的生成器,专注于创建从随机角度渲染图像的三维模型。

Magic3D
Magic3D 是由英伟达公司开发的文本到3D模型。虽然 Dreamfusion 模型取得了显著的效果,但该方法存在两个问题:处理时间长和生成的图像质量低。然而,Magic3D 使用两阶段优化框架解决了这些问题。
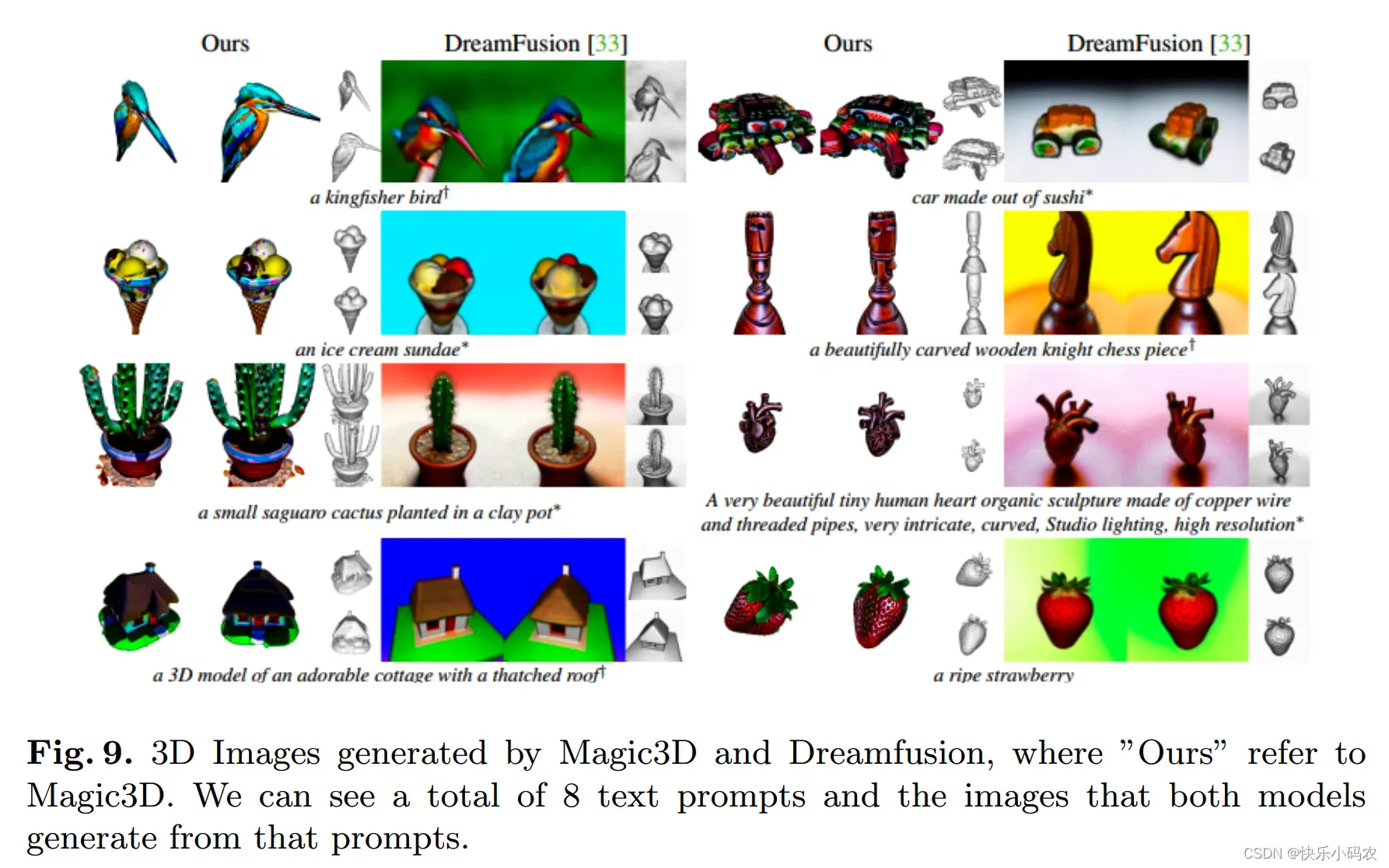
首先,Magic3D 构建了一个低分辨率的扩散先验,然后,它使用稀疏的3D哈希网格结构加速。使用这一点,纹理化的3D网格模型通过有效的可微渲染进一步优化。经过人类评估对比 Dreamfusion 和 Magic3D,Magic3D 模型取得了更好的结果,结果表示 61.7% 的人更喜欢 Magic3D 而不是DreamFusion。如下图9所示,与 DreamFusion 相比,Magic3D 在几何体和纹理方面实现了更高质量的3D形状。
请小伙伴们持续关注我的公众号「HsuDan」,我会继续更新这篇生成式AI模型综述《ChatGPT is not all you need. A State of the Art Review of large Generative AI models》中剩下的7大类模型:Image-to-Text 模型,Text-to-Video 模型,Text-to-Audio 模型,Text-to-Text 模型,Text-to-Code 模型,Text-to-Science 模型等。
欢迎各位关注我的个人公众号:HsuDan,我将分享更多自己的学习心得、避坑总结、面试经验、AI最新技术资讯。

版权声明:本文为博主作者:快乐小码农原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/u012744245/article/details/129049342