今天,人工智能技术的快速发展和广泛应用已经引起了大众的关注和兴趣,它不仅成为技术发展的核心驱动力,更是推动着社会生活的全方位变革。特别是作为AI重要分支的深度学习,通过不断刷新的表现力已引领并定义了一场科技革命。大型深度学习模型(简称AI大模型)以其强大的表征能力和卓越的性能,在自然语言处理、计算机视觉、推荐系统等领域均取得了突破性的进展。尤其随着AI大模型的广泛应用,无数领域因此受益。
然而,AI大模型的研究和应用是一次复杂且困难的探索。其在训练方法、优化技术、计算资源、数据质量、安全性、伦理性等方面的挑战和难题需要人们去一一应对和破解。以上就是作者编写本书的初衷和目标:希望通过本书能为研究者、工程师、学者、学生等群体提供一份详尽的指南和参考,为读者提供一个理论与实践相结合的全面视角,使他们能够理解并运用AI大模型,同时也希望本书能引领读者探索更多的新问题,从而推动人工智能的持续发展。
AI大模型的训练需要巨大的计算资源和复杂的分布式系统支持。从机器学习到AI大模型的发展历程来看,只有掌握了深度学习的基本概念、经典算法和网络架构,才能更好地理解和应用AI大模型。此外,分布式训练和并行策略在AI大模型训练中起着关键作用,能够有效提升训练效率和模型性能。同时,AI大模型的应用也涉及自然语言处理、计算机视觉等多个领域,为各类读者提供了更广阔的应用空间
一、哪些方法可以提升小目标检测的效果?
-
提高图像分辨率。小目标在边界框中可能只包含几个像素,那么能通过提高图像的分辨率以增加小目标的特征的丰富度。
-
提高模型的输入分辨率。这是一个效果较好的通用方法,但是会带来模型inference速度变慢的问题。
-
平铺图像。

-
数据增强。小目标检测增强包括随机裁剪、随机旋转和镶嵌增强等。
-
自动学习anchor。
-
类别优化。
二、MobileNet系列模型的结构和特点?
MobileNet是一种轻量级的网络结构,主要针对手机等嵌入式设备而设计。MobileNetv1网络结构在VGG的基础上使用depthwise Separable卷积,在保证不损失太大精度的同时,大幅降低模型参数量。
Depthwise separable卷积是由Depthwise卷积和Pointwise卷积构成。
Depthwise卷积(DW)能有效减少参数数量并提升运算速度。但是由于每个特征图只被一个卷积核卷积,因此经过DW输出的特征图只包含输入特征图的全部信息,而且特征之间的信息不能进行交流,导致“信息流通不畅”。Pointwise卷积(PW)实现通道特征信息交流,解决DW卷积导致“信息流通不畅”的问题。
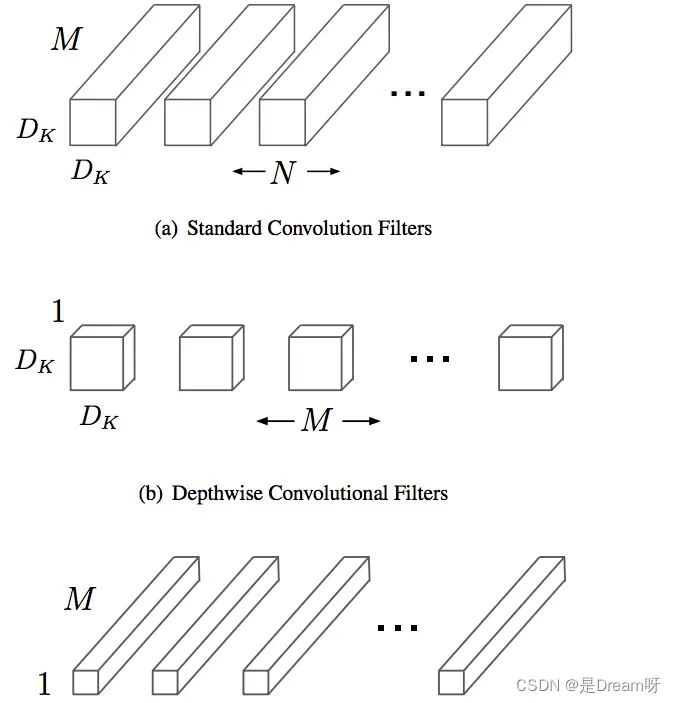
Depthwise Separable卷积和标准卷积的计算量对比:
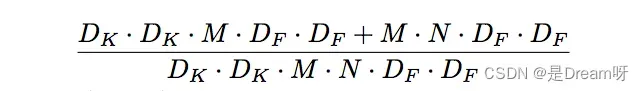
相比标准卷积,Depthwise Separable卷积可以大幅减小计算量。并且随着卷积通道数的增加,效果更加明显。
并且Mobilenetv1使用stride=2的卷积替换池化操作,直接在卷积时利用stride=2完成了下采样,从而节省了卷积后再去用池化操作去进行一次下采样的时间,可以提升运算速度。
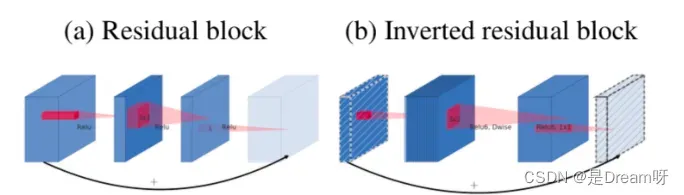
MobileNetV2在MobileNetV1的基础上引入了Linear Bottleneck 和 Inverted Residuals。
MobileNetV2使用Linear Bottleneck(线性变换)来代替原本的非线性激活函数,来捕获感兴趣的流形。实验证明,使用Linear Bottleneck可以在小网络中较好地保留有用特征信息。
Inverted Residuals与经典ResNet残差模块的通道间操作正好相反。由于MobileNetV2使用了Linear Bottleneck结构,使其提取的特征维度整体偏低,如果只是使用低维的feature map效果并不会好。如果卷积层都是使用低维的feature map来提取特征的话,那么就没有办法提取到整体的足够多的信息。如果想要提取全面的特征信息的话,我们就需要有高维的feature map来进行补充,从而达到平衡。
MobileNetV3在整体上有两大创新:
1.互补搜索技术组合:由资源受限的NAS执行模块级搜索;由NetAdapt执行局部搜索,对各个模块确定之后网络层的微调。
2.网络结构改进:进一步减少网络层数,并引入h-swish激活函数。
作者发现swish激活函数能够有效提高网络的精度。然而,swish的计算量太大了。作者提出h-swish(hard version of swish)如下所示:
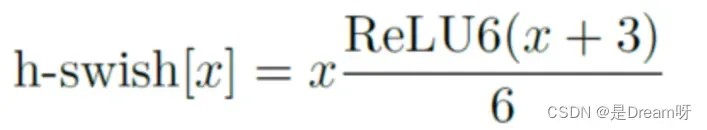
这种非线性在保持精度的情况下带了了很多优势,首先ReLU6在众多软硬件框架中都可以实现,其次量化时避免了数值精度的损失,运行快。
MobileNetV3模型结构的优化:
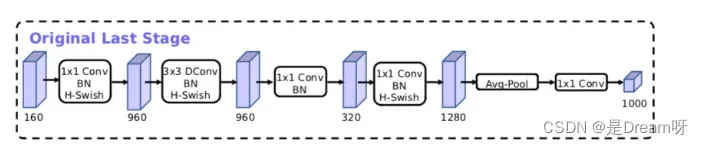
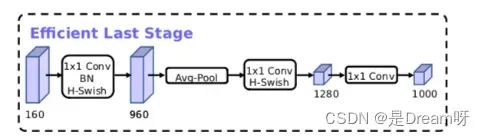
MobileNetV3的论文:《Searching for MobileNetV3》
三、ViT(Vision Transformer)模型的结构和特点?
ViT模型特点:
1.ViT直接将标准的Transformer结构直接用于图像分类,其模型结构中不含CNN。
2.为了满足Transformer输入结构要求,输入端将整个图像拆分成小图像块,然后将这些小图像块的线性嵌入序列输入网络中。在最后的输出端,使用了Class Token形式进行分类预测。
3.Transformer比CNN结构少了一定的平移不变性和局部感知性,在数据量较少的情况下,效果可能不如CNN模型,但是在大规模数据集上预训练过后,再进行迁移学习,可以在特定任务上达到SOTA性能。
ViT的整体模型结构:
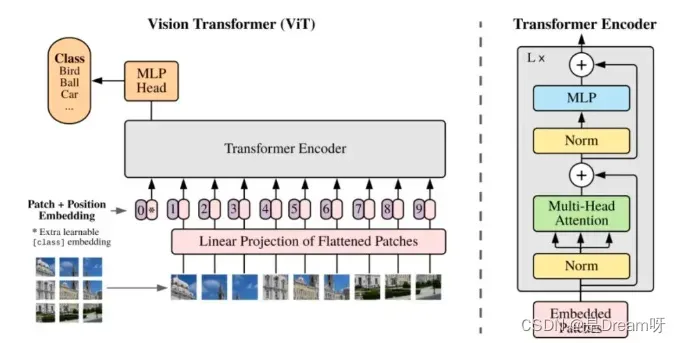
其可以具体分成如下几个部分:
-
图像分块嵌入
-
多头注意力结构
-
多层感知机结构(MLP)
-
使用DropPath,Class Token,Positional Encoding等操作。
四、有哪些经典的轻量型人脸检测模型?
人脸检测相对于通用目标检测来说,算是一个子任务。比起通用目标检测任务动辄检测1000个类别,人脸检测任务主要聚焦于人脸的单类目标检测,使用通用目标检测模型太过奢侈,有点“杀鸡用牛刀”的感觉,并且大量的参数冗余,会影响部署侧的实用性,故针对人脸检测任务,学术界提出了很多轻量型的人脸检测模型,Rocky在这里给大家介绍一些比较有代表性的:
- libfacedetection
- Ultra-Light-Fast-Generic-Face-Detector-1MB
- A-Light-and-Fast-Face-Detector-for-Edge-Devices
- CenterFace
- DBFace
- RetinaFace
- MTCNN
五、LFFD人脸检测模型的结构和特点?
Rocky在实习/校招面试中被多次问到LFFD模型以及面试官想套取LFFD相关算法方案的情况,说明LFFD模型在工业界还是比较有价值的,下面Rocky就带着大家学习一下LFFD模型的知识:
LFFD(A-Light-and-Fast-Face-Detector-for-Edge-Devices)适用于人脸、行人、车辆等单目标检测任务,具有速度快,模型小,效果好的特点。LFFD是Anchor-free的方法,使用感受野替代Anchors,并在主干结构上抽取8路特征图对从小到大的人脸进行检测,检测模块分为类别二分类与边界框回归。
LFFD模型结构
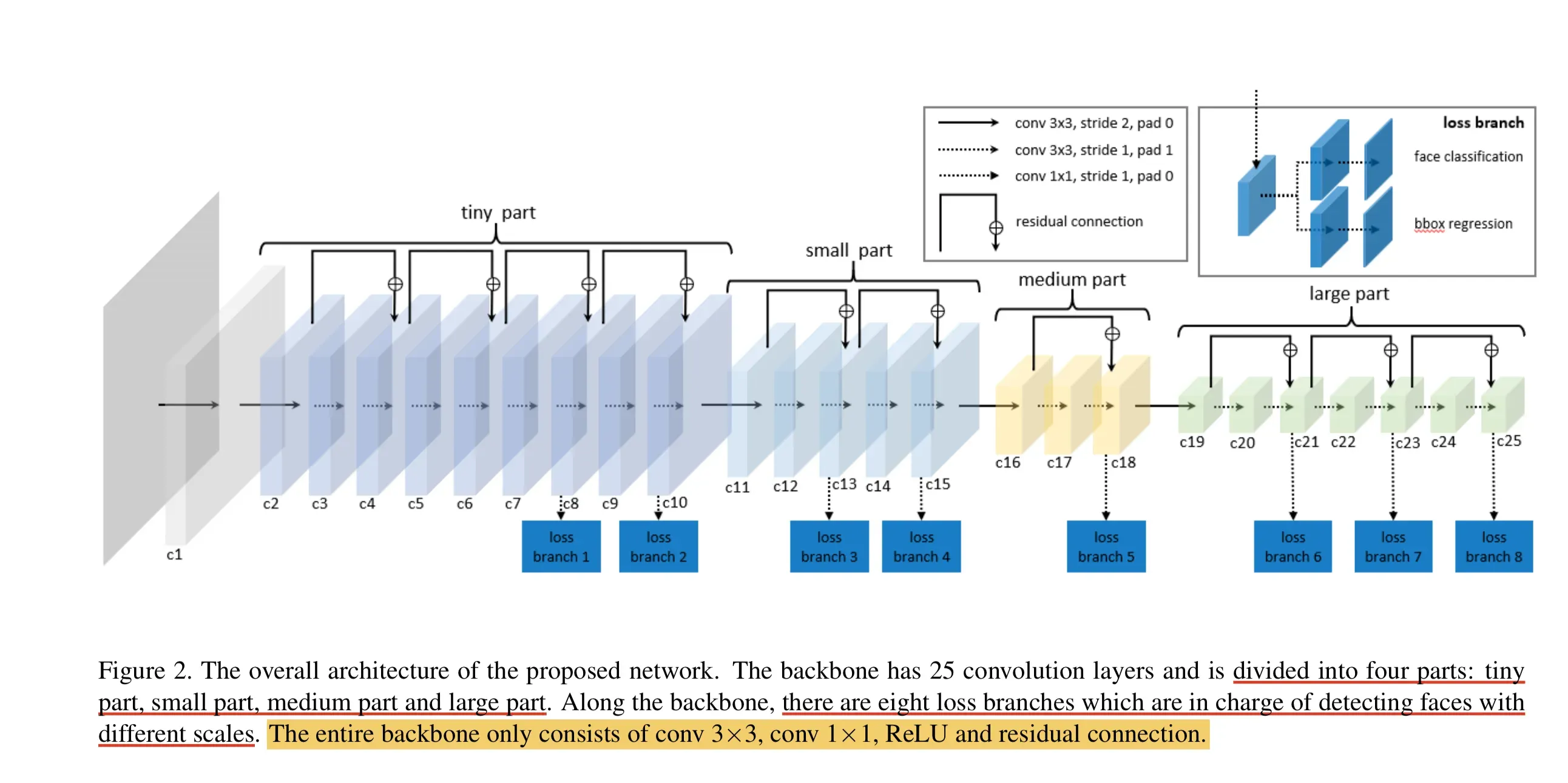
我们可以看到,LFFD模型主要由四部分组成:tiny part、small part、medium part、large part。
模型中并没有采用BN层,因为BN层会减慢17%的推理速度。其主要采用尽可能快的下采样来保持100%的人脸覆盖。
LFFD主要特点:
-
结构简单直接,易于在主流AI端侧设备中进行部署。
-
检测小目标能力突出,在极高分辨率(比如8K或更大)画面,可以检测其间10个像素大小的目标;
LFFD损失函数
LFFD损失函数是由regression loss和classification loss的加权和。
分类损失使用了交叉熵损失。
回归损失使用了L2损失函数。
LFFD论文地址:LFFD: A Light and Fast Face Detector for Edge Devices论文地址
六、GAN的核心思想?
2014年,Ian Goodfellow第一次提出了GAN的概念。Yann LeCun曾经说过:“生成对抗网络及其变种已经成为最近10年以来机器学习领域最为重要的思想之一”。GAN的提出让生成式模型重新站在了深度学习这个浪潮的璀璨舞台上,与判别式模型开始谈笑风生。
GAN由生成器和判别器
组成。其中,生成器主要负责生成相应的样本数据,输入一般是由高斯分布随机采样得到的噪声
。而判别器的主要职责是区分生成器生成的样本与
样本,输入一般是
样本与相应的生成样本,我们想要的是对
样本输出的置信度越接近
越好,而对生成样本输出的置信度越接近
越好。与一般神经网络不同的是,GAN在训练时要同时训练生成器与判别器,所以其训练难度是比较大的。
在提出GAN的第一篇论文中,生成器被比喻为印假钞票的犯罪分子,判别器则被当作警察。犯罪分子努力让印出的假钞看起来逼真,警察则不断提升对于假钞的辨识能力。二者互相博弈,随着时间的进行,都会越来越强。在图像生成任务中也是如此,生成器不断生成尽可能逼真的假图像。判别器则判断图像是图像,还是生成的图像。二者不断博弈优化,最终生成器生成的图像使得判别器完全无法判别真假。
GAN的对抗思想主要由其目标函数实现。具体公式如下所示:
![]()
上面这个公式看似复杂,其实不然。跳出细节来看,整个公式的核心逻辑其实就是一个min-max问题,深度学习数学应用的边界扩展到这里,GAN便开始发光了。
接着我们再切入细节。我们可以分两部分开看这个公式,即判别器最小化角度与生成器最大化角度。在判别器角度,我们希望最大化这个目标函数,因为在公示第一部分,其表示样本
输入判别器后输出的置信度,当然是越接近
越好。而公式的第二部分表示生成器输出的生成样本
再输入判别器中进行进行二分类判别,其输出的置信度当然是越接近
越好,所以
越接近
越好。
在生成器角度,我们想要最小化判别器目标函数的最大值。判别器目标函数的最大值代表的是真实数据分布与生成数据分布的JS散度,JS散度可以度量分布的相似性,两个分布越接近,JS散度越小(JS散度是在初始GAN论文中被提出,实际应用中会发现有不足的地方,后来的论文陆续提出了很多的新损失函数来进行优化)
- 原始GAN及其训练逻辑
- DCGAN
- CGAN
- WGAN
- LSGAN
- PixPix系列
- CysleGAN
- SRGAN系列
AI大模型推荐
推荐用书:实战AI大模型

实战AI大模型》详细介绍了从基本概念到实践技巧的诸多内容,全方位解读AI大模型,循序渐进、由浅入深。书中配有二维码视频,使读者身临其境,迅速、深入地掌握各种经验和技巧。本书还附带了丰富的额外资源:开源工具和库、数据集和模型案例研究和实际应用、在线交流社区等。读者可以综合利用这些资源,获得更丰富的学习体验,加速自己的学习和成长。
《实战AI大模型》是一本旨在填补人工智能(AI)领域(特别是AI大模型)理论与实践之间鸿沟的实用手册。书中介绍了AI大模型的基础知识和关键技术,如Transformer、BERT、ALBERT、T5、GPT系列、InstructGPT、ChatGPT、GPT 4、PaLM和视觉模型等,并详细解释了这些模型的技术原理、实际应用以及高性能计算(HPC)技术的使用,如并行计算和内存优化。
同时,《实战AI大模型》还提供了实践案例,详细介绍了如何使用Colossal AI训练各种模型。无论是人工智能初学者还是经验丰富的实践者,都能从本书学到实用的知识和技能,从而在迅速发展的AI领域中找到适合自己的方向。
购买链接:https://item.jd.com/14281522.html

版权声明:本文为博主作者:是Dream呀原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_51390582/article/details/135173150