一、背景介绍
模型部署基本步骤分为模型选择、模型部署、运行,如果需要在特定的场景下定制化模型,则还需要进行数据集的选择、数据集格式转换、微调。
根据上述的步骤本教程选取如下的开源模型、数据集,来对医疗场景下进行定制化模型部署。当然模型部署对GPU要求非常高,所以本教程将使用AutoDL提供的服务器资源。
- 地址:https://www.autodl.com/home
ChatGLM-6B(模型):清华开源的、支持中英双语对话的语言模型,具有62亿参数。
- 地址:https://github.com/THUDM/ChatGLM-6B
HuatuoGPT-sft-data-v1(数据集):医疗数据集,拥有333M庞大数据。
- 地址:https://huggingface.co/datasets/FreedomIntelligence/HuatuoGPT-sft-data-v1
ChatGLM Efficient Tuning(微调):针对ChatGLM-6B进行微调,集成多个微调框架。
- 地址:https://github.com/hiyouga/ChatGLM-Efficient-Tuning/blob/main/README_zh.md
二、创建服务器资源
进入AutoDL官网申请一台服务器资源,可以按如下图步骤操作:
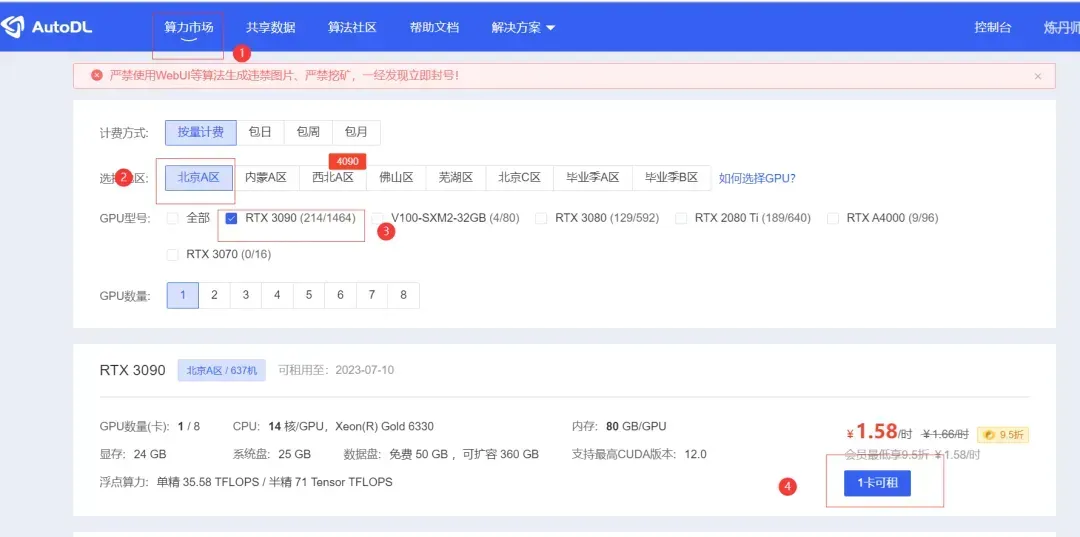
进入后选择社区镜像,在红框处输入:
WhaleOps/dolphinschedulerllm/dolphinscheduler-llm-0521
这个镜像集成了基础的模型运行环境,可以方便以后部署。
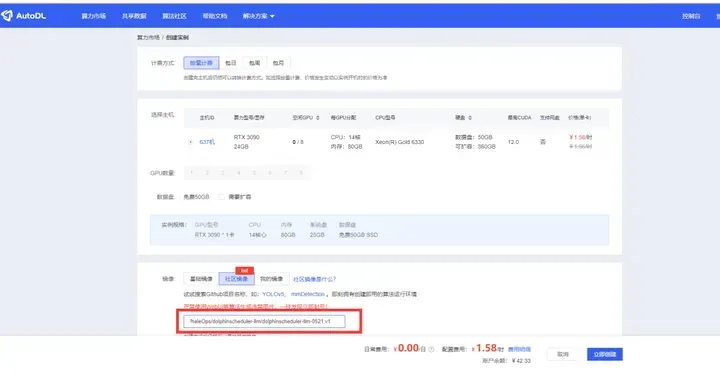
创建完成后等待服务器创建完成即可。创建完成后可以参考下图:
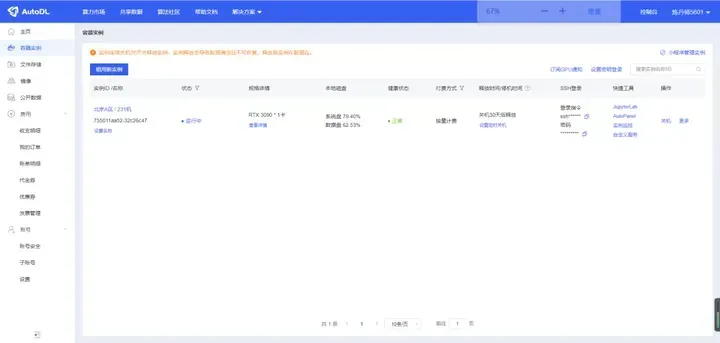
至此服务器资源已创建完成。
三、模型部署
点击JupyterLab进入服务器的控制台。
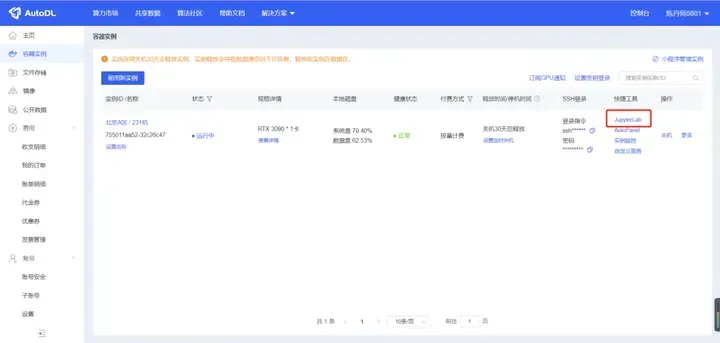
进入终端,正式开始模型部署。

3.1 下载ChatGLM模型
首先进入/root/autodl-tmp目录,在这里创建一个文件夹用来保存ChatGLM模型,文件目录可以参考下图用git_project来存放模型。
![]()
进入git_project目录输入git clone https://huggingface.co/THUDM/chatglm-6b 命令下载模型,模型文件比较大可能要等一段时间。下载完成后可以进入chatglm-6b目录,目录内容参考下图,后面运行就需要依赖下图的模型。

3.2 下载ChatGLM运行依赖
回到git_project目录输入git clone https://github.com/THUDM/ChatGLM-6B.git 命令,下载完成后进入ChatGLM-6B目录,可以看到如下目录:

我们使用pip install -r requirements.txt 命令下载脚本依赖的库。等待命令跑完即可。
3.3 ChatGLM运行
运行模型需要配置一下模型的文件位置,输入vim web_demo.py ,修改内容参考下图红框处。
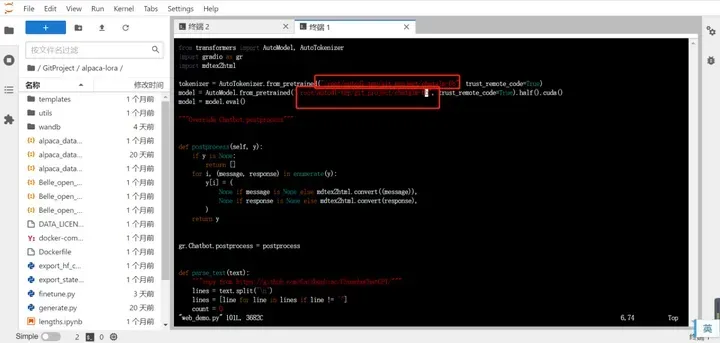
把红框处的内容改成我们刚刚下载好的模型地址。上图是已经改过的,可以参考下。
现在已经可以运行了,输入 python web_demo.py 试试看。
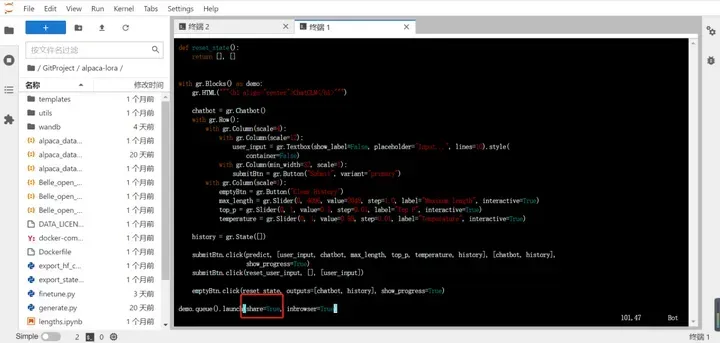
运行后可以看到只能够在本地自己使用,为了让运行的模型可以分享给大家使用,可以修改参数share=True,参数位置位于web_demo.py最底部。可以参考下图:
再尝试输入 python web_demo.py 后可以看到控制台打印了url地址,参考下图:
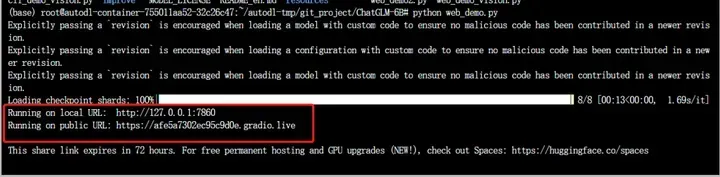
复制 public URL的地址,放到浏览器中体验一下部署好的模型吧。
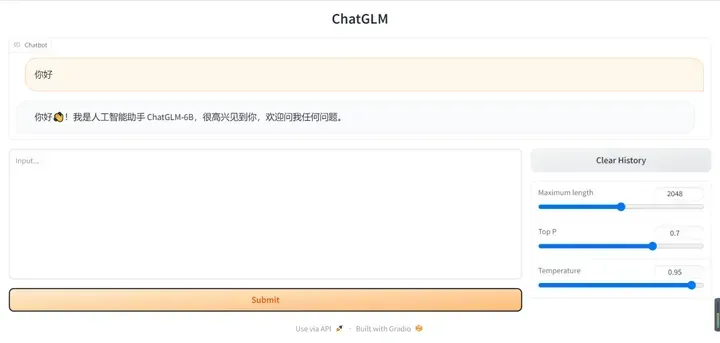
这是部署好的界面:
四、数据集
虽然基础模型在各个方面都了解,但一旦深入就开始胡言乱语了。下面我们开始对模型微调,使它在医疗方面表现的更好一些。
4.1 下载数据集
AutoDL服务器下载HuggingFace内容比较慢,所以先在本地下载好数据集后,再上传到服务器。
进入这个网址,按下图步骤进行操作:
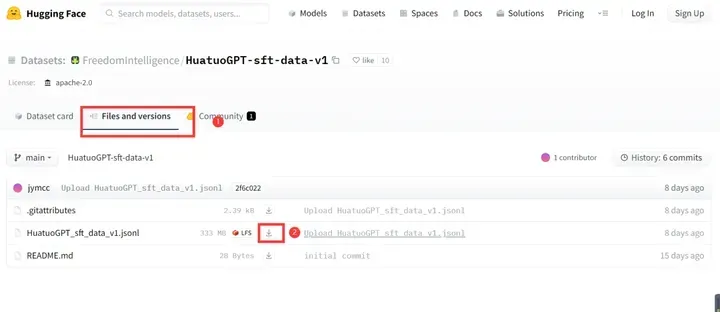
4.2 数据集环境配置
进入git_project目录,下载微调框架,输入 git clone :
https://github.com/hiyouga/ChatGLM-Efficient-Tuning.git。
进入ChatGLM-Efficient-Tuning目录后可以看到如下子目录:

我们进入data目录,在data目录下新建huatuo_gpt文件夹用来存放我们的数据集和数据集格式转换脚本。
把下载好的数据集放到huatuo_gpt下,并新增一个脚本文件。参考图如下:

脚本可以参考链接,具体脚本编写参考这个网址:
https://huggingface.co/docs/datasets/dataset_script
回到data目录,编辑dataset_info.json文件,对刚才新增的数据集进行配置。把dataset_info.json划到最后面,新增如下红框内容:
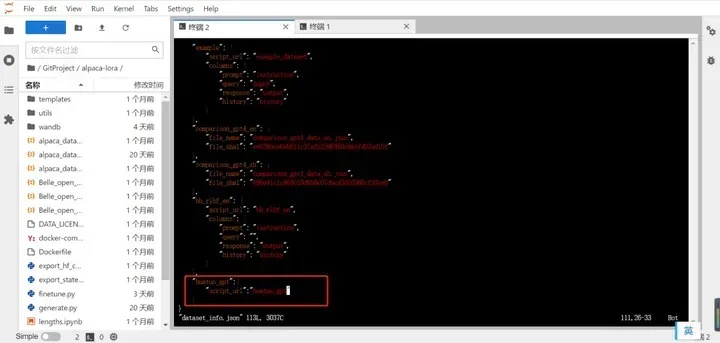
至此数据集环境已经配置好了。
五、微调
环境已经配置完成了,现在可以进行微调,具体步骤如下。
回到ChatGLM-Efficient-Tuning目录,输入命令:
CUDA_VISIBLE_DEVICES=0 python src/train_sft.py \
--do_train \
--model_name_or_path /root/autodl-tmp/git_project/chatglm-6b \
--dataset huatuo_gpt \
--finetuning_type lora \
--output_dir /root/autodl-tmp/train_model \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--fp16 > output.log &对部分参数讲解一下:
–model_name_or_path:基础模型的文件位置。
–dataset:刚才在dataset_info中设置的名称。
–finetuning_type:微调模型的类型。
–output_dir:训练后模型的文件位置。
具体模型参数可以参考这个地址:
https://github.com/hiyouga/ChatGLM-Efficient-Tuning/wiki/%E4%BD%BF%E7%94%A8%E6%96%B9%E6%B3%95#%E5%BE%AE%E8%B0%83%E8%AE%AD%E7%BB%83
运行这个脚本大概需要40小时左右。
六、运行
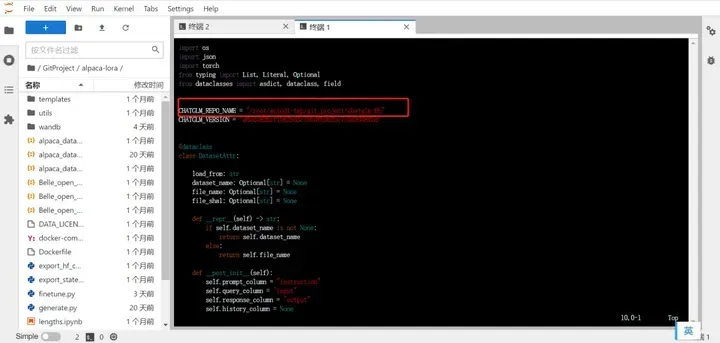
微调结束后进入ChatGLM-Efficient-Tuning目录,输入vim src/utils/config.py命令修改一下基础模型的文件位置,具体参考如下:
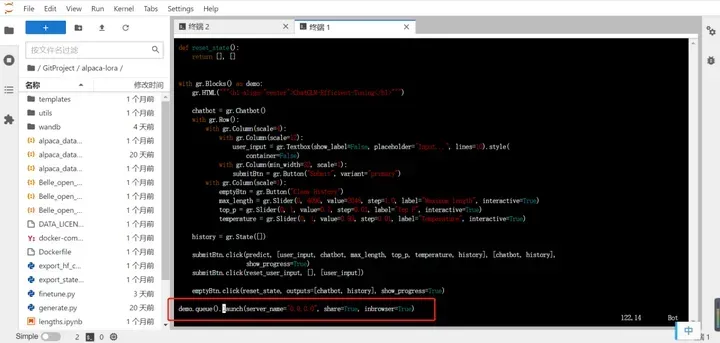
为了可以在浏览器中访问,我们回到ChatGLM-Efficient-Tuning目录输入vim src/web_demo.py, 划到最下面修改参数为share=True,参考如下:
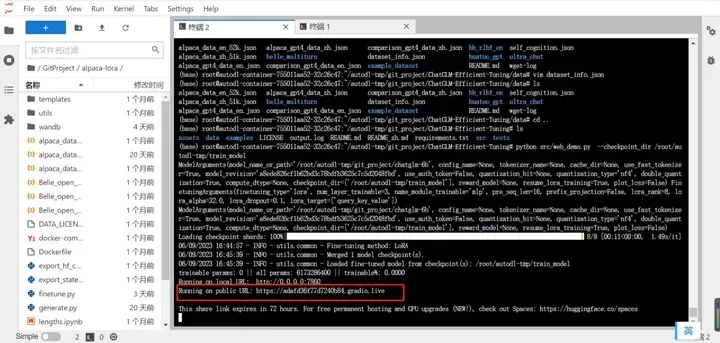
现在可以运行微调后的模型了,输入python src/web_demo.py –checkpoint_dir 训练后模型的文件位置 命令。可以在控制台看见如下红框的地址。复制到浏览器上就可以体验了。
七、训练前后对比
微调前的效果:

微调后的效果:

可以看到微调前的对医疗的回答结果比较浅显,微调后回答结果专注治疗、解决办法。
到此就结束了,大家可以自己动手尝试一下。
更多AI小知识欢迎关注“神州数码云基地”公众号,回复“AI与数字化转型”进入社群交流
版权声明:文章由神州数码武汉云基地团队实践整理输出,转载请注明出处。
版权声明:本文为博主作者:神州数码云基地原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/CBGCampus/article/details/135262728