Mamba: Linear-Time Sequence Modeling with Selective State Spaces

Mamba:基于选择状态空间的线性时间序列建模
论文两位作者Albert Gu和Tri Dao,博士都毕业于斯坦福大学,导师为Christopher Ré。
Albert Gu现在是CMU助理教授,多年来一直推动SSM架构发展。他曾在DeepMind 工作,目前是Cartesia AI的联合创始人及首席科学家。
Tri Dao,以FlashAttention、FlashDecoding系列工作闻名,现在是普林斯顿助理教授,和Together AI首席科学家,也在Cartesia AI担任顾问。
Code:https://github.com/state-spaces/mamba
Background
基础模型(FM),即在海量数据上进行预训练,然后针对下游任务进行调整的大型模型,已成为现代机器学习的有效范式。这些模型几乎都基于 Transformer 架构及其核心注意力模块。
自注意力的效果主要归功于它能够在上下文窗口中密集地传递信息的能力,使其能够对复杂数据进行建模。然而,这一特性也带来了一些根本性的缺陷:
- **无法对有限窗口外的任何内容进行建模:**自注意力机制通常在一个固定的上下文窗口(如一个句子或一个图像的一部分)内操作,这意味着它只能考虑并处理这个窗口内的信息。当需要理解或分析的信息分散在更大的上下文中,或者与当前窗口相隔较远时,自注意力可能无法有效捕捉这些信息,因为自注意力缺乏直接的机制来处理或引入窗口之外的信息。这在处理长篇文本或大规模图像时尤其成问题,因为重要信息可能分布在整个文档或图像中。
- **窗口长度的二次缩放问题:**自注意力的一个关键特点是它在计算时需要比较和加权窗口内的所有元素对。这意味着如果窗口长度增加,所需的比较(和因此的计算资源)会以二次方的方式增加。例如,如果窗口长度加倍,那么所需的计算量将增加四倍。这种二次缩放性质使得自注意力在处理大窗口或长序列时变得效率低下。
为了解决 Transformer 在长序列上的计算效率低下问题,人们开发了许多亚二次时间架构,如线性注意力、门控卷积和递归模型以及结构化状态空间模型(SSM)。此类模型的一个关键弱点是无法进行基于内容的推理。
其中SSMs最有潜力,它可以被解释为递归神经网络(RNN)和卷积神经网络(CNN)的结合,其灵感来自经典的状态空间模型(卡尔曼,1960)。但它们在离散和信息密集数据(如文本)的建模方面不太有效。
Contribution
改进
作者提出了一类新的选择性状态空间模型,该模型在多个维度上改进了先前的工作,从而在序列长度线性缩放的同时,实现了Transformer的建模能力。主要的改进有以下几点:
- 选择机制 先前的模型,特别是那些用于处理序列数据的模型,可能在有效选择数据方面存在局限,它们可能不够有效地关注重要的输入信息或忽略不相关的输入信息。选择性复制和归纳头等合成任务在理解和改进模型的选择机制方面提供了重要的直觉。于是作者设计了一种简单的选择机制,根据输入对 SSM 参数进行参数化(让 SSM 参数成为输入的函数)。这样,模型就能过滤掉无关信息,并无限期地记住相关信息。
- 硬件感知算法 先前的SSM模型为了计算效率,必须是时间不变和输入不变的,这意味着它们的计算方式不随时间或输入数据的变化而改变。而上一点提到的改进,虽然提高了模型的灵活性和效果,但也带来了技术上的挑战。
于是作者开发了一种硬件感知算法。这种算法考虑了硬件的特性和限制,特别是在使用GPU进行计算时。算法使用递归的方式通过扫描来计算模型,而不是使用传统的卷积。
算法设计考虑到了GPU内存层次结构,为了避免不同级别之间的IO访问,它不会实体化扩展的状态,这一步骤有助于减少内存访问和相关的时间延迟。
在理论上,这种实现方式使得处理速度随序列长度线性增长,与基于卷积的所有SSM模型的伪线性增长相比有显著优势。在A100 GPU上,实现的性能比之前的方法快3倍。 - 模型架构 作者将先前的 SSM 架构设计(Dao、Fu、Saab 等人,2023 )与 Transformers 的 MLP 模块合并为一个模块,集成到一个简化的端到端神经网络架构中,该架构没有注意力,甚至没有 MLP 块,简化了先前的深度序列模型架构,形成了一种包含选择性状态空间的简单、同质的架构设计(Mamba)。
优势
选择性 SSM 以及 Mamba 架构是完全递归模型,其关键特性使其适合作为在序列上运行的通用基础模型的骨干,它具有以下几个特点:
- **高质量:**选择性为语言和基因组学等密集模式带来了强大的性能。
- **快速训练和推理:**在训练过程中,计算量和内存与序列长度成线性关系,而在推理过程中,由于不需要缓存以前的元素,因此自回归展开模型每一步只需要恒定的时间。
- **上下文长:**质量和效率共同提高了实际数据的性能,序列长度可达 100 万。
应用范围
-
合成 在一些重要的合成任务上,如被认为是大型语言模型关键的复制和归纳头,Mamba 不仅能轻松解决,还能推导出无限长(>100 万个词组)的解决方案。
-
音频和基因组学 在音频波形和 DNA 序列建模方面,Mamba 在预训练质量和下游指标(例如,在具有挑战性的语音生成数据集上,FID 降低了一半以上)方面都优于 SaShiMi、Hyena 和 Transformers 等先前的一流模型。在这两种情况下,它的性能都随着上下文长度的增加而提高,最高可达百万长度的序列。
-
语言建模 Mamba 是第一个线性时间序列模型,无论是在预训练复杂度还是下游评估方面,都真正达到了 Transformer 质量的性能。通过多达 1B 个参数的缩放规律,作者发现 Mamba 的性能超过了大量基线模型,包括基于 LLaMa(Touvron 等人,2023 年)的非常强大的现代Transfomer训练方法。Mamba 语言模型与类似规模的 Transformer 相比,具有 5 倍的生成吞吐量,而且 Mamba-3B 的质量与两倍于其规模的 Transformer 相当(例如,与 Pythia-3B 相比,常识推理的平均值高出 4 分,甚至超过 Pythia-7B)。
State Space Models(状态空间模型)
“状态空间模型”一词广泛涵盖涉及潜在状态的任何循环过程,并已用于描述跨多个学科的各种概念。
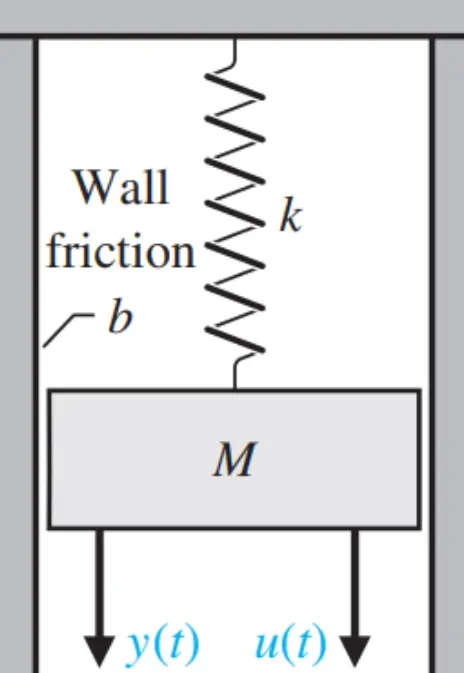
可以先从物理中的状态空间模型来理解:
由常规物理规律可以研究系统的三个维度:系统输入、系统输出和状态量,上述模型中,u(t)为系统输入即拉力,y(t)为系统输出即位移量,该系统的状态可以有位移、速度、加速度等等更深层的潜在特征。
以弹簧-质量-阻尼系统 (SMD)为例,我们想要知道,在给定一个力作为系统输入量
的时候, 以及质量块 M 随时间变化的位移
,速度
的方程。其中我们设置位移
作为系统的输出量
。
版权声明:本文为博主作者:啵啵菜go原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/lhx526080338/article/details/135959994