最近ChatGPT大火,其实去年11月份就备受关注了,最近火出圈了,还是这家伙太恐怖了,未来重复性的工作很危险。回归主题,ChatGPT就是由无数个(具体也不知道多少个,哈哈哈哈)Transformer语言模型组成,Transformer最开始在2017年提出,目的是解决序列数据的训练,大多数应用到了语言相关,最近在图像领域也很有作为,属于是多点开花了。今天来简单看看他的实现吧。
目录
一、Transformer原理
说实话,介绍这个东西优点太伤神了,我想把有限的时间浪费在有意义的事情上,不对其数学原理发表什么了(主要是不会),简单介绍他的组成结构吧。
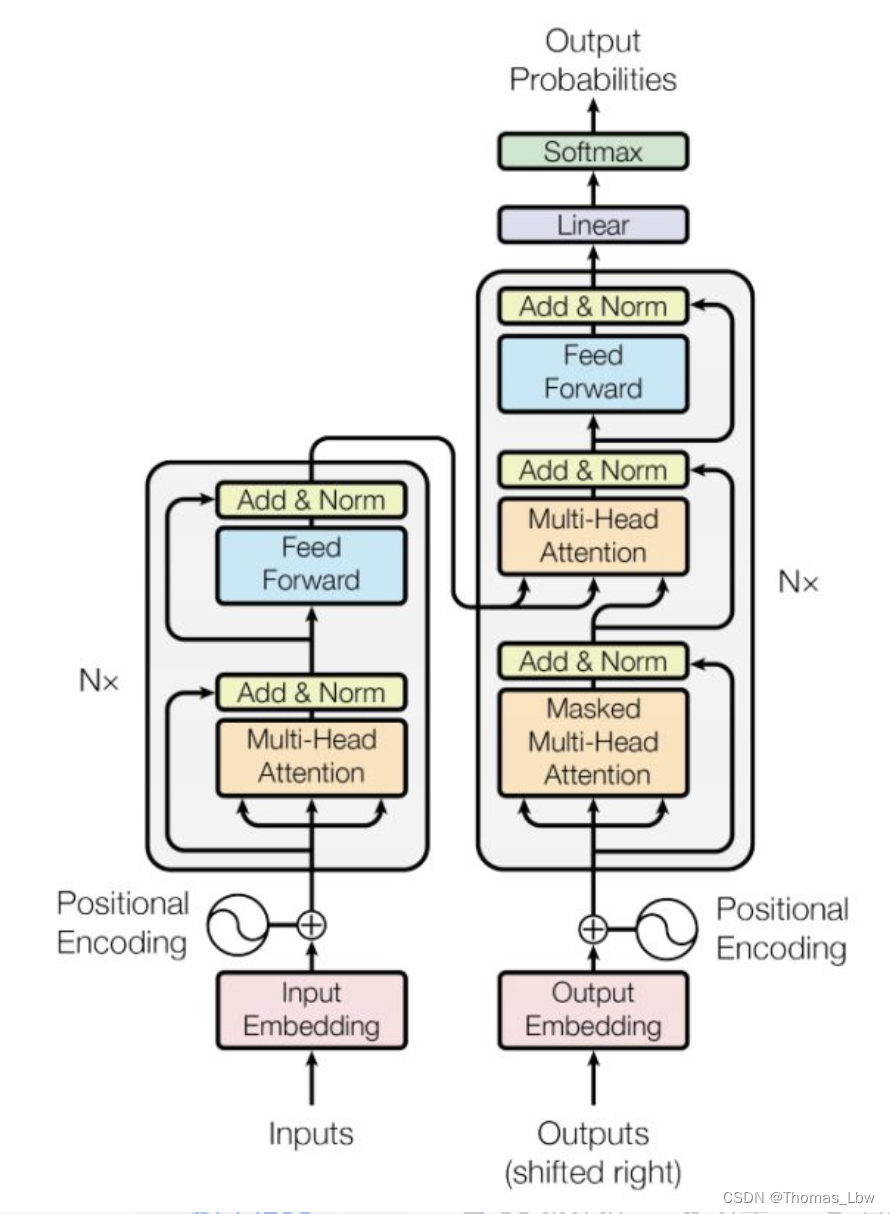
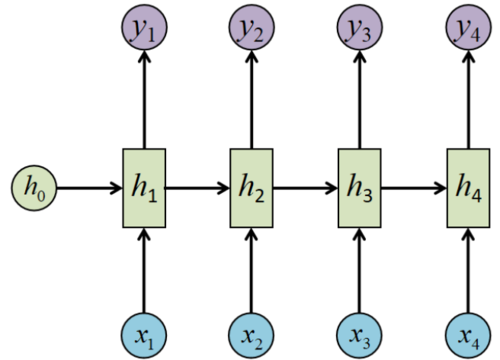
上图是组成transformer的一部分,他可以被分为编码层和解码层,对于语言这样的序列来讲,必须对其进行编码才能使用其数据信息。最简单的编码便是一个字符对应一个数字,这个大家心中有数就好,真实的Transformer编码原理肯定比这个复杂,不过现在的torch里你可以不需要知道内部的细节,可以直接调用。为了更直观的理解,你可以预习RNN的编码解码。总之,这个过程是一种信息转化、提取的过程,将计算机不懂的字符变为它能计算的数字。RNN图如下:
具体原理实现可以看下面的链接:
二、代码实现
代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class TransformerEncoder(nn.Module):
def __init__(self, d_model, nhead, num_layers, dim_feedforward, dropout=0.1):
super(TransformerEncoder, self).__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, dim_feedforward),
nn.ReLU(),
nn.Linear(dim_feedforward, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
self.num_layers = num_layers
def forward(self, x, mask=None):
attn_output, _ = self.self_attn(x, x, x, attn_mask=mask)
x = x + self.dropout(attn_output)
x = self.norm1(x)
ff = self.feed_forward(x)
x = x + self.dropout(ff)
x = self.norm2(x)
return x
class TransformerDecoder(nn.Module):
def __init__(self, d_model, nhead, num_layers, dim_feedforward, dropout=0.1):
super(TransformerDecoder, self).__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.src_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, dim_feedforward),
nn.ReLU(),
nn.Linear(dim_feedforward, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
self.num_layers = num_layers
def forward(self, x, src, mask=None, src_mask=None):
attn_output, _ = self.self_attn(x, x, x, attn_mask=mask)
x = x + self.dropout(attn_output)
x = self.norm1(x)
attn_output, _ = self.src_attn(x, src, src, attn_mask=src_mask)
x = x + self.dropout(attn_output)
x = self.norm2(x)
ff = self.feed_forward(x)
x = x + self.dropout(ff)
x = self.norm3(x)
return x
class Transformer(nn.Module):
def __init__(self, d_model, nhead, num_layers, dim_feedforward, dropout=0.1):
super(Transformer, self).__init__()
self.encoder = TransformerEncoder(d_model, nhead, num_layers, dim_feedforward, dropout)
self.decoder = TransformerDecoder(d_model, nhead, num_layers, dim_feedforward, dropout)
self.d_model = d_model
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
memory = self.encoder(src, src_mask)
output = self.decoder(tgt, memory, tgt_mask, src_mask)
return output
if __name__ == "__main__":
d_model = 512
nhead = 8
num_layers = 6
dim_feedforward = 2048
dropout = 0.1
transformer = Transformer(d_model, nhead, num_layers, dim_feedforward, dropout)
src = torch.randn(10, 32, d_model)
tgt = torch.randn(20, 32, d_model)
output = transformer(src, tgt)
print(src)
print("########################")
print(output)
src和tgt分别是输入的源数据和目标数据,大小为batch_size x sequence_length x d_model。src_mask和tgt_mask分别是对于src和tgt的有效位置的掩码,大小为batch_size x sequence_length x sequence_length,为了实现对填充位置的忽略。d_model是模型中间语义空间的维数。nhead是多头注意力机制中每个头的数量。num_layers是编码器和解码器的层数。dim_feedforward是前馈网络的隐藏层大小。dropout是 dropout 的比率。
三、通俗解释如何使用Transformer
在语言领域,Transformer有很强大的序列特征提取能力,具体多强我并没有感受,因为没用过,没法对比。不过ChatGPT的大量使用Transformer足可以证明它正值年壮,没道理我们不用它。
在图像领域同样很强,不过需要大量数据来训练,否则它不如CNN,这个也都是大量先人的经验,踩过坑自然知道。缺点还有就是模型太大,需要很大的算力。
你可以把它当成黑盒来用,这个是Transformer用于翻译:

用于图像领域,如果是图像像素点判断(图像分割),那么需要将FC去掉,根据自己需要修改吧:
import torch
import torch.nn as nn
import torch.nn.functional as F
class TransformerEncoder(nn.Module):
def __init__(self, d_model, nhead, num_layers, dim_feedforward, dropout=0.1):
super(TransformerEncoder, self).__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, dim_feedforward),
nn.ReLU(),
nn.Linear(dim_feedforward, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
self.num_layers = num_layers
def forward(self, x, mask=None):
attn_output, _ = self.self_attn(x, x, x, attn_mask=mask)
x = x + self.dropout(attn_output)
x = self.norm1(x)
ff = self.feed_forward(x)
x = x + self.dropout(ff)
x = self.norm2(x)
return x
class ImageTransformer(nn.Module):
def __init__(self, d_model, nhead, num_layers, dim_feedforward, dropout=0.1):
super(ImageTransformer, self).__init__()
self.encoder = TransformerEncoder(d_model, nhead, num_layers, dim_feedforward, dropout)
self.fc = nn.Linear(d_model, 1024)
def forward(self, x):
x = self.encoder(x)
x = self.fc(x)
x = F.relu(x)
return x
if __name__ == "__main__":
# 实例化ImageTransformer模型
model = ImageTransformer(d_model=16, nhead=8, num_layers=6, dim_feedforward=2048, dropout=0.1)
# 使用图像数据输入模型
image = torch.randn(3, 16, 16)
features = model(image)
print(features)
四、总结
Transformer用来训练语言模型一点问题没有,人家本来就是为序列而生。但是训练图像需要甄别自己的实际情况。随着ChatGPT的爆火,你不了解它,但是它在了解你。
文章出处登录后可见!