链队列及其基本操作的C语言实现
- 导言
- 一、链队列
- 二、链队列的基本操作的实现
-
- 2.1 链队列的数据类型
- 2.2 链队列的初始化
-
- 2.2.1 带头结点的链队列的初始化
- 2.2.3 不带头结点的链队列的初始化
- 2.3 链队列的判空
-
- 2.3.1 带头结点的链队列的判空
- 2.3.2 不带头结点的链队列的判空
- 2.4 链队列的入队
-
- 2.4.1 带头结点的链队列的入队
- 2.4.2 不带头结点的链队列的入队
- 2.5 链队列的出队
-
- 2.5.1 带头结点的链队列的出队
- 2.5.2 不带头结点的链队列的出队
- 2.6 链队列的查找
-
- 2.6.1 带头结点的链队列的查找
- 2.6.2 不带头结点的链队列的查找
- 2.7 链队列的销毁
-
- 2.7.1 带头结点的链队列的销毁
- 2.7.2 不带头结点的链队列的销毁
- 三、链队列的实现演示
-
- 3.1 带头结点的链队列的实现演示
- 3.2 不带头结点的链队列的实现演示
- 结语

导言
大家好,很高兴又和大家见面啦!!!
在上一个篇章中,我们详细的介绍了队列的顺序存储结构——循环队列。同时花费了大量的篇幅来介绍循环队列的实现逻辑与实现方式,最后我们还使用C语言通过两种方式是实现了循环队列,相信大家看完上一篇内容的话应该对循环队列及其基本操作的实现已经没什么问题了。如果对这些内容还有疑问的朋友可以在文章下方评论留言,或者私信博主,博主看到后都会回复的哦!
在介绍顺序存储结构时我们会发现对于循环队列而言也是会有队满的情况,下面我们来想象一个实际情景:
现在我们要做一家奶茶店的在线下单管理系统,按正常的流量来说,每天可能只有200——300用户会来下单,而且也是陆陆续续的,那我们通过队列来实现的话只需要申请300的空间就足够应付了。但是有一天因为一些美食博主的推荐,这家店突然火了,每天的客流量可能达到500甚至更多,500人同时在线下单,此时就会出现满队的情况,就会导致前面300人下单不受影响,但是之后的200人只有在前面的订单完成后才能成功下单。
在上面的这个情景中,如果经常性的让用户出现无法下单的问题,这样即使你这家店再火也是会对不能成功下单的顾客造成不好的体验,所以我们就需要想个办法来解决这个问题,这里我们就可以通过对内存空间使用更加灵活的链式存储来完成。
所以在今天的内容中,我们将要详细介绍一下队列的链式存储——链队列。
一、链队列
通过链式存储实现的队列称之为链队列。
前面在介绍单链表时,我们有介绍过对于一个单链表而言,它在创建时,既可以通过从队头插入新的结点来创建一个单链表,也可以通过从队尾插入新的结点来创建一个单链表,当我们单链表创建好后,想要插入新的元素或者删除一个元素我们是可以在任意位置实现插入和删除的。
现在对于队列而言它已经限制了插入与删除的位置——只能从队尾入队,从队头出队。大家能不能联想到什么呢?
没错如果我们要实现一个链队列的话,实际上就是实现了一个只能进行尾插操作与头删操作的单链表。也就是说,链队列的本质就是一个操作受限的单链表,在这个单链表中它同时拥有指向表头元素的指针与指向表尾元素的指针。
在明确了链队列的本质后,下面我们就可以开始来通过C语言实现链队列了。
二、链队列的基本操作的实现
我们在实现一个链队列时,同样是一个从无到有的过程,也就是,我们也是从定义数据类型、初始化、判空、入队、出队、查找、销毁等基本操作进行一一介绍。
这时可能就有朋友说了,你这里怎么没有判满呢?
这就是链队列相比于循环队列比较友好的地方,因为链队列是和单链表一样在进行插入操作时才会申请一片新的空间,理论上来说,只要你的内存空间足够大,它就不存在满队的情况,它能够一直插入新的元素。
现在我们就来看一下链队列的第一个内容——数据类型的定义;
2.1 链队列的数据类型
链队列的数据类型的定义,我们需要先弄清楚它所拥有的元素,如下所示:
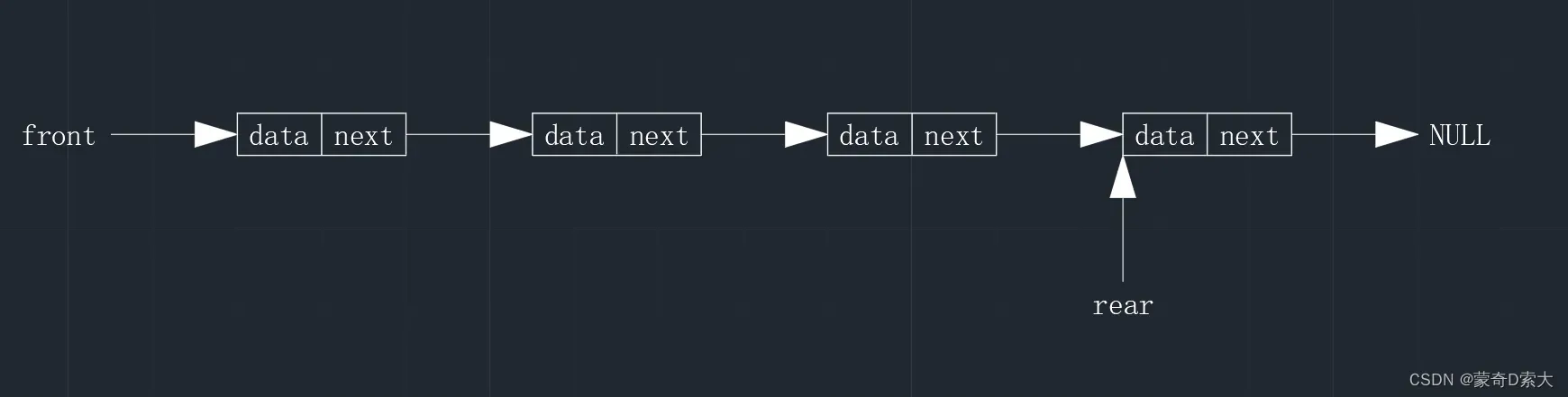
从图中我们可以看到,对于一个链队列而言,它是由存储数据元素以及指向下一个元素的结点和队头指针与队尾指针组成,那是不是就是说我们应该将数据类型定义为下面这种形式呢?
//链队列的数据类型
typedef int ElemType;
typedef struct LinkQueue {
ElemType data;//数据域
struct LinkQueue* next;//指针域
struct LinkQueue* front, * rear;//队头指针与队尾指针
}LinkQueue;
对于这种形式的数据类型,我们通过该数据类型来定义一个队列看一下它会什么样的情况:
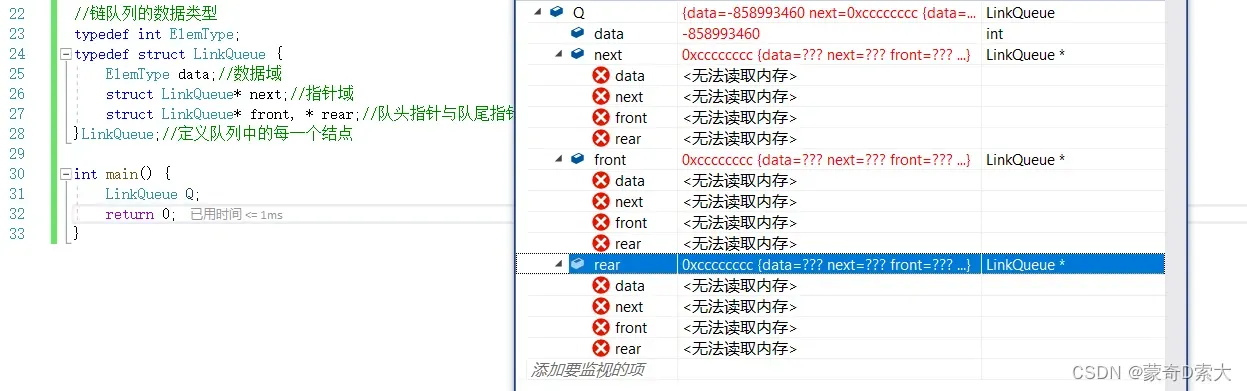
从监视窗口中我们可以看到,通过这个类型定义出来的队列它是拥有三个指针域和一个数据域的结点,如果画图展示的话那就是如下结构:

这个与我们需要的差距还是挺大的,那就是说明我们通过这种方式定义的数据类型是错误的,那我们应该如何定义的?
我们再来回顾一下我们的需求——1.存储数据元素和指向下一个元素的结点,2.拥有队头指针和队尾指针。
对于这两个需求,我们可以不可以将其拆解为两个内容呢?也就是将结点单独拎出来,将队头指针与队尾指针单独领出来,并且,队头指针和队尾指针是指向结点的两个指针,对应的数据类型,我们就可以将其描述为:
//链队列的数据类型
typedef int ElemType;
typedef struct LinkNode {
ElemType data;//数据域
struct LinkNode* next;//指针域
}LinkNode;//定义队列中的每一个结点
typedef struct LinkQueue{
LinkNode* front, * rear;//队头指针与队尾指针
}LinkQueue;//定义队列的队头指针与队尾指针
所谓实践才是检验真理的唯一标准,我们可以直接通过监视窗口来看一下是否如我们所需要的那样:
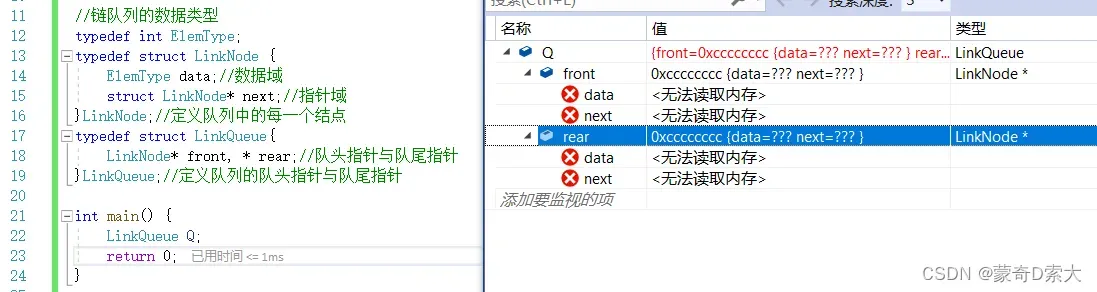
可以看到,此时就很好的满足了我们的需求,一个链队列中拥有队头指针与队尾指针,并且两个指针分别指向存储数据元素的结点。
现在我们就已经定义好了链队列的数据类型,下面就可以开始给链队进行初始化了;
2.2 链队列的初始化
对于链队列而言,它既然本质是单链表,那么它就能有两种方式来实现——带头结点和不带头结点。
在单链表中我们就已经介绍过这两种方式的差异,现在我们再来回顾一下:
- 带头结点的单链表的好处就是我们在初始化阶段,链表的头指针就已经有了具体指向的空间,因此在后续的插入与删除操作中,就不需要在分情况来讨论了;
- 而不带头结点的单链表,在初始化阶段,头结点是没有指向对象的,因此需要初始化为空指针,在后续的插入操作中因为头指针为空指针的原因,所以我们还需要将它这种情况分开处理;
从这两种的操作上来看带头结点的单链表会跟更加的简便一点,而且如果我们想要计算表长,还可以通过头结点的数据域来进行记录,不过这里我们还是将两种情况的初始化都给大家展示一下,大家后面自己在实现时可以依照自己的需求来选择实现的方式;
2.2.1 带头结点的链队列的初始化
带头结点的链队列与带头结点的单链表一样,初始化时头结点的指针域初始化为空指针,与单链表不同的是链队列的头指针被队头指针代替,并新增了队尾指针,如下所示:
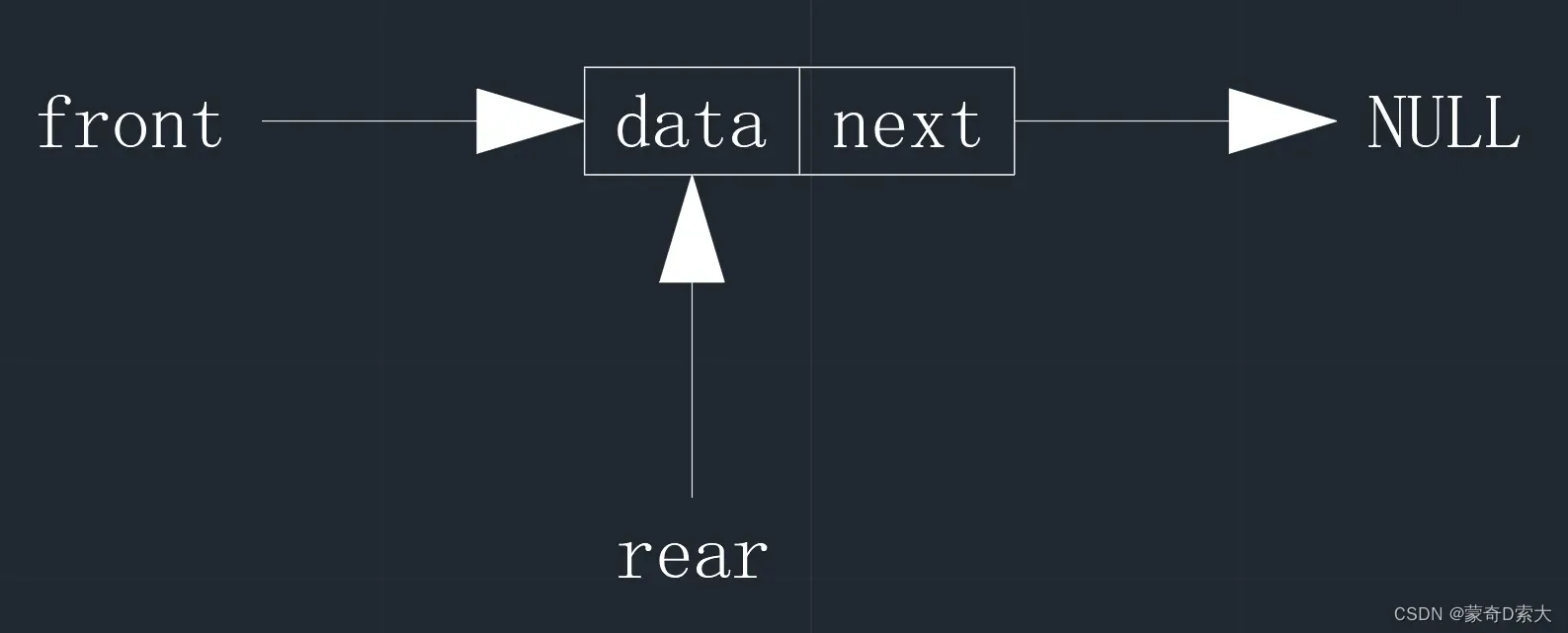
将这个结构用C语言描述则是:
//带头结点的链队列的初始化
bool InitQueue(LinkQueue* Q) {
if (!Q)
return false;
//为头结点申请空间
Q->rear = (LinkNode*)calloc(1, sizeof(LinkNode));
if (!Q->rear)
return false;
//初始化头结点
Q->rear->next = NULL;
//初始化队尾指针
Q->front = Q->rear;//队尾指针与队头指针同时指向头结点
return true;
}
对于带头结点的链队列的初始化有几个问题可能会被大家忽视掉,下面我们一起来看一下;
- 在链队列的初始化中,我们可不可以通过链队列Q来申请一块空间?
这个答案肯定是不可以的。为了解答这个问题,我们首先需要搞清楚我们申请空间的目的是什么?
我们申请一块空间是为了存放数据元素,以及存放下一个元素的位置,因此,我们实际上申请的是一块结点空间,而不是链队列的空间,当我们通过链队列的数据类型创建好链队列Q之后,我们是可以直接通过Q来访问对应的头尾指针的,并且我们只能通过头尾指针来找到对应的结点。
因此我们不能通过链队列Q来申请空间。
- 在链队列的初始化中,我们可不可以通过队头指针来申请空间?
这个答案也是不可以的。这个问题的依据是队列的操作特性——先进先出(FIFO)。队列中的元素只能从队尾入队,只能从队头出队,因此,我们在为头结点申请空间时,也需要遵从这个特性。
在链队列中,队尾指针的作用是用来插入新的结点,而队头指针的作用是用来删除结点,所以我们只能通过队尾指针来申请头结点的空间并插入到队列中
现在大家对这种带头结点的初始化应该是了解了,下面我们再来看一下,如果是不带头结点的链队列,我们又应该如何初始化;
2.2.3 不带头结点的链队列的初始化
如果一个链队列它不带头结点的话也就是在创建好队列后,此时的队头指针与队尾指针是不指向任何对象的。在这种情况下,为了防止队头指针与队尾指针变成野指针,我们需要做的就是将其初始化为空指针,代码如下所示:
//不带头结点的链队列的初始化
bool InitQueue2(LinkQueue* Q) {
if (!Q)
return false;
//初始化队头指针与队尾指针
Q->front = Q->rear = NULL;
return true;
}
对于初始化的实现,我们只要明确要初始化的对象以及初始化的内容,基本上问题不大。在完成初始化之后,我们可以随带实现的就是判空操作,下面我们来探讨一下对于不同形式的链队列,我们应该如何实现判空;
2.3 链队列的判空
在循环队列中,因为满队时的情况会发生变化,所以根据形式的实现,我们需要关注的就是队头指针与队尾指针在逻辑上的相对位置,而对于链队列而言,它并不存在满队的情况,因此它的空队列的情况是固定的,不同形式实现的链队列的判空与对应的初始化是相同的,下面我们就来一一介绍一下;
2.3.1 带头结点的链队列的判空
当我们通过带头结点的单链表实现队列时,在初始化阶段,队头指针与队尾指针指向的是同一个结点,当我们插入新的结点时,队头指针指向的对象不会改变,依旧是头结点,唯一有改变的就是队尾指针,如下所示:
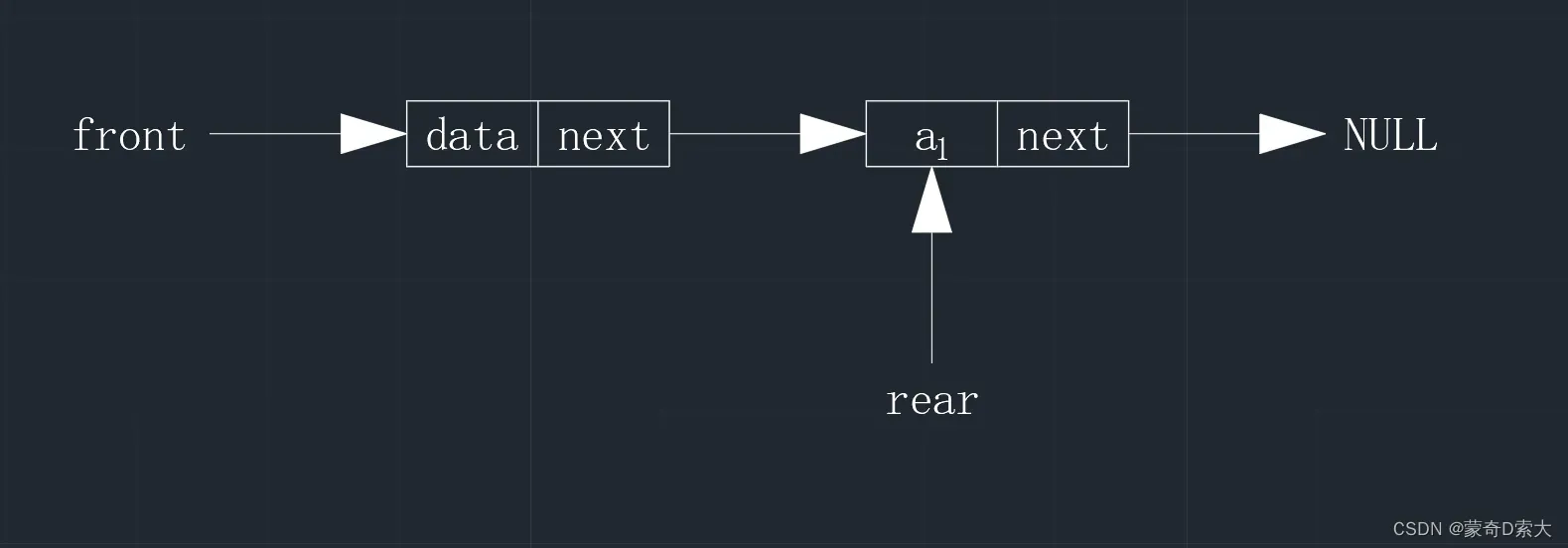
也就是说,当队尾指针与队头指针指向同一个对象时,那就说明此时的队列为空队列,因此,我们就可以编写代码:
//带头结点的链队列的判空
bool EmptyQueue(LinkQueue Q) {
if (Q.front == Q.rear)
return true;
return false;
}
对于参数的使用,一定要记住下面这个点:
- 当我们需要对实参进行修改时,就需要传址传参,对应的形参需要通过指针接收参数,就如我们在初始化阶段,会对实参进行修改,所以形参是通过指针进行接收;
- 当我们不需要对实参进行修改时,可以只用传值传参,对应的形参正常接收即可,就像我们这里的判空,我们不会对实参有任何的修改,因此,正常使用与实参相对应的形参即可;
2.3.2 不带头结点的链队列的判空
当我们通过不带头结点的单链表实现一个链队列时,此时的链队列和单链表一样,也是一个从无到有的过程,也就是说,在没有任何元素时,不管是队头指针还是队尾指针,它们此时都应该是空指针,但是当有了第一个元素之后,它们会同时指向第一个元素的结点,如下所示:
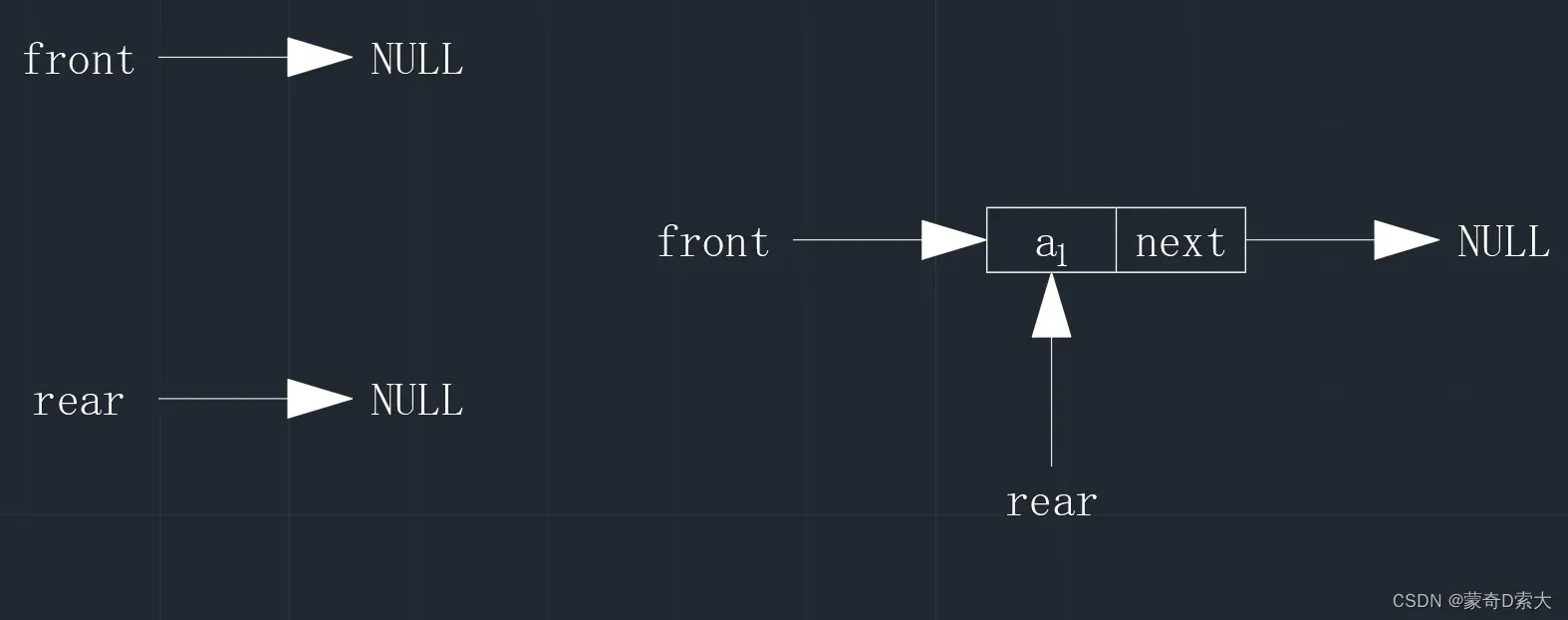
因此如果我们要对一个不带头结点的链队列进行判空操作,我们只需要判断队头指针或者队尾指针是否为空指针即可,如下所示:
//不带头结点的链队列的判空
bool EmptyQueue2(LinkQueue Q) {
//通过队头指针判断
if (Q.front == NULL)//可以简写成if(!Q.front)
return true;
//或者通过队尾指针判断
//if (Q.rear == NULL)//可以简写成if(!Q.rear)
// return true;
return false;
}
这里的判断条件可以通过使用逻辑反操作符来进行简写,由于结构体成员访问操作符的优先级高于逻辑反操作符的优先级,因此我们可以直接写成!Q.front这种形式;
2.4 链队列的入队
在完成了初始化后,我们就可以对链队列进行入队的操作了,前面也有介绍过两种实现方式的区别,这里我们还是一一的进行详细的介绍;
2.4.1 带头结点的链队列的入队
对于带头结点的链队列而言,我们在进行入队操作时,需要做的就是插入新的结点,并改变队尾指针的指向对象,由于队列的操作特性是只能从队尾入队,因此,我们在实现链队列时,也只能通过尾插法的方式进行入队,这里我就不展示对应的图片了,下面直接来看代码:
//带头结点的链队列的入队
bool EnQueue(LinkQueue* Q, ElemType x) {
if (!Q)
return false;
//为新的结点申请空间
LinkNode* p = (LinkNode*)calloc(1, sizeof(LinkNode));
if (!p)
return false;
p->data = x;//将数据存入新结点的数据域中
p->next = Q->rear->next;//将新结点的指针域指向队尾结点的后继对象,也就是NULL
Q->rear->next = p;//队尾结点的后继指针指向新结点,完成插入操作
Q->rear = p;//队尾指针指向新的结点
return true;
}
既然是单链表,那么后插的操作就是通过结点指针域的修改实现的插入,这里需要注意的是,因为插入的新结点肯定是在队尾进行插入操作的,所以我们可以直接将新结点的指针域置为空指针,然后只对队尾结点的指针域以及队尾指针进行修改就行,如下所示:
p->next = NULL;//新结点的指针域置为空
Q->rear->next = p;//队尾结点的后继指针指向新结点,完成插入操作
Q->rear = p;//队尾指针指向新的结点
这种插入操作的效果是一样的,只不过我通过上面的写法,能够更加直观的感受到结点插入的过程,代码的可读性也会更强一点;
2.4.2 不带头结点的链队列的入队
对于不带头结点的链队列,我们在进行入队操作时,是从无到有的过程,这就导致了插入第一个结点时的处理方式与插入后续结点时的处理方式上有所差异,所以我们需要分情况讨论,如下所示:
//不带头结点的链队列的入队
bool EnQueue2(LinkQueue* Q, ElemType x) {
if (!Q)
return false;
if (EmptyQueue2(*Q)) {
Q->rear = (LinkNode*)calloc(1, sizeof(LinkNode));
if (!Q->rear)
return false;
Q->rear->data = x;//将数据存入新结点中
Q->rear->next = NULL;//将新结点的后继指针置为空
Q->front = Q->rear;//将队头指针指向新结点
}
else {
LinkNode* p = (LinkNode*)calloc(1, sizeof(LinkNode));
if (!p)
return false;
p->data = x;//将数据存入新结点中
p->next = Q->rear->next;//将新结点的后继指针指向队尾结点的后继对象
Q->rear->next = p;//队尾结点的后继指针指向新结点完成插入操作
Q->rear = p;//队尾结点指向新结点
}
return true;
}
可以看到,对于不带头结点的链队列,在进行插入操作时相比于带头结点的链队列会麻烦一点,每次在执行插入操作时,都需要完成一次判断,检查队列是否为空,相比于带头结点的链队列来说会稍微麻烦一点;
2.5 链队列的出队
链队列的出队操作对于两种方式的实现也是有一定的差异,下面我们一起来看一下,如何实现这两种链队列,以及它们之间的差异在哪里;
2.5.1 带头结点的链队列的出队
对于带头结点的链队列来说,我们在进行出队时,是对队头元素的结点进行出队,而不是对头结点进行出队,因此我们只需要实现简单的头删操作即可,如下所示:
//带头结点的链队列的出队
bool DeQueue(LinkQueue* Q, ElemType* x) {
if (!Q && !x)
return false;
if (EmptyQueue(*Q))
return false;
LinkNode* p = Q->front->next;//指向队头元素的指针
Q->front->next = p->next;//修改头结点的后继结点
if (Q->rear == p)//判断此时的队头结点的后继结点是否为队尾结点
Q->rear = Q->front;//当为队尾结点时,移动队尾指针
p->next = NULL;//队头元素结点完成出队操作
*x = p->data;//将出队的元素通过变量x带回到主函数中
free(p);//释放该结点占用的内存空间
p = NULL;//将指针置空防止出现野指针
return true;
}
出队操作实际上就是对头结点的后继结点进行更改,并释放被删除的结点的空间,而对于带回出队元素的操作,这个不做强制要求,根据实际需求进行就行,但是在考试中,这个是需要加上的;
但是有一点需要注意,不管是带头结点的队列进行出队还是不带头结点的队列进行出队,能够执行出队操作的前提肯定是队列不为空,因此我们需要在出队操作前加入一次判空队列的操作;
因为我们在链队列中使用的是两个指针——队头指针与队尾指针,因此,我们在进行出队操作时,还要注意队尾指针的位置,当队列中只剩最后一个结点时,我们执行完出队操作后,队列会变为空队列,所以在进行出队前,我们需要先改变队尾指针的指向,使其与队头指针一同指向头结点;
2.5.2 不带头结点的链队列的出队
在不带头结点的链队列中,我们执行头删操作时,修改的是队头指针的指向对象,其他操作都相同,对应的代码如下所示:
//不带头结点的链队列的出队
bool DeQueue2(LinkQueue* Q, ElemType* x) {
if (!Q && !x)
return false;
if (EmptyQueue2(*Q))
return false;
LinkNode* p = Q->front;//指向队头结点的指针
Q->front = p->next;//队头指针指向队头结点的后继结点
if (Q->rear == p)//判断此时的队头结点是否为队尾结点
Q->rear = NULL;//当为队尾结点时,需要移动队尾指针
p->next = NULL;//队头结点完成出队操作
*x = p->data;//将出队的元素带回主函数中
free(p);//释放队头结点的内存空间
p = NULL;//将指针p置为空,防止出现野指针
return true;
}
在不带头结点的链队列中,对队尾结点删除的处理也是有别于带头结点的链队列的,造成这个区别的原因就是因为两种链队列的空队列是不一样的,不带头结点的链队列的空队列是队头指针与队尾指针都是空指针,因此这里我们需要在进行最后一个结点出队时将队尾指针置为空指针;
2.6 链队列的查找
对于查找操作而言,我们只能在出队的一边进行查找,就好比自动贩卖机,当我们想要购买饮料时,我们只能获得一列饮料中的第一瓶饮料,而无法越过第一瓶直接找到后面的饮料,因此,查找操作就是访问的队头元素。下面我们来看一下不同形式的链队列如何实现查找操作;
2.6.1 带头结点的链队列的查找
在带头结点的链队列中,我们要查找时,是通过头结点来访问队头元素,对应的代码如下所示:
//带头结点的链队列的查找
bool GetHead(LinkQueue Q, ElemType* x) {
if (!x)
return false;
if (EmptyQueue(Q))
return false;
*x = Q.front->next->data;//通过头结点找到队头元素的结点
return true;
}
当然,我们能成功访问队头结点的前提是队列不为空,所以在访问前,我们需要先判断队列是否为空;
2.6.2 不带头结点的链队列的查找
当队列不带头结点时,队头指针指向的就是队头结点,因此我们可以直接通过队头指针来进行访问,对应代码如下所示:
//不带头结点的链队列的查找
bool GetHead2(LinkQueue Q, ElemType* x) {
if (!x)
return false;
if (EmptyQueue2(Q))
return false;
*x = Q.front->data;//通过队头指针访问队头结点
return true;
}
链队列的查找操作对于两种链队列都是一样的,我们只要分清访问队头结点的对象就行;
2.7 链队列的销毁
当我们要销毁一个队列时,我们需要注意几点:
- 销毁的目的是释放并回收队列向内存申请的空间;
- 队列的销毁操作是通过重复的出队操作实现的;
- 队列在完成销毁前需要先完成置空,最后再回收队列的空间;
- 链队列的空间与链队列的结点的空间回收方式是不相同的;
上面这些点如果能弄清的话,那销毁操作的实现就并不复杂了,下面我们一起来看一下这两种链队列的销毁的实现方式;
2.7.1 带头结点的链队列的销毁
带头结点的链队列的销毁操作分为两步——1.出队所有的元素结点,2.释放头结点的空间。具体实现的代码如下所示:
//带头结点的链队列的销毁
bool DestroyQueue(LinkQueue* Q) {
if (!Q)
return false;
while (Q->front->next) {
ElemType x = 0;
if (DeQueue(Q, &x))
printf("元素%d所在结点完成出队\n", x);
else {
printf("当前结点出队失败\n");
break;//当出队失败时退出循环
}
}
if (EmptyQueue(*Q))//在结束循环后,对队列进行判空
printf("当前队列为空队列\n");
else {
printf("当前队列为非空队列\n");
return false;
}
free(Q->front);//释放头结点的内存空间
Q->rear = Q->front = NULL;//将队头指针与队尾指针置为空,完成销毁操作
return true;
}
在带头结点的链队列中,我们通过指向队头结点的指针平来进行各个元素结点的销毁,在各元素结点销毁的过程中会遇到两种情况:
- 队列为空队列;
- 队列非空且没有正常销毁;
当遇到上述两种情况,我们都无法继续进行出队操作,因此在跳出循环后我们需要通过判空操作来判断退出循环的原因,并给予对应的反馈:
- 当队列为空时,说明一切正常,我们此时只需要释放头结点的空间,并在完成释放后将队头指针与队尾指针置为空,避免出现野指针,最后返回
true来告知用户成功销毁; - 当队列不为空时,说明出现了问题,此时我们需要直接返回
false;
我们通过对不同情况的反馈结过来提高代码的健壮性;
2.7.2 不带头结点的链队列的销毁
对于不带头结点的链队列,当所有元素的结点全部销毁完后,对应的队头指针与队尾指针就直接变为了空指针,因此它的销毁操作的代码如下所示:
//不带头结点的链队列的销毁
bool DestroyQueue2(LinkQueue* Q) {
if (!Q)
return false;
while (Q->front) {
ElemType x = 0;
if (DeQueue2(Q, &x))
printf("元素%d所在结点完成出队\n", x);
else {
printf("当前结点出队失败\n");
break;
}
}
if (EmptyQueue2(*Q))
printf("当前队列为空队列\n");
else {
printf("当前队列为非空队列\n");
return false;
}
return true;
}
同样的为了避免队列的销毁出现问题,我们也是需要对不同的情况给予及时的反馈,以此来提高代码的健壮性;
三、链队列的实现演示
对于链队列的基本操作我们已经全部介绍完了,下面我们来看一下链队列的实现过程;
3.1 带头结点的链队列的实现演示
我们先来看一下完整的代码:
//链队列的数据类型
typedef int ElemType;
typedef struct LinkNode {
ElemType data;//数据域
struct LinkNode* next;//指针域
}LinkNode;//定义队列中的每一个结点
typedef struct LinkQueue {
LinkNode* front, * rear;//队头指针与队尾指针
}LinkQueue;//定义队列的队头指针与队尾指针
//带头结点的链队列的初始化
bool InitQueue(LinkQueue* Q) {
if (!Q)
return false;
//为头结点申请空间
Q->rear = (LinkNode*)calloc(1, sizeof(LinkNode));
if (!Q->rear)
return false;
//初始化头结点
Q->rear->next = NULL;
//初始化队尾指针
Q->front = Q->rear;//队尾指针与队头指针同时指向头结点
return true;
}
//带头结点的链队列的判空
bool EmptyQueue(LinkQueue Q) {
if (Q.front == Q.rear)
return true;
return false;
}
//带头结点的链队列的入队
bool EnQueue(LinkQueue* Q, ElemType x) {
if (!Q)
return false;
//为新的结点申请空间
LinkNode* p = (LinkNode*)calloc(1, sizeof(LinkNode));
if (!p)
return false;
p->data = x;//将数据存入新结点的数据域中
p->next = Q->rear->next;//将新结点的指针域指向队尾结点的后继对象,也就是NULL
//p->next = NULL;//新结点的指针域置为空
Q->rear->next = p;//队尾结点的后继指针指向新结点,完成插入操作
Q->rear = p;//队尾指针指向新的结点
return true;
}
//带头结点的链队列的出队
bool DeQueue(LinkQueue* Q, ElemType* x) {
if (!Q && !x)
return false;
if (EmptyQueue(*Q))
return false;
LinkNode* p = Q->front->next;//指向队头元素的指针
Q->front->next = p->next;//修改头结点的后继结点
if (Q->rear == p)//判断此时的队头结点的后继结点是否为队尾结点
Q->rear = Q->front;//当为队尾结点时,移动队尾指针
p->next = NULL;//队头元素结点完成出队操作
*x = p->data;//将出队的元素通过变量x带回到主函数中
free(p);//释放该结点占用的内存空间
p = NULL;//将指针置空防止出现野指针
return true;
}
//带头结点的链队列的查找
bool GetHead(LinkQueue Q, ElemType* x) {
if (!x)
return false;
if (EmptyQueue(Q))
return false;
*x = Q.front->next->data;//通过头结点找到队头元素的结点
return true;
}
//带头结点的链队列的销毁
bool DestroyQueue(LinkQueue* Q) {
if (!Q)
return false;
while (Q->front->next) {
ElemType x = 0;
if (DeQueue(Q, &x))
printf("元素%d所在结点完成出队\n", x);
else {
printf("当前结点出队失败\n");
break;//当出队失败时退出循环
}
}
if (EmptyQueue(*Q))//在结束循环后,对队列进行判空
printf("当前队列为空队列\n");
else {
printf("当前队列为非空队列\n");
return false;
}
free(Q->front);//释放头结点的内存空间
Q->rear = Q->front = NULL;//将队头指针与队尾指针置为空,完成销毁操作
return true;
}
//带头结点的链队列的实现
void test1() {
//链队列的创建
LinkQueue Q;
//链队列的初始化
if (InitQueue(&Q)) {
printf("初始化成功\n");
}
else {
printf("初始化失败\n");
}
//链队列的判空
if (EmptyQueue(Q)) {
printf("队列为空队列\n");
}
else {
printf("队列为非空队列\n");
}
//链队列的入队
int x = 0;
while (scanf("%d", &x) == 1) {
if (EnQueue(&Q, x)) {
printf("元素%d成功入队\n", x);
}
else {
printf("元素%d入队失败\n", x);
}
}
//链队列的出队
if (DeQueue(&Q, &x)) {
printf("元素%d成功出队\n", x);
}
else {
printf("元素出队失败\n");
if (EmptyQueue(Q)) {
printf("此时的队列为空队列\n");
}
else {
printf("此时的队列为非空队列\n");
}
}
//链队列的查找
if (GetHead(Q, &x)) {
printf("此时的队头元素为%d\n", x);
}
else {
printf("查找队头元素失败\n");
if (EmptyQueue(Q)) {
printf("此时的队列为空队列\n");
}
else {
printf("此时的队列为非空队列\n");
}
}
//队列的销毁
if (DestroyQueue(&Q)) {
printf("队列已成功销毁\n");
}
else {
printf("队列销毁失败\n");
}
}
int main() {
test1();
return 0;
}
接下来我们通过插入1~6这六个元素来验证每一步操作:
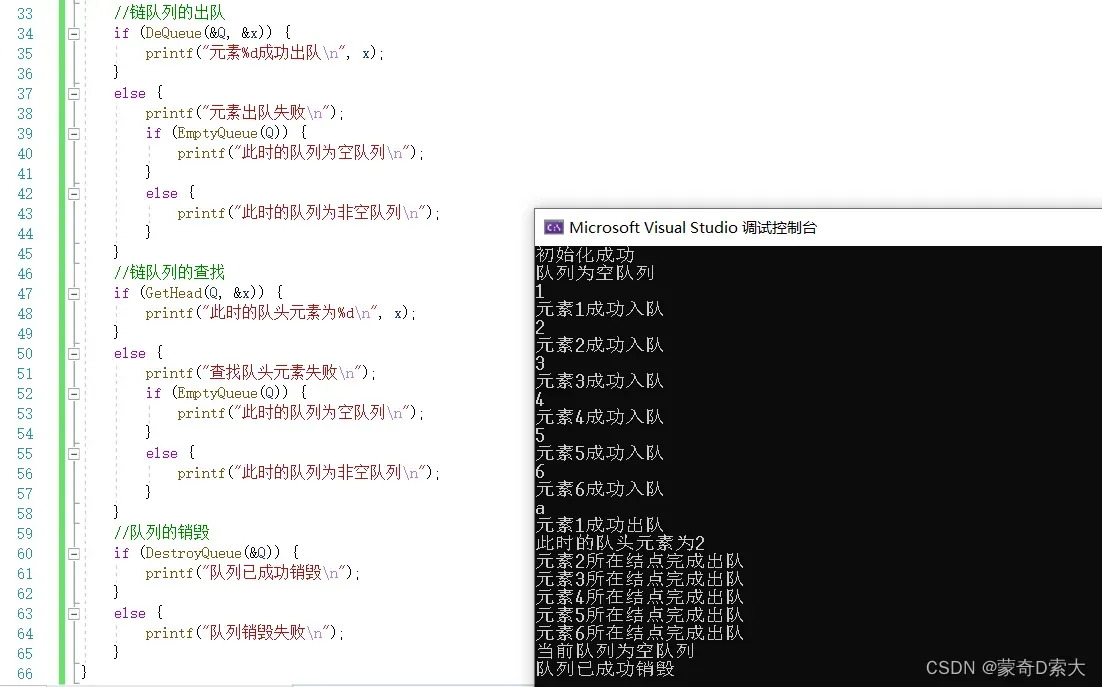
是可以看到所有的操作都能正常运行,也就是说,此时我们很好的实现了带头结点的链队列;
3.2 不带头结点的链队列的实现演示
同样我们还是先看完整的代码:
//链队列的数据类型
typedef int ElemType;
typedef struct LinkNode {
ElemType data;//数据域
struct LinkNode* next;//指针域
}LinkNode;//定义队列中的每一个结点
typedef struct LinkQueue {
LinkNode* front, * rear;//队头指针与队尾指针
}LinkQueue;//定义队列的队头指针与队尾指针
//不带头结点的链队列的初始化
bool InitQueue2(LinkQueue* Q) {
if (!Q)
return false;
//初始化队头指针与队尾指针
Q->front = Q->rear = NULL;
return true;
}
//带头结点的链队列的判空
bool EmptyQueue2(LinkQueue Q) {
//通过队头指针判断
if (Q.front == NULL)//可以简写成if(!Q.front)
return true;
//或者通过队尾指针判断
//if (Q.rear == NULL)//可以简写成if(!Q.rear)
// return true;
return false;
}
//不带头结点的链队列的入队
bool EnQueue2(LinkQueue* Q, ElemType x) {
if (!Q)
return false;
if (EmptyQueue2(*Q)) {
Q->rear = (LinkNode*)calloc(1, sizeof(LinkNode));
if (!Q->rear)
return false;
Q->rear->data = x;//将数据存入新结点中
Q->rear->next = NULL;//将新结点的后继指针置为空
Q->front = Q->rear;//将队头指针指向新结点
}
else {
LinkNode* p = (LinkNode*)calloc(1, sizeof(LinkNode));
if (!p)
return false;
p->data = x;//将数据存入新结点中
p->next = Q->rear->next;//将新结点的后继指针指向队尾结点的后继对象
Q->rear->next = p;//队尾结点的后继指针指向新结点完成插入操作
Q->rear = p;//队尾结点指向新结点
}
return true;
}
//不带头结点的链队列的出队
bool DeQueue2(LinkQueue* Q, ElemType* x) {
if (!Q && !x)
return false;
if (EmptyQueue2(*Q))
return false;
LinkNode* p = Q->front;//指向队头结点的指针
Q->front = p->next;//队头指针指向队头结点的后继结点
if (Q->rear == p)//判断此时的队头结点是否为队尾结点
Q->rear = NULL;//当为队尾结点时,需要移动队尾指针
p->next = NULL;//队头结点完成出队操作
*x = p->data;//将出队的元素带回主函数中
free(p);//释放队头结点的内存空间
p = NULL;//将指针p置为空,防止出现野指针
return true;
}
//不带头结点的链队列的查找
bool GetHead2(LinkQueue Q, ElemType* x) {
if (!x)
return false;
if (EmptyQueue2(Q))
return false;
*x = Q.front->data;//通过队头指针访问队头结点
return true;
}
//不带头结点的链队列的销毁
bool DestroyQueue2(LinkQueue* Q) {
if (!Q)
return false;
while (Q->front) {
ElemType x = 0;
if (DeQueue2(Q, &x))
printf("元素%d所在结点完成出队\n", x);
else {
printf("当前结点出队失败\n");
break;
}
}
if (EmptyQueue2(*Q))
printf("当前队列为空队列\n");
else {
printf("当前队列为非空队列\n");
return false;
}
return true;
}
//不带头结点的链队列的实现
void test2() {
//链队列的创建
LinkQueue Q;
//链队列的初始化
if (InitQueue2(&Q)) {
printf("初始化成功\n");
}
else {
printf("初始化失败\n");
}
//链队列的判空
if (EmptyQueue2(Q)) {
printf("队列为空队列\n");
}
else {
printf("队列为非空队列\n");
}
//链队列的入队
int x = 0;
while (scanf("%d", &x) == 1) {
if (EnQueue2(&Q, x)) {
printf("元素%d成功入队\n", x);
}
else {
printf("元素%d入队失败\n", x);
}
}
//链队列的出队
if (DeQueue2(&Q, &x)) {
printf("元素%d成功出队\n", x);
}
else {
printf("元素出队失败\n");
if (EmptyQueue2(Q)) {
printf("此时的队列为空队列\n");
}
else {
printf("此时的队列为非空队列\n");
}
}
//链队列的查找
if (GetHead2(Q, &x)) {
printf("此时的队头元素为%d\n", x);
}
else {
printf("查找队头元素失败\n");
if (EmptyQueue2(Q)) {
printf("此时的队列为空队列\n");
}
else {
printf("此时的队列为非空队列\n");
}
}
//队列的销毁
if (DestroyQueue2(&Q)) {
printf("队列已成功销毁\n");
}
else {
printf("队列销毁失败\n");
}
}
int main() {
test2();
return 0;
}
下面我们来看一下测试结果:
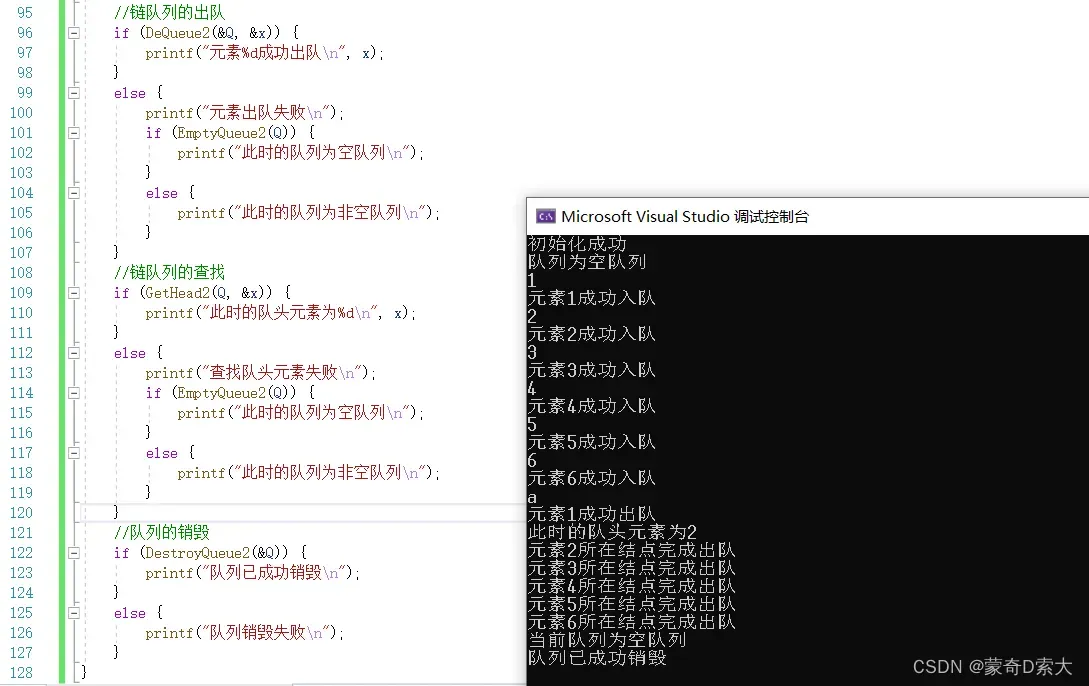
可以看到,此时我们也很好的实现了不带头结点的链队列的各个操作。
结语
在今天的内容中,我们详细介绍了两种链队列及其基本操作的实现与演示。在介绍基本操作实现的过程中,也有将大家容易忽视的问题进行了介绍,比如
- 数据类型的定义为什么是分两次进行定义?
- 在进行链队列的初始化时,为什么不能直接通过链队列Q来进行初始化?
- 在定义头结点时为什么不能通过队头指针来申请空间?
等等,如果大家对链队列的基本操作与实现还有不理解的地方可以仔细的阅读本文,并做下记录,如果还是有不清楚的点,可以评论区留言或者私信博主,博主看到后会对相应的问题进行解答。
今天的内容到这里就全部介绍了,希望今天的内容对大家理解链队列及其基本操作的实现上能提供一点帮助,在下一篇内容中,我们将介绍双端队列的相关知识点,大家记得关注哦!!!
最后感谢各位的翻阅,咱们下一篇再见!!!
版权声明:本文为博主作者:蒙奇D索大原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/2301_79458548/article/details/135730431