博主介绍
🌊 作者主页:苏州程序大白
🌊作者简介:🏆CSDN人工智能域优质创作者🥇,苏州市凯捷智能科技有限公司创始之一,目前合作公司富士康、歌尔等几家新能源公司
💬如果文章对你有帮助,欢迎关注、点赞、收藏(一键三连)和C#、Halcon、python+opencv、VUE、各大公司面试等一些订阅专栏哦
💅 有任何问题请私信,我们会及时回复
💅关注苏州节目大白,分享粉丝福利
自然语言处理概述
NLP 的定义
NLP(Nature Language Processing,自然语言处理)是计算机及人工智能领域的一个重要的子项目,它研究计算机如何处理、理解及应用人类语言。是人类在漫长的进化过程中形成的计算机语言复杂的符号等系统(类似C/Java的符号等系统)。以下是关于自然处理的常见定义:
- 语言处理是涉及计算机和人类语言翻译的科学和自然语言领域。
- 语言处理是人工智能领域的一个重要方向。它研究使用自然语言实现人与计算机之间有效操作的各种理论和方法。
- 语言处理研究这些方法在交际条件和交际条件下的语言问题,以及人类和计算机网络中的语言问题和语言问题。不断改进这些语言模型,根据系统的实用性和系统的实用性对技术进行评估。
自然语言处理还有一些其他的名称,如:自然语言(Natural Language Understanding)、计算机语言学(Computational Linguistics)、人类语言技术(Human Language Technology)等。
NLP的主要任务
NLP 可以分成两类,是生成主要基于新文本或语料的分析,另一种文本或语料。
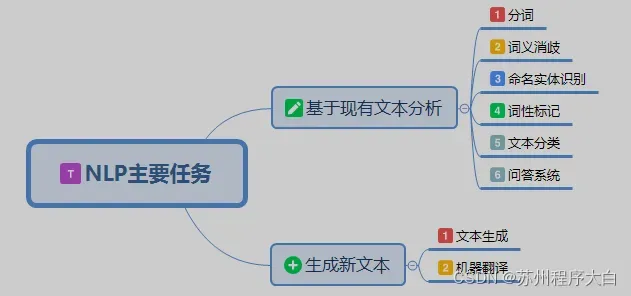
分词
此任务将文本或语言对分成更多的语言特征单元(单词)。对于拉丁语系统,单词和其他单词之间有重要的空格。对于中文来说,分词就是一个例子,它直接影响对文本的理解。
文本:苏州市姑苏区超市
分词1:苏州市/姑苏区/超市
分词2:苏州/市长/零食/店
词义消歧
例如,在“The dog barked at the mailman”(狗对邮递递员吠叫)和正确的树皮“用作药物”(树皮有时用作药物),用于不同的含义。词义消歧任务就是这样。
识别物体识别(NER)
NER尝试从给定的文本或文本语料库中提取实体(例如,人物、位置和组织)。例如,句子:
周一,约翰在学校给了玛丽两个苹果
将转换为:![]()
词性标注(PoS)
PoS 常用的两种称呼分别是名词、动词、形容词、词、词、词等、也可以是词性的词、词、词、动词、动词等。
文本分类
例如,文本分类、垃圾邮件检测、新闻文章分类(例如政治、技术和体育)和产品评论评分(即正面或负面)有很多应用场景。我们可以通过使用数据标记(即手动将评论标记为正面或负面)训练分类模型来做到这一点。
语言生成
可以利用 NLP 来生成新的文本或材料,编写机器天气预报(天气预报、新闻、例如唐诗等),生成文本是一段机器合成的“下面的诗”:
向塞向芶芶临扇,猛牒来惊。向面炎交好
,若隚。
何人改,松仙绕绮霞。偶笑寒栖咽,长闻暖顶时。
失个亦垂谏,守身丈韦鸿。忆及他年事,应愁一故名。
坐忆山高道,为随夏郭间。到乱唯无己,千方得命赊。
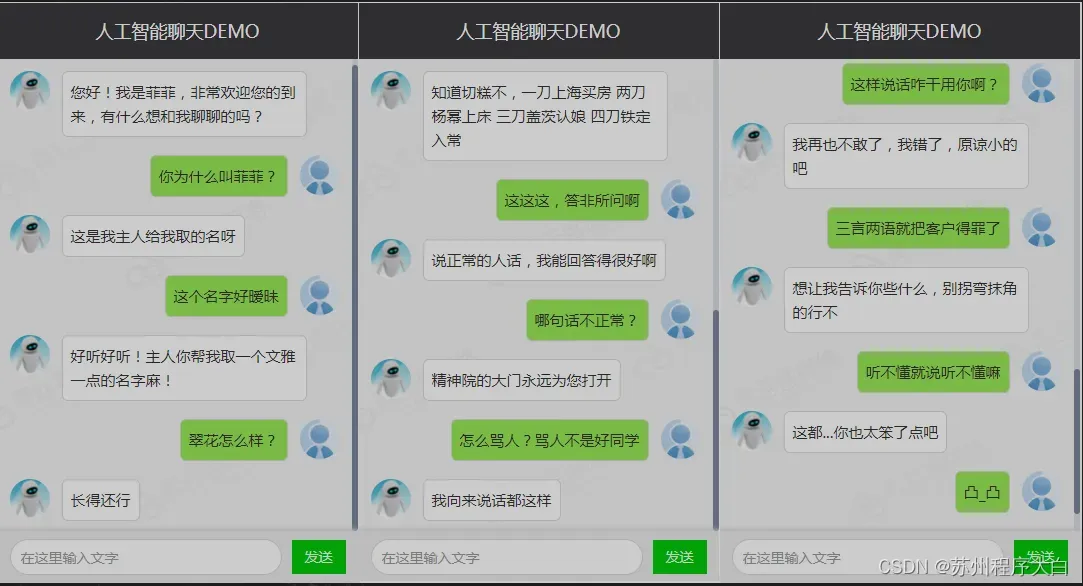
问答(QA)系统
QA 技术具有广泛的商业价值,这些技术是聊天机器人和 VA(例如,Google Assistant 和 Apple Siri)的支持。许多公司已经采用对话机器人来提供客户。以下是一段与聊天机器人的:
机器翻译(MT)
机器翻译,MT)指将文本由一种语言翻译成另一种语言,是根据一个序列(机器翻译最接近的另一种语言生成)。

NLP的发展历程
NLP的发展发展为:基于规则→其基于统计→基于深入学习,发展大致经历了4个阶段:1956年的萌芽期;1957年1970年的快速期;1971年1993年的低速期;1994年现在的复苏融合期。
- 萌芽期(1956年前)
- 1946年:第一台电子计算机诞生
- 148 年香农 把 离散 商业 年: 描述 于 马尔 可 的 机 器 。
- 156 年:Chomsky 又提出了当时的自然语言,并将其运用到处理中。
快速发展期(1957~1970)
一个时期是在不同的处理领域中存在的自然规律和基于两种不同的处理方式。基于这种方法的符号(象征性的)另一派(每个派别)。期间,方法派的研究取得了从60年代开始到长足的发展。乔姆斯基为代表的象征派学者开始了语言理论和生成句法的研究,60年代进行了叶逻辑形式的研究。也取得了很大的进步。
1997 年 TDAP 期重要的美国语言研究成果,美国的语言系统的建立与等。知联系起来了。
低速发展期(1971~1993)
语言研究的结果由于人们看到基于自然语言处理的应用并不能在地段中不断涌现解决,而一连的新问题又出现了,于是,很多人对随着语言处理的研究失去了自然的信心。 70 年代开始,自然语言处理在自然低谷时期。
尽管如此,一些研究人员仍然继续进入了他们的研究。由于他们的出色工作,自然语言处理这一低谷时期同样取得了一些成果。70当年,基于隐马尔可夫模型,HMM的马尔可夫模型(Hidden Markov Model,HMM的马尔可夫模型)统计了最初在语音领域取得重大进展,话语分析(话语分析)也取得了。过去的研究方法进行了反思,有限状态模型和经验主义研究也开始复苏。
复苏融合期(1994年至今)
90年代以后,有两台计算机从根本上发展到促进语言的自然复苏与研究。一件事是90年代以来,计算机的速度和测量量自然增加,为语言处理改善了物质基础,处理事件的事件; 19 可能化是互联网化和网络化 2000 年的另一种商业活动 4 年基于语言的信息和语言的信息和成为自然语言的 00 话题的热门话题。之后 NLP 领域的里程碑事件:
- 2001年:神经语言模型
- 2008年:多任务学习
- 2013年:词嵌入
- 2013年:NLP的神经网络
- 2014年:序列到序列模型
- 2015年:纪律机制
- 2015年:根据记忆的神经网络
- 2018年:预训练语言模型
NLP的困难与挑战
语言歧义
- 不同分词引起的歧义:
例:自动化研究所取得的成就
一:自动化/研究/所/取得/的/成就
成就二:自动化/研究所/取得/的/成就
- 词性歧义:
动物保护警察
“保护”理解为动词和名词,两者是不同的。
- 结构差异:
喜欢乡下的孩子
关于鲁迅的文章
- 笑声:
节假日期间,所有博物馆全部(不)开放
- 不同语言结构的区别:

- 未知语言的不可预测性:
语言不断出现,每年都有大量的新词、出现材料,给一些 NLP 任务造成了困难。以下是 2022 年网络上的新词:
双减
元 宇宙
绝绝子
平躺
- 语言表达的复杂性:
甲:你这人真正的英文?甲:没有英文,英文
?那我就不好意思了。
- 机器语言处理 广泛的背景和常识
中国队最有悬念的是全世界有一个女人也有她和她,他们一个谁也有谁干过球,不过,另一个人打
如果希拉里干过球,只是因为美国总统和美国总统的努力,克林顿也将成为全世界唯一一个干过美国总统和干过美国总统的男人
NLP相关知识构成
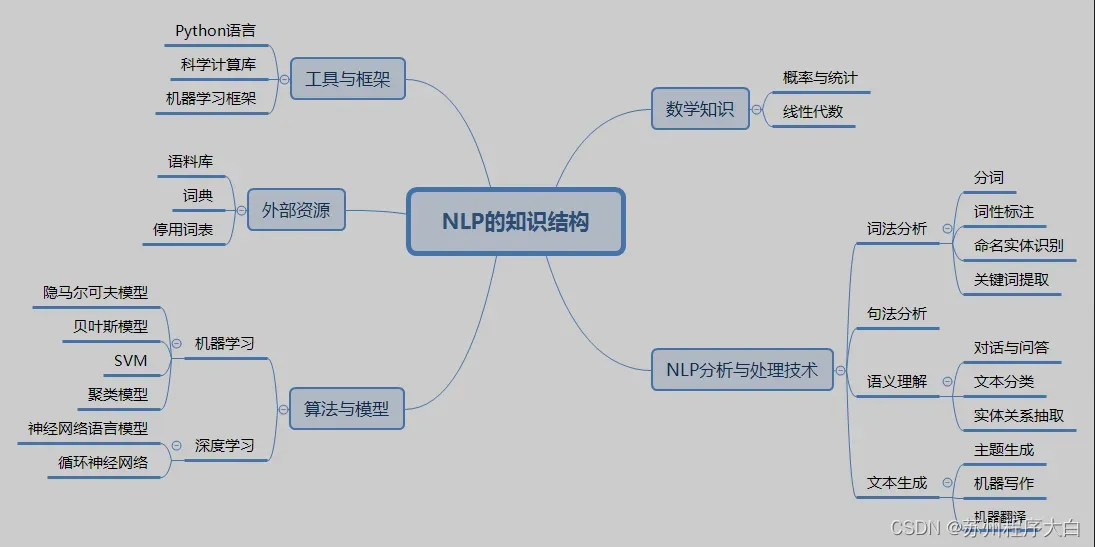
语料库
什么是语料库
语料库是指语言材料(材料库的我们)。现代语料库是指放置在原始语料库中或带有文字注释的文本文本。 ,语言反应单元的用途和意义,基本上是以知识的形式——语言的本来面目。
语料库的特点
- 语料库存储在现实世界中出现过的材料。
- 语料库是计算机承载语言知识的资源,是语言知识的资源。
- 真实的语料库需要经过分析、处理和处理才能成为有用的资源。
语料库的作用
- 支持语言学和语言教学研究。
- 支持 NLP 系统的开发。
通用语料库介绍
北京大学计算机语言所语料库(中文),地址: https://opendata.pku.edu.cn/dataverse/icl
London-Lund 英语口语语料库,地址:http 😕/www.helsinki.fi/varieng/CoRD/copora.LLC/
腾讯中文语每包含800个万个单词。其中每一个词都满足2200个维的库,包括最新的一期新词。采用了一个更先进的工具预测的数据和更好的。
维基百科是编辑和最常用的开放网络数据集之一,作为最常用的材料、内容、格式的文本语言,各种语言的维基百科在 NLP 中广泛应用。
传统NLP处理技术
中文分词
中文分词是一项重要的基础任务,对文本分词的统计有着重要而直接的影响,对分词规则有一定的了解。分词主要是基于分词和分词。基于分词,主要是通过语句的维护。切分时,将语句的每个子串与表中的单词匹配进行切分,若缺失则不切分;根据统计找到的分词是基于统计规则和语言模型。输出一个特征最大分词(因为需要的知识还没有讲解,暂时不讨论);混合分词是混合使用各种分词方法,从而提高分词的准确率。以下是按照介绍规则分词的顺序。
前向最大匹配
正向最大匹配法(Forward Maximum Matching,FMM)是按照从前到后的顺序对语句进行分段。步骤是:
- 从左向右取字待分汉语句的m个作为匹配字段,m为词典中词的最长长度;
- 查找字典匹配;
- 如果成功,则将其分割为匹配词;
- 如果不成功,则调度一个单词,其余单词将作为新匹配;
- 重复上述过程,直到所有单词都被切分完毕。
逆最大匹配
逆向最大匹配法(Reverse Maximum Matching,RMM)基本原理与FMM基本相同,不同分的方向开始与是相反。RMM是从待分词的右开始,也就是从向左匹配扫描句子,这时句子取m个字作为匹配的地方,找不到匹配的地方,则把前面的一个字,继续匹配。
最大匹配法
对于最大法线匹配,Bi-MM(Bi-MM)方向匹配最大匹配法线结果的正向。最匹配规则的反向匹配规则为:
- 如果是肯定的,则相反,取词数较少的一个,分词结果的个数不同;
- 分词结果的结果没有不同的含义;在分词中,返回不同的词,返回不同的主题。
前向最大匹配标记化
# 正向最大匹配分词示例
class MM ( object ): def __init__ ( self ): self.window_size = 3
def cut ( self, text ):
result [文本分词结果
= 0 # 文本长度 = 文本位置
( text_len =) # 长度
dic = [ "苏州" , "苏州市" , "姑苏" , "苏锦" , "零食" , "超市" ]
while text_len start: for size in range (self.window_size + start, start, - 1 )
#取最大长度,逐步比较
piece = text[start:size]
#ifpiece in dic:
#在字典中
result.append(piece)
# 添加到列表
start += len (piece) break else :
#没在字典中,什么都不做
if len (piece) == 1 :
result.append(piece)
# 结果字成词 开始
+= len(片)
break
result.reverse()
返回结果
if __name__ == "__main__":
text = "苏州市苏锦超市"
tk = MM() # 实例化对象
result = tk.cut(text)
print(result)
结果:
[ '苏州市', '苏锦', '超市']
反向最大匹配标记化
# 逆向最大匹配分词示例
class RMM(object):
def __init__(self):
self.window_size = 3
def cut(self, text):
result = [] # 分词结果
start = len(text) # 起始位置
text_len = len(text) # 文本长度
dic = ["苏州", "苏州市", "姑苏", "苏锦", "零食", "超市"]
while start > 0:
for size in range(self.window_size, 0, -1):
piece = text[start-size:start] # 切片
if piece in dic: # 在字典中
result.append(piece) # 添加到列表
start -= len(piece)
break
else: # 没在字典中
if len(piece) == 1:
result.append(piece) # 单个字成词
start -= len(piece)
break
result.reverse()
return result
if __name__ == "__main__":
text = "苏州市姑苏超市"
tk = RMM() # 实例化对象
result = tk.cut(text)
print(result)
结果:
[ '苏州', '苏锦', '超市']
Jieba库分词
Jieba 是一款很简单的功能、功能、使用的中文分词工具库,它提供了分词模式:
- Sentence Rational Text Mode:这个词最有道理,最适合分析。
- 全文:划分丹中词的所有词组,速度快,有重复的词型和歧义。
- 搜索引擎模式:在合理模式的基础上,对长词进行再分词,提高性能,适用于搜索引擎的分词。
使用 Jieba 库之前,需要进行安装:
pip install jieba== 0.42 . 1
分词代码如下:
# jieba分词示例
import jieba
text = "吉林市长春药店"
# 全模式
seg_list = jieba.cut(text, cut_all=True)
for word in seg_list:
print(word, end="/")
print()
# 精确模式
seg_list = jieba.cut(text, cut_all=False)
for word in seg_list:
print(word, end="/")
print()
# 搜索引擎模式
seg_list = jieba.cut_for_search(text)
for word in seg_list:
print(word, end="/")
print()
结果:
苏州/苏州市/姑苏/苏锦/零食/超市/
苏州市/姑苏/超市/
苏州/苏州市/姑苏/超市/
文字高频消费
# 通过tf-idf提取高频词汇
import glob
import random
import jieba
# 读取文件内容
def get_content(path):
with open(path, "r", encoding="gbk", errors="ignore") as f:
content = ""
for line in f.readlines():
line = line.strip()
content += line
return content
# 统计词频,返回最高前10位词频列表
def get_tf(words, topk=10):
tf_dict = {}
for w in words:
if w not in tf_dict.items():
tf_dict[w] = tf_dict.get(w, 0) + 1 # 获取词频并加1
# 倒序排列
new_list = sorted(tf_dict.items(), key=lambda x: x[1], reverse=True)
return new_list[:topk]
# 去除停用词
def get_stop_words(path):
with open(path, encoding="utf8") as f:
return [line.strip() for line in f.readlines()]
if __name__ == "__main__":
# 样本文件
fname = "d:\\NLP_DATA\\chap_3\\news\\C000008\\11.txt"
# 读取文件内容
corpus = get_content(fname)
# 分词
tmp_list = list(jieba.cut(corpus))
# 去除停用词
stop_words = get_stop_words("d:\\NLP_DATA\\chap_3\\stop_words.utf8")
split_words = []
for tmp in tmp_list:
if tmp not in stop_words:
split_words.append(tmp)
# print("样本:\n", corpus)
print("\n 分词结果: \n" + "/".join(split_words))
# 统计高频词
tf_list = get_tf(split_words)
print("\n top10词 \n:", str(tf_list))
结果:
分词结果:
焦点/个股/苏宁/电器/002024/该股/早市/涨停/开盘/其后/获利盘/抛/压下/略有/回落/强大/买盘/推动/下该/股/已经/再次/封于/涨停/主力/资金/积极/拉升/意愿/相当/强烈/盘面/解析/技术/层面/早市/指数/小幅/探低/迅速/回升/中石化/强势/上扬/带动/指数/已经/成功/翻红/多头/实力/之强/令人/瞠目结舌/市场/高度/繁荣/情形/投资者/需谨慎/操作/必竟/持续/上攻/已经/消耗/大量/多头/动能/盘中/热点/来看/相比/周二/略有/退温/依然/看到/目前/热点/效应/外扩散/迹象/相当/明显/高度/活跌/板块/已经/前期/有色金属/金融/地产股/向外/扩大/军工/概念/航天航空/操作/思路/短线/依然/需/规避/一下/技术性/回调/风险/盘中/切记/不可/追高
top10词:
[('已经', 4), ('早市', 2), ('涨停', 2), ('略有', 2), ('相当', 2), ('指数', 2), ('多头', 2), ('高度', 2), ('操作', 2), ('盘中', 2)]
top10词:
[( '已经' , 4 ), ( '指数' , 2 ), ( '涨停' , 2 ) , ('突然' , 2 ), ( '相当' , 2 ), ( '指数' , 2 ), ( '多头' , 2 ), ( '高度' , 2 ), ( '操作' , 2 ), ( '盘中' , 2 )]
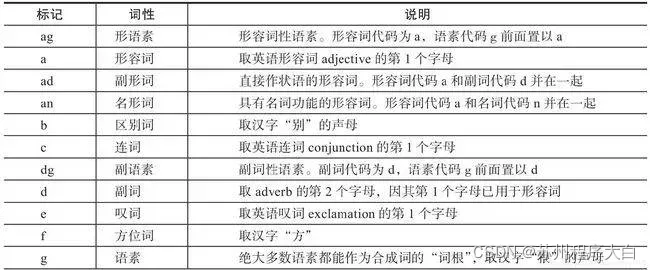
词性标注
什么是词性标注
词性是词性的语法,通常也称为词性。词性标记是识别给定文本中各种词性的属性。不同环境中的不同词性词性是词性的基本特征,即词性标注的基本词性。来之不易。
词性标注的原理
词性标注生成方法将输入的相同分词序列视为序列生成。
词性标注
有一定的标注规范,如将名词、标注、动词表示为“n”、“adj”、“v”等词性。以下是北大词性标注部分词性表示:
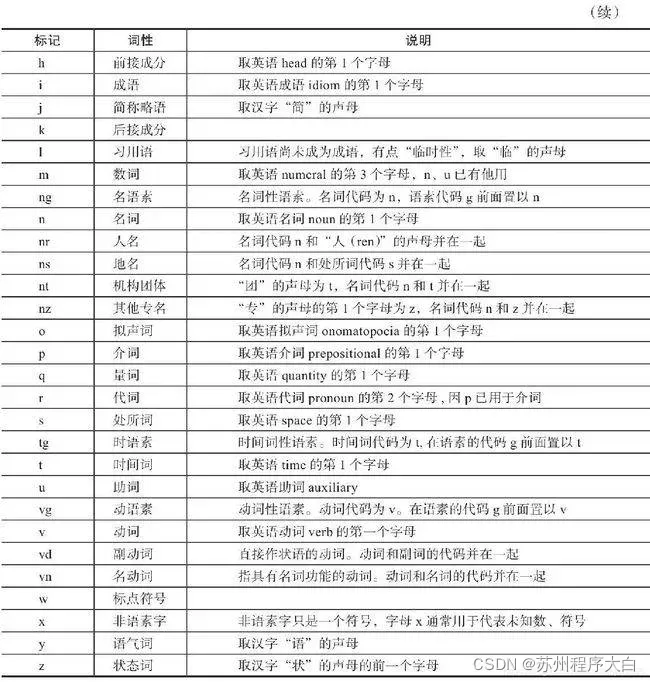
jieba 库词性标注
Jieba 库提供了词性标注功能,采用结合规则和统计的方式,具体为在词性标注的过程中,词典匹配和 HMM 共同作用。词性标注流程如下:
第一步:根据正则表达式判断文本是否为汉字;
第二步:如果判断为汉字,构建 HMM 模型计算最大概率,在词典中查找分出的词性,若在词典中未找到,则标记为 “未知”;
第三步:如果上面的正则表达式不正确,继续通过正则表达式判断,分别赋值“unknown”、“numerical”或“English”。
Jieba 库实现词性标注代码实现
import jieba.posseg as psg
def pos(text):
results = psg.cut(text)
for w, t in results:
print("%s/%s" % (w, t), end=" ")
print("")
text = "呼伦贝尔大草原"
pos(text)
text = "梅兰芳大剧院里星期六晚上有演出"
pos(text)
运行结果:
呼伦贝尔/nr 大/a 草原/n
梅兰芳/nr 大/a 剧院/n 里/f 星期六/t 晚上/t 有/v 演出/v
命名实体识别(NER)
命名实体识别(Named Entities Recognition,NER)也是自然语言处理的一个基础任务,是信息抽取、信息检索、机器翻译、问答系统等多种自然语言处理技术必不可少的组成部分。其目的是识别语料中人名、地名、组织机构名等命名实体,实体类型包括 3 大类(实体类、时间类和数字类)和 7 小类(人名、地名、组织机构名、时间、日期、货币和百分比)。中文命名实体识别主要有以下难点:
1、各类命名实体的数量众多。
2、命名实体的构成规律复杂。
3、嵌套情况复杂。
4、长度不确定。
命名实体识别方法有:
1、基于规则的命名实体识别。规则加词典是早期命名实体识别中最行之有效的方式。其依赖手工规则的系统,结合命名实体库,对每条规则进行权重赋值,然后通过实体与规则的相符情况来进行类型判断。这种方式可移植性差、更新维护困难等问题。
2、基于统计的命名实体识别。基于统计的命名实体识别方法有:隐马尔可夫模型、最大熵模型、条件随机场等。其主要思想是基于人工标注的语料,将命名实体识别任务作为序列标注问题来解决。基于统计的方法对语料库的依赖比较大,而可以用来建设和评估命名实体识别系统的大规模通用语料库又比较少,这是该方法的一大制约。
3、基于深度学习的方法。利用深度学习模型,预测词(或字)是否为命名实体,并预测出起始、结束位置。
4、混合方法。将前面介绍的方法混合使用。
命名实体识别有一个特殊情况需要在深度学习部分讨论和演示。
关键词提取
关键词抽取是抽取代表文章重要内容的一组词,在文本聚类、分类、自动摘要中起到重要作用。此外,关键词提取使人们能够方便地浏览和获取信息。现实中大量文本不包含关键词,自动提取关键检测技术具有重要意义和价值。关键词提取包括监督学习和无监督学习方法。
有监督关键词提取。该方法主要是通过分类进行,通过构建一个比较丰富完整的词汇表,然后通过判断每个文档和词汇表中每个词的匹配度,以类似标注的方式,达到关键词提取的效果。这种方法可以获得较高的准确率,但需要标注大量样本,人工成本太高。另外,每天都会出现大量的新信息,固定的词汇很难表达新信息的内容,而人工实时维护词汇的成本太高。因此,监督学习关键词提取方法存在明显缺陷。
无监督关键词提取。相对于有监督关键词提取,无监督方法对数据要求低得多,既不需要人工维护词表,也不需要人工标注语料辅助训练。因此,在实际应用中更受青睐。这里主要介绍无监督关键词提取算法,包括 TF-IDF 算法,TextRank 算法和主题模型算法。
TF-IDF 算法
TF-IDF(Term Frequency-Inverse Document Frequency,词频 - 逆文档频率)是一种基于传统的统计计算方法,常用于评估一个文档集中一个词对某份文档的重要程度。其基本思想是:一个词语在文档中出现的次数越多、出现的文档越少,语义贡献度越大(对文档区分能力越强)。TF-IDF 表达式由两部分构成,词频、逆文档频率。词频定义为:
其中,表示词语 i 在文档 j 中出现的次数,分母
表示所有文档总次数。逆文档频率定义为:
其中,为文档总数,
为文档中出现词 i 的文档数量,分母加 1 是避免分母为 0 的情况(称为拉普拉斯平滑),TF-IDF 算法是将 TF 和 IDF 综合使用,表达式为:
由公式可知,词频越大,该值越大;出现的文档数越多(说明该词越通用),逆文档频率越接近 0,语义贡献度越低。例如有以下文本:
世界献血日,学校团体、献血服务志愿者等可到血液中心参观检验加工过程,我们会对检验结果进行公示,同时血液的价格也将进行公示。
以上文本词语总数为 30,计算几个词的词频:

假设出现献血、血液、进行、公示文档数量分别为 10、15、100、50,根据 TF-IDF 计算公式,得:

“献血”、“血液” 的 TF-IDF 值最高,所以为最适合这篇文档的关键词。
TextRank 算法
与TF-IDF不一样,TextRank 算法可以脱离于语料库,仅对单篇文档进行分析就可以提取该文档的关键词,这也是TextRank 算法的一个重要特点。TextRank 算法最早用于文档的自动摘要,基于句子维度的分析,利用算法对每个句子进行打分,挑选出分数最高的 n 个句子作为文档的关键句,以达到自动摘要的效果。
TextRank 算法的基本思想来源于Google的PageRank 算法,该算法是 Google 创始人拉里・佩奇和希尔盖・布林于 1997 年构建早期的搜索系统原型时提出的链接分析法,用于评价搜索系统各覆盖网页重要性的一种方法。随着 Google 的成功,该算法也称为其它搜索引擎和学术界十分关注的计算模型。
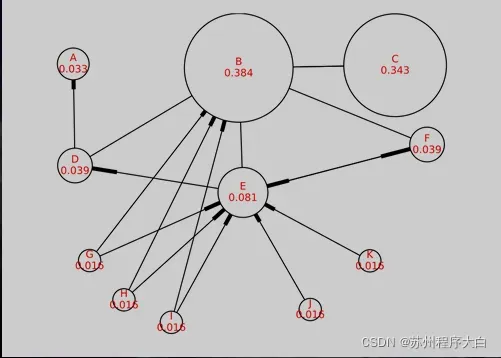
PageRank 基本思想有两条:
- 链接数。一个页面链接到的页面越多,该页面就越重要。
- 链接质量。网页由权重较高的网页链接,也可以表示该网页更重要。
基于上述思想,一个网页的 PageRank 计算公式可以表示为:
其中,为
的入链集合,
为
的出链集合,
为出链的数量。因为每个网页要将它自身的分数平均贡献给每个出链,则
即为
贡献给
的分数。将所有入链贡献给它的分数全部加起来,就是
自身的得分。算法开始时,将所有页面的得分均初始化为 1。
对于一些孤立页面,可能链入、链出的页面数量为 0,为了避免这种情况,对公式进行了改造,加入了一个阻尼系数,这样,即使孤立页面也有一个得分。改造后的公式如下:
以上就是 PageRank 的理论,也是 TextRank 的理论基础,不同于的是 TextRank 不需要与文档中的所有词进行链接,而是采用一个窗口大小,在窗口中的词互相都有链接关系。例如对下面的文本进行窗口划分:
世界献血日,学校团体、献血服务志愿者等可到血液中心参观检验加工过程,我们会对检验结果进行公示,同时血液的价格也将进行公示。
如果将窗口大小设置为 5,则可得到如下计算窗口:
[世界,献血,日,学校,团体]
[献血,日,学校,团体,献血]
[日,学校,团体,献血,服务]
[学校,团体,献血,服务,志愿者]
……
每个窗口内所有词之间都有链接关系,如 [世界] 和 [献血,日,学校,团体] 之间有链接关系。得到了链接关系,就可以套用 TextRank 公式,计算每个词的得分,最后选择得分最高的 N 个词作为文档的关键词。
关键字提取示例
本案例演示了通过自定义TF-IDF并调用TextRank API来提取关键字:
# -*- coding: utf-8 -*-
import math
import jieba
import jieba.posseg as psg
from gensim import corpora, models
from jieba import analyse
import functools
import numpy as np
# 停用词表加载方法
def get_stopword_list():
# 停用词表存储路径,每一行为一个词,按行读取进行加载
# 进行编码转换确保匹配准确率
stop_word_path = '../data/stopword.txt'
with open(stop_word_path, "r", encoding="utf-8") as f:
lines = f.readlines()
stopword_list = [sw.replace('\n', '') for sw in lines]
return stopword_list
# 去除停用词
def word_filter(seg_list):
filter_list = []
for word in seg_list:
# 过滤停用词表中的词,以及长度为<2的词
if not word in stopword_list and len(word) > 1:
filter_list.append(word)
return filter_list
# 数据加载,pos为是否词性标注的参数,corpus_path为数据集路径
def load_data(corpus_path):
# 调用上面方式对数据集进行处理,处理后的每条数据仅保留非干扰词
doc_list = []
for line in open(corpus_path, 'r', encoding='utf-8'): # 循环读取一行(一行即一个文档)
content = line.strip() # 去空格
seg_list = jieba.cut(content) # 分词
filter_list = word_filter(seg_list) # 去除停用词
doc_list.append(filter_list) # 将分词后的内容添加到列表
return doc_list
# idf值统计方法
def train_idf(doc_list):
idf_dic = {}
tt_count = len(doc_list) # 总文档数
# 每个词出现的文档数
for doc in doc_list:
doc_set = set(doc) # 将词推入集合去重
for word in doc_set: # 词语在文档中
idf_dic[word] = idf_dic.get(word, 0.0) + 1.0 # 文档数加1
# 按公式转换为idf值,分母加1进行平滑处理
for word, doc_cnt in idf_dic.items():
idf_dic[word] = math.log(tt_count / (1.0 + doc_cnt))
# 对于没有在字典中的词,默认其仅在一个文档出现,得到默认idf值
default_idf = math.log(tt_count / (1.0))
return idf_dic, default_idf
# TF-IDF类
class TfIdf(object):
def __init__(self, idf_dic, default_idf, word_list, keyword_num):
"""
TfIdf类构造方法
:param idf_dic: 训练好的idf字典
:param default_idf: 默认idf值
:param word_list: 待提取文本
:param keyword_num: 关键词数量
"""
self.word_list = word_list
self.idf_dic, self.default_idf = idf_dic, default_idf # 逆文档频率
self.tf_dic = self.get_tf_dic() # 词频
self.keyword_num = keyword_num
# 统计tf值
def get_tf_dic(self):
tf_dic = {} # 词频字典
for word in self.word_list:
tf_dic[word] = tf_dic.get(word, 0.0) + 1.0
total = len(self.word_list) # 词语总数
for word, word_cnt in tf_dic.items():
tf_dic[word] = float(word_cnt) / total
return tf_dic
# 按公式计算tf-idf
def get_tfidf(self):
tfidf_dic = {}
for word in self.word_list:
idf = self.idf_dic.get(word, self.default_idf)
tf = self.tf_dic.get(word, 0)
tfidf = tf * idf # 计算TF-IDF
tfidf_dic[word] = tfidf
# 根据tf-idf排序,去排名前keyword_num的词作为关键词
s_list = sorted(tfidf_dic.items(), key=lambda x: x[1], reverse=True)
# print(s_list)
top_list = s_list[:self.keyword_num] # 切出前N个
for k, v in top_list:
print(k + ", ", end='')
print()
def tfidf_extract(word_list, keyword_num=20):
doc_list = load_data('../data/corpus.txt') # 读取文件内容
# print(doc_list)
idf_dic, default_idf = train_idf(doc_list) # 计算逆文档频率
tfidf_model = TfIdf(idf_dic, default_idf, word_list, keyword_num)
tfidf_model.get_tfidf()
def textrank_extract(text, keyword_num=20):
keywords = analyse.textrank(text, keyword_num)
# 输出抽取出的关键词
for keyword in keywords:
print(keyword + ", ", end='')
print()
if __name__ == '__main__':
global stopword_list
text = """在中国共产党百年华诞的重要时刻,在“两个一百年”奋斗目标历史交汇关键节点,
党的十九届六中全会的召开具有重大历史意义。全会审议通过的《决议》全面系统总结了党的百年奋斗
重大成就和历史经验,特别是着重阐释了党的十八大以来党和国家事业取得的历史性成就、发生的历史性变革,
充分彰显了中国共产党的历史自觉与历史自信。"""
stopword_list = get_stopword_list()
seg_list = jieba.cut(text) # 分词
filter_list = word_filter(seg_list)
# TF-IDF提取关键词
print('TF-IDF模型结果:')
tfidf_extract(filter_list)
# TextRank提取关键词
print('TextRank模型结果:')
textrank_extract(text)
运行结果:
TF-IDF模型结果:
历史, 中国共产党, 百年, 历史性, 华诞, 一百年, 奋斗目标, 交汇, 节点, 十九, 六中全会, 全会, 奋斗, 重大成就, 着重, 阐释, 十八, 党和国家, 成就, 变革,
TextRank模型结果:
历史, 历史性, 意义, 成就, 决议, 审议, 发生, 系统, 总结, 全面, 节点, 关键, 交汇, 召开, 具有, 全会, 取得, 事业, 自信, 变革,
综合案例
垃圾邮件分类
- 数据集介绍:包含 5000 份正常邮件、5001 份垃圾邮件的样本
- 文本特征处理方式:采用 TF-IDF 作为文本特征值
- 模型选择:朴素贝叶斯、SVM模型
- 基本流程:读取数据 → 去除停用词和特殊符号 → 计算 TF-IDF 特征值 → 模型训练 → 预测 → 打印结果
# -*- coding: utf-8 -*-
# 利用TF-IDF特征、朴素贝叶斯/支持向量机实现垃圾邮件分类
import numpy as np
import re
import string
import sklearn.model_selection as ms
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import SGDClassifier
from sklearn import metrics
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
label_name_map = ["垃圾邮件", "正常邮件"]
# 分词
def tokenize_text(text):
tokens = jieba.cut(text) # 分词
tokens = [token.strip() for token in tokens] # 去空格
return tokens
def remove_special_characters(text):
tokens = tokenize_text(text)
# escape函数对字符进行转义处理
# compile函数用于编译正则表达式,生成一个 Pattern 对象
pattern = re.compile('[{}]'.format(re.escape(string.punctuation)))
# filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表
# sub函数进行正则匹配字符串替换
filtered_tokens = filter(None, [pattern.sub('', token) for token in tokens])
filtered_text = ' '.join(filtered_tokens)
return filtered_text
# 去除停用词
def remove_stopwords(text):
tokens = tokenize_text(text) # 分词、去空格
filtered_tokens = [token for token in tokens if token not in stopword_list] # 去除停用词
filtered_text = ''.join(filtered_tokens)
return filtered_text
# 规范化处理
def normalize_corpus(corpus):
result = [] # 处理结果
for text in corpus: # 遍历每个词汇
text = remove_special_characters(text) # 去除标点符号
text = remove_stopwords(text) # 去除停用词
result.append(text)
return result
def tfidf_extractor(corpus):
vectorizer = TfidfVectorizer(min_df=1,
norm='l2',
smooth_idf=True,
use_idf=True)
features = vectorizer.fit_transform(corpus)
return vectorizer, features
def get_data():
'''
获取数据
:return: 文本数据,对应的labels
'''
corpus = [] # 邮件内容
labels = [] # 标签(0-垃圾邮件 1-正常邮件)
# 正常邮件
with open("data/ham_data.txt", encoding="utf8") as f:
for line in f.readlines():
corpus.append(line)
labels.append(1)
# 垃圾邮件
with open("data/spam_data.txt", encoding="utf8") as f:
for line in f.readlines():
corpus.append(line)
labels.append(0)
return corpus, labels
# 过滤空文档
def remove_empty_docs(corpus, labels):
filtered_corpus = []
filtered_labels = []
for doc, label in zip(corpus, labels):
if doc.strip():
filtered_corpus.append(doc)
filtered_labels.append(label)
return filtered_corpus, filtered_labels
# 计算并打印分类指标
def print_metrics(true_labels, predicted_labels):
# Accuracy
accuracy = metrics.accuracy_score(true_labels, predicted_labels)
# Precision
precision = metrics.precision_score(true_labels,
predicted_labels,
average='weighted')
# Recall
recall = metrics.recall_score(true_labels,
predicted_labels,
average='weighted')
# F1
f1 = metrics.f1_score(true_labels,
predicted_labels,
average='weighted')
print("正确率: %.2f, 查准率: %.2f, 召回率: %.2f, F1: %.2f" % (accuracy, precision, recall, f1))
if __name__ == "__main__":
global stopword_list
# 读取停用词
with open("dict/stop_words.utf8", encoding="utf8") as f:
stopword_list = f.readlines()
corpus, labels = get_data() # 加载数据
corpus, labels = remove_empty_docs(corpus, labels)
print("总的数据量:", len(labels))
# 打印前N个样本
for i in range(10):
print("label:", labels[i], " 邮件内容:", corpus[i])
# 对数据进行划分
train_corpus, test_corpus, train_labels, test_labels = \
ms.train_test_split(corpus,
labels,
test_size=0.10,
random_state=36)
# 规范化处理
norm_train_corpus = normalize_corpus(train_corpus)
norm_test_corpus = normalize_corpus(test_corpus)
# tfidf 特征
## 先计算tf-idf
tfidf_vectorizer, tfidf_train_features = tfidf_extractor(norm_train_corpus)
## 再用刚刚训练的tf-idf模型计算测试集tf-idf
tfidf_test_features = tfidf_vectorizer.transform(norm_test_corpus)
# print(tfidf_test_features)
# print(tfidf_test_features)
# 基于tfidf的多项式朴素贝叶斯模型
print("基于tfidf的贝叶斯模型")
nb_model = MultinomialNB() # 多分类朴素贝叶斯模型
nb_model.fit(tfidf_train_features, train_labels) # 训练
mnb_pred = nb_model.predict(tfidf_test_features) # 预测
print_metrics(true_labels=test_labels, predicted_labels=mnb_pred) # 打印测试集下的分类指标
print("")
# 基于tfidf的支持向量机模型
print("基于tfidf的支持向量机模型")
svm_model = SGDClassifier()
svm_model.fit(tfidf_train_features, train_labels) # 训练
svm_pred = svm_model.predict(tfidf_test_features) # 预测
print_metrics(true_labels=test_labels, predicted_labels=svm_pred) # 打印测试集下的分类指标
print("")
# 打印测试结果
num = 0
for text, label, pred_lbl in zip(test_corpus, test_labels, svm_pred):
print('真实类别:', label_name_map[int(label)], ' 预测结果:', label_name_map[int(pred_lbl)])
print('邮件内容【', text.replace("\n", ""), '】')
print("")
num += 1
if num == 10:
break
运行结果:
基于tfidf的贝叶斯模型
正确率: 0.97, 查准率: 0.97, 召回率: 0.97, F1: 0.97
基于tfidf的支持向量机模型
正确率: 0.98, 查准率: 0.98, 召回率: 0.98, F1: 0.98
真实类别: 正常邮件 预测结果: 正常邮件
邮件内容【 分专业吧,也分导师吧 标 题: Re: 问一个:有人觉得自己博士能混毕业吗 当然很好混毕业了 : 博士读到快中期了,始终感觉什么都不会,文章也没发几篇好的,论文的架构也没有, : 一切跟刚上的时候没有区别。但是事实上我也很辛苦的找资料,做实验,还进公司实习过, : 现在感觉好失败,内心已经放弃了,打算混毕业,不知道过来人有什么高招,请指点一二。 -- 】
真实类别: 垃圾邮件 预测结果: 垃圾邮件
邮件内容【 您好! 我公司有多余的发票可以向外代开!(国税、地税、运输、广告、海关缴款书)。 如果贵公司(厂)有需要请来电洽谈、咨询! 联系电话: 01521025**** 大白 谢谢 顺祝商祺! 】
文本表示
1、One-hot
One-hot(独热)编码是一种最简单的文本表示方式。如果有一个大小为 V 的词表,对于第 i 个词,可以用一个长度为 V 的向量来表示,其中第 i 个元素为 1,其它为 0. 例如:
减肥:[1, 0, 0, 0, 0]
瘦身:[0, 1, 0, 0, 0]
增重:[0, 0, 1, 0, 0]
One-hot 词向量构建简单,但也存在明显的弱点:
- 尺寸太高。如果词的数量很大,每个词都需要用更长的向量来表示,造成维度灾难;
- 稀疏矩阵。每个词向量,其中只有一位为 1,其它位均为零;
- 语义鸿沟。词之间的相似性和相关性无法衡量。
词袋模型
词袋模型 (Bag-of-words model,BOW),BOW 模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。例如:
我把他揍了一顿,揍得鼻青眼肿
他把我走了一顿,揍得鼻青眼肿
建立字典:
{"我":0, "把":1, "他":2, "揍":3, "了":4 "一顿":5, "鼻青眼肿":6, "得":7}
再将句子向量化,维数和字典大小一致,第 i 维上的数值代表 ID 为 i 的词在句子里出现的频次,两个句子可以表示为:
[1, 1, 1, 2, 1, 1, 1, 1]
[1, 1, 1, 2, 1, 1, 1, 1]
bag-of-words模型表达简单,但也有明显的缺点:
- 顺序和语义丢失了。顺序是极其重要的语义信息。词袋模型只计算词的频率,忽略词的顺序。比如上面两个句子意思相反,但是bag-of-words模型表示是完全一样的;
- 高维和稀疏。当语料增加时,词袋模型的维度也会增加,需要更长的向量来表示。但是大多数单词不会出现在文本中,所以矩阵是稀疏的。
TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency,词频 - 逆文档频率)是一种传统的统计计算方法,常用于评估文档集合中的单词对文档的重要性。基本思想是:一个词在文档中出现的次数越多,出现的文档越少,语义贡献越大(区分文档的能力越强)。其表达式为:
该指示器仍然不能保留文本中单词的位置关系。这个指标之前已经详细讨论过了,这里不再赘述。
共现矩阵
共现(co-occurrence)矩阵是指统计单词在预先指定大小的窗口中的共现次数,以单词周围的共现单词个数作为当前单词的向量。具体来说,我们通过从大量语料库文本中构造一个共现矩阵来表示单词。例如,有如下语料库:
I like deep learning.
I like NLP.
I enjoy flying.
那么共现矩阵表示为: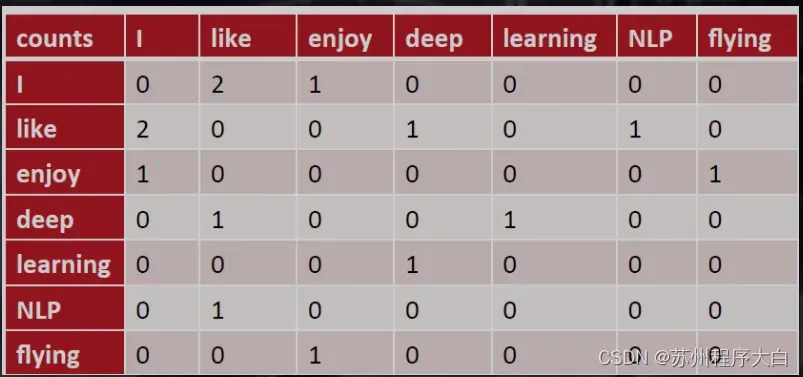
矩阵定义的词向量在一定程度上缓解了 one-hot 向量相似度为 0 的问题,但没有解决数据稀疏性和维度灾难的问题。
💫点击直接数据领取💫

各种学习资料,有趣好玩的编程项目,各种难得一见的资源。
文章出处登录后可见!