tensorflow处理图像识别
- 图像识别
- 图像识别的关键点及特点
- 卷积神经网络原理
- 视觉生物学研究
- 神经网络优势
- 卷积层
- 池化层
- 正则化层
- 卷积神经网络实例
- 样本数据读取
- urlretrieve()方法
- python tarfile模块
- 构建卷积神经网络模型
- 构建卷积层
- 构建池化层
- 完整代码
- 实战完成代码
图像识别
研究图像识别离不开两样东西:第一,大量的样本数据;第二,好的算法。从某种意义上来说,数据比算法更重要,算法只是决定了图像识别的准确率,但如果没有样本数据,图像识别就无从谈起了。
图像识别的关键点及特点
-
图像识别的关键:特征 和特征之间的相对位置。
- 首先是特征,我们记住一个事物首先记住的应该是它的关键特征,然后将这些关键特征与我们所知道的事物关联起来,从而完成对事物的识别。
- 其次是特征之间的相对位置、比如一个男人,他的右脸有一个刀疤,我们可能会用“右脸上有个刀疤”的特征来描述,在这里“有个刀疤”是一个特征信息,“右脸”就是这个特征的相对位置。
所以,特征及特征之间的相对位置就是图像识别的关键信息。
-
图像识别的特点:可以归纳为三个不变性和一个模糊性。三个不变性指的是平移不变性、旋转不变性和缩放不变性,一个模糊性指的是特征之间的相对位置是不精确的,如一个人脸的图片,如果双眼之间的距离缩短了一些,我们还是能精确的识别出来的。
- 平移不变性:当原始的图片平移到另一个位置之后我们还是能精确的识别出来的,但是对于图像识别算法来说,这个是需要关注的难点。
- 缩放不变性:经过等比例的缩放,我们人眼还是能很容易地识别出来。但是,对于计算机来说,缩放前后的图片,对应的像素数值已经发生了巨大的变化,所以这也是图像识别算法需要解决的难点之一。
- 选择不变性:不是所有的图形都具有旋转不变性。比如数字9,选择180度之后,变成了6.
卷积神经网络原理
事实上,计算机视觉受到了视觉系统的视觉信息处理研究的启发,我们对感觉系统信号处理过程的认识,启发了人们将视野(或感受野)、物体特征识别、尺度特性转换的特点应用在图像识别中。
卷积核又叫过滤器。卷积核的叫法来源于机器学习中的“核函数” ;过滤器的叫法来源于信号处理中的“滤波器”,过滤器的叫法在TensorFlow中广泛使用。
视觉生物学研究
在1959年,神经科学家David Hunter Hubel与合作者Torsten N. Wiesel进行了一项研究,展示了视觉系统是如何将来自外界的视觉信号传递到视皮层,并通过一系列处理过程(本质上就是特征提取),包括边界检测、运动检测、立体深度检测和颜色检测,最后在大脑中构建一幅视觉图像的。
研究发现,不同神经元对不同的空间方位(视野或感受野)的敏感程度不同,同时还发现不同神经元对亮光带和暗光带的反应模式也不相同,有些神经元对亮光敏感、有些神经元对暗光敏感。David Hunter Hubel与Torsten N. Wiesel将这些神经元称为“简单细胞”,将初级视皮层里其他的神经元称为“复杂细胞”。
而我们卷积神经网络就是收到视觉处理过程中不同的神经元对不同的空间范围敏感的启发,放弃全连接神经网络的连接方式,采用一个神经元只与输入图像的部分区域连接的方式。
这种方式极大程度减少了神经元的数量,并且能够让神经元更好地发现局部的特征。
神经网络优势
下图为全连接神经网络与卷积神经网络连接方式的对比
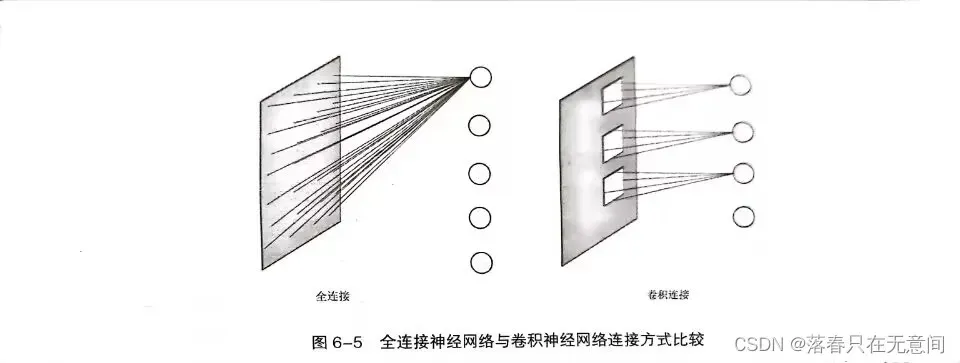
我们假设输入图形是1000 * 1000个像素,隐藏层的神经元是10000个,那个全连接神经网络一共需要 个参数。看一下卷积神经网络,我们的每一个神经元与输入图像中的10*10的区域相连,那么需要的参数数量仅为
而在实际中,卷积神经网络采用权值共享的方式来进一步降低参数的数量。由于每个神经元都是与一个1010的区域相连,每个神经元都有1010个参数,那么我们如果将第一个神经元的1010个参数共享给其他神经元,那么不论隐藏层有多少个神经元,整个卷积神经网络只有1010个参数。
但是这样会有一个问题,我们只有10*10的过滤器,那么只能提取一个特征。因为如果我们要提取多个特征,我们可以通过增加过滤器的方式来实现,不同的过滤器用于提取不同的特征。假设有100个过滤器,那么参数的总数也不超过个,相比较与全连接参数的个数大大降低了。
卷积层
- 这里提到的将参数共享给其他神经元,首先一个神经元就是很多个上一层的神经元输出分别×weight再整体加上偏置b的一次运算,进过激活函数得到输出的这样一个过程。我们只是共享其中的weight,但是由于每一个神经元对应的局域不同,所在最后卷积之后的结果不完全一致的。
右上边描述我们就可以知道,如果一个图像我们总计实行了36次卷积操作,那么该卷积层神经网络中有36个神经元。
池化层
通常情况下,卷积层之后会紧跟着一个池化层,常用的池化操作有Max Pooling(最大值池化法)和Average Pooling(平均值池化法),较常用的是最大池化。
- 池化操作之后,特征图谱只会在宽度和高度上变小,在深度上不会改变。
- 需要池化的原因:
池化的操作的过程是输入的特征图谱的宽度、高度变小,本质上是一个下采样的过程,这个过程舍弃了大量的信息。我们知道,只有舍弃的信息是“噪声”,才会有助于提高模型的识别准确率,否则池化操作只会导致模型识别的准确率降低。那么我们是如果丢弃这个“噪声”信息的呢?卷积的目的是提取特征,特征之外的这些非零信息其实是噪声,池化操作通过取最大值的办法,将池化区域的数个像素只保留一个像素,减少了哪些不重要(卷积点积的结果数值较小的区域)数值的干扰,达到减少“噪声”的目的。
正则化层
有的卷积神经网络中,在池化层之后、全连接层之前会有一个正则化层,正则化层试图模拟在生物脑神经中观察到的抑制现象。但是现在已经不流行了,因为实践发现,正则化层对模型的贡献率是非常小的。
卷积神经网络实例
以识别CIFAR-10数据集中的图像为例。大体步骤为先对样本数据和测试数据进行读取,之后构建卷积神经网络模型,最后调研样本数据读取函数,将数据注入构建好的模型,完成模型的训练和评估。
样本数据读取
urlretrieve()方法
python3中urllib.request模块提供的urlretrieve()函数。urlretrieve()方法直接将远程数据下载到本地。
urlretrieve(url, filename=None, reporthook=None, data=None)
- 参数url:下载链接地址
- 参数filename:指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。)
- 参数reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
- 参数data:指post导服务器的数据,该方法返回一个包含两个元素的(filename, headers) 元组,filename 表示保存到本地的路径,header表示服务器的响应头
进度条显示结果如下:

python tarfile模块
tarfile模块的主要作用是用来加压缩和解压缩文件,其压缩文件的类型可以是
.tar | .tar.gz | .tgz | .tar.bz2 等
- 加压:
tar = tarfile.open("/tmp/test.tar.gz","w:gz") for root,dir,files in os.walk("/home/red/桌面/test"): for file in files: apath = os.path.join(root,file) tar.add(apath) tar.close - 解压:
tar = tarfile.open("/tmp/test.tar.gz","r") for ti in tar: tar.extract(ti,"/") tar.close()
完整代码:
def read_cifar10_data(path=None):
"""
读取Cifar-10的训练数据和测试数据。
:param path: 保存Cifar-10的本地文件目录。
:Returns: 训练集的图片、训练集标签、测试集图片、测试集标签。
"""
# Cifar-10的官方下载网址,需要下载binary version文件
url = 'https://www.cs.toronto.edu/~kriz/'
tar = 'cifar-10-binary.tar.gz'
files = ['cifar-10-batches-bin/data_batch_1.bin',
'cifar-10-batches-bin/data_batch_2.bin',
'cifar-10-batches-bin/data_batch_3.bin',
'cifar-10-batches-bin/data_batch_4.bin',
'cifar-10-batches-bin/data_batch_5.bin',
'cifar-10-batches-bin/test_batch.bin']
# 如果没有指定本地文件目录,那么,设置目录为"~/data/cifar10"
if path is None:
path = os.path.join(os.path.expanduser('~'), 'data', 'cifar10')
# 确保相关目录、及其子目录存在
os.makedirs(path, exist_ok=True)
# 如果本地文件不存在,那么,从网络上下载Cifar-10数据
tar_file = os.path.join(path, tar)
if not os.path.exists(tar_file):
print("\n文件{}不存在,尝试从网络下载。".format(tar_file))
# 从网上下载图片数据,并且,保存到本地文件
img_url = os.path.join(url, tar)
# 本地文件名称
img_path = os.path.join(path, tar)
print("开始下载: {}, 时间:{}".format(
img_url, time.strftime('%Y-%m-%d %H:%M:%S')))
# 文件下载进度条,
def _progress(count, block_size, total_size):
# 下载完成进度(百分比)
percentage = float(count * block_size) / float(total_size) * 100.0
# 下载进度条总共有50个方块组成(已完成的部分用'█',未完成的用'.')
# 根据count的奇偶性,决定最后一个方块是否出现,实现闪烁的效果
done = int(percentage / 2.0)
done += (count & 1)
# 显示进度条,其中'\r'表示在同一行显示(不换行)
sys.stdout.write('\r[{}{}] 进度:{:.2f} count:{:2d}'.format
('█' * done, '.' * (50 - done), percentage, count))
sys.stdout.flush()
# 从网络下载tar文件,并且,回调显示进度条的函数
urllib.request.urlretrieve(img_url, img_path, _progress)
print("保存到:{}".format(img_path))
# 打印一个空行,将下载日志与数据读取日志分隔开
print("")
# 从tar.gz文件中读取训练数据和测试数据
with tarfile.open(tar_file) as tar_object:
# 每个文件包含10,000个彩色图像和10,000个标签
# 每个图像的宽度、高度、深度(色彩通道),分别是32、32、3
fsize = 10000 * (32 * 32 * 3) + 10000
# 共有6个数据文件(5个训练数据文件、1个测试数据文件)
buffer = np.zeros(fsize * 6, np.uint8)
# 从tar.gz文件中读取数据文件的对象
# -- tar.gz文件中还包含REDME和其他的非数据晚饭吗
members = [file for file in tar_object if file.name in files]
# 对数据文件按照名称排序
# -- 确保按顺序装载数据文件
# -- 确保测试数据最后加载
members.sort(key=lambda member: member.name)
# 从tar.gz文件中读取数据文件的的内容(解压)
# 读取文件开始,增加空行隔开日志,更清晰
print()
for i, member in enumerate(members):
# 得到tar.gz中的数据文件对象
f = tar_object.extractfile(member)
print("正在读取 {} 中的数据……".format(member.name))
# 从数据文件对象中读取数据到缓冲区,按照字节读取
buffer[i * fsize:(i + 1) *
fsize] = np.frombuffer(f.read(), np.ubyte)
# 读取文件结束,增加空行隔开日志
print()
# 解析缓冲区数据
# -- 样本数据是按数据块存储的,每个数据块有3073个字节长
# -- 每个数据块的第一个字节是标签
# -- 紧接着的3072个字节的图像数据(32 * 32 * 3 = 3,072)
# 将每个数据块的第一个字节取出来,形成标签列表
# 从第0个字节开始,将每隔3073个字节的数据取出来形成标签
# 对应的字节索引为0×3073, 1×3073, 2×3073, 3×3073, 4×3073……
labels = buffer[::3073]
# 将标签数据删除,之后,剩下的全部是图像数据
pixels = np.delete(buffer, np.arange(0, buffer.size, 3073))
# 对图像数据进行归一化处理(除以255)
images = pixels.reshape(-1, 3072).astype(np.float32)
# 将样本数据切分成训练数据和测试数据
# 第0个至第50,000个用作训练数据,从第50,000个开始的用作测试数据(共10,000个)
train_images, test_images = images[:50000], images[50000:]
train_labels, test_labels = labels[:50000], labels[50000:]
return train_images, train_labels.astype(np.int32), \
test_images, test_labels.astype(np.int32)

构建卷积神经网络模型
构建卷积神经网络模型也可以分成三个步骤:第一,关键函数。生成卷积层、池化层的关键函数;第二,规划卷积神经网络架构,包括各个神经网络层的排列方式,卷积层的过滤器的尺寸、步长、个数及激活函数,池化层的池化过滤器的尺寸、步长,全连接层的神经元个数等;第三,按照规划的卷积神经网络架构,完成卷积神经网络的构建。
构建卷积层
生成卷积层的函数如下:
tf. layers. conv2d(
inputs,
filters.
kernel_size,
strides=(1,1),
padding=‘valid’,
data_format=’ channels_last’,
dilation_rate=(1,1),
activation=None,
use_bias= True,
kernel_initializer= None,
bias_initializer= tf. zeros_initializer( ),
kernel_regularizer= None,
bias_regularizer= None,
activity_regularizer= None,
kernel_constraint= None,
bias_constraint= None,
trainable=True,
name=None,
reuse=None
)
- input:卷积层的输入张量
- filters: 过滤器的个数。过滤器个数 = 此卷积层输出张量(数据长方体)的深度。
- kernel_size:过滤器的尺寸,用于指定过滤器的宽度和高度,可以是一个包含两个数字的一维列表,也可以是一个数字。如果是一个数字,则是一个方阵
- strides: 滑动步长。
- padding: 填充方式。
- data_format: 输入张量的维度排列方式。
- dilation_rate: 过滤器沿空间的各个维度的扩张率。
- activation: 激活函数。如果设置为None,采用线性激活函数。
- use_bias:是否增加偏置项。
实例
# 第一个卷积层,直接接受输入层(输入的原始图像数据)
# 过滤器个数Filter_count = 32, 过滤器大小 Filter_size: 5×5
# 请注意:过滤器的深度总是与输入张量的深度保持一致,本例中Filter_depth = 3
# 填充方式"same", 表示按照卷积之后图像保持原状来填充。另外一种填充方式"valid"
# 过滤器的激活函数采用tf.nn.relu的方式
# 本层的输出是形状为32×32×64的数据长方体
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=64,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
# 第一个池化层,接收conv1的输出作为本层的输入
# 采用最大化池化方法, 池化过滤器尺寸 3×3, 步长为2,这样实现重叠池化
# 在这种情况下,填充的层数必然是单层,因为输出的数据长方体的尺寸必须满足公式:
# Output_size = ceil(input_size / stride)
# 第二个卷积层和池化层,从第一个池化层接受输入
# 过滤器个数64个,尺寸5×5, 填充方式为保持图像不变,激活函数relu
# 本层输出的数据长方体是16×16×64
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=64,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
构建池化层
生成池化层的函数如下:
tf.layers.max_pooling2d(
inputs,
pool_size,
strides,
padding=‘valid’,
data_format = ‘channels_last’,
name=None
)
实例
# 本层输出的数据长方体为16×16×64
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[
3, 3], strides=2, padding='SAME')
# 第二个池化层,从第二个卷积层接收输入
# 本层输出的数据长方体是8×8×64
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[
3, 3], strides=2, padding='SAME')
完整代码
def cifar10_model(features, labels, mode):
""" 创建CIFAR10图像识别模型
:param features: 输入的特征列表,这里只有一个输入特征张量"x",代表输入的图像
:param labels: 输出的特征列表,这里是图像所述的类别
:param mode: 模式,是训练状态还是评估状态
"""
# (1) 定义输入张量
# 输入层张量,[batch_size, height, weight, depth]
# batch_size等于-1代表重整为实际输入的训练数据个数
# CIFAR10的图像格式为[height, weight, depth] = [32, 32, 3]
input_layer = tf.reshape(features["x"], [-1, 32, 32, 3])
# (2) 构建模型(卷积神经网络)
# 第一个卷积层,直接接受输入层(输入的原始图像数据)
# 过滤器个数Filter_count = 32, 过滤器大小 Filter_size: 5×5
# 请注意:过滤器的深度总是与输入张量的深度保持一致,本例中Filter_depth = 3
# 填充方式"same", 表示按照卷积之后图像保持原状来填充。另外一种填充方式"valid"
# 过滤器的激活函数采用tf.nn.relu的方式
# 本层的输出是形状为32×32×64的数据长方体
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=64,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
# 第一个池化层,接收conv1的输出作为本层的输入
# 采用最大化池化方法, 池化过滤器尺寸 3×3, 步长为2,这样实现重叠池化
# 在这种情况下,填充的层数必然是单层,因为输出的数据长方体的尺寸必须满足公式:
# Output_size = ceil(input_size / stride)
# 本层输出的数据长方体为16×16×64
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[
3, 3], strides=2, padding='SAME')
# 第二个卷积层和池化层,从第一个池化层接受输入
# 过滤器个数64个,尺寸5×5, 填充方式为保持图像不变,激活函数relu
# 本层输出的数据长方体是16×16×64
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=64,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
# 第二个池化层,从第二个卷积层接收输入
# 本层输出的数据长方体是8×8×64
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[
3, 3], strides=2, padding='SAME')
# 将第二个池化层的输出展平,以方便与后面的全连接层连接
pool2_flat = tf.reshape(pool2, [-1, 8 * 8 * 64])
# 全连接层,接受第二个池化层展平后的结果作为输入
# 共有1024个神经元、激活函数tf.nn.relu
dense = tf.layers.dense(
inputs=pool2_flat, units=1024, activation=tf.nn.relu)
# Dropout层,提高模型的健壮性
dropout = tf.layers.dropout(
inputs=dense, rate=0.1, training=(mode == tf.estimator.ModeKeys.TRAIN))
# 输出层,
logits = tf.layers.dense(inputs=dropout, units=10)
predictions = {
# (为 PREDICT 和 EVAL 模式)生成预测值
"classes": tf.argmax(input=logits, axis=1),
# 将 `softmax_tensor` 添加至计算图。用于 PREDICT 模式下的 `logging_hook`.
"probabilities": tf.nn.softmax(logits, name="softmax_tensor")
}
# 如果是评估(测试)模式,那么,执行预测分析
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)
# 计算损失(可用于`训练`和`评价`中)
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
# (3)完成模型训练
# 配置训练操作(用于 TRAIN 模式)
if mode == tf.estimator.ModeKeys.TRAIN:
optimizer = tf.train.AdamOptimizer(learning_rate=1e-4)
train_op = optimizer.minimize(
loss=loss,
global_step=tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)
# 添加评价指标(用于评估)
eval_metric_ops = {
"accuracy": tf.metrics.accuracy(
labels=labels, predictions=predictions["classes"])}
return tf.estimator.EstimatorSpec(
mode=mode, loss=loss, eval_metric_ops=eval_metric_ops)
实战完成代码
#!/usr/local/bin/python3
# -*- coding: UTF-8 -*-
# 导入依赖模块
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np
import tensorflow as tf
import os
import tarfile
import urllib.request
import time
import sys
tf.logging.set_verbosity(tf.logging.INFO)
def read_cifar10_data(path=None):
"""
读取Cifar-10的训练数据和测试数据。
:param path: 保存Cifar-10的本地文件目录。
:Returns: 训练集的图片、训练集标签、测试集图片、测试集标签。
"""
# Cifar-10的官方下载网址,需要下载binary version文件
url = 'https://www.cs.toronto.edu/~kriz/'
tar = 'cifar-10-binary.tar.gz'
files = ['cifar-10-batches-bin/data_batch_1.bin',
'cifar-10-batches-bin/data_batch_2.bin',
'cifar-10-batches-bin/data_batch_3.bin',
'cifar-10-batches-bin/data_batch_4.bin',
'cifar-10-batches-bin/data_batch_5.bin',
'cifar-10-batches-bin/test_batch.bin']
# 如果没有指定本地文件目录,那么,设置目录为"~/data/cifar10"
if path is None:
path = os.path.join(os.path.expanduser('~'), 'data', 'cifar10')
# 确保相关目录、及其子目录存在
os.makedirs(path, exist_ok=True)
# 如果本地文件不存在,那么,从网络上下载Cifar-10数据
tar_file = os.path.join(path, tar)
if not os.path.exists(tar_file):
print("\n文件{}不存在,尝试从网络下载。".format(tar_file))
# 从网上下载图片数据,并且,保存到本地文件
img_url = os.path.join(url, tar)
# 本地文件名称
img_path = os.path.join(path, tar)
print("开始下载: {}, 时间:{}".format(
img_url, time.strftime('%Y-%m-%d %H:%M:%S')))
# 文件下载进度条,
def _progress(count, block_size, total_size):
# 下载完成进度(百分比)
percentage = float(count * block_size) / float(total_size) * 100.0
# 下载进度条总共有50个方块组成(已完成的部分用'█',未完成的用'.')
# 根据count的奇偶性,决定最后一个方块是否出现,实现闪烁的效果
done = int(percentage / 2.0)
done += (count & 1)
# 显示进度条,其中'\r'表示在同一行显示(不换行)
sys.stdout.write('\r[{}{}] 进度:{:.2f} count:{:2d}'.format
('█' * done, '.' * (50 - done), percentage, count))
sys.stdout.flush()
# 从网络下载tar文件,并且,回调显示进度条的函数
urllib.request.urlretrieve(img_url, img_path, _progress)
print("保存到:{}".format(img_path))
# 打印一个空行,将下载日志与数据读取日志分隔开
print("")
# 从tar.gz文件中读取训练数据和测试数据
with tarfile.open(tar_file) as tar_object:
# 每个文件包含10,000个彩色图像和10,000个标签
# 每个图像的宽度、高度、深度(色彩通道),分别是32、32、3
fsize = 10000 * (32 * 32 * 3) + 10000
# 共有6个数据文件(5个训练数据文件、1个测试数据文件)
buffer = np.zeros(fsize * 6, np.uint8)
# 从tar.gz文件中读取数据文件的对象
# -- tar.gz文件中还包含REDME和其他的非数据晚饭吗
members = [file for file in tar_object if file.name in files]
# 对数据文件按照名称排序
# -- 确保按顺序装载数据文件
# -- 确保测试数据最后加载
members.sort(key=lambda member: member.name)
# 从tar.gz文件中读取数据文件的的内容(解压)
# 读取文件开始,增加空行隔开日志,更清晰
print()
for i, member in enumerate(members):
# 得到tar.gz中的数据文件对象
f = tar_object.extractfile(member)
print("正在读取 {} 中的数据……".format(member.name))
# 从数据文件对象中读取数据到缓冲区,按照字节读取
buffer[i * fsize:(i + 1) *
fsize] = np.frombuffer(f.read(), np.ubyte)
# 读取文件结束,增加空行隔开日志
print()
# 解析缓冲区数据
# -- 样本数据是按数据块存储的,每个数据块有3073个字节长
# -- 每个数据块的第一个字节是标签
# -- 紧接着的3072个字节的图像数据(32 * 32 * 3 = 3,072)
# 将每个数据块的第一个字节取出来,形成标签列表
# 从第0个字节开始,将每隔3073个字节的数据取出来形成标签
# 对应的字节索引为0×3073, 1×3073, 2×3073, 3×3073, 4×3073……
labels = buffer[::3073]
# 将标签数据删除,之后,剩下的全部是图像数据
pixels = np.delete(buffer, np.arange(0, buffer.size, 3073))
# 对图像数据进行归一化处理(除以255)
images = pixels.reshape(-1, 3072).astype(np.float32)
# 将样本数据切分成训练数据和测试数据
# 第0个至第50,000个用作训练数据,从第50,000个开始的用作测试数据(共10,000个)
train_images, test_images = images[:50000], images[50000:]
train_labels, test_labels = labels[:50000], labels[50000:]
return train_images, train_labels.astype(np.int32), \
test_images, test_labels.astype(np.int32)
def cifar10_model(features, labels, mode):
""" 创建CIFAR10图像识别模型
:param features: 输入的特征列表,这里只有一个输入特征张量"x",代表输入的图像
:param labels: 输出的特征列表,这里是图像所述的类别
:param mode: 模式,是训练状态还是评估状态
"""
# (1) 定义输入张量
# 输入层张量,[batch_size, height, weight, depth]
# batch_size等于-1代表重整为实际输入的训练数据个数
# CIFAR10的图像格式为[height, weight, depth] = [32, 32, 3]
input_layer = tf.reshape(features["x"], [-1, 32, 32, 3])
# (2) 构建模型(卷积神经网络)
# 第一个卷积层,直接接受输入层(输入的原始图像数据)
# 过滤器个数Filter_count = 32, 过滤器大小 Filter_size: 5×5
# 请注意:过滤器的深度总是与输入张量的深度保持一致,本例中Filter_depth = 3
# 填充方式"same", 表示按照卷积之后图像保持原状来填充。另外一种填充方式"valid"
# 过滤器的激活函数采用tf.nn.relu的方式
# 本层的输出是形状为32×32×64的数据长方体
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=64,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
# 第一个池化层,接收conv1的输出作为本层的输入
# 采用最大化池化方法, 池化过滤器尺寸 3×3, 步长为2,这样实现重叠池化
# 在这种情况下,填充的层数必然是单层,因为输出的数据长方体的尺寸必须满足公式:
# Output_size = ceil(input_size / stride)
# 本层输出的数据长方体为16×16×64
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[
3, 3], strides=2, padding='SAME')
# 第二个卷积层和池化层,从第一个池化层接受输入
# 过滤器个数64个,尺寸5×5, 填充方式为保持图像不变,激活函数relu
# 本层输出的数据长方体是16×16×64
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=64,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
# 第二个池化层,从第二个卷积层接收输入
# 本层输出的数据长方体是8×8×64
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[
3, 3], strides=2, padding='SAME')
# 将第二个池化层的输出展平,以方便与后面的全连接层连接
pool2_flat = tf.reshape(pool2, [-1, 8 * 8 * 64])
# 全连接层,接受第二个池化层展平后的结果作为输入
# 共有1024个神经元、激活函数tf.nn.relu
dense = tf.layers.dense(
inputs=pool2_flat, units=1024, activation=tf.nn.relu)
# Dropout层,提高模型的健壮性
dropout = tf.layers.dropout(
inputs=dense, rate=0.1, training=(mode == tf.estimator.ModeKeys.TRAIN))
# 输出层,
logits = tf.layers.dense(inputs=dropout, units=10)
predictions = {
# (为 PREDICT 和 EVAL 模式)生成预测值
"classes": tf.argmax(input=logits, axis=1),
# 将 `softmax_tensor` 添加至计算图。用于 PREDICT 模式下的 `logging_hook`.
"probabilities": tf.nn.softmax(logits, name="softmax_tensor")
}
# 如果是评估(测试)模式,那么,执行预测分析
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)
# 计算损失(可用于`训练`和`评价`中)
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
# (3)完成模型训练
# 配置训练操作(用于 TRAIN 模式)
if mode == tf.estimator.ModeKeys.TRAIN:
optimizer = tf.train.AdamOptimizer(learning_rate=1e-4)
train_op = optimizer.minimize(
loss=loss,
global_step=tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)
# 添加评价指标(用于评估)
eval_metric_ops = {
"accuracy": tf.metrics.accuracy(
labels=labels, predictions=predictions["classes"])}
return tf.estimator.EstimatorSpec(
mode=mode, loss=loss, eval_metric_ops=eval_metric_ops)
def cifar10_train():
"""
模型入口函数。读取训练数据完成模型训练和评估
"""
# 创建一个卷积神经网络(CNN)的Estimator
cifar10_classifier = tf.estimator.Estimator(
model_fn=cifar10_model, model_dir="./tmp/cifar10_convnet_model")
train_imgs, train_labels, test_imgs, test_labels = read_cifar10_data(
"./data/")
# 模型训练的数据输入函数
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": train_imgs},
y=train_labels,
batch_size=100,
num_epochs=None,
shuffle=True)
# 开始CIFAR10的模型训练
cifar10_classifier.train(
input_fn=train_input_fn,
steps=20000)
# 评估模型并输出结果
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": test_imgs},
y=test_labels,
num_epochs=1,
shuffle=False)
eval_results = cifar10_classifier.evaluate(input_fn=eval_input_fn)
print("\n识别准确率: {:.2f}%\n".format(eval_results['accuracy'] * 100.0))
# 执行测试文件
cifar10_train()
文章出处登录后可见!