感谢https://github.com/tsingcoo/LLaMA-Efficient-Tuning/commit/f3a532f56b4aa7d4200f24d93fade4b2c9042736和https://github.com/huggingface/peft/issues/432的帮助。
在LLaMA-Factory中添加adalora
1. 修改src/llmtuner/hparams/finetuning_args.py代码
在FinetuningArguments中修改finetuning_type,添加target_r和init_r
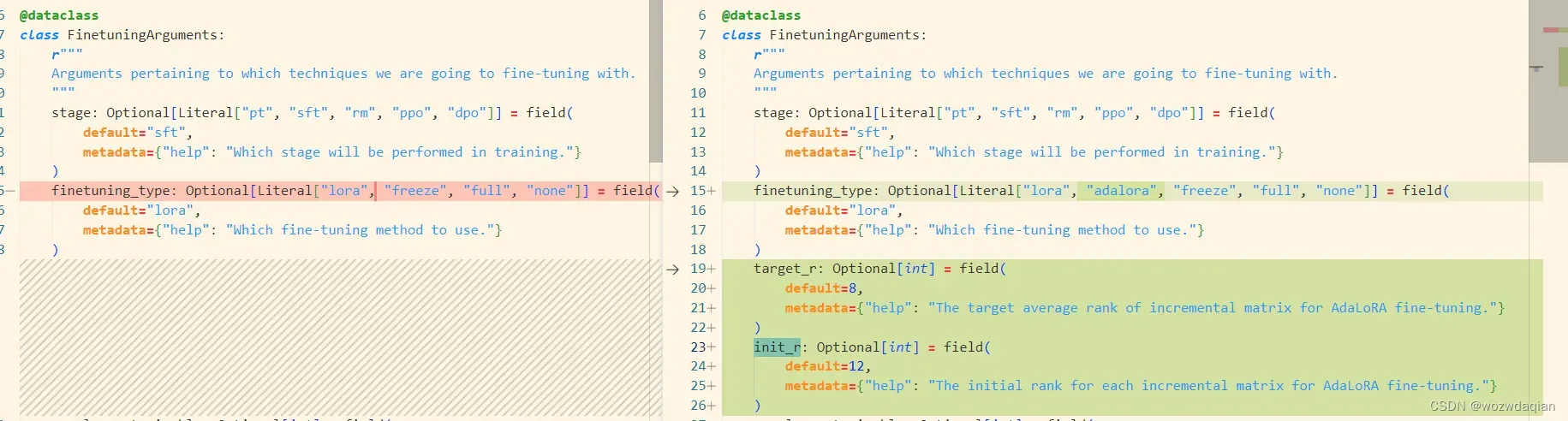
修改__post_init__函数

2. 修改src/llmtuner/tuner/core/adapter.py代码
添加AdaLoraConfig

在init_adapter函数中添加一个if判断,添加位置在如红框所示:
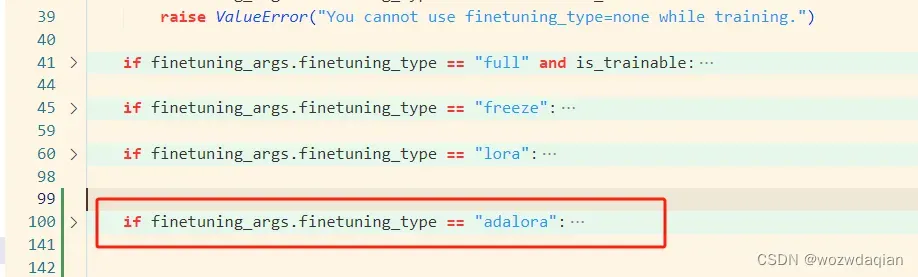
if finetuning_args.finetuning_type == "adalora":
logger.info("Fine-tuning method: AdaLoRA")
latest_checkpoint = None
if model_args.checkpoint_dir is not None:
if (is_trainable and finetuning_args.resume_lora_training) or (not is_mergeable): # continually fine-tuning
checkpoints_to_merge, latest_checkpoint = model_args.checkpoint_dir[:-1], model_args.checkpoint_dir[-1]
else:
checkpoints_to_merge = model_args.checkpoint_dir
for checkpoint in checkpoints_to_merge:
model = PeftModel.from_pretrained(model, checkpoint)
model = model.merge_and_unload()
if len(checkpoints_to_merge) > 0:
logger.info("Merged {} model checkpoint(s).".format(len(checkpoints_to_merge)))
if latest_checkpoint is not None: # resume lora training or quantized inference
model = PeftModel.from_pretrained(model, latest_checkpoint, is_trainable=is_trainable)
if is_trainable and latest_checkpoint is None: # create new lora weights while training
if len(finetuning_args.lora_target) == 1 and finetuning_args.lora_target[0] == "all":
target_modules = find_all_linear_modules(model, model_args.quantization_bit)
else:
target_modules = finetuning_args.lora_target
lora_config = AdaLoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
target_r=finetuning_args.target_r,
init_r=finetuning_args.init_r,
r=finetuning_args.lora_rank,
target_modules=target_modules,
lora_alpha=finetuning_args.lora_alpha,
lora_dropout=finetuning_args.lora_dropout,
)
model = get_peft_model(model, lora_config)
if id(model.peft_config) != id(model.base_model.peft_config): # https://github.com/huggingface/peft/issues/923
model.base_model.peft_config = model.peft_config
3. 修改src/llmtuner/tuner/core/parser.py的代码
这边建议所有有关finetuning_args.finetuning_type==/!= “lora”的都改成图片所示

修改transformer源码
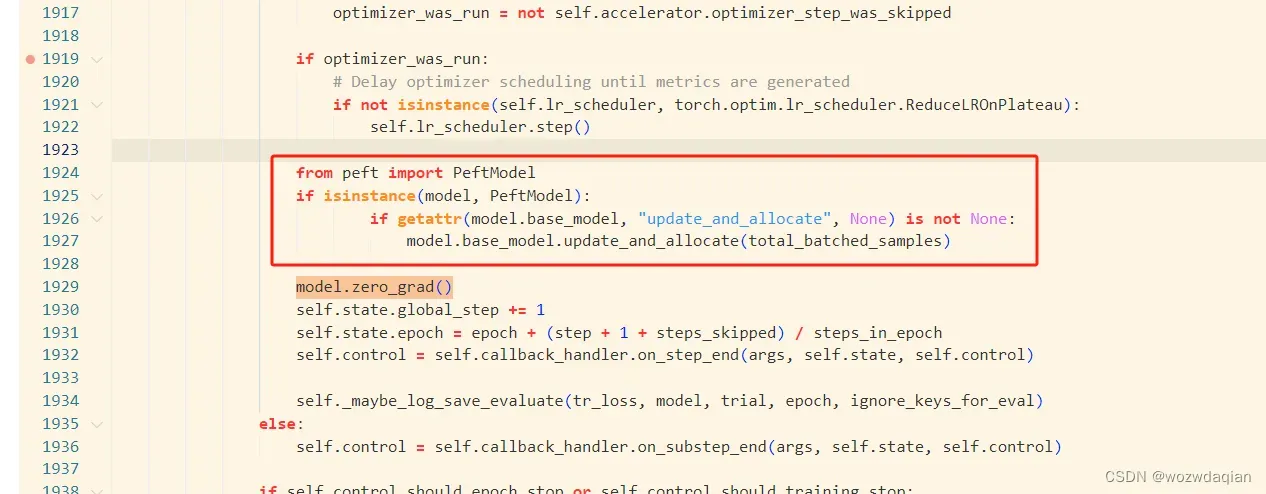
按照上面的改完之后虽然可以训练,但是其实并没有实现adalora的秩的调整。
我是通过在update_and_allocate函数中设置断点发现模型训练没有调用update_and_allocate函数,update_and_allocate函数位于python3.10/site-packages/peft/tuners/adalora.py中。
1. 修改python3.10/site-packages/transformers/trainer.py代码
from peft import PeftModel
if isinstance(model, PeftModel):
if getattr(model.base_model, "update_and_allocate", None) is not None:
model.base_model.update_and_allocate(total_batched_samples)
把上面的代码复制到train函数中,具体的位置应该是整个文件的第二个model.zero_grad()上面,不同transformers的位置可能不一样
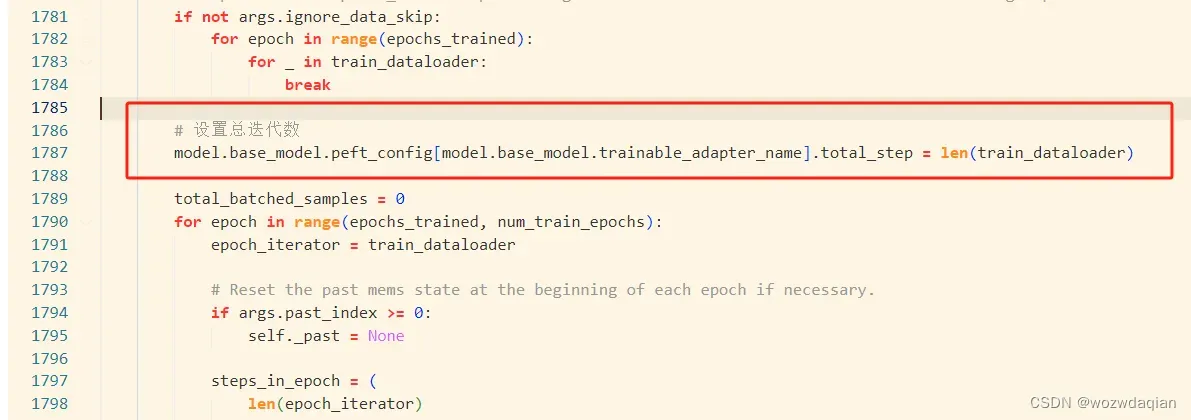
2. 设置adalora的总迭代次数
两个方法一个是在adaloraconfig定义的时候设定(我没试),另外一个就是一样修改train.py,如下:
在for epoch in range(epochs_trained, num_train_epochs):上面一行设置
# 设置总迭代数
model.base_model.peft_config[model.base_model.trainable_adapter_name].total_step = len(train_dataloader)
训练启动

版权声明:本文为博主作者:wozwdaqian原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_42001765/article/details/135559173