共享单车数据是城市时空大数据的重要组成部分,通过对共享单车数据进行深入的分析与挖掘,研究人员可以发现有价值的知识,从而帮助政府和城市管理者进行更合理的城市规划与管理,提升城市运行效率,实现城市的可持续发展
城市共享单车出入流预测是共享单车数据挖掘的重要研究内容,通过对本问题的研究,可以从一定程度上反映城市居民的出行规律,缓解共享单车在不同区域供需不平衡的问题,提前发现未来某一时段内共享单车需求量暴增或者共享单车数量不足的问题,以做好单车调度,单车分配等任务,缓解城市中的“最后一公里问题
利用深度学习和迁移学习方法,以基于深度域适应网络的共享单车出入流知识迁移与预测为应用背景,对现有的公开共享单车数据,进行深入分析,学习共享单车复杂的时空分布,进行知识迁移,并进行预测。以“数据获取-数据预处理-应用实战”为主线
共享单车出入流预测
即利用城市中不同区域的历史共享单车数据预测未来一段时间内的共享单车出入流数据,一般通过深度学习等技术构建模型,并使用天气等外部数据辅助预测
如果仅仅关注某一特定位置在一段时间内的相关共享单车测量数据,那么可以将其建模成时间序列数据,如某条道路上的共享单车流量数据
在传统的研究上,研究者们大都使用基于统计的方法,如ARIMA、SVR与贝叶斯网络等。但是这些基于统计的方法学习到的特征比较浅,由于它们有限的学习能力,无法学习到复杂的时空依赖
随着深度学习技术的进步,深度学习技术被广泛应用到共享单车出入流预测上
一类方法通过将整个城市看作图像,并应用卷积神经网络CNN捕获空间特征,进行区域级的共享单车出入流预测。由于时间特征对共享单车预测研究十分重要,又引入循环神经网络RNN,并结合CNN同时学习时空特征,引入了如ConvLSTM等模型,并进一步扩展出SeqST-GAN等方法
但是,随着研究的深入,研究学者们发现目前的算法将整个城市看作一张图片,然后使用卷积神经网络CNN 对其进行处理,但是这种方式不能完整地反映空间关系。比如说,城市中的两个区域相隔比较远,但是它们却有着相似的空间模式,而传统的卷积神经网络CNN 无法捕获这种空间特征
为了捕获这种全局的空间特征,对这种非欧式数据进行建模,研究者们又提出了另一类研究方法,即基于网神经网络(GNN)的共享单车出入流预测方法,通过引入随机游走(random walk)、图卷积神经网络(GCN)等方法,并结合RNN与最近很火的transformer等方法,提出了很多方法,如AEST等
同时,我们也可以将图像的每一个区域看作节点,将DCRNN、STGCN和GMAN等方法应用于共享单车出入流预测
随着数据种类的增加,很多研究者引入了迁移学习、联合训练模型和多任务学习模型对共享单车的出入流预测进行了研究。来自北京大学等单位的研究者们提出了名为RegionTrans的迁移学习方法,首先利用现有数据计算目标域中的每个区域和源域直接的相似性,然后将这些相似性加入到基于深度学习的预测模型中作为约束,将数据丰富的城市数据知识迁移到数据稀疏的城市中
一种统一的端到端的时空域适应网络ST-DAAN,从数据分布的角度,借助深度域适应网络DAN与最大均值差异MMD,将丰富的源域知识迁移到目标域中,以辅助数据稀疏的城市进行共享单车的出入流预测。同时,为了考虑出入流预测与起点-目的地(OD)预测的相关性,笔者又提出了MT-ASTN模型,利用基于对抗学习的多任务学习方法,学习两个任务的公有特征,同时辅助共享单车出入流预测与OD预测
共享单车调度优化
共享单车的调度优化研究能为城市管理者与共享单车运营商管理共享单车提供参考与理论支撑,其受多维因素影响,如天气、节假日等。现对国内外共享单车调度优化研究进行简要综述
国外对共享单车的调度优化研究比较早,在早期的研究中,研究者们主要使用基于规则的算法进行共享单车的调度优化
研究者们一开始通过建立总调度距离最短模型和分支切割算法对调度车辆唯一情况下的调度问题进行求解;紧接着,另一部分研究者研究了共享单车调度路线的确定、迁移或自行车放置路线问题,通过将目标函数定义为调度总距离及被租赁点拒绝的使用者数量进行优化;随后,有研究者引入数据挖掘方法,利用聚类分析,对单车的租赁点进行聚类,对不同租赁点之间的线路分布进行建模;同时,又有研究者引入系统动力学模型解决共享单车系统的动态平衡问题,求解不同状态下系统的最佳调度方案
考虑到调度成本问题,研究者们提出了基于调度成本最小化的单车二次配送的动态模型,模型得出了客户满意度最高的最优调度路径;为了对不同站点不同车辆进行统一规划,提出了混合整数规划模型,为大规模公共自行车系统的调度和再分配问题提供了一种新思路
还有一部分研究者们借助机器学习方法,将能考虑到的影响共享单车调度因素作为特征输入到机器学习模型中,优化共享单车调度;随着强化学习的火爆,现在的研究者们引入强化学习对共享单车的调度路线进行优化,以减少成本。但是国外对调度问题的研究主要基于有桩共享单车,涉及无桩共享单车的调度研究较少
国内的学者对共享单车的调度优化也有很多重要的研究。 起初,研究者们利用遗传算法和禁忌搜索法,通过将运营成本与服务质量作为约束,对需求不断变化的供需单车调度问题进行求解
后来,有研究者发现共享单车的供需关系在时空上都存在不均衡问题,使用蚁群算法对单车调度路径优化问题进行求解;还有研究者通过归纳分析借还车数据,建立BP神经网络预测借还车的分布情况,通过定义调度时间窗内站点的饱和度分析最优调度方案;另一部分研究者利用聚类等数据挖掘方法分析居民使用共享单车的出行规律,对时空特征建模,为共享单车调度提供参考
共享单车数据简介及数据预处理
共享单车领域的数据集主要包含摩拜单车数据集、纽约有桩共享单车数据集、芝加哥共享单车数据集等
主要以基于经纬度的共享单车的出入流预测为主,因此,此处会着重对纽约有桩共享单车数据集和芝加哥共享单车数据集的获取手段以及相关的数据集信息进行简介,同时也会对摩拜单车数据集进行简要介绍
纽约有桩共享单车数据集 CitiBike
CitiBike是纽约有桩共享单车的轨迹数据,包含2013年6月到2021年7月(截至笔者撰写本节前)全纽约市范围内城市有桩共享单车的数据,本节以2015年1月至2015年12的数据为例,总的来说,CitiBike在纽约建立了超过600个自行车站点,并投放了10000辆左右的自行车
网目前可直接下载2015年1月1日至2015年12月31日的数据,该数据集超过九百万条。CitiBike官网(https://www.citibikenyc.com/system-data)提供了其他年份的全量数据可供下载,且提供了详细的数据集说明
数据集中的每条轨迹数据包含11个字段:
行程时间 行程开始日期/时间 行程结束日期/时间 起始站点编号 起始站点名称 起始站点经度 起始站点纬度
终止站点编号 终止站点名称 终止站点经度 终止站点纬度 自行车编号 用户类型 生日 性别
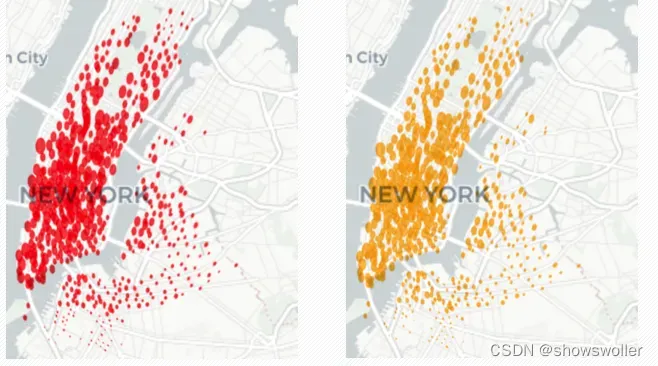
以热力图的形式,可视化了整个纽约共享单车数据集2015年某个时刻的签入签出数据,如图所示(左侧为签出数据、右侧为签入数据)
芝加哥共享单车数据集 DivvyBike
DivvyBike是基于经纬度的芝加哥公开共享单车数据集,由芝加哥自行车共享系统Divvy进行数据采集,包含2013年1月至2021年7月全芝加哥市范围内城市共享单车的数据,本节以2015年的共享单车数据为例。总的来说,DivvyBike建立了580个站点,并投放了5800辆自行车。从2015年1月至2015年12月,DivvyBike拥有超过6百万条自行车行程数据
用户可通过Divvy Data官网(https://www.divvybikes.com/system-data)下载全量数据,同时官网也提供相应的数据说明和数据使用条例
每条行程数据包含以下字段:
行程开始时间 行程结束时间 起始站点编号 起始站点名称 起始站点经度 起始站点纬度
终止站点编号 终止站点名称 终止站点经度 终止站点纬度 自行车编号 用户类型 生日 性别
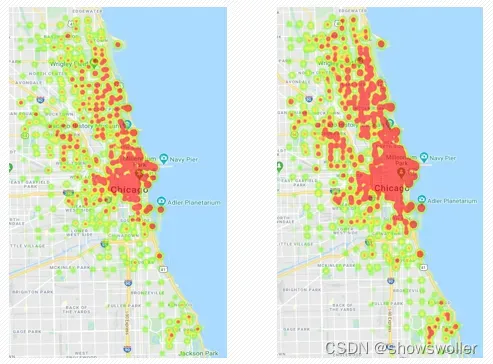
以热力图的形式,可视化了整个芝加哥共享单车数据集2015年某个时刻的签入签出数据,如图所示(左侧为签出数据、右侧为签入数据)
摩拜单车数据集 MoBike
MoBike北京摩拜单车数据集来源于2017年中国人工智能学会与摩拜联合举办的2017摩拜杯算法挑战赛,大赛以摩拜单车推出以来,已经在很多城市成为除公共交通以外的居民出行方式的首选为背景,主要目标是利用机器学习等技术去预测用户的出行目的地等。MoBike数据集没有固定的站点,在北京投放了超过40万辆共享单车
其中每条数据包含7个字段:
订单编号 用户编号 车辆编号 车辆类型 骑行起始时间 骑行起始区块位置 骑行目的地区块位置
地理位置信息,如骑行起始区块位置和骑行目的地区块位置信息,通过Geohash加密,可以通过开源的方法获得详细的经纬度数据。
文章出处登录后可见!