
简介
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力💪
本文仅记录自己感兴趣的内容
torch.nn.init.xavier_uniform_()
语法
torch.nn.init.xavier_uniform_(tensor, gain=1.0)
作用
根据了解训练深度前馈神经网络的难度 – Glorot, X. & Bengio, Y. (2010) 中描述的方法
使用均匀分布 用值填充输入张量
结果张量将具有从 采样的值,其中
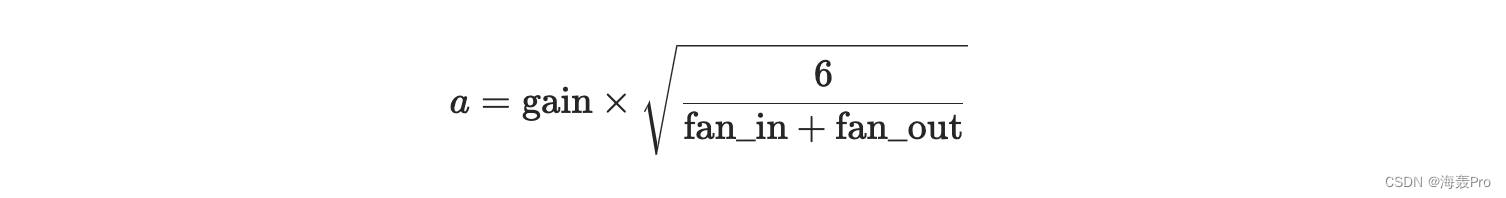

举例
w = torch.empty(3, 5)
print('w : \n', w)
nn.init.xavier_uniform_(w, gain=nn.init.calculate_gain('relu'))
print('w : \n', w)

w = torch.Tensor([[1.0,2,3],[2.0,3,4]])
print('w : \n', w)
nn.init.xavier_uniform_(w, gain=nn.init.calculate_gain('relu'))
print('w : \n', w)

注:w不能为1维
为什么需要Xavier 初始化?

所以论文提出,在每一层网络保证输入和输出的方差相同
参考:https://blog.csdn.net/dss_dssssd/article/details/83959474
个人感觉使用Xavier的作用就是预防一些参数过大或过小的情况,再保证方差一样的情况下进行缩放,便于计算
参考
- https://pytorch.org/docs/stable/nn.init.html
- https://blog.csdn.net/dss_dssssd/article/details/83959474
结语
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正

文章出处登录后可见!
已经登录?立即刷新