PS:好久没写csdn了,有点忙,但更多的是比较懒。
今天分享的论文是OSTrack:Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework
论文网址:https://arxiv.org/pdf/2203.11991.pdf
GitHub网址:https://github.com/botaoye/OSTrack
单目标跟踪的相关背景就不详细展开。
目录
双流两阶段架构
开始前,先讲一下双流两阶段架构。
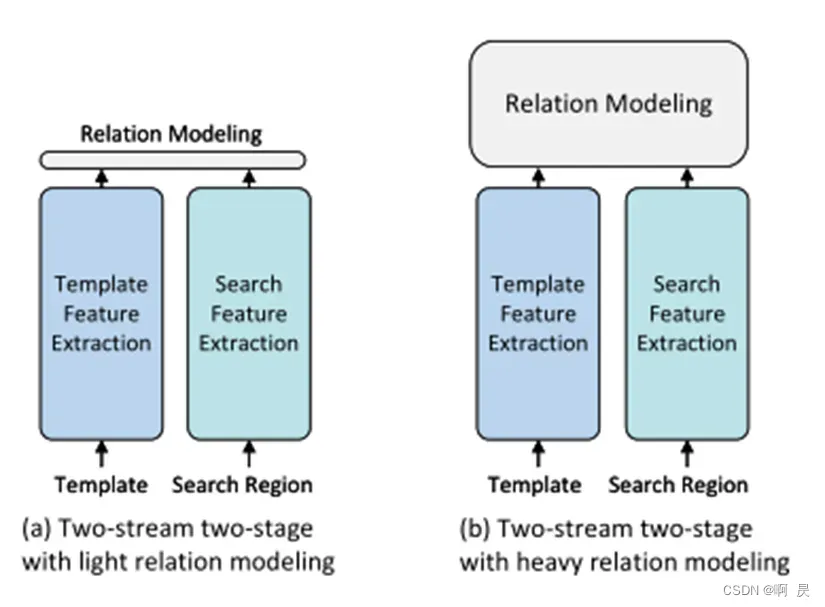
目前主流的跟踪器通常使用通用的双流和两阶段组件来区分目标与背景,这意味着模板和搜索区域的特征是分别提取的(双流),整个过程分为两个顺序步骤:特征提取和关系建模(两阶段)。这种从SiamFC延续而来的模型架构采用了“分而治之”的策略,在跟踪性能方面取得了显著的成功。(图源:MixFormer)
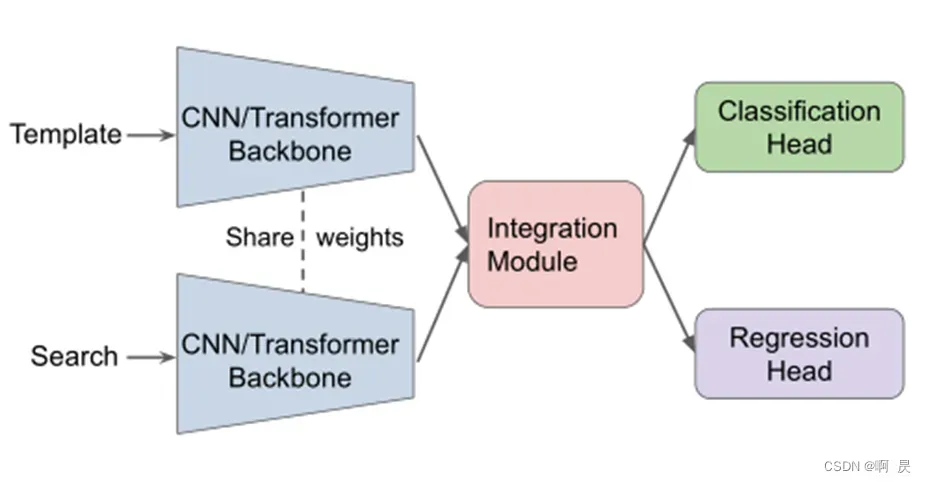
比如说SiamFC、SiamRPN、TransT等架构,都属于双流两阶段架构。
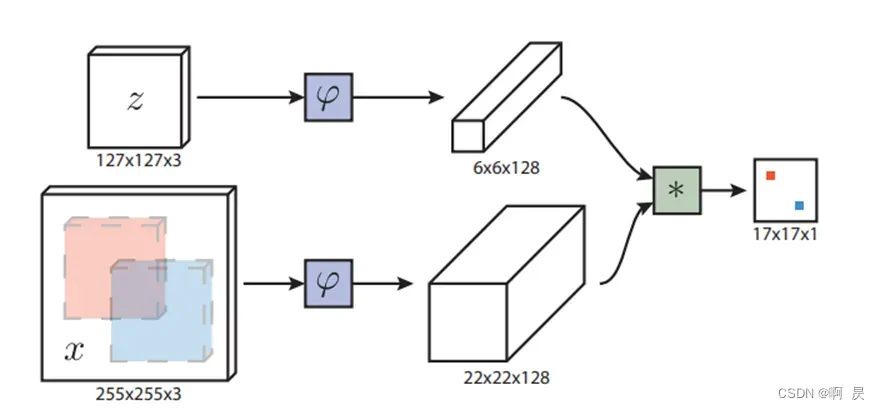
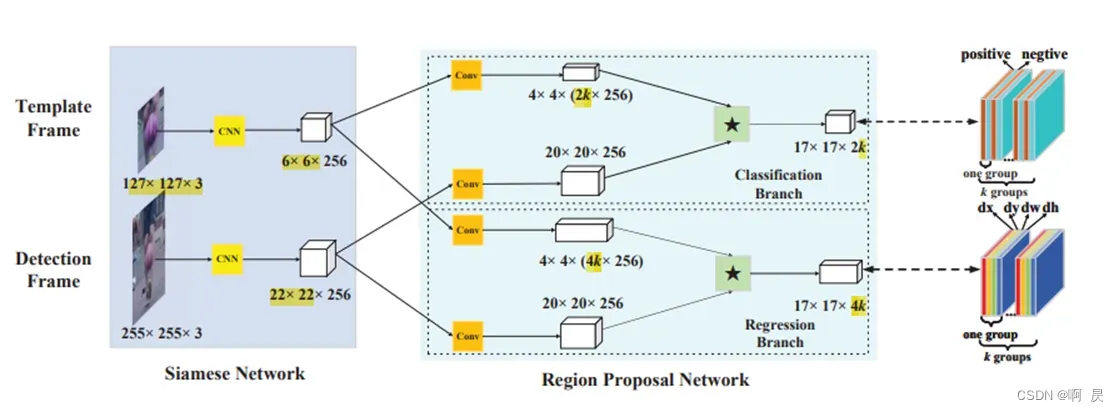
但是,OSTrack论文中说明了此架构的一些缺点:
- 双流两阶段架构在特征提取阶段缺乏目标信息。换句话说,每个图像的特征提取是在离线训练后确定的,模板和搜索区域之间没有交互。这与目标的不断变化和随意性相矛盾,从而导致目标与背景的区分能力受限。
- 其次,双流两阶段的架构容易受到性能的影响。根据特征融合模块的计算负担,通常使用两种不同的策略。第一种类型,如图(a)所示,简单地采用了一个单一的算子,如互相关,速度块,但效果较差,因为简单的线性运算会导致判别信息丢失。第二种类型,如图(b)所示,采用编解码架构,解决了复杂非线性交互造成的信息损失但由于大量参数和迭代细化的使用,效率较低。(图源:OStrack)
单流单阶段架构
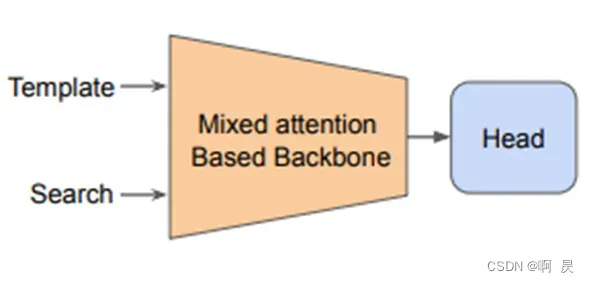
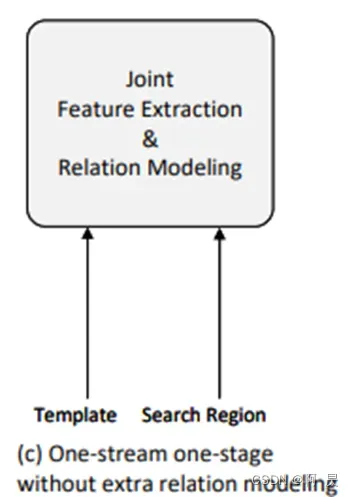
另一种架构模型在近一年被提出—单流单阶段架构。比如说MixFormer及本文要分享的OSTrack。
它们的特点是:
将特征提取和特征融合统一在一个模块中,并将它们输入到标记的自注意层,生成的搜索区域特征可以直接用于目标分类和回归,而无需进一步匹配。
该架构具有以下优势(OSTrack中提及):
- 它使特征提取能够动态地意识到相应的跟踪目标,并从浅层就能区分目标和背景,从而捕获更多目标特定的特征。
- 它允许将目标信息更广泛地集成到搜索区域中,以更好地捕捉它们之间的相关性。
- 由于不需要额外的重型关系建模模块,该模型架构实现了高度的并行化,更加紧凑简洁和高效,因此所提出的跟踪器运行速度很快。
(上图源:MIXFormer,下图源:OSTrack)
OSTrack模型
OSTrack模型相比于其他模型,独特的创新点:
- 将特征提取和关系建模相结合,提出了一个简单、整洁、有效的单流单阶段跟踪框架。
- 提出一个网络(基于VIT)内早期候选消除模块,用于及时逐步识别和丢弃属于背景的候选者。所提出的候选消除模块不仅显著提高了推理速度,而且避免了无信息背景区域对特征匹配的负面影响。
其中第二点的早期候选消除模块是重点后文将详细讲解。
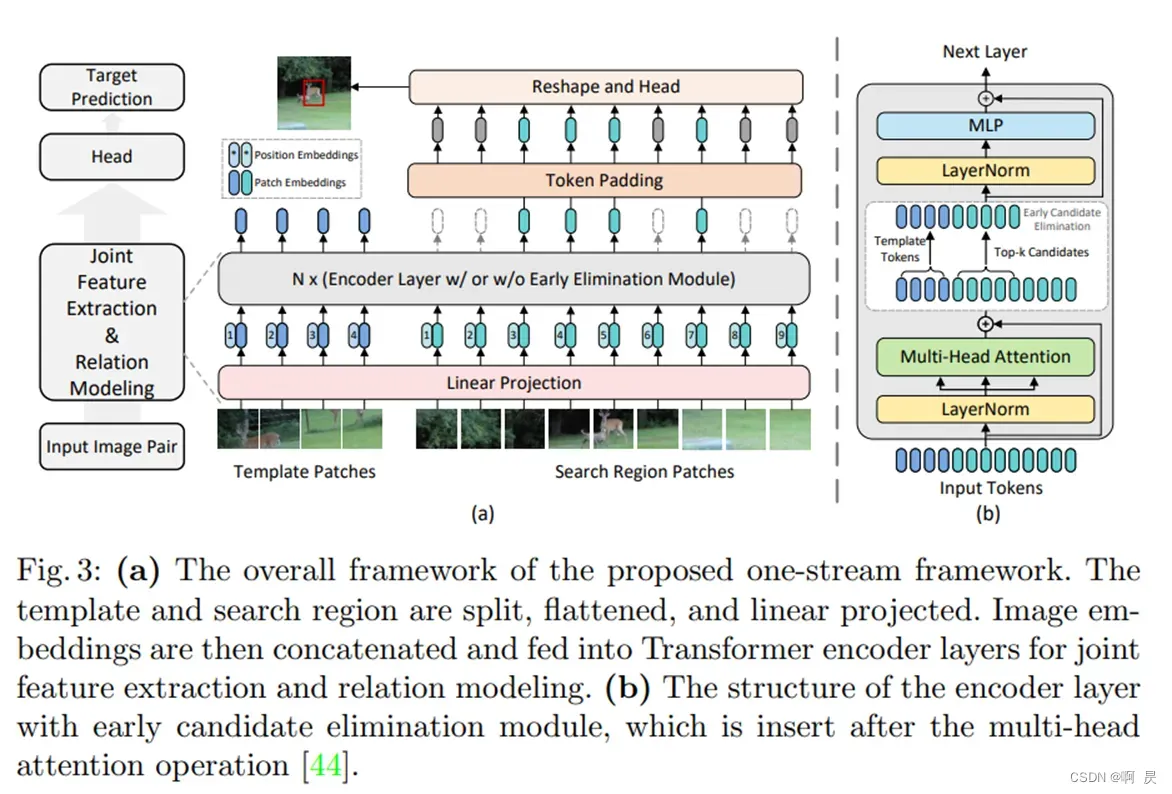
如上图所示,OSTrack模型流程可简单分为以下几步:
- Search_pic和Template_pic进行patch embeding让图片变成一个一个块
- flatten得到template_token(也可称为template_feature) search_token(search_feature) 并加上位置编码,再将两个token
拼接起来,送入后面的N个encoder层(N一般取12) 。 - 每第3、6、9(可手动更改,这里给出的是基线模型的设置)个encoder,执行候选消除模块 。
- 对search_token中消除的块进行padding 得到最终的search_token (由于template_token不会消除模块,所以template_token不变)。 将两个token 再拼接,得到最终的X。
- 对X后处理。
候选消除模块
(PS:这也是写这篇文章的主要原因,也看过很多的CSDN博客,但都草草略过这个关键点。本文的目的是详细的讲明这个关键点)
大致思想:
- search图像中的每个patch都可以被看作是一个目标候选区域。
- 在每个候选消除模块中,每个候选区域会被计算一个与template图像的相似度作为其得分,得分最高的k个候选区域会被保留下来,其他的候选区域则会被丢弃。
- 为了避免template中背景区域的影响,在本文中作者并没有使用候选区域与每个template patch计算相似度并取均值,而是直接计算其与template最中心位置的patch之间的相似度作为其得分。可以这样做的原因在于经过self-attention操作之后,中心的template patch已经聚集了足够的目标信息。
- 由于这些背景区域不会对分类和回归操作造成影响,因此在Transformer输出之前,这些中途被丢弃的区域直接做zero-padding (作者想法)即可将特征恢复成原尺寸。
首先看如下的流程图。
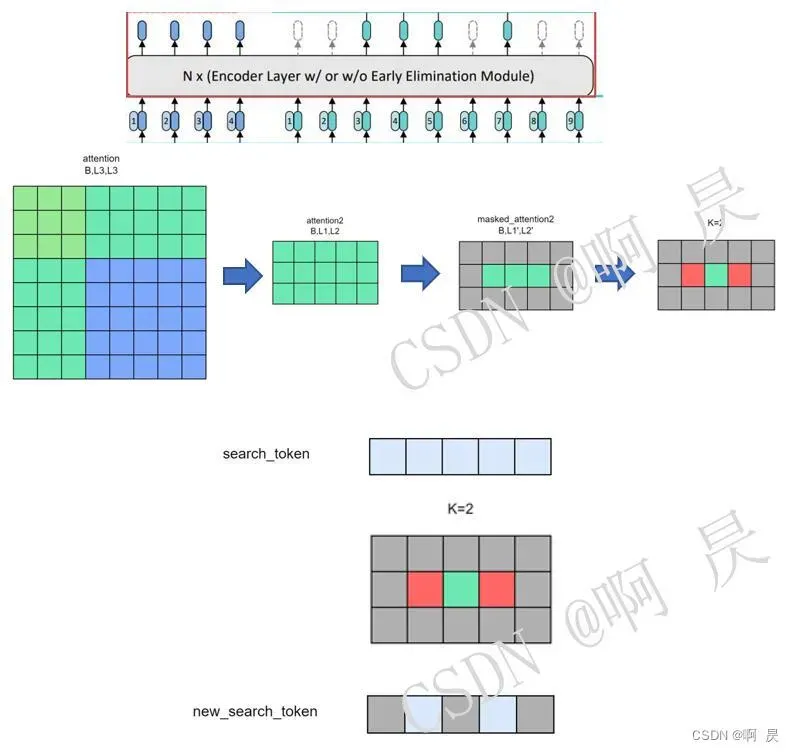
接着配合代码再来过一遍流程
核心代码来源:https://github.com/botaoye/OSTrack/blob/main/lib/models/layers/attn_blocks.py


PS:代码中的box_mask_z的具体实现来源于:https://github.com/botaoye/OSTrack/blob/main/lib/utils/ce_utils.py#L15
大致思想就是只保留attention的中心部分。通过对周围区域赋0,对中心区域赋1来达到掩码的效果。
其它(简单略过)
Head部分的结构也比较简单,包括三个分支,分别预测分类得分 、为了补偿下采样量化误差而预测的偏移值 以及归一化的bounding box尺寸
损失函数方面:对于分类分支,采用了weighted focal loss即与GT中心距离越远的位置权重越低。对于回归分支,则使用了常用的IoU loss以及L1 loss的组合。
![]() ||||||||
||||||||![]()
实验及结果
消融实验:比较双流双级架构和单流单级架构
其中第三行结果是OSTrack在没有早期候选消除模块的情况下的结果。(为了防止候选消除模块对结果的影响)

PS:最后一行是添加了候选消除模块的OSTrack模型。
发现添加早期候选者消除模块后,效果下降不明显(略微提升),FPS还得到的较大提升,展现了单流单级架构的优势。
GOT-10K上与其他模型的比较
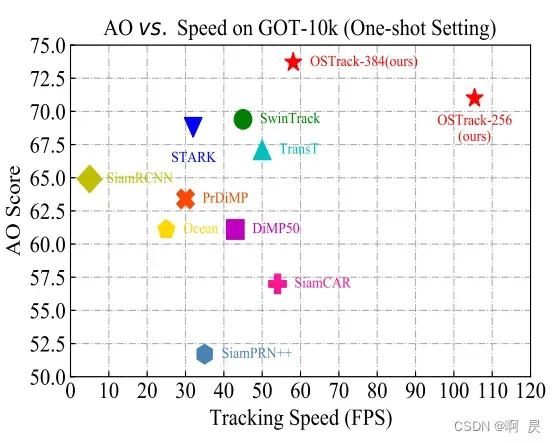
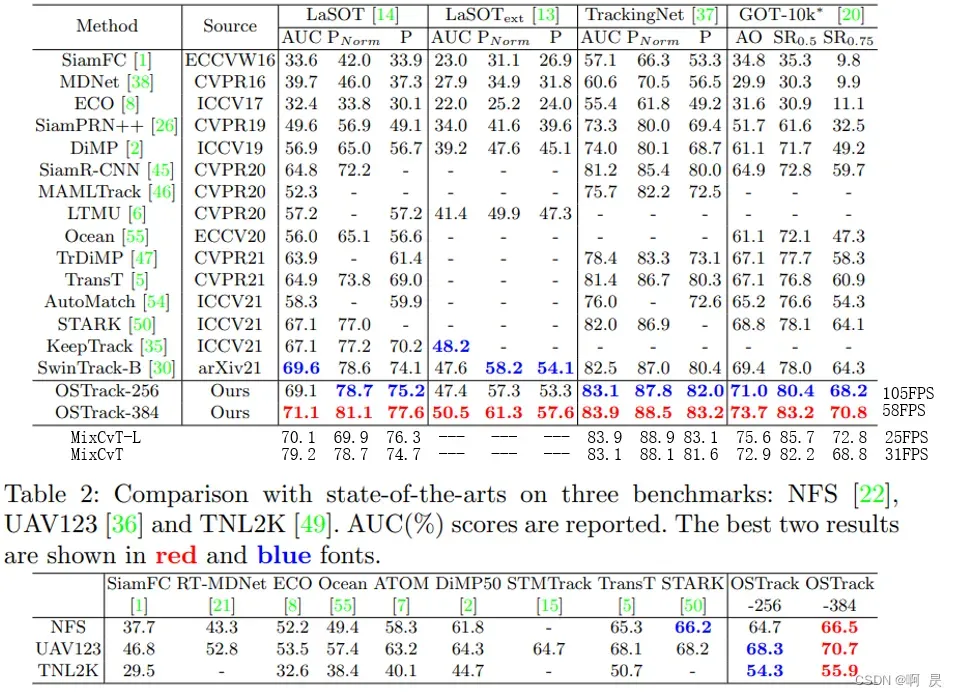
PS:由于OSTrack交稿期间MixFormer论文还没发表,因此作者没有与MixFormer论文进行比较,我在Table1中最后二行添加了MixFormer的两个模型的结果(具体的模型对应的信息可以看MixFormer相关论文)。
总结
- 提出了一个简单、整洁、高性能的基于Vision Transformer的单流跟踪框架,该框架突破了孪生网络的传统架构。所提出的跟踪器结合了特征提取和关系建模任务,在性能和推理速度之间表现出良好的平衡。
- 提出了一种早期候选消除模块,该模块逐步丢弃属于背景区域的搜索区域标记,显著提高了跟踪推理速度。大量实验表明,所提出的单流跟踪器在多个基准测试上的性能比以前的方法要好得多。
额外补充
MixFormer论文:https://arxiv.org/pdf/2302.02814.pdf
欢迎指正
因为本文主要是本人用来做的笔记,顺便进行知识巩固。如果本文对你有所帮助,那么本博客的目的就已经超额完成了。
本人英语水平、阅读论文能力、读写代码能力较为有限。有错误,恳请大佬指正,感谢。
欢迎交流
邮箱:refreshmentccoffee@gmail.com
版权声明:本文为博主作者:啊 昃原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_44799766/article/details/131074627