文章目录
一、Stable Diffusion XL基本概念
Stable Diffusion XL 或 SDXL 是最新的图像生成模型,与以前的 SD 模型(包括 SD 2.1)相比,它专为更逼真的输出而定制,具有更详细的图像和构图。与Stable DiffusionV1-v2相比,Stable Diffusion XL主要做了如下的优化:
- 对Stable Diffusion原先的U-Net,VAE,CLIP Text Encoder三大件都做了改进:
- U-Net 增加 Transformer Blocks (自注意力 + 交叉注意力) 来增强特征提取和融合能力;
- VAE 增加条件变分自编码器来提升潜在空间的表达能力;
- CLIP Text Encoder 增加两个大小不同的编码器来提升文本理解和匹配能力。
- 增加一个单独的基于Latent的Refiner模型,来提升图像的精细化程度;
- 设计了很多训练Tricks,包括图像尺寸条件化策略,图像裁剪参数条件化以及多尺度训练等。
二、SDXL模型架构上的优化
(一)SDXL的整体架构
Stable Diffusion XL是一个二阶段的级联扩散模型,包括Base模型和Refiner模型:
- Base模型:主要工作和Stable Diffusion一致,具备文生图,图生图,图像inpainting等能力。(由U-Net,VAE,CLIP Text Encoder(两个)三个模块组成)
- Refiner模型:对Base模型生成的图像Latent特征进行精细化,其本质上是在做图生图的工作。(由U-Net,VAE,CLIP Text Encoder(一个)三个模块组成)
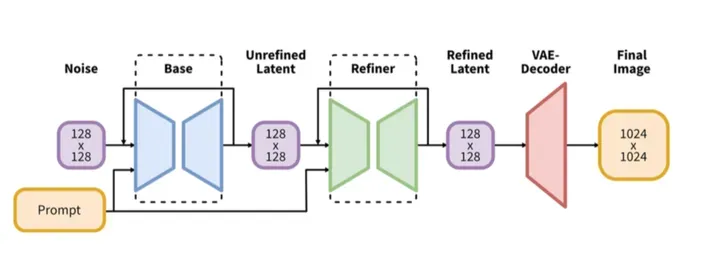
SDXL和之前的版本也是基于latent diffusion架构,对于latent diffusion,首先会采用一个auto encoder模型来图像压缩为latent,然后扩散模型用来生成latent,生成的latent可以通过auto encoder的decoder来重建出图像。
(二)VAE
SDXL的autoencoder依然采用KL-f8,但是并没有采用之前的autoencoder,而是基于同样的架构采用了更大的batch size(256 vs 9)重新训练,同时对模型的参数采用了EMA(指数移动平均),从而改善生成图片的局部和高频细节。重新训练的VAE模型相比之前的模型,其重建性能有一定的提升:
 上表中的三个VAE模型的模型结构完全一样:
上表中的三个VAE模型的模型结构完全一样:
- SD-VAE 2.x在SD-VAE 1.x的基础上重新微调了decoder部分,但是encoder权重是相同的,所以两者的latent分布是一样的,两个VAE模型是都可以用在SD 1.x和SD 2.x上的;
- SDXL-VAE是完全重新训练的,它的latent分布发生了改变,不可以将SDXL-VAE应用在SD 1.x和SD 2.x上。在将latent送入扩散模型之前,我们要对latent进行缩放来使得latent的标准差尽量为1,由于权重发生了改变,所以SDXL-VAE的缩放系数也和之前不同。
(三)U-Net
SDXL相比之前的版本,Unet的变化主要有如下两点:
-
Unet 结构发生了改变,从之前的4stage变成了3stage:
如图所示,相比之前的SD,SDXL的第一个stage采用的是普通的DownBlock2D,而不是采用基于attention的CrossAttnDownBlock2D;此外,SDXL只用了3个stage,只进行了两次2x下采样,而之前的SD使用4个stage,包含3个2x下采样。SDXL的网络宽度(channels)相比之前的版本并没有改变,3个stage的特征channels分别是320、640和1280。
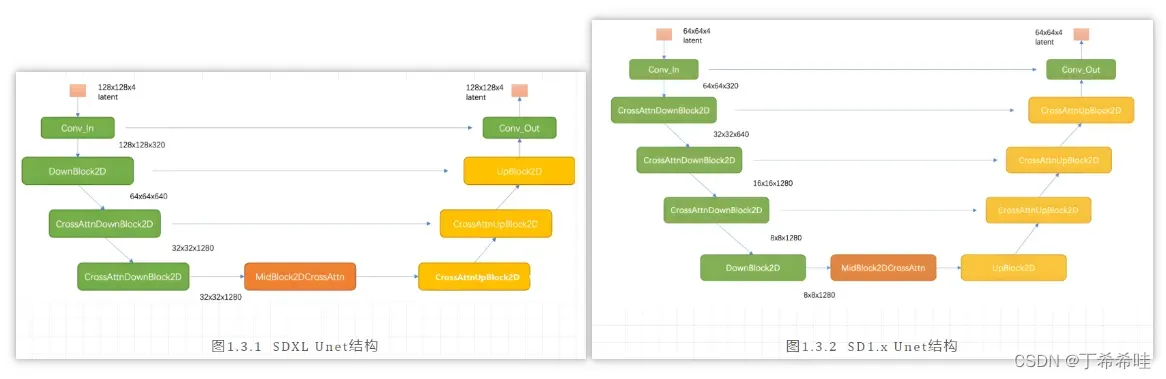
-
采用了更大的UNet,SDXL的U-Net模型(Base部分)参数量相比SD模型增加了3倍左右:
SDXL参数量的增加主要是使用了更多的transformer blocks,在之前的版本,每个包含attention的block只使用一个transformer block(self-attention -> cross-attention -> ffn),但是SDXL中stage2和stage3的两个CrossAttnDownBlock2D模块中的transformer block数量分别设置为2和10,并且中间的MidBlock2DCrossAttn的transformer blocks数量也设置为10。
(四)text encoder
- SD 1.x采用的text encoder是123M的OpenAI CLIP ViT-L/14,SD 2.x将text encoder升级为354M的OpenCLIP ViT-H/14,SDXL不仅采用了更大的OpenCLIP ViT-bigG(参数量为694M),而且同时也用了OpenAI CLIP ViT-L/14,分别提取两个text encoder的倒数第二层特征,其中OpenCLIP ViT-bigG的特征维度为1280,而CLIP ViT-L/14的特征维度是768,两个特征concat在一起总的特征维度大小是2048,这也就是SDXL的context dim;
- 此外,SDXL还提取了OpenCLIP ViT-bigG的 pooled text embedding(用于CLIP对比学习所使用的特征),将其映射到time embedding的维度并与之相加。
(五)refiner model
- refiner model是和base model采用同样VAE的一个latent diffusion model,但是它只在使用较低的noise level进行训练(只在前200 timesteps上)。在推理时,我们只使用refiner model的图生图能力。对于一个prompt,我们首先用base model生成latent,然后我们给这个latent加一定的噪音(采用扩散过程),并使用refiner model进行去噪。经过这样一个重新加噪再去噪的过程,图像的局部细节会有一定的提升;
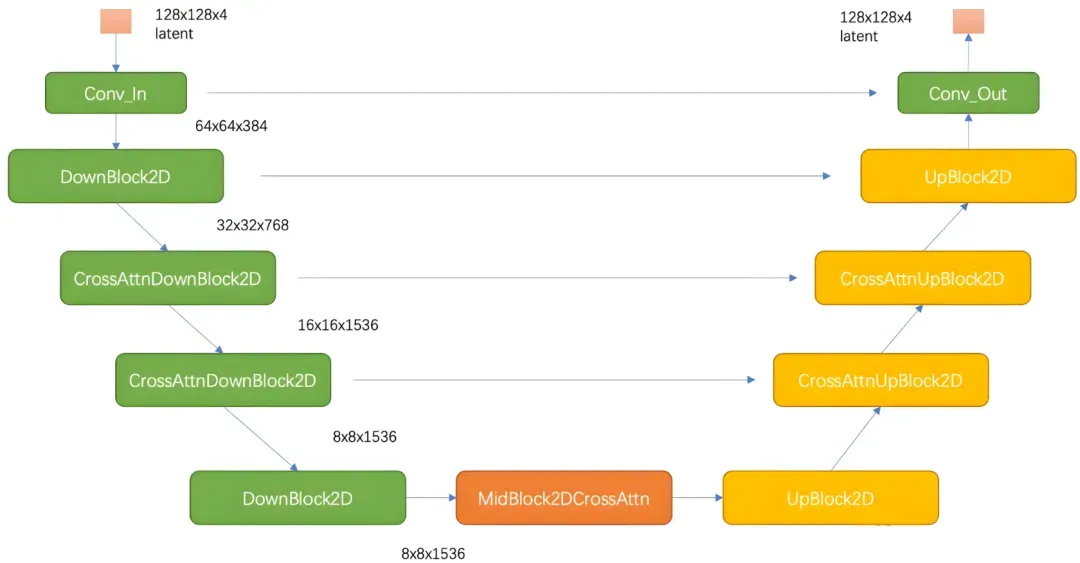
- refiner model和base model在结构上有一定的不同,其UNet的结构如下图所示,refiner model采用4个stage,第一个stage采用没有attention的DownBlock2D,网络的特征维度采用384,而base model是320。另外,refiner model的attention模块中transformer block数量均设置为4。refiner model的参数量为2.3B,略小于base model。refiner model的text encoder只使用了OpenCLIP ViT-bigG,也是提取倒数第二层特征以及pooled text embed。
三、SDXL在训练上的技巧
(一)图像尺寸条件化
Stable Diffusion 1.x/2.x存在的数据集利用率问题:
- Stable Diffusion 1.x/2.x 的训练过程主要分成两个阶段:先在256×256的图像尺寸上进行预训练,然后在512×512的图像尺寸上继续训练;
- 这两个阶段的训练过程都要对图像最小尺寸进行约束。第一阶段中,会将尺寸小于256×256的图像舍弃;在第二阶段,会将尺寸小于512×512的图像舍弃。这样会导致训练数据中的大量数据被丢弃,数据利用率不高,而且很可能导致模型性能和泛化性的降低。
SDXL的解决方案:
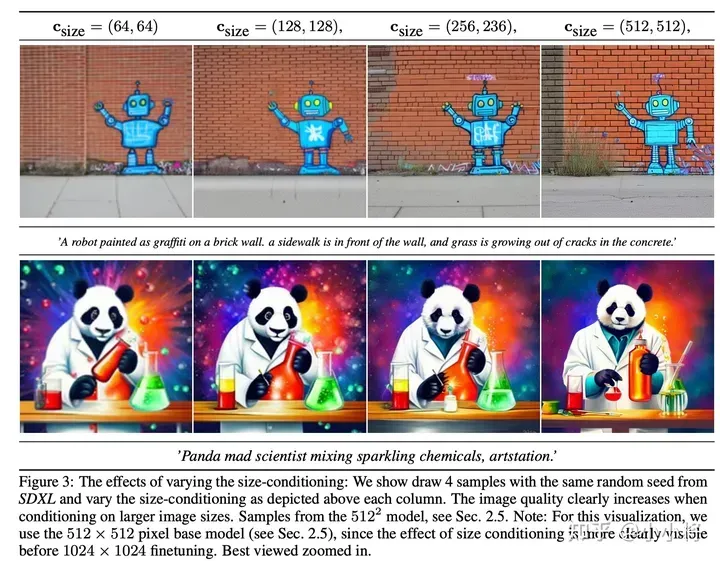
- 核心思想:将图像的原始尺寸(width和height)作为条件嵌入UNet模型中
- 嵌入方式:height和width分别用傅里叶特征编码,然后将特征concat后加在Time Embedding上;
- 这相当于让模型学到了图像分辨率参数,在训练过程中,我们可以不过滤数据直接resize图像,在推理时,我们只需要送入目标分辨率而保证生成的图像质量。
(二)图像裁剪参数条件
Stable Diffusion 1.x/2.x存在的图像裁剪问题:
- 目前文生图模型预训练往往采用固定图像尺寸,这就需要对原始图像进行预处理,这个处理流程一般是先将图像的最短边resize到目标尺寸,然后沿着图像的最长边进行裁剪;
- 训练中对图像裁剪导致的图像特征丢失,可能会导致模型在图像生成阶段出现不符合训练数据分布的特征,比如图像出现缺失等问题。
SDXL的解决方案:图像裁剪参数条件化策略
- 主要思想:将训练过程中裁剪的左上定点坐标作为额外的条件注入到UNet中
- 注入方式:通过傅立叶编码并加在time embedding上
- 在推理时,我们只需要将这个坐标设置为(0, 0)就可以得到物体居中的图像(此时图像相当于没有裁剪)。
(三)多尺度(宽高比)图片训练
现实数据集中包含不同宽高比的图像,然而文生图模型输出一般都是512×512或者1024×1024,作者认为这并不是一个好的结果,因为不同宽高比的图像有广泛的应用场景,比如(16:9)。基于以上原因,作为对模型进行了多尺度图像微调。
SDXL的解决方案:多尺度训练策略
- 多尺度训练策略:借鉴NovelAI所提出的方案,将数据集中图像按照不同的长宽比划分到不同的buckets上(按照最近邻原则);
- 在训练过程中,每个step可以在不同的buckets之间切换,每个batch的数据都是从相同的bucket中采样得到;
- SDXL也将bucket size即target size作为条件加入UNet中,这个条件注入方式和之前图像原始尺寸条件注入一样。
参考:
Stable Diffusion XL(SDXL)原理详解
深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识
文生图模型之SDXL
版权声明:本文为博主作者:丁希希哇原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_47748259/article/details/135541372