计算机二级python真题
文章目录
- 计算机二级python真题
- 一、简单应用题 1
- 二、简单应用题 2
- 三、综合应用题 1
- 四、综合应用题2

一、简单应用题 1
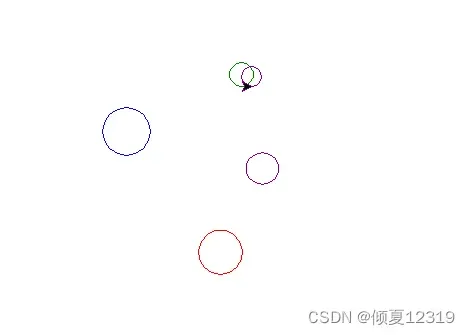
五个彩色圈圈
请参考编程,编写代码替换横线内容,不得修改其他代码,实现下面功能。
(1)使用turtle库和random库,在屏幕上绘制5个彩色的圆;
(2)圆的颜色随机从颜色列表color中获取;
(3)圆的圆心坐标x和y值从范围[-100, 100]之间选取,半径从范围[10,30]之间选取。效果如下图所示。
代码:
import turtle as t
import random as r
color = ['red','green','blue','purple','black']
r.seed(1)
for j in range(
5
):
t.pencolor(color[r.randint(0,4)])
t.penup()
t.goto(r.randint(-100,100),r.randint(-100,100))
t. pendown()
t.circle(r.randint(10,30))
t.done()
二、简单应用题 2
中文分词
请编写代码替换省略号,可修改其他代码,实现下面功能:
(1)获取用户输入的一段文本,包含但不限于中文字符、中文标点符号及其他字符;
(2)用jieba的精确模式分词,统计分词后中文词语词频,具体为:将字符长度大于等于2的词语及其词频写入文件data. txt,每行-一个词语,词语和词频之间用中文冒号分隔。
示例如下(其中数据仅用于示意):
输入:
借助平台优势,宣传推广相应产品,并为技术从业者提供更多学习、交流、探讨的机会,从而促进技术交流、企业互通、人才培养,促进技术的发展。
输出:
借助:1
平台:1
优势:1
宣传:1
推广:1
相应:1
产品:1
技术:3
从业者:1
提供:1
学习:1
交流:2
探讨:1
机会:1
从而:1
促进:2
企业:1
互通:1
人才培养:1
发展:1
…(略)
代码:
import jieba
s = input("请输入一个中文字符串,包含逗号和句号:") #请输入一个中文字符串,包含逗号和句号:
k = jieba.lcut(s) #使用jieba库的精确分词模式
dict1 = {} #定义空字典dict1
for i in k: #构建词与词频键值对存放在字典dict1中
dict1[i] = dict1.get(i, 0) + 1 #字典的get函数
with open('data.txt', 'w') as f: #使用with语句处理文件时,无论是否抛出异常,都能保证with语句执行完毕后关闭已经打开的文件
list1 = []
for k,v in dict1.items(): #筛选键值字符串长度大于等于2的键值对存放到list1列表中
if len(k)>=2:
list1.append(k + ':' + str(v))
for item in list1: #将列表元素逐行写入data.txt文件
f.write(item +'\n') #'\n'表示换行
三、综合应用题 1
价值链
附件中有素材文件 data3.txt,文件内容示例如下:
商业模式价值链由三个环节组成产品、工具、社区。我们团队以一站式系统开发为当前主要产品,利用XAMPP,PHPSTORM,微信开发者工具等软件根据客户要求提供合适的一体化管理系统。
… (略)
请编程实现如下功能:
(1)统计文件中出现词频最多的前10个长度不小于2个字符的词语,将词语及其出现的词频数按照词频数递减排序后显示在屏幕上,每行显示一个词语,用英文冒号连接词语及其词频。
示例如下:
我们:5
系统:3
微信:3
……(略)
代码:
import jieba
dict_words = {}
with open('data3.txt', 'r', encoding='GBK') as f:
lines = f.read().split("\n")
for line in lines:
words = jieba.lcut(line)
for word in words:
if len(word)>=2:
dict_words[word] = dict_words.get(word,0)+1
ls = list(dict_words.items())
ls.sort(key=lambda x:x[1], reverse = True)
for i in range(10):
print("{}:{}".format(ls[i][0],ls[i][1]))
代码:
import jieba
dict_words = {}
with open('data3.txt', 'r', encoding='GBK') as f:
k = jieba.cut(f.read())
for i in k:
if len(i) >= 2:
dict_words[i] = dict_words.get(i, 0) + 1
data = sorted(dict_words.items(), key=lambda x:x[1], reverse=True)
print(''.join([k + ':' + str(v) +'\n' for k, v in data[:10]]))
四、综合应用题2
价值链
编程实现如下功能:
(2)将文档以中文逗号及中文句号为分隔符分割成短句,将包含最高词频的词语的句子,输出到文件out. txt中,每句一行,示例如下:
以此为我们吸引更多的商机
同时普及我们的一站式开发技术
…(略)
代码:
import jieba
import re
dict_words = {}
with open('data3.txt', 'r', encoding='GBK') as f:
senses = re.sub('([,。\n])', '|' , f.read())
k = jieba.cut(senses)
for i in k:
if len(i) >= 2:
dict_words[i] = dict_words.get(i, 0) + 1
data = sorted(dict_words.items(), key=lambda x:x[1], reverse=True)
with open('out.txt', 'w') as f:
for sense in senses.split('|'):
if data[0][0] in sense:
f.write(sense+ '\n')
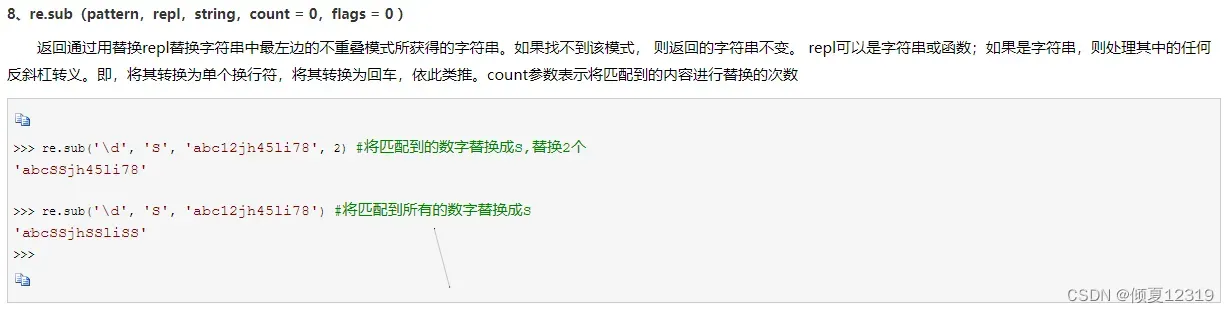
Python re模块:https://www.cnblogs.com/shenjianping/p/11647473.html
文章出处登录后可见!