高级深度学习—-学习率调度
交流学术思想,加入Q群 号:815783932
找到一个好的学习率非常重要。设置太高会导致训练发散,设置太低会收敛到最优解,但耗时长,更新慢。
1、幂调度
将学习率设置为迭代次数t的函数,公式如下: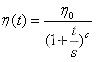
其中初始学习率是η0,幂c一般设置为1,步骤s为超参数。根据迭代次数t可知,每一次epoch都会下降,下降为一开始迅速下降,最后越来越慢。
利用keras 实现 幂调度十分简单。
##幂调度
optimizer=keras.optimizers.SGD(learning_rate=0.001,decay=1e-4)
decay是超参数s的倒数,其中c默认为1。
2、指数调度
![]()
由上方公式可以看出,每经过s步将逐渐下降10倍,不同于幂调度,他是每次都降低10倍。
##指数调度
def exp_decay_fn(epoch):
return 0.01*0.1**(epoch/20)
##若想使S 和初始化学习率 可以自己编写 则可写成下面编码方式
def exponential_decay(lr0,s):
def exponential_decay_fn(epoch):
return lr0*0.1**(epoch/20)
return exponential_decay_fn
exponential_decay_fn=exponential_decay(lr0=0.001,s=20)
lr_scheduler=keras.callbacks.LearningRateScheduler(exponential_decay_fn)
history=model.fit(x_train,y_train,[...],callbacks=[lr_scheduler])
通过回调函数根据epoch 控制学习率的变化。
3、分段恒定调度(最常见最宜控制的)
##解决分段恒定调度 学习率
def priecewise_constant_fn(epoch):
if epoch<5:
return 0.01
elif epoch<15:
return 0.005
else:
return 0.001
lr_scheduler = keras.callbacks.LearningRateScheduler(priecewise_constant_fn)
history=model.fit(model_input, model_output, epochs=928, batch_size=5,callbacks=[lr_scheduler])
通过设定epoch数值的范围来控制,学习率参数的大小,这是我们做实验中最常见的一种方式。
4、性能调度(个人最常用的调度算法)
用下方回调函数时,其中factor=0.5,patience=5。表示每当联系5个轮次的最好验证损失还没有得到改善的时候,会将学习率乘以0.5。官方文档如下:https://tensorflow.google.cn/api_docs/python/tf/keras/callbacks/ReduceLROnPlateau
lr_scheduler = keras.callbacks.ReduceLROnPlateau(factor=0.5, patience=5)
文章出处登录后可见!
已经登录?立即刷新