项目需要coco格式的数据集但是自己的数据集是VOC格式的该如何转换呢。
VOC格式

coco格式:
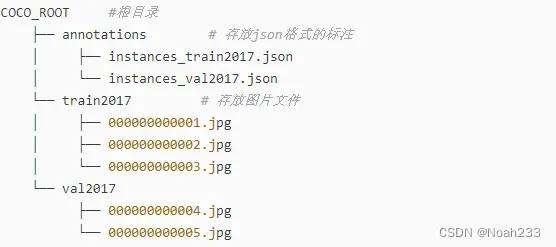
因为VOC格式的数据集中图片是放在一个文件下的,所以需要先划分训练集、验证集和测试集的比例,需要改两行文件路径和划分比例
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='F:\dataset\VOCWSODD\Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='F:\dataset\VOCWSODD\ImageSets\Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.8 # 训练+验证集一共所占的比例为0.8(注意看清楚),剩下的0.2就是测试集
train_percent = 0.8 # 训练集在训练集和验证集总集合中占的比例(注意看清楚是谁占谁的比例),可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
然后 根据划分的三个TXT文件将VOC的xml转为COCO的JSON,需要改最开始自己数据集中的类别和最后三行文件路径
import sys
import os
import json
import xml.etree.ElementTree as ET
START_BOUNDING_BOX_ID = 0
PRE_DEFINE_CATEGORIES = {"ship": 0, "harbor": 1, "boat": 2, "bridge": 3,
"rock": 4, "ball": 5, "platform": 6, "tree": 7,
"grass": 8, "person": 9, "rubbish": 10, "animal": 11,
"buoy": 12, "mast": 13} # 修改的地方,修改为自己的类别
# If necessary, pre-define category and its id
# PRE_DEFINE_CATEGORIES = {"aeroplane": 1, "bicycle": 2, "bird": 3, "boat": 4,
# "bottle":5, "bus": 6, "car": 7, "cat": 8, "chair": 9,
# "cow": 10, "diningtable": 11, "dog": 12, "horse": 13,
# "motorbike": 14, "person": 15, "pottedplant": 16,
# "sheep": 17, "sofa": 18, "train": 19, "tvmonitor": 20}
def get(root, name):
vars = root.findall(name)
return vars
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise NotImplementedError('Can not find %s in %s.' % (name, root.tag))
if length > 0 and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.' % (name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def get_filename_as_int(filename):
try:
filename = os.path.splitext(filename)[0]
return filename
except:
raise NotImplementedError('Filename %s is supposed to be an integer.' % (filename))
# xml_list为xml文件存放的txt文件名 xml_dir为真实xml的存放路径 json_file为存放的json路径
def convert(xml_list, xml_dir, json_file):
list_fp = open(xml_list, 'r')
json_dict = {"images": [], "type": "instances", "annotations": [],
"categories": []}
categories = PRE_DEFINE_CATEGORIES
bnd_id = START_BOUNDING_BOX_ID
for line in list_fp:
line = line.strip()
line = line + ".xml"
print("Processing %s" % (line))
xml_f = os.path.join(xml_dir, line)
tree = ET.parse(xml_f)
root = tree.getroot()
path = get(root, 'path')
if len(path) == 1:
filename = os.path.basename(path[0].text)
elif len(path) == 0:
filename = get_and_check(root, 'filename', 1).text
else:
raise NotImplementedError('%d paths found in %s' % (len(path), line))
## The filename must be a number
image_id = get_filename_as_int(filename)
size = get_and_check(root, 'size', 1)
width = int(get_and_check(size, 'width', 1).text)
height = int(get_and_check(size, 'height', 1).text)
image = {'file_name': filename, 'height': height, 'width': width,
'id': image_id}
json_dict['images'].append(image)
## Cruuently we do not support segmentation
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, 'object'):
category = get_and_check(obj, 'name', 1).text
if category not in categories:
new_id = len(categories)
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, 'bndbox', 1)
xmin = int(get_and_check(bndbox, 'xmin', 1).text) - 1
ymin = int(get_and_check(bndbox, 'ymin', 1).text) - 1
xmax = int(get_and_check(bndbox, 'xmax', 1).text)
ymax = int(get_and_check(bndbox, 'ymax', 1).text)
assert (xmax > xmin)
assert (ymax > ymin)
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id':
image_id, 'bbox': [xmin, ymin, o_width, o_height],
'category_id': category_id, 'id': bnd_id, 'ignore': 0,
'segmentation': []}
json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {'supercategory': 'none', 'id': cid, 'name': cate}
json_dict['categories'].append(cat)
json_fp = open(json_file, 'w')
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
list_fp.close()
if __name__ == '__main__':
# xml_list为xml文件存放的txt文件名 xml_dir为真实xml的存放路径 json_file为存放的json路径
xml_list = 'F:\dataset\VOCWSODD\ImageSets\Main\\test.txt'
xml_dir = 'F:\dataset\VOCWSODD\Annotations'
json_dir = 'F:\dataset\cocoU\\test.json' # 注意!!!这里test.json先要自己创建,不然 #程序回报权限不足
convert(xml_list, xml_dir, json_dir)最后对图片进行拷贝,训练集、验证集和测试集的图片添加到不同的目录下(和COCO数据集格式一致),只需要改前三行
import os
import shutil
images_file_path = 'F:\dataset\VOCWSODD\JPEGImages\\' #VOC数据中图片所在文件夹
split_data_file_path = 'F:\dataset\VOCWSODD\ImageSets\Main\\' #前面三个.txt文件所在文件夹
new_images_file_path = 'F:\dataset\cocoU\\' #图片输出文件夹
if not os.path.exists(new_images_file_path + 'train'):
os.makedirs(new_images_file_path + 'train')
if not os.path.exists(new_images_file_path + 'val'):
os.makedirs(new_images_file_path + 'val')
if not os.path.exists(new_images_file_path + 'test'):
os.makedirs(new_images_file_path + 'test')
dst_train_Image = new_images_file_path + 'train/'
dst_val_Image = new_images_file_path + 'val/'
dst_test_Image = new_images_file_path + 'test/'
total_txt = os.listdir(split_data_file_path)
for i in total_txt:
name = i[:-4]
if name == 'train':
txt_file = open(split_data_file_path + i, 'r')
for line in txt_file:
line = line.strip('\n')
line = line.strip('\r')
srcImage = images_file_path + line + '.jpg'
dstImage = dst_train_Image + line + '.jpg'
shutil.copyfile(srcImage, dstImage)
txt_file.close()
elif name == 'val':
txt_file = open(split_data_file_path + i, 'r')
for line in txt_file:
line = line.strip('\n')
line = line.strip('\r')
srcImage = images_file_path + line + '.jpg'
dstImage = dst_val_Image + line + '.jpg'
shutil.copyfile(srcImage, dstImage)
txt_file.close()
elif name == 'test':
txt_file = open(split_data_file_path + i, 'r')
for line in txt_file:
line = line.strip('\n')
line = line.strip('\r')
srcImage = images_file_path + line + '.jpg'
dstImage = dst_test_Image + line + '.jpg'
shutil.copyfile(srcImage, dstImage)
txt_file.close()
else:
print("Error, Please check the file name of folder")
注意文件路径一定要配置对,如果遇到\t这类的需要再加一个\变为\\t,否则路径会报错
文章出处登录后可见!
已经登录?立即刷新