博文介绍的DeepLabV3 代码主要来自于pytorch官方torchvision模块中的源码。
1. DeepLabv3代码的使用
环境配置
- Python3.6 以上
- Pytorch1.10
- Ubuntu或Centos(Windows暂不支持多GPU训练)
- 最好使用GPU训练
- 详细环境配置见requirements.txt
文件结构
├── src: 模型的backbone以及DeepLabv3的搭建
├── train_utils: 训练、验证以及多GPU训练相关模块
├── my_dataset.py: 自定义dataset用于读取VOC数据集
├── train.py: 以deeplabv3_resnet50为例进行训练
├── train_multi_GPU.py: 针对使用多GPU的用户使用
├── predict.py: 简易的预测脚本,使用训练好的权重进行预测测试
├── validation.py: 利用训练好的权重验证/测试数据的mIoU等指标,并生成record_mAP.txt文件
└── pascal_voc_classes.json: pascal_voc标签文件
预训练权重下载地址
- 注意:官方提供的预训练权重是在COCO上预训练得到的,训练时只针对和PASCAL VOC相同的类别进行了训练,所以类别数是21(包括背景)
- deeplabv3_resnet50: https://download.pytorch.org/models/deeplabv3_resnet50_coco-cd0a2569.pth
- deeplabv3_resnet101: https://download.pytorch.org/models/deeplabv3_resnet101_coco-586e9e4e.pth
- deeplabv3_mobilenetv3_large_coco: https://download.pytorch.org/models/deeplabv3_mobilenet_v3_large-fc3c493d.pth
注意,下载的预训练权重记得要重命名,比如在train.py中读取的是deeplabv3_resnet50_coco.pth文件, 不是deeplabv3_resnet50_coco-cd0a2569.pth
数据集
本例程使用的是PASCAL VOC2012数据集
Pascal VOC2012 train/val数据集下载地址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
如果不了解数据集或者想使用自己的数据集进行训练,请参霹雳啪啦博文: https://blog.csdn.net/qq_37541097/article/details/115787033
训练方法
- 确保提前准备好数据集
- 确保提前下载好对应预训练模型权重
- 若要使用单GPU或者CPU训练,直接使用train.py训练脚本
- 若要使用多GPU训练,使用
torchrun --nproc_per_node=8 train_multi_GPU.py指令,nproc_per_node参数为使用GPU数量 - 如果想指定使用哪些GPU设备可在指令前加上CUDA_VISIBLE_DEVICES=0,3(例如我只要使用设备中的第1块和第4块GPU设备)
- CUDA_VISIBLE_DEVICES=0,3 torchrun –nproc_per_node=2 train_multi_GPU.py
注意事项
- 在使用训练脚本时,注意要将
'--data-path'(VOC_root)设置为自己存放'VOCdevkit'文件夹所在的根目录 - 在使用预测脚本时,要将
'weights_path'设置为你自己生成的权重路径。 - 使用validation文件时,注意确保你的验证集或者测试集中必须包含每个类别的目标,并且使用时只需要修改
'--num-classes'、'--aux'、'--data-path'和'--weights'即可,其他代码尽量不要改动
对DeepLabV3网络不熟悉,可以参考我的博客 图像分割:DeepLabV3网络讲解
Pytorch官方实现的DeeplabV3网络框架图
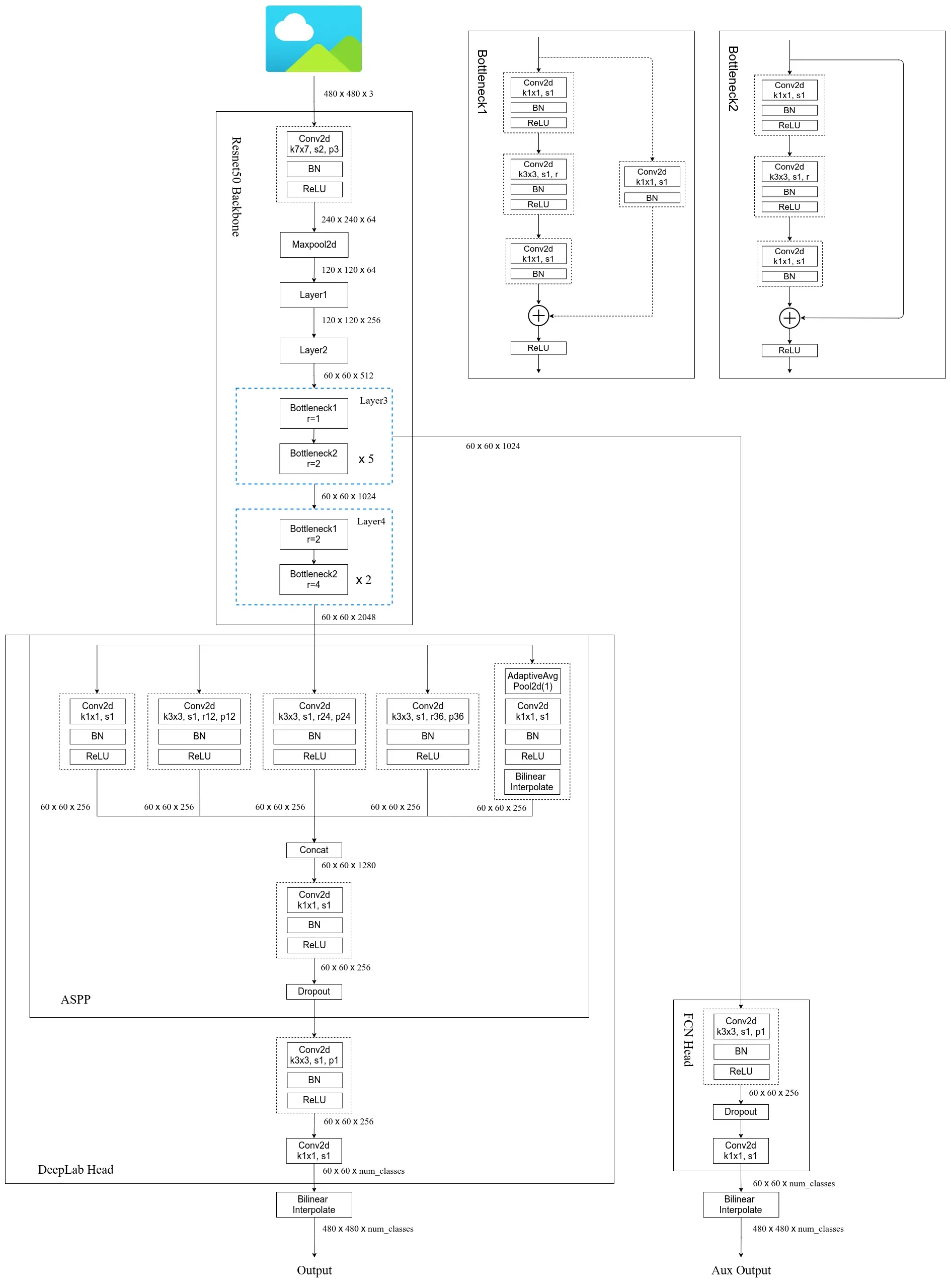
2. 源码讲解
2.1 train 脚本
2.1.1 学习率策略poly
DeepLabV3的train脚本和之前将FCN源码时,使用的train基本是一模一样的,无论是训练还是去验证我们的模型,各项指标的代码都是一模一样的。所以关于重复的部分就不再细讲了。这里讲解下之前没有讲到过的学习率更新策略代码。
# 创建学习率更新策略,这里是每个step更新一次(不是每个epoch)
lr_scheduler = create_lr_scheduler(optimizer, len(train_loader), args.epochs, warmup=True)
在DeepLab V2网络中我们提到过,论文中提出了一种poly的训练策略, 它的学习率公式:
论文中power=0.9 。
create_lr_scheduler函数的代码如下:
def create_lr_scheduler(optimizer,
num_step: int,
epochs: int,
warmup=True,
warmup_epochs=1,
warmup_factor=1e-3):
assert num_step > 0 and epochs > 0
if warmup is False:
warmup_epochs = 0
def f(x):
"""
根据step数返回一个学习率倍率因子,
注意在训练开始之前,pytorch会提前调用一次lr_scheduler.step()方法
"""
if warmup is True and x <= (warmup_epochs * num_step):
alpha = float(x) / (warmup_epochs * num_step)
# warmup过程中lr倍率因子从warmup_factor -> 1
return warmup_factor * (1 - alpha) + alpha
else:
# warmup后lr倍率因子从1 -> 0
# 参考deeplab_v2: Learning rate policy
return (1 - (x - warmup_epochs * num_step) / ((epochs - warmup_epochs) * num_step)) ** 0.9
return torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=f)
- 传入的参数
num_step代表的是训练一个Epoch需要迭代多少步。epochs代表我们总共要迭代多少个Epoch。warmup代表是否使用热身训练,现在一般都会使用warmup做个热身训练,所以它默认是为True。warmup_epochs表示我们热身训练要保持多少个Epoch,这里默认的是1。` f(x): 传入的参数x代表当前训练的steps数,return返回的是当前steps下的学习率倍率因子,也就是当前所采用的学习率= lr(初始学习率) * 倍率因子。- 当采用warmup时,warmup过程中lr倍率因子从
warmup_factor 到 1 - 在warmup之后,学习率倍率因子的变换,就是
poly的策略对应代码:(1 - (x - warmup_epochs * num_step) / ((epochs - warmup_epochs) * num_step)) ** 0.9,如果我们启用了warmup时,我们的step数需要减去之前warmup的step数:warmup_epochs * num_step,如果没启用warmups,那么warmup_epochs * num_step=0,计算方式和poly公式是一模一样的。
下面的代码可以将学习率绘制出来
import matplotlib.pyplot as plt
lr_list = []
for _ in range(args.epochs):
for _ in range(len(train_loader)):
lr_scheduler.step()
lr = optimizer.param_groups[0]["lr"]
lr_list.append(lr)
plt.plot(range(len(lr_list)), lr_list)
plt.show()
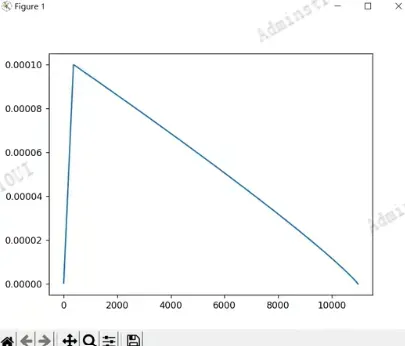
- 学习率曲线的横坐标对应迭代的steps数,纵坐标对应的是学习率。本文采用的是迁移学习的方法,因此初始学习率lr设置的比较低为0.0010 。从图中可以看到
lr从非常小的数值慢慢递增到我们设置的初始学习率(对应warmup的过程),然后再慢慢的下降,下降采用的策略就是poly策略
2.1.2 模型构建
对应的脚本在train.py中的create_model函数,这里默认采用deeplabv3_restnet50的版本。
model = deeplabv3_resnet50(aux=aux, num_classes=num_classes)
- 如果你想去使用其他版本的话,可以import 出对应的模型构建方法,这些方法都已在src文件中的代码实现了,直接引用就可以。比如导入
deeplabv3_mobilenetv3_large如下:
from src import deeplabv3_resnet50,deeplabv3_mobilenetv3_large
deeplabv3_resnet50搭建
- 构建模型的第一个参数为
aux,pytorch官方实现的deeplabv3_resnet50模型,它有加上辅助分类器,当然你也可以不去使用。它是根据aux参数进行设置的,如果aux为True,则使用辅助分类器,否则不使用。num_classes对应的是我们分类的类别数,pretrain表示我们是否去使用预训练模型。这里的预训练模型指的是官方提前在coco数据集训练好的模型权重。这里会删除掉权重当中和类别相关的权重。因为你所采用的分类类别个数和预训练权重的类别个数一样。所以这里会将类别权重给先删除掉,然后载入剩余的权重。
if pretrain:
weights_dict = torch.load("./deeplabv3_resnet50_coco.pth", map_location='cpu')
if num_classes != 21:
# 官方提供的预训练权重是21类(包括背景)
# 如果训练自己的数据集,将和类别相关的权重删除,防止权重shape不一致报错
for k in list(weights_dict.keys()):
if "classifier.4" in k:
del weights_dict[k]
missing_keys, unexpected_keys = model.load_state_dict(weights_dict, strict=False)
if len(missing_keys) != 0 or len(unexpected_keys) != 0:
print("missing_keys: ", missing_keys)
print("unexpected_keys: ", unexpected_keys)
接下来看看deeplabv3_resnet50内部是如何构建的
def deeplabv3_resnet50(aux, num_classes=21, pretrain_backbone=False):
# 'resnet50_imagenet': 'https://download.pytorch.org/models/resnet50-0676ba61.pth'
# 'deeplabv3_resnet50_coco': 'https://download.pytorch.org/models/deeplabv3_resnet50_coco-cd0a2569.pth'
backbone = resnet50(replace_stride_with_dilation=[False, True, True])
if pretrain_backbone:
# 载入resnet50 backbone预训练权重
backbone.load_state_dict(torch.load("resnet50.pth", map_location='cpu'))
out_inplanes = 2048
aux_inplanes = 1024
return_layers = {'layer4': 'out'}
if aux:
return_layers['layer3'] = 'aux'
backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
aux_classifier = None
# why using aux: https://github.com/pytorch/vision/issues/4292
if aux:
aux_classifier = FCNHead(aux_inplanes, num_classes)
classifier = DeepLabHead(out_inplanes, num_classes)
model = DeepLabV3(backbone, classifier, aux_classifier)
return model
- 首先创建一个resnet50的backbone, 与一般的resnet50的差别存在一个
replace_stride_with_dilation, 我们这里创建的resnet50和之前讲FCN是一模一样的,这边就不再细讲了,不懂的话可以参考: 图像分割FCN(3):FCN模型搭建和自定义数据集 - 对于pretrain参数,默认是设置为False的,针对backbone如果你不想使用官方在coco数据集上预训练的权重,可以将
pretain_backbone设置为True, 它就会载入在ImageNet上预训练好的resnet50权重。 - 然后通过
IntermediateLayerGetter方法去重构我们的backbone,将resnet网络中我们没用到的如全局池化,和全连接层去掉。这部分在之前图像分割FCN(3):FCN模型搭建和自定义数据集,有讲到过,这边就不再赘述了。 - 然后实例化辅助分类器,并实例化
DeepLabHead构建主分类器,DeepLabHead对应的网络结构见下图所示。DeepLabHead包括ASPP模块以及1个3x3卷积和1个1x1卷积。
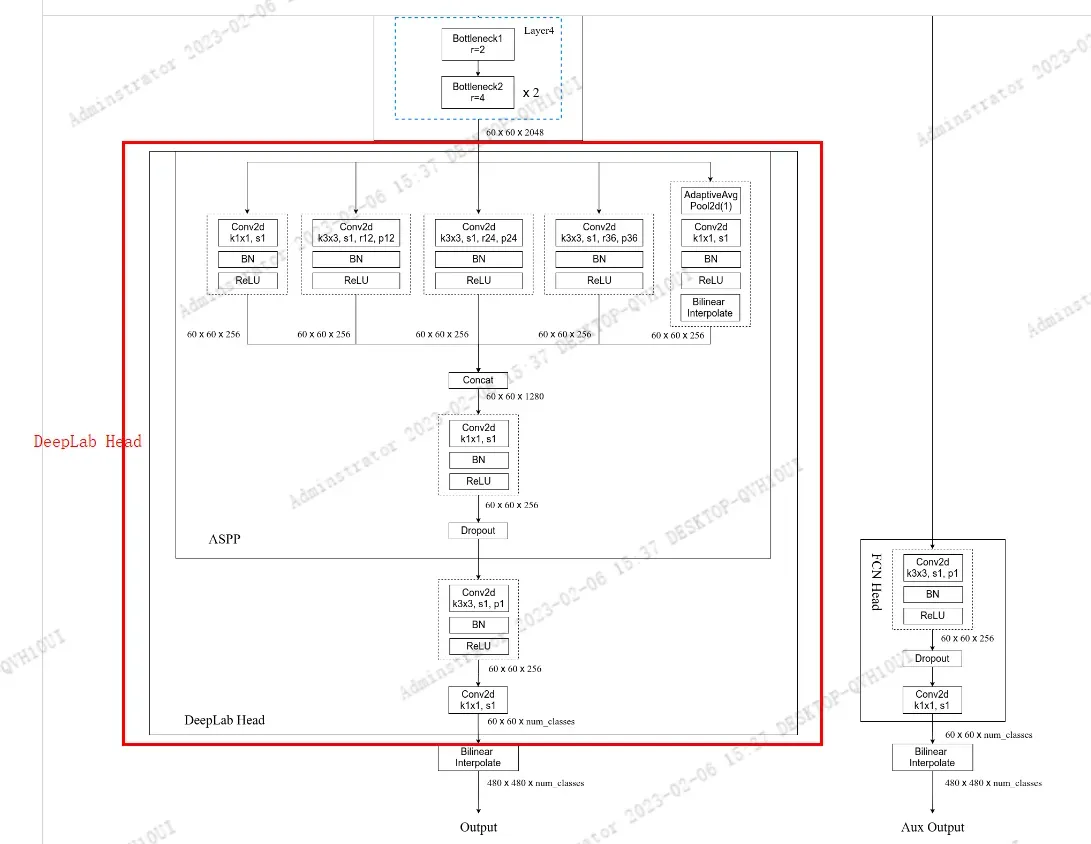
DeepLabHead的第一个参数out_inplanes是输入主分类器的channel,对应backbone中Layer4的输出channel(2048),第二个参数num_classes对应分类类别数(包含背景), DeepLabHead类对应的代码如下:
class DeepLabHead(nn.Sequential):
def __init__(self, in_channels: int, num_classes: int) -> None:
super(DeepLabHead, self).__init__(
ASPP(in_channels, [12, 24, 36]),
nn.Conv2d(256, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, num_classes, 1)
)
- DeepLabHead类继承
nn.Sequential,然后调用 super的__init__, 顺序传入搭建网络需要的一系列结构。 - 首先传入的是ASPP结构,参数
in_channels对应为backbone输出特征成的channel(layer4的输出channel), 第二个参数是ASPP中3个膨胀卷积层采用的膨胀系数[12, 24, 36]。
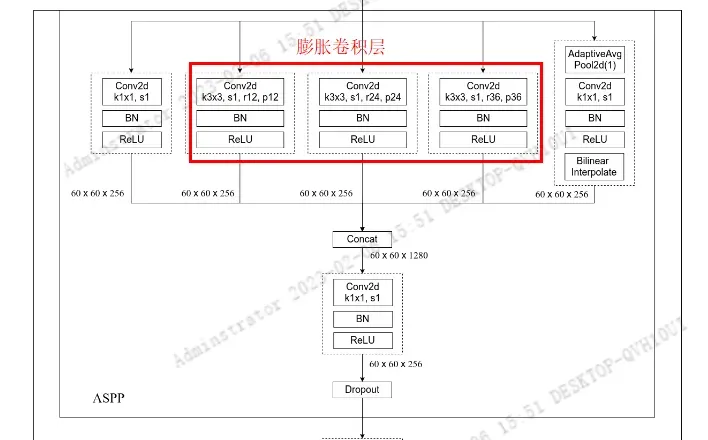
ASPP的构建
class ASPP(nn.Module):
def __init__(self, in_channels: int, atrous_rates: List[int], out_channels: int = 256) -> None:
super(ASPP, self).__init__()
modules = [
nn.Sequential(nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU())
]
rates = tuple(atrous_rates)
for rate in rates:
modules.append(ASPPConv(in_channels, out_channels, rate))
modules.append(ASPPPooling(in_channels, out_channels))
self.convs = nn.ModuleList(modules)
self.project = nn.Sequential(
nn.Conv2d(len(self.convs) * out_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Dropout(0.5)
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
_res = []
for conv in self.convs:
_res.append(conv(x))
res = torch.cat(_res, dim=1)
return self.project(res)
- ASPP 方法中参数
atrous_rates就是我们要构建的3个膨胀卷积对应的膨胀系数。out_channel表示通过膨胀卷积后将channel调整到多少,默认为256。 - ASPP结构一共有
5个分支,第一个分支是1x1卷积层,第2,3,4分支都对应的是膨胀卷积。最后一个分支首先通过一个全局平均池化(AdaptiveAvgPool2d)将特征图池化到1x1大小,然后再通过1x1卷积层去调整channel, 然后通过双线性插值的方法调整到输入特征图的宽高(60×60)。此时这5个分支的特征矩阵的channel和宽高都是一样的了。
1)构建5个分支
- 首先在modules的列表中,加入
第一个分支,也就是1x1卷积,利用nn.Sequetial,分别传入1x1 Conv +BN+Relu
modules = [
nn.Sequential(nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU())
]
- 然后循环遍历,构建
3个膨胀卷积ASPPConv,并分别添加到modules列表中, 其中ASPPConv结构,就是普通的膨胀卷积层。由于采用的是膨胀卷积,padding和dilation`都是一样的,对应的是膨胀系数
ASPPConv
class ASPPConv(nn.Sequential):
def __init__(self, in_channels: int, out_channels: int, dilation: int) -> None:
super(ASPPConv, self).__init__(
nn.Conv2d(in_channels, out_channels, 3, padding=dilation, dilation=dilation, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
- 最后再构建
最后一个分支对应的是ASPPPooling,并添加到modules列表中, 其中ASPPPooling实现的代码如下:
class ASPPPooling(nn.Sequential):
def __init__(self, in_channels: int, out_channels: int) -> None:
super(ASPPPooling, self).__init__(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
size = x.shape[-2:]
for mod in self:
x = mod(x)
return F.interpolate(x, size=size, mode='bilinear', align_corners=False)
- 再这个方法中,首先构建一个自适应平均池化
AdaptiveAvgPool2d,池化后特征层的宽高变为1x1,然后再创建1x1卷积来调节输出的channel,最后跟上BN和ReLu - 将输出传入到双线性插值
interpolate还原到输入特征矩阵x的尺度。
2) 构建project层
将modules列表传入到nn.ModuleList中,就完成了5个分支的构建,另外还需要构建一个映射层project层,project层就是对应结构图中5个分支concat拼接后的1x1卷积层。
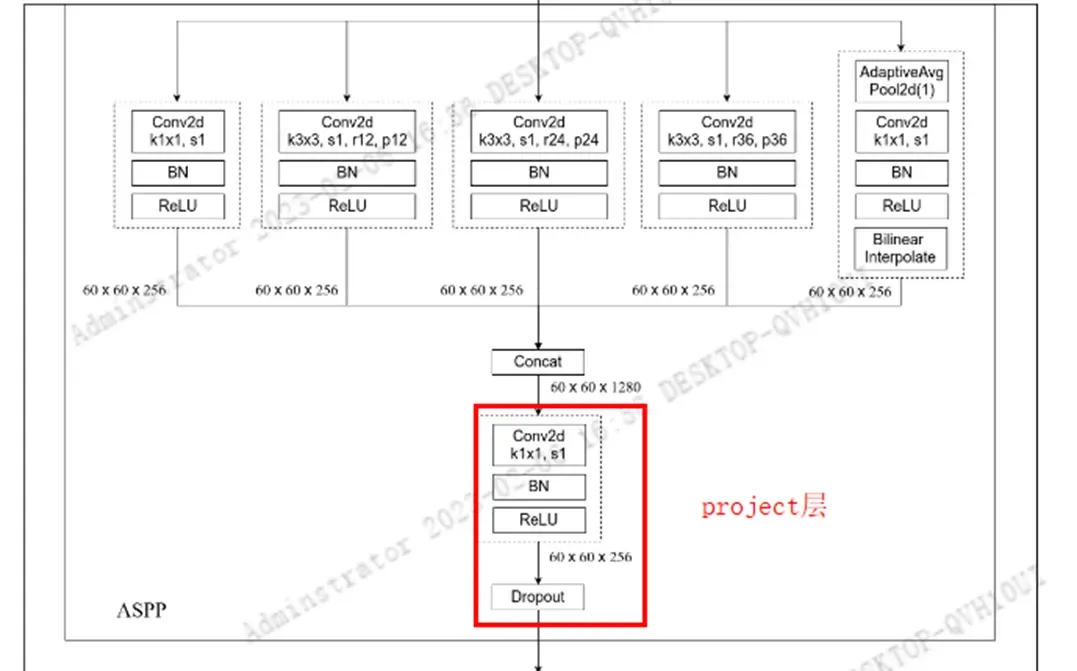
- project层就是一个
1x1的卷积,它的in_channels,就是5个分支concat后的channels, 经过1x1卷积之后会将channels调整到out_channels。
self.project = nn.Sequential(
nn.Conv2d(len(self.convs) * out_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Dropout(0.5)
)
以上就完成了ASPP结构的构建
3×3 Conv + 1×1 Conv
构建好ASPP后,还需要在接上一个3x3卷积,跟上BN 和ReLu,最后在通过1x1卷积将输出channel调整到num_classes,注意1×1卷积后面是没有跟BN和Relu的
class DeepLabHead(nn.Sequential):
def __init__(self, in_channels: int, num_classes: int) -> None:
super(DeepLabHead, self).__init__(
ASPP(in_channels, [12, 24, 36]),
nn.Conv2d(256, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, num_classes, 1)
)
这样就构建好了主分支的分类器classifer
利用backbone,classifer,aux_classifer构建model
model = DeepLabV3(backbone, classifier, aux_classifier)
class DeepLabV3(nn.Module):
__constants__ = ['aux_classifier']
def __init__(self, backbone, classifier, aux_classifier=None):
super(DeepLabV3, self).__init__()
self.backbone = backbone
self.classifier = classifier
self.aux_classifier = aux_classifier
def forward(self, x: Tensor) -> Dict[str, Tensor]:
input_shape = x.shape[-2:]
# contract: features is a dict of tensors
features = self.backbone(x)
result = OrderedDict()
x = features["out"]
x = self.classifier(x)
# 使用双线性插值还原回原图尺度
x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)
result["out"] = x
if self.aux_classifier is not None:
x = features["aux"]
x = self.aux_classifier(x)
# 使用双线性插值还原回原图尺度
x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)
result["aux"] = x
return result
- 将数据传入backbone获得特征层feature,利用键值
out取出对应layer4层的输出作为主分支classifier的输入特征矩阵,利用键值aux取出对应layer3层的输出作为辅助分类器aux_classifier的输入特征矩阵 - 接着将对应输入分别传给主分类器classifier得到输出,然后利用双线性插值还原到原图尺度上,将结果保存result字典中,对应result中键值为key的值中
- 如果
self.aux_classifier的话,就会将对应输入传给辅助分类器得到输出,,然后利用双线性插值还原到原图尺度上,将结果保存result字典中,对应result中键值为aux的值中, 最后返回result结果
以上就是构建deeplabv3的过程,利用同样的办法你也能够去搭建deeplabv3_resnet101以及我们的deeplabv3_mobilenet_v3_large, 在deeplabv3_mobilenet_v3_large构建backbone的方式和本博文讲的方式有点不一样,这部分参见 lraspp博客。
参考:
- 太阳花小绿豆博客: DeepLabV3网络简析
文章出处登录后可见!