
欢迎关注博主 Mindtechnist 或加入【Linux C/C++/Python社区】一起探讨和分享Linux C/C++/Python/Shell编程、机器人技术、机器学习、机器视觉、嵌入式AI相关领域的知识和技术。
Python中import模块导入的实现原理
- 什么是模块
- import搜索路径
- import导入模块的原理
- 图书推荐
专栏:《python从入门到实战》
什么是模块
一个.py文件就是一个模块,即Module。
模块分为三种:python标准库、第三方模块、应用程序自定义模块。
- import语句 – 导入模块
- Directory – 文件夹(空的)
- Package – 比文件夹多了一个__init__.py
"""
file: cal.py
"""
def add(x, y)
return x+y
def sub(x, y)
return x-y
print(‘hello cal’)
"""
file: test.py
"""
import cal
print(cal.add(1, 2))
import做了什么?
import导入模块的时候,首先会把导入的文件执行一遍,比如说我们运行test.py的时候,print(‘hello cal’)也会被执行,因为import cal的时候就把cal.py运行了一遍。所以,我们在模块文件中只写功能(也就是函数),而不要写可执行的语句。
- 执行被引入的py文件,即使只引入一个变量(from cal import add
),也会运行整个文件。 - 引入变量名 → 文件名变量
引入多个模块
import cal, time
只引入一个方法
# 只引入一个方法
from cal import add
print(add(1, 2)) #可以直接使用add,不用加cal.
引入所有方法,不推荐使用,你并不知道都引入了哪些变量,可能会出现本文件变量与引入变量名字重复的情况。
#引入所有方法 – 不推荐使用,你并不知道都引入了哪些变量,可能会出现本文件变量与引入变量名字重复的情况。
from cal import *
#新的变量名会覆盖旧的变量名
#+++++++++++++++++++++++++++
from cal import *
def add(x, y)
return x+y+100
print(add(1, 2))
#+++++++++++++++++++++++++++
def add(x, y)
return x+y+100
from cal import *
print(add(1, 2))
#+++++++++++++++++++++++++++
import搜索路径
import sys
print(sys.path) #查看路径
path中包含python自己定义的路径,以及当前执行的py文件的路径,也就是说当前执行路径会被自动加入到sys.path中,import就是按照这些路径去搜索被引入的变量的。
也可以通过手动添加路径
from path import cal
#path就是cal所在的路径
import导入模块的原理
首先import会根据路径找到文件,根据路径找到模块后把模块加载到内存中执行一遍,执行的时候是把模块的内容拷贝到当前文件执行。import导入是将模块从磁盘中把磁盘文件导入到内存中,这个速度是比较慢的,实际上,在导入时会有一个导入缓存,同一个模块在导入第一次的时候会有一个缓存,以后再导入都是用的缓存的导入,所以有时候你可能遇到这样的问题,被导入的文件已经删除了,但是程序还是能运行,这是因为程序使用的是缓存的导入模块。
from path import mode,它相当于把路径进行了一次拼接path\mode.py,这是from的工作。
路径拼接是在当前执行文件的路径基础上进行拼接。
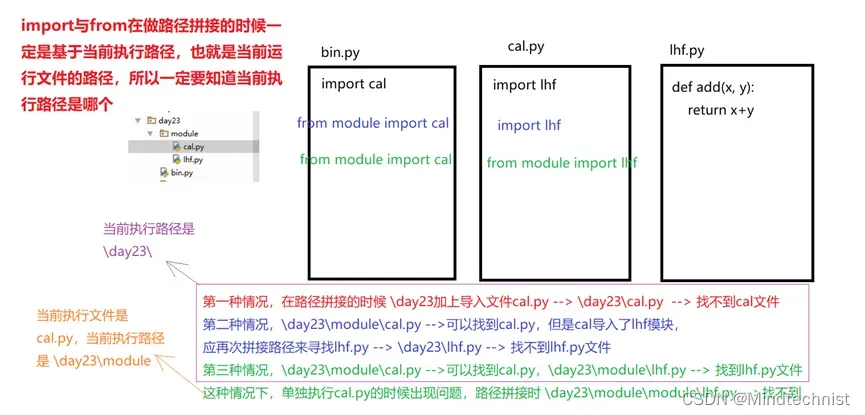
当引入了很多模块的时候,一个目录下会有很多py文件,一般把bin.py作为要执行的文件,也就是整个程序的入口。而逻辑主文件叫做main.py,这里面包含了程序的主要逻辑,其他功能都放到其它文件中作为一个模块。我们在运行的时候,运行bin.py,由bin.py去调用main.py中的主逻辑。也就是说只有bin是可执行的,其余文件都不应作为执行文件。
前面说过,sys.path中只会加入当前运行程序所在的路径,bin.py是整个程序的运行文件,也就是说sys.path中只会加入bin.py的路径,假如说文件有如下导入关系

假如说main.py和cal.py在同一级目录,那么不用加路径即可导入,但是如果bin.py和这两个文件不在同一级目录(比如在上一级目录),那么bin.py导入main.py的时候就要加上main.py的路径,但是这样在执行的时候会报错,因为bin.py间接导入了cal.py,并且bin.py只加了main.py的路径而没有加cal.py的路径,前面说过sys.py只会包含当前运行路径,也就是bin.py的路径。
解决方法有两个:
- 在main.py中加上cal.py的路径from path import cal;
- 把路径加到sys.path中;
file 获取当前文件名
os.path.dirname(__file__) #获取当前文件路径
os.path.dirname(os.path.dirname(__file__)) #获取当前文件的上一级路径
pycharm会自己根据当前文件名获取绝对路径,并把绝对路径通过os.path.dirname()返回给我们os.path.dirname(file),但是在终端运行的时候,终端并没有这个功能,我们需要自己去找到绝对路径,然后根据绝对路径找到文件名,并反推出上一级目录。
p = os.path.dirname(__file__) #获取当前文件的绝对路径
BASEDIR = os.path.dirname(os.path.dirname(p))
sys.psth.append(BASEDIR)
实际上,这三步的操作相当于把当前运行文件的上一级目录通过相对路径的方式添加到了环境变量。如果我们以绝对路径的方式添加环境变量,当我们换了电脑或者环境,环境变量就失效了。我们这样通过程序找出相对路径来添加到环境变量,只要将当前整个工程一块拷贝到别的机器,就一定可以找到这个环境变量。
图书推荐
🔥强化学习:原理与Python实战
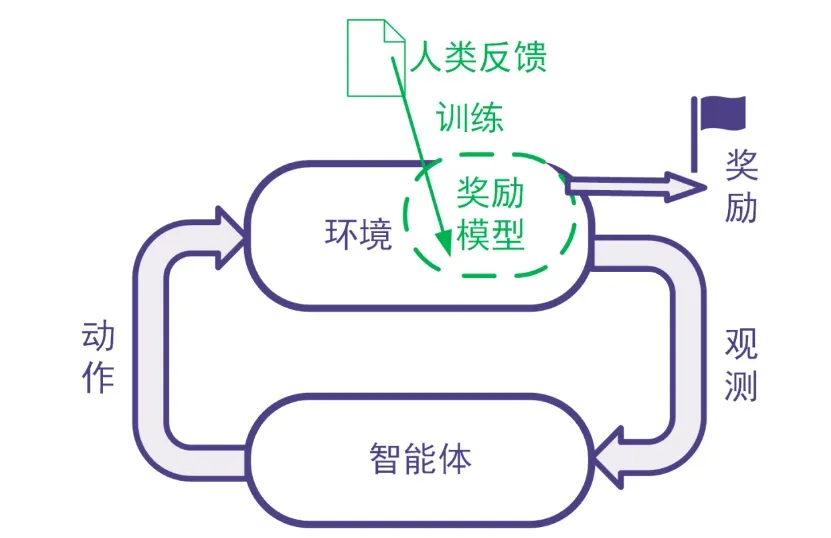
强化学习利用奖励信号训练智能体。有些任务并没有自带能给出奖励信号的环境,也没有现成的生成奖励信号的方法。为此,可以搭建奖励模型来提供奖励信号。在搭建奖励模型时,可以用数据驱动的机器学习方法来训练奖励模型,并且由人类提供数据。我们把这样的利用人类提供的反馈数据来训练奖励模型以用于强化学习的系统称为人类反馈强化学习,示意图如下。
想要学好这些知识,一定要有好的工具书,下面推荐一本理论与实践结合的好书。书名:《强化学习:原理与Python实战》
作者:肖智清
出版社:机械工业出版社
购买链接:点击购买



文章出处登录后可见!