
推荐基于稳定扩散(stable diffusion) AI 模型开发的自动纹理工具:DreamTexture.js自动纹理化开发包 – NSDT
稳定扩散获得如此多关注的原因
如果你还没有看过它:稳定扩散是一个文本到图像的生成模型,你可以输入一个文本提示,比如“一个人一半尤达一半甘道夫”,然后接收一个图像(512×512像素)作为输出,如下所示:

提示:一个人一半尤达一半甘道夫,幻想绘画在artstation上流行
结果看起来像 DALL-E 2 甚至更好,这本身已经很棒了,但它变得更好:它的计算效率非常高,可以在只需要大约 8-10GB 内存的消费级 GPU 卡上运行。它的训练效率也比过去的模型更高(唉,如果你不能使用很多GPU,它仍然太贵了)。
除了计算效率之外,结果看起来也很棒。事实上,正如上面引用的论文所解释的那样,它们在图像基准测试中达到了几个新的高分,例如图像修复和类条件图像合成。
最好的部分是:这是完全开源的。这包括代码、模型权重以及将其用于任何人的权利,目的是使任何人的创造力民主化。
关于它的名字 stable diffusion 的稳定部分是,名为 Stability 的赞助商提供了大量的 GPU 计算来将该模型训练到当前状态(在 512x512px 图像上进行了微调),然后将其开源。
深入了解:稳定扩散是如何工作的?
我非常喜欢分层学习,所以我们将从高级视图开始,然后深入研究各个部分。
高级视图
该系统分为三个部分:
- 一种语言模型,它将您输入的文本提示转换为一种表示形式,该表示形式可以馈送到扩散模型并通过交叉注意力机制使用。他们使用带有转换器的“现成”BERT 分词器来处理这部分,所以我不会更深入地介绍它。
- 扩散模型基本上是一个时间条件 U-Net(有关 U-Net 的详细信息,请查看此处),它采用一些高斯噪声和文本提示的表示作为输入,并对高斯噪声进行去噪以更接近您的文本表示。这重复了好几次,这就是为什么它被称为时间条件。
- 一种解码器,用于获取扩散模型的输出并将其放大为完整图像。扩散模型在 64x64px 上运行,解码器将其带到 512x512px。

文本到图像生成的插图(由作者制作)。语言模型创建文本提示的嵌入。它与一些随机噪声一起输入扩散模型。扩散模型将其向嵌入方向去噪。这重复了几次。最后,解码器将图像放大到更大的尺寸。
扩散模型的高级视图
扩散模型的想法是拍摄图像并添加一点高斯噪声,从而获得略带噪点的图像。 然后重复该过程,因此在略微嘈杂的图像中,您再次添加一点高斯噪声以获得更嘈杂的图像。 重复此操作数次(最多 ~1000 次)以获得完全嘈杂的图像。
在这样做时,您知道每个步骤的原始图像(或略带噪点的图像)及其嘈杂的版本。
然后,你训练一个神经网络,该神经网络获取噪声较大的示例作为输入,并具有预测图像的降噪版本的任务。

扩散过程的图示(由作者制作):从左到右,您不断向图像添加高斯噪声。然后,模型从右到左学习以对其进行降噪。
在许多不同的步骤中,神经网络学习以重复的方式对非常嘈杂的图像进行降噪以获得原始图像。
高水平培训
在训练过程中,还存在一个编码器,它是上述解码器的对应部分。
编码器和解码器共同构成一个自动编码器。
编码器的目标是将输入图像转换为具有高度语义的下采样表示,但去除了与手头图像不太相关的高频视觉噪声。
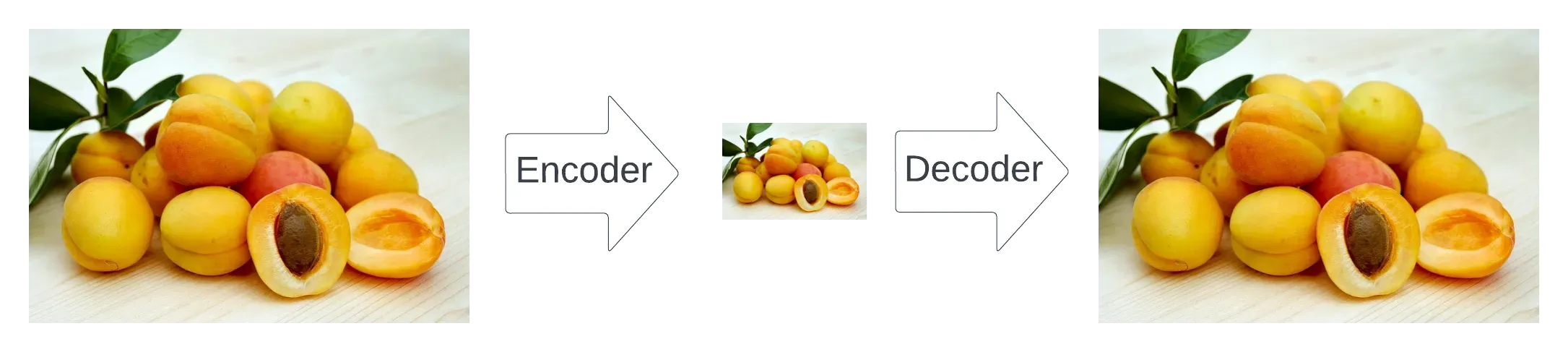
自动编码器的插图(由作者制作):编码器找到图像的更小的表示形式,但保留了语义含义。解码器以尽可能少的损失从有效表示中重新获得图像的原始版本。
这里的诀窍是,他们将编码与训练扩散模型解耦。这样,可以训练自动编码器以获得最佳图像表示,然后可以在下游的几个扩散模型上进行所谓的潜在表示(这只是以语义上有意义的方式表示的图像,但像素少 64 倍)。
这样一来,在像素空间上训练扩散模型时,在原始图像空间上的计算量需要比以前少 64 倍。这是完全相关的,因为正如我们稍后将看到的,扩散模型的训练和推理是最昂贵的部分。
因此,培训分两个阶段进行:
- 训练自动编码器,用于处理图像表示的压缩和解压缩
- 在自动编码器的编码器生成的潜在因素上训练扩散模型(这与文本表示/注意力部分相结合)
组件的详细视图
训练自动编码器
自动编码器的训练有两个损失:
- 像素空间上的感知损失
- 基于补丁的对抗性损失,可强制执行局部真实感并避免模糊
它通过一个因子对图像进行下采样,该因子已在论文中使用许多不同的值进行了测试,并且权衡了 OR 是好的。ff=4f=8
除了损耗之外,正则化还应用于自动编码器。这里可以使用两种不同的形式:
- Kullback-Leibler 惩罚,用于将学习到的潜伏子与过去潜伏子的标准正态对齐,以确保潜伏子的方差不会太高
- 解码器中的矢量量化层;这就像定义原型一样
N
有时他们使用KL惩罚,有时在训练不同的扩散模型时使用向量量化。对我来说,尚不完全清楚何时一个或另一个更好。 似乎对于文本到图像合成模型,使用了KL惩罚。
扩散模型的训练
考虑到使图像产生噪声或在逆过程中对其进行降噪的连续步骤数,这可以描述为马尔可夫链,因为每个时间步骤仅取决于直接后继者,而没有其他任何内容。

扩散模型的训练过程图示(由作者制作)。具有现有标题的图像用于训练。噪声在连续的时间步长中添加到编码图像中。文本标题由语言模型嵌入。扩散模型接收图像的噪声版本和文本嵌入,并需要预测图像的上一个时间步长。梯度下降用于预期图像与扩散模型预测之间的像素差。
为了训练它,幸运的是,你有可以有效地生成的前向步骤,所以你可以确切地知道给定图像在时间步长和时间步长上看起来如何。NN+1
然后,将时间步长的图像传递到网络,并期望它返回时间步长的图像。对于损失,您考虑了网络预测与时间步长图像之间的像素差异。N+1NN
图像上的噪声越多,网络在不太相关的视觉特征上花费的就越多,因此通常在较早的时间步长比在较晚的时间步长采样的示例更多。
等等,但为什么这会产生所有这些创造性的艺术?!
所以,你们问自己的真正问题当然是:魔法从何而来?
正如我所描述的,它是一个复杂的系统,由三部分组成——自动编码器、文本嵌入的语言模型和潜在扩散模型。
所有这些部分都是在大量图像或图像/文本对上训练的,因此自动编码器和语言模型的嵌入非常复杂,涵盖了我们人类的大部分语义空间。然后,当通过新的文本提示将概念组合在一起时,这些概念会组合成一个涵盖这一点的嵌入。潜在扩散模型本身经过训练,可以从噪声中发现图像,但受这种嵌入的引导,因此它将创造性的嵌入概念推向图像表示。最后,解码器有助于将潜在表示带入更放大和人类可见的版本(并且它还在数百万张图像上进行了训练!
我认为魔力在于在培训期间学到的概念的重叠/可组合性。例如,有些图像是半男半女或类似的东西,所以学习了一半/一半的概念。许多其他图像都包含《星球大战》/尤达的部分内容,因此学习了尤达的概念。然后其他图像了解了甘道夫。当最终将所有这些组合到一个提示中时,系统会尝试将所有这些知识集成到最有可能看起来像这样的图像中。因此,创建了本文中的图像。
总结
意识到要加速扩散模型,您应该减少像素空间,因为它被反复使用(在马尔可夫链方法中),因此变得昂贵,这是向前迈出的一大步。事实上,它不仅减少了像素空间,而且通过预先的自动编码器学习了良好的表示/嵌入,它仍然具有所有语义和语义的视觉表示。
以单独的方式进行,以便单独训练自动编码器,从而可以灵活地训练多个不同的扩散模型,这些模型针对特殊任务进行了调整。
将其与交叉注意力步骤中的其他输入相结合,对于实现快速且具有视觉吸引力的文本到图像生成模型的惊人效果至关重要。
但是,除了使用文本提示之外,还可以使用其他输入/嵌入。例如,作者展示了如何使用粗略的分割草图,然后通过模型将其转换为美丽的图像,以及更多诸如从图像中删除人物之类的东西(想想Photoshop魔杖超级高级工具):

摘自论文的图 22:从图像中去除物体的潜在扩散模型。
希望这篇关于稳定扩散的博客文章能让你对所使用的概念有一个很好的概述。
版权声明:本文为博主作者:ygtu2018原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/ygtu2018/article/details/134326376