Yang S, Chen X, Liao J. Uni-paint: A Unified Framework for Multimodal Image Inpainting with Pretrained Diffusion Model[C]//Proceedings of the 31st ACM International Conference on Multimedia. 2023: 3190-3199.
效果展示
![]()
使用不同模态引导图像Inpainting生成任务的效果。左侧是单模态引导生成,从左至右的引导条件分别为:无条件、文本、简笔画、参考图。右侧是多模态引导生成:从左至右的引导条件分别为:文本+简笔画、 文本+参考图、参考图+简笔画、文本+简笔画+参考图。
摘要
现有方法的问题:使用Inpainting时,为了使生成的结果更加可控,我们不仅希望能用文本引导生成,也希望能用其它模态进行引导。但现有的基于扩散模型的Inpainting方法,只能使用单个模态引导,对于不同的模态,要针对性的进行task-specifc训练。而且这种针对单个的模态训练,也限制了模型的多模态信息处理能力。
为此本文提出了Uni-paint,使用统一的框架,支持不同模态信息的引导生成。这些模态包括文本、简笔画、参考图,同时也可以组合多种模态。另外,Uni-paint基于预训练的SD模型进行few-shot,无需在特定数据集上进行task-specifc的训练。
背景介绍
基于扩散模型的Inpainting可以分为2大类:(1) training-based method: 训练image-to-image的扩散模型,基于预训练的文生图模型加控制条件(如masked image)。这类方法推理更快,但是训练需要大规模的数据,而且针对不同模态的扩展能力差。(2) few-shot method: 基于预训练模型的能力,通过model prior或guided sampling进行Inpainting,不需要额外的训练数据。本文属于这一类。
本文主要贡献有三点:
(1) 首次提出了一个统一的多种模态引导生成框架Uni-paint。
(2) Mask Finetuing: 在非mask区域finetune预训练的SD模型,让模型具备在mask区域生成上下文合理的内容的能力。
(3) Mask Attention:一种attention机制,优化模型在mask区域的生成效果。
方法
1. Mask finetuing
原始的SD已经具备生成合理图片的能力,通过已知区域(也是一种mask区域)的finetuing,模型便拥有了在mask区域生成上下文合理的内容的能力。
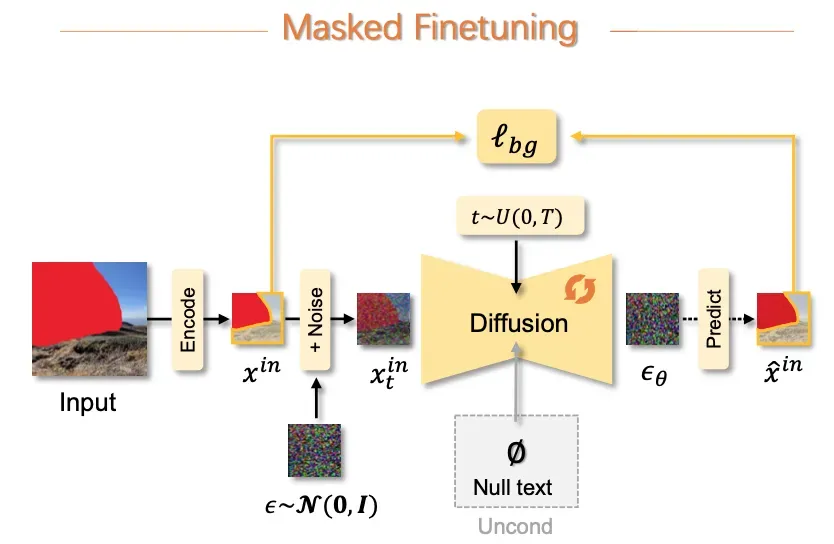
具体方法:使用无prompt的数据(Unconditional),finetune预训练的SD模型,让模型只生成已知的部分。输入是加噪的masked image,输出是去噪后的masked image。
效果

Sampling with blending
为了保持非mask区域的不变,也使用融合技术,在每次去噪之后,在mask区域,用原图加噪的图像替换生成的图像。(类似RePaint第一步)
2. Text-driven inpainting
完成了mask funtuning之后,模型便具备了在un-mask区域生成内容的能力。这时候以文本作为控制条件,便能生成相应的内容。因为mask funetuning的时候,没有使用文本控制,因此模型对文本的响应能力会比较弱,为此作者提出了mask attention进行改善。
3. Exemplar-driven inpainting
对于输入的参考图,需要先转成embedding,再输入到模型的文本接口中作为控制条件。
如何转成embedding?SD的文本encoder使用的是CLIP的text encoder,因此本文使用CLIP的图像encoder将参考图转成embedding。具体计算方式如下:
输入参考图,使用CLIP的image encoder转成图像embedding。然后将输入文本中的每个token,使用CLIP的text encoder转成文本embedding,图像embedding与每个token的文本embedding相乘,最大的token作为参考图的token表示。
为了使模型对输入参考图有响应,我们还需要使用参考图的token输入进行finetune。有了参考图的token表示,我们将作为控制条件,输入SD模型进行finetuning(可以和mask finetuning并行进行,加个loss),loss的形式为
4. Stroke-driven inpainting
对于简笔画,mask funetuning得到的模型便有能力处理这种输入(可能来源于SD),只需要将简笔画与原图在特定的去噪步数时进行融合即可,如下:
对于某一时刻t的噪声图像,新图像为加噪原图与加噪简笔画图融合的结果。
5. 多种模态引导生成
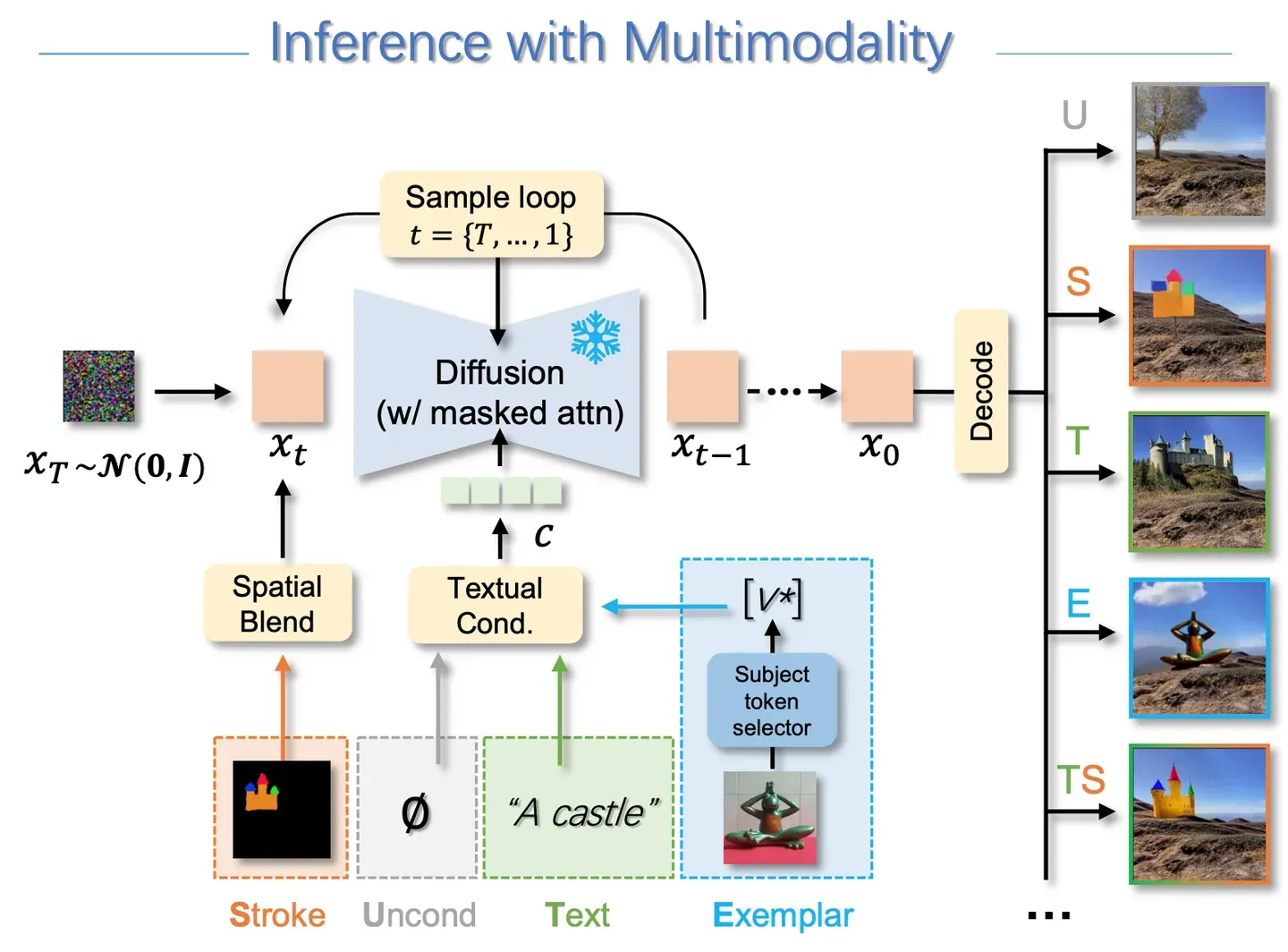
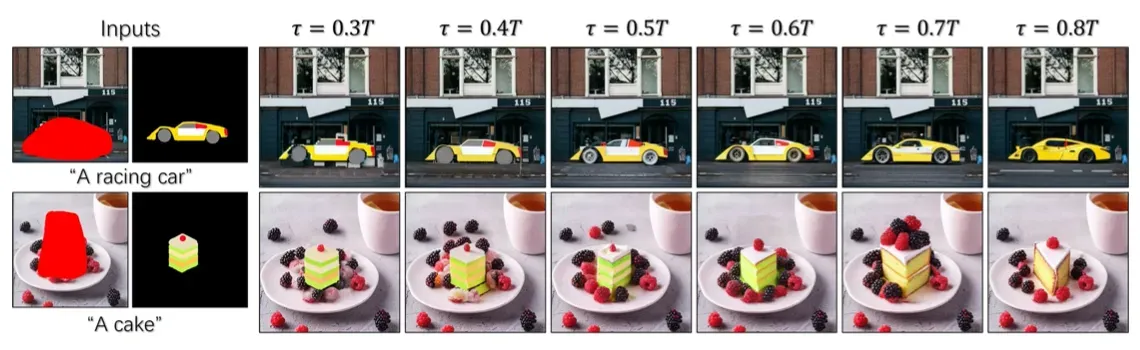
在去噪过程中,设定时间阈值t,当时间步大于阈值t时,使用无条件去噪,但时间步等于t时,进行简笔画图像融合,当时间小于等于t时,使用文本+参考图作为条件引导。
t怎么选?
6. Masked attention
在mask区域生成新物体的时候,生成的内容有时会超出边界,嵌入到非mask区域中,为了解决这个问题,作者提出了masked attention。
按照之前的UNet架构,文本(KV)和图像(Q)会通过Cross-att交互,图像本身会通过Self-att交互。本文将Cross-att和Self-att都限制在mask区域中。对于文本与图像之间的Cross-att,文本只和图像只在mask区域计算cross-att。对于图像本身的self-att,只在mask区域计算self-att。
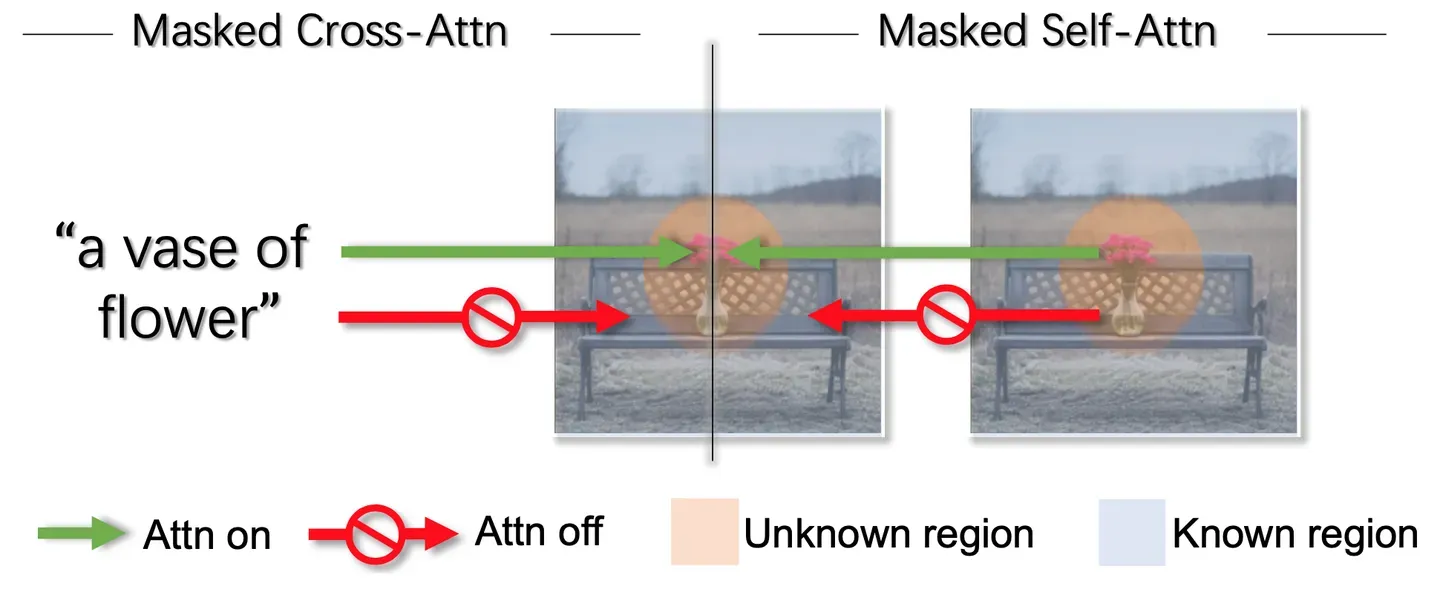
效果

实验
基于sd-v1.4模型,finetune了100个iters。数据集包含:(1) EditBench: 一个用于评估文本引导的图像Inpainting任务的benchmark数据集。(2) 来源于Unsplash网站的图片 (3) 作者自己收集的图片 (4)其它论文用到的图片。
评估指标
(1) NIMA(Neural Image Assessment): 一个评估图片质量的指标(类似美学模型打分)
(2) T2I(Text-to-Image Alignment): 使用CLIP模型评估文本和生成图像的相似度,用于评价文本引导的图像生成任务。
(3) I2I (Image-to-Image Alignment): 使用CLIP模型评估图像和生成图像的相似度,用于评价参考图引导的图像生成任务。
(4) RMSE:评估简笔画和生成图像之间的diff,用于评价简笔画引导的图像生成任务。
(5) Human perference: 用户投票,选出他们认为生成质量最好的图片。
文本引导的生成任务

GLIDE-Inpainting边缘融合效果不好(如蛋糕那张);BLD倾向于往mask填充内容,和背景的内容不融洽不自然(如豹子的头比例不对);Repaint对全图的语义理解欠缺(如人头鸟身)。SD Inpainting的效果相当,但需要大量数据的额外训练。
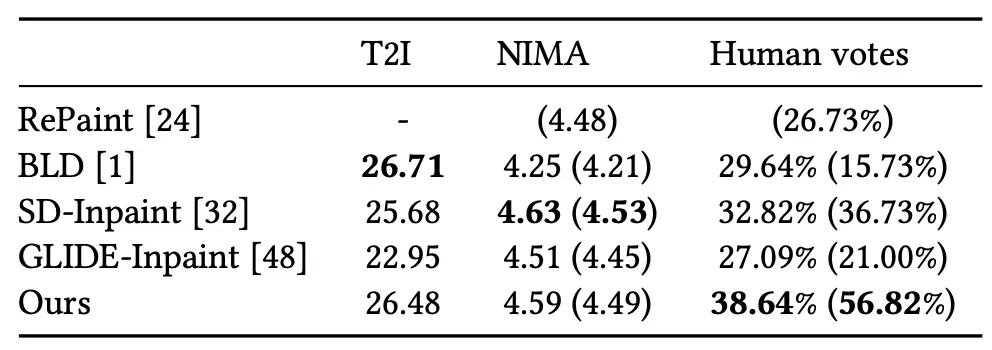
BLD: T2I最大,局部生成的内容对文本响应最好;NIMA最低,局部内容和背景内容融合不自然。
SD-Inpainting:T2I偏低,对文本响应不好,可能是因为用随机mask训练的,mask和prompt并没有对应关系;NIMA和用户投票都不错。
本文基于SD微调训练,无论是对文本的响应能力,还是生成质量都很好。
参考图引导的生成任务

简笔画引导的生成任务
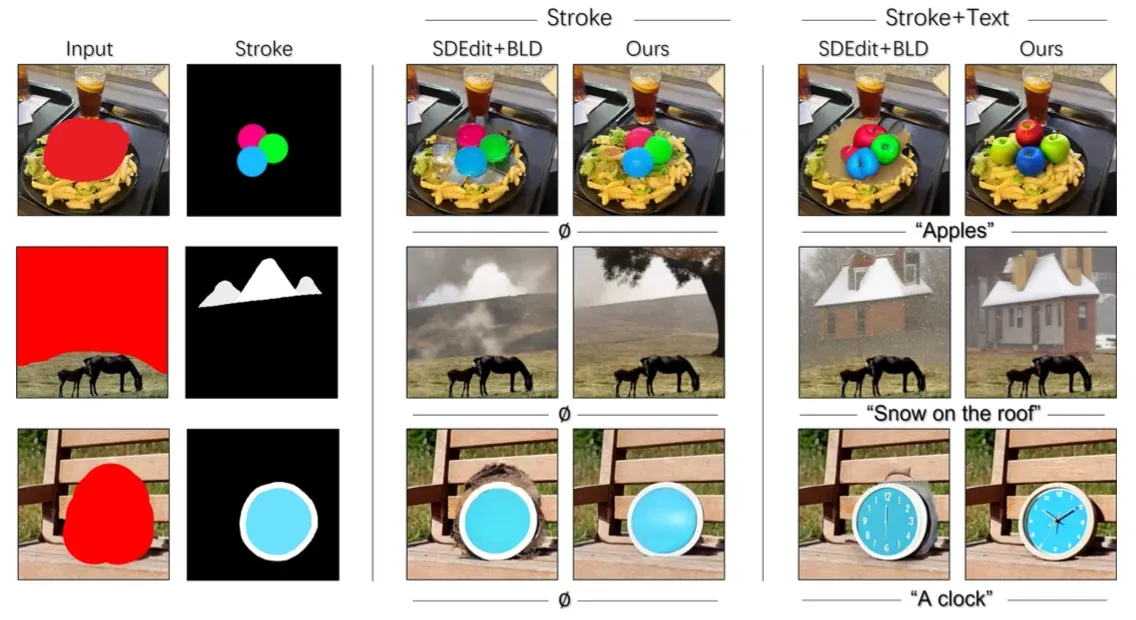
总结
提出了一个统一的多种模态引导生成框架,对文本和参考图模态,将其转成Text Embedding;对简笔画模态,在去噪过程中与原图融合。另外两个策略,Mask finetuing使用少部分数据让模型具备在mask区域生成合理内容的能力,Masked attention让模型在mask区域生成的内容不会超过mask之外的区域。
版权声明:本文为博主作者:Pencil_J原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Pencilhj/article/details/135046259