目录
学前视频
stable diffusion 文生图讲解
0.本章素材
anything模型(二次元模型)百度地址:https://pan.baidu.com/s/1VvDJOP_MbUcR7lCSasQ19Q?pwd=g5uk提取码:g5uk夸克地址:https://pan.quark.cn/s/09719485f653提取码:PWLu
vae:vae-ft-mse-840000-ema-pruned百度网盘链接:https://pan.baidu.com/s/1XnZoRd7n4NV0SFjslpjM_w?pwd=gu4f 提取码:gu4f夸克网盘:https://pan.quark.cn/s/db59977509f8提取码:mehy
通用提示词模板:夸克网盘:https://pan.quark.cn/s/fb90a98535071.什么是文生图
stablediffustion并不是自己就能平白无故生成一张图,stablediffustion只是一个执行者,既然是执行者,那么就需要对应的指令去告诉SD,我们需要做什么,比如说我需要一个在山里的女孩的图片
我输入1girl,inthemountain,那么SD就会输出背景是山,一个女孩的图片了,文生图,就是从文字概述中生成对应的图片信息.
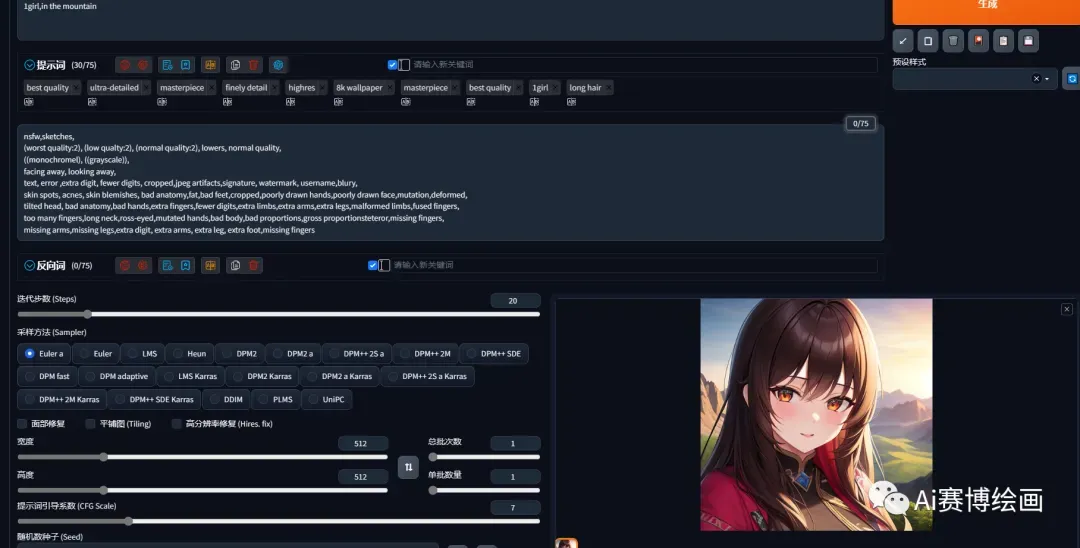
由于SD不认识中文,提示词都必须是英文,而且看上去混乱无章,很多人刚刚入门时,会觉得一头雾水,不知道要怎么写,也不知道该写什么,看到界面这么多参数,也不知道该点什么.不用担心.接下来,我将通过细致的讲解,让同学们一步一步学会甚至熟练使用。
2.界面介绍
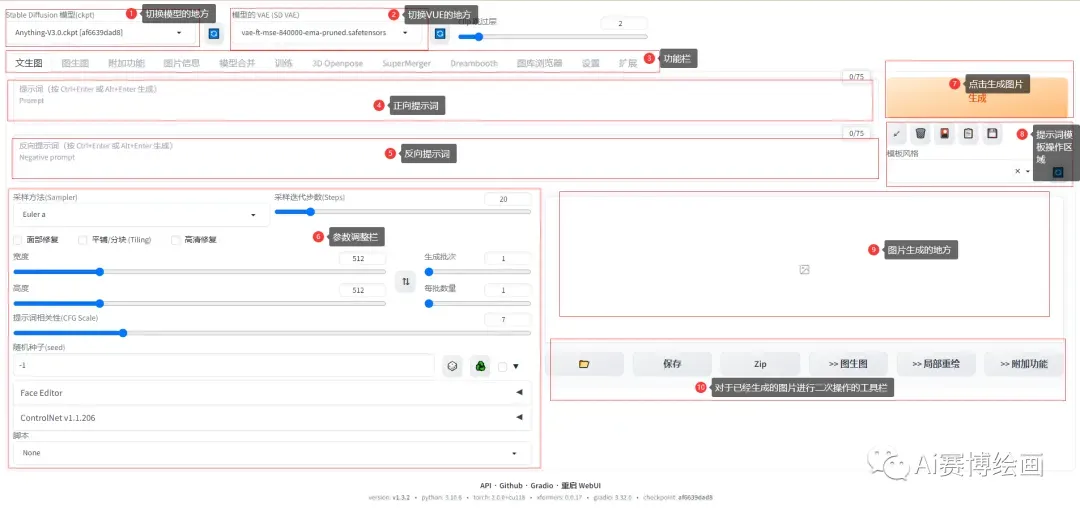
2.1切换模型的地方
模型简单来说就是决定你出图效果,一些模型是出3D图片效果很好,一些模型是二次元图片效果很好,但是需要注意的事,如果用建筑类的模型去生成二次元图片,会大大增加崩坏图片的几率,因为模型出图的效果是基于训练的素材,建筑类的模型,一般是大量的使用建筑图片给模型进行训练.
模型常见的尾缀为ckpt,safetensors,大小一般是2G到7G
存放路径是x:\xxx\sd-webui-aki-v4\models\Stable-diffusion
常见的模型下载网站有:
https://civitai.com/(C站,国内无法正常访问)
国内可用:
https://www.liblibai.com/(类似C站的国内镜像网站)
https://huggingface.co/(抱脸网)

2.2切换VAE
VAE简单的理解可以是增强画质的工具,(多数情况下,可以增加画质,但是也有可能会导致画质变得更差)类似滤镜,或者智能P图,多数模型都会自带有对应的VUE模型,会自动识别.
简短来说就是图没有灰色,或者画质过差,不用切换VAE
存放地址:X:\\XX\sd-webui-aki-v4\models\VAE

2.3功能栏
主要是Stablediffusion各种功能的切换,本章讲解文生图功能
2.4提示词
提示词是控制图片绘制的核心要素,也是本章的重点内容,会分多个小点进行讲解
1.提示词的词性
在文生图界面中提示词分为两种,一种是正向提示词(Prompt),一种是反向提示词(NegativePrompt)。
-
正向提示词的意思是:我需要什么(图片中出现什么)。
-
反向提示词的意思是:我不需要什么(图片中不出现什么)。
例如hair(头发)在正向提示词输入框中,则说明生成的图片中需要头发,反之在反向提示词输入框中,则说明图片中不要出现头发,一个词语是正向提示词还是反向提示词取决于词语在什么输入框(反向提示词未必一定会生效,比如加了缺少胳膊,出的图一定几率也会出没有手)
2.提示词的语法
1.sd支持单词,短语,简单的句子这几种模式
-
单词:1girl,longhair,in the mountain(一个女孩,长发,在山里);
-
短语:Agirlhaslonghair,in the mountain(一个女孩有长发,在山里);
-
句子:Agirl with long hair is in the mountains(一个长发女孩在山里);
以上这几种的效果都是一样的,都会生成相同效果的图片,而我们常用的是使用单词进行编写提示词,因为更容易进行调试修改
2.不同提示词之间需要用英文逗号进行分割,并且前后有空格或者换行是不影响效果的
3.提示词越在前面,权重越高,所以主体应该放在前面
3.提示词的组成
-
基础词:通用的词语,主要是对画质的提示,通常无论哪种图片都可以加上,也称为起手式常用的有bestquality,ultra-detailed,masterpiece,finelydetail,highres,8kwallpaper(最好的质量,超细节,杰作,精细的细节,高分辨率,8k壁纸).
-
主体词:对画面的主体进行描述的词语,比如环境描述,光线描述,图片包含什么的描述,比如1petitegirl,outdoors,Purplefog(一个娇小的女孩,户外,紫雾).
-
细节词:对于主体的更加细节描述,比如眼睛的大小,瞳孔的颜色,衣服的描述,发色的描述,身材的描述等比如redeyes,eyehighlights,dress,shortpuffysleeves(红眼睛,挑亮眼睛,裙子,蓬松的短袖)
正向提示词从本质上说就是基础词+主体词+细节词的描述,也许你会说我一下子想不出这么丰富的词语,那么你可以从最简单的开始:
一个女孩在户外->生成图片->查看图片->添加细节->一个娇小的女孩,有着红色的眼睛,穿着裙子和蓬松的短袖->循环的生成图片->不停的调整细节->生成图片有个反向提示词需要注意:nsfw,反向提示词加上这个词语可以很大程度上减少少儿不宜的图片出现,避免社死.
提示词网站:https://prompthero.com/stable-diffusion-prompts
4.提示词的权重调整
在生成图片的时候我们可能需要某个细节更加突出或者减弱,此时我们可以使用权重去进行控制
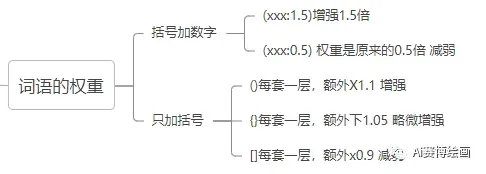
1.固定权重调整
-
权重上升()(xxx)包含的词语是指权重增加1.1倍,()可以进行叠加,每叠加一次就增加1.1倍,例如((xxx))就是1.1*1.1,(((xxx)))就是1.1*1.1*1.1
-
权重微量上升{}{xxx}包含的词语权重增加1.05倍,同时也可以叠加,{ {xxx}}就是1.05*10.5
-
权重下降[][xxx]每套一层,额外x0.9同时也可以叠加,[[xxx]]就是0.9*0.9
2.动态权重调整
括号加数字(xxx:1.5)当数字大于1时权重上升,1.5则是1.5倍的意思,数字小于1时,权重下降(xxx:0.5)权重是原来的0.5倍

2.5参数调整栏
这里就是对文生图绘制的细节调整,每一个参数都有自己对应的含义,也会对结果图有一定的影响。
1.采样方法
采样方式就是指sd用什么算法进行图片生成,影响出图质量以及出图速度。
以下是各种采样方式的出图效果:

-
Euler a速度和质量都非常不错,适合快速出图,但是要注意自己的提示词,因为快也很容易出一些崩坏图
-
DDIM和Euler则需要一定的好的运气,需要反复抽卡
-
DPM++2系列算法则以相对步数就可以达到其他算法的质量甚至更高(一般来说带++的都是升级版)
-
LMS、DPMfast、LMSKarras和PLMS这几个算法则不太推荐
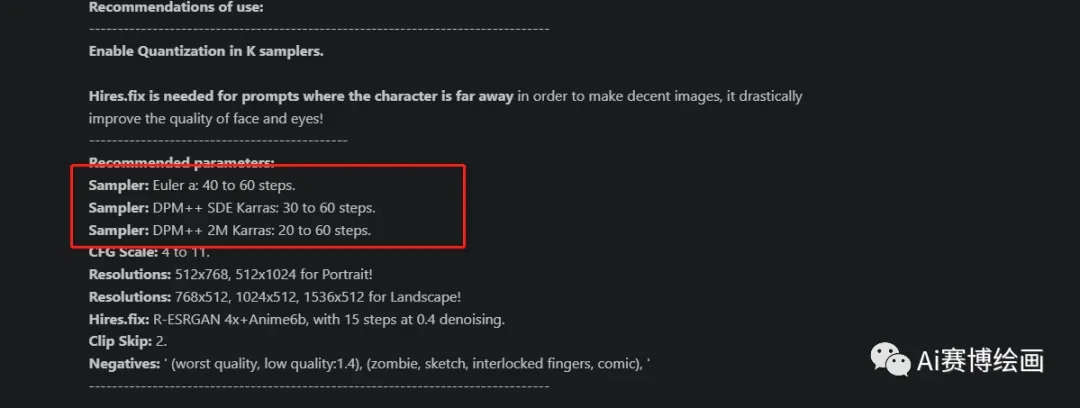
一般细心的模型都会有推荐采样算法,大家也可以上模型的详情进行查看例如:
2.采样迭代步数
采样迭代步数越高,图片则会越精细,但是需要申明采样迭代步数并不是越高越好,图片的质量是有上限的,过高的采样迭代步数只会增加出图的速度以及增加崩坏的几率,但是也有研究表明,过高的迭代步数有助于手部的生成,但是大部分情况下,过高的迭代步数并不会有较大的收益.
对于不同的模型也有各种不同的采样迭代步数:
·DDIM和EulerA一般为30以上40以下;
·DPM2A则一般为60以上;
·DPM系列则一般为20以上30以下;
但是有个异类DPMadaptive这个采样方式,采样迭代步数对于这个采样方法是不生效的.
当然这个并不是通用的,更多是一种参考值,更加具体的,可以参考模型的推荐步数.
3.面部修复
一般是用于三次元图片的面部修复,但是对于二次元图片的面部修复支持效果不是很好,三次元图片可以勾选,二次元图片不要勾选,二次元修复效果不好
4.平铺图
就是一张图片中会出现重复的元素,特定场景会使用.
5.高清修复
这个可是神器之一,可以把模糊的照片变清晰

sd用放大倍率进行等比例放大,这样图片的细节会更加清晰,质量更加高,如果放大倍数是2时图片分辨率会从512*512变为1024*1024,高清修复的时候不要直接拉动宽度和高度.
常用的放大算法三次元的用R-ESRGAN4x+,二次元用R-ESRGAN4x+Anime6B,高分迭代步数为0则是用原图的意思,重绘幅度一般0.5到0.7最佳,过高会导致原图和修复后的图片有较大区别.
6.宽度和高度
这个应该很容易理解吧,就是图片的宽度和高度,配置太低的不要调太大,会无法出图,并且如果宽高设置过大,会出现多人,多手,多脚,多头等奇异画风,这个主要是因为模型训练时大多数是使用小图进行训练,当生成图片过大,AI会认为这是多张图合并而成,当需要生成大图时,建议使用高清修复功能.
当515*512时,大概率会生成大头照,而需要生成全身照时,需要将高度调高到700以上,并且加上提示词“fullbody”.
7.生成批次和每批数量
这个需要一起说明,生成批次是指生成多少次,每批数量是指一次生成多少张,生成批次对显存要求不高,但是每批数量对显存的要求较高,一般我们需要出多张图时,只设置生成批次即可,每批数量过多容易导致爆显存,生成批次只会影响出图速度.
8.提示词引导系数(CFGScale)
就是SD多大程度上会听从你的指令.
1-基本上不理会你的提示;
3-更具创造性;
7-在遵守提示和自由之间取得良好的平衡(默认值);
15-更加遵守提示;
30-严格遵守提示;
9.随机种子
你可以认为这个就是图片的编码,当为-1的时候,则是随机生成一个编号,相同的随机种子出的图会大致一致.


2.6模板操作区

3.结语
至此文生图的讲解就到这里结束了,下一章,我们开始了解什么是图生图
4.课后训练
-
使用anythiny模型构建一张小女孩在月光下微笑的图片(512*512大小)
-
通过更换采样模式查看相同图片的生成效果是否一致(seed需要一致)
-
图片不变的情况下,生成一张1024×1024的高清图
-
同时生成五张小女孩在月光下微笑的图片
-
提示词不变的情况下,通过调节引导系数,查看图片的变化情况

下一节:【stable diffusion】保姆级入门课程02-Stable diffusion(SD)图生图-基础图生图用法
文章出处登录后可见!