python算法比赛常用模块
1.math 库:
提供数学相关的函数,如三角函数、指数函数、对数函数等。
常用函数:math.sqrt()、math.pow()、math.sin()、math.cos()、math.tan()、math.exp()、math.log() 等。
math模块提供了各种数学函数和常数的实现。下面列举一些常用的函数和常数:
- 数学常数
math.e:自然常数 e 的值,约等于 2.71828。
math.pi:圆周率 π 的值,约等于 3.14159。
- 常用数学函数
math.sqrt(x):返回 x 的平方根。
math.pow(x, y):返回 x 的 y 次方。
math.exp(x):返回 e 的 x 次方。
math.log(x, base=math.e):返回 x 的对数。base 参数为对数的底数,默认为自然对数 e。
math.sin(x)、math.cos(x)、math.tan(x):返回 x 的正弦、余弦和正切值。
math.asin(x)、math.acos(x)、math.atan(x):返回 x 的反正弦、反余弦和反正切值。
- 数值运算函数
math.ceil(x):返回不小于 x 的最小整数。
math.floor(x):返回不大于 x 的最大整数。
math.trunc(x):返回 x 的整数部分。
math.modf(x):返回 x 的小数部分和整数部分,以元组形式返回。
math.fabs(x):返回 x 的绝对值。
math.factorial(x):返回 x 的阶乘。
math.gcd(a, b):返回 a 和 b 的最大公约数。
- 特殊函数
math.erf(x)、math.erfc(x):返回 x 的误差函数和余误差函数的值。
math.gamma(x)、math.lgamma(x):返回 x 的伽马函数和它的自然对数。
除了以上列出的函数和常数,math模块还提供了很多其他有用的函数。在蓝桥杯Python组考试中,如果需要进行一些数学运算或计算,math模块是一个非常有用的工具。
2.random 库:
提供随机数相关的函数,如生成随机整数、随机浮点数、随机序列等。
常用函数:random.randint()、random.uniform()、random.choice()、random.shuffle() 等。
-
random.random(): 返回随机生成的一个浮点数,范围在[0,1)之间
-
random.uniform(a, b): 返回随机生成的一个浮点数,范围在[a, b)之间
-
random.randint(a,b):生成指定范围内的整数
-
random.randrange([start],stop[,step]):用于从指定范围内按指定基数递增的集合中获取一个随机数。
-
random.choice():从指定的序列中获取一个随机元素
-
random.shuffle(x[,random]):用于将一个列表中的元素打乱,随机排序
-
random.sample(sequence,k):用于从指定序列中随机获取指定长度的片段,sample()函数不会修改原有序列。
-
np.random.rand(d0, d1, …, dn): 返回一个或一组浮点数,范围在[0, 1)之间
-
np.random.normal(loc=a, scale=b, size=()): 返回满足条件为均值=a, 标准差=b的正态分布(高斯分布)的概率密度随机数
10 np.random.randn(d0, d1, … dn): 返回标准正态分布(均值=0,标准差=1)的概率密度随机数
-
np.random.standard_normal(size=()): 返回标准正态分布(均值=0,标准差=1)的概率密度随机数
-
np.random.randint(a, b, size=(), dtype=int): 返回在范围在[a, b)中的随机整数(含有重复值)
-
random.seed(): 设定随机种子
3.datetime 库:
提供日期和时间相关的函数,如获取当前日期、时间差计算、日期格式化等。
常用函数:datetime.datetime.now()、datetime.timedelta()、datetime.datetime.strftime() 等。
开始之前,需要说明一下,datetime 模块是 Python 中的时间处理模块,它有一个和它同名的 datetime 类,如果导入库的时候,用 import datetime,表明只导入了 datetime 模块,后续调用属性和方法时,都需要使用datetime.datetime 申明是调用的是 datetime 类;如果导入时使用 from datetime import datetime 语句,则表明已经从 datetime 模块中导入了 datetime 类, 后续调用属性和方法时,直接 datetime. 就可以使用
1.初识 datetime
# 导入 datetime 库的 datetime 类
from datetime import datetime
# 获取现在时间
datetime.now()
print('当前时间为:',datetime.now())
# 输出
datetime.datetime(2021, 6, 15, 12, 40, 29, 840272)
当前时间为: 2021-06-15 12:41:12.350532
# 创建指定时间
a = datetime(2030,10,16,10,16)
print(a)
# 输出
2030-10-16 10:16:00
2.str 转 datetime
实际工作中会经常遇到时间字段格式是 str 的情况,如果涉及到提取 day、hour 以及计算的问题,就需要将 str 转成 datetime,原因是 str 格式的时间是无法直接完成上述操作的。datetime 提供了 strptime() 方法将 str 转为 datetime
b = '20210506'
c = '2021-06-14 10:15:55'
d = datetime.strptime(b,'%Y%m%d')
e = datetime.strptime(c,'%Y-%m-%d %H:%M:%S')
print(d)
print(e)
type(d)
type(e)
print(d.year)
print(e.month)
# 输出
2021-05-06 00:00:00
2021-06-14 10:15:55
datetime.datetime
2021
6
这样就将 str 格式的时间转为了 datetime,取出年和月,日,小时,分钟这些也都可以提取,看你自己需求。需要注意的是 b 的格式是’20210506’,年月日之间无’-‘,所以转 datetime 时,也不能加’-‘,格式要匹配,否则会报 ValueError ,如下:
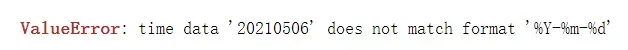
3.datetime 转 str
datetime 模块提供了 strftime() 方法将 datetime 转为 str,可以用 type 函数来看是否转换成功,输出 str,证明已经将 datetime 格式转换为了 str
today = datetime.now()
print(today.strftime('%Y-%m-%d %H:%M:%S'))
print(today.strftime('%Y-%m-%d'))
type(today.strftime('%Y-%m-%d %H:%M:%S'))
# 输出
2021-06-15 14:37:47
2021-06-15
str
4.时间计算
from datetime import datetime,timedelta # 导入时间计算库
today = datetime.now()
time1= datetime(2021,1,1,10,10)
print(today-time1)
print((today-time1).days) # 两个时间相减取天数
print((today-time1).seconds) # 两个时间相减取秒数
print(today-timedelta(days=30)) # 当前时间30天之前的时间
print(today-timedelta(hours=10)) # 当前时间10小时之前的时间
# 输出
165 days, 4:41:13.968424
165
16873
2021-05-16 14:51:13.968424
2021-06-15 04:51:13.968424
datetime 格式的时间之间才能计算,还有,需要注意的是,两个时间相减后,只有取相隔天数 days 和 seconds 的方法,没有 hours 和 months,minutes 方法,会报错,如下:

5.datetime 转 date
# 一句代码
today = datetime.now()
print(datetime.date(today))
type(datetime.date(today))
# 输出
2021-06-15
datetime.date
6.初识时间戳
what 时间戳?
时间戳是指格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总秒数,通俗讲,时间戳是一份能够表示一份数据在一个特定时间点已经存在的完整的可验证的数据。
6.1 datetime 转时间戳
s=datetime.now()
d=s.timestamp()
print(d)
# 输出
1620642412.236521
6.2 时间戳转 datetime
f=datetime.fromtimestamp(d)
print(f)
# 输出
2021-05-10 18:26:52.236521
type(f)
# 格式是 datetime
datetime.datetime
6.3 时间戳转字符串
先将时间戳转成datetime,然后再将 datetime 转成字符串
datetime.strftime(datetime.fromtimestamp(d),'%Y-%m-%d %H:%M:%S')
# 输出
'2021-05-10 18:26:52'
6.4 字符串转时间戳
先将字符串转为 datetime ,然后转为时间戳
l='20231016'
f=datetime.strptime(l,'%Y%m%d')
d=f.timestamp()
print(d)
# 输出
1697385600.0
总结:datetime 相当于字符串和时间戳之间的桥梁,后两者无法之间转换,都需要先转换为 datetime,然后再从 datetime 转换。datetime 相当于 Python 中时间处理的中间核心地带,熟悉 datetime 常用的方法后,基本上可以应付日常工作中90%以上的时间处理需求。
4.os 库:
提供操作系统相关的函数,如文件和目录操作、进程管理等。
常用函数:os.getcwd()、os.listdir()、os.path.join()、os.path.exists()、os.system() 等。
文件和目录操作
os.getcwd():返回当前工作目录的字符串。os.listdir():返回指定路径下的文件和目录列表。如果没有指定路径,则返回当前目录下的列表。os.path.join(path1, path2, ...):将多个路径组件合并后返回,自动处理操作系统的文件路径分隔符。os.path.exists(path):检查指定路径的文件或目录是否存在。os.mkdir(path):创建一个新目录。os.rmdir(path):删除一个目录。os.rename(src, dst):重命名文件或目录。
进程管理
os.system(command):运行系统命令,这是一种创建进程的简单方式。os.startfile(path):在Windows中,用关联的应用程序打开一个文件。os.fork():在Unix和Linux中,用于创建子进程。
环境变量
os.environ:一个表示当前系统环境变量的字典。os.getenv(key):获取一个环境变量的值。
5.sys 库:
提供与 Python 解释器相关的函数和变量,如获取命令行参数、获取系统版本等。
常用函数:sys.argv[]、sys.version_info.major、sys.exit() 等。
6.re 库:
Python的re模块提供了一整套正则表达式相关的功能,用于高效地处理字符串。它可以进行复杂的模式匹配、检索、替换等操作。下面是re模块中一些常用函数和方法的扩展介绍以及示例代码。
常用函数
1. re.match(pattern, string[, flags])
这个函数尝试从字符串的开始进行匹配,如果开头部分不符合正则表达式,则返回None。当匹配成功时,返回一个匹配对象。
import re
# 匹配以'Hello'开始的字符串
match = re.match(r'Hello', 'Hello World!')
if match:
print("Match found:", match.group())
- re.search(pattern, string[, flags])
search方法在整个字符串中进行搜索,返回第一个成功的匹配对象。如果没有找到匹配项,则返回None。
# 在字符串中搜索第一个数字
search = re.search(r'\d+', 'User12345')
if search:
print("Found number:", search.group())
- re.findall(pattern, string[, flags])
这个方法找出字符串中所有符合正则表达式的部分,并以列表的形式返回这些匹配的字符串。
# 找出所有的数字
numbers = re.findall(r'\d+', 'User123 and User456')
print("Numbers found:", numbers)
- re.sub(pattern, repl, string[, count, flags])
sub方法用于替换字符串中符合正则表达式的部分。repl可以是字符串或一个函数。
# 替换字符串中的数字为'#'
replaced = re.sub(r'\d+', '#', 'User123, User456')
print("Replaced String:", replaced)
标志(Flags)
在re模块中,标志用于修改某些操作的行为。例如,re.IGNORECASE(或re.I)用于忽略大小写,re.DOTALL(或re.S)使.匹配任何字符,包括换行符等。
7.queue模块
如果需要使用更高级的队列和栈数据结构,可以使用Python标准库中的deque模块和queue模块,这两个模块提供了更多功能和性能更好的队列和栈实现方式。例如,使用deque模块中的deque类可以轻松实现双端队列。使用queue模块中的Queue类可以轻松实现线程安全的队列。
queue模块提供了多种队列实现方式,包括先进先出队列(FIFO)、后进先出队列(LIFO)和优先级队列。队列实现是线程安全的,因此适用于多线程编程。
下面以先进先出队列(FIFO)为例,介绍一下queue模块的使用方法:
首先需要导入queue模块:
import queue
然后,创建一个FIFO队列对象:
q = queue.Queue()
此时,可以使用put()方法向队列中添加元素,使用get()方法从队列中获取元素:
q.put(1)
q.put(2)
q.put(3)
print(q.get()) # 输出1
print(q.get()) # 输出2
注意,队列中元素的顺序是先进先出的,即第一个放入队列的元素会被第一个取出。如果队列为空,get()方法会阻塞,直到队列中有元素可取。
除了Queue类之外,queue模块还提供了LifoQueue类和PriorityQueue类,分别对应后进先出队列和优先级队列。它们的使用方法类似,只需要将Queue替换成相应的类名即可。
如果需要实现线程安全的队列,可以使用queue模块中的Queue类和LifoQueue类。如果需要实现线程安全的优先级队列,可以使用queue模块中的PriorityQueue类。
总之,queue模块提供了方便易用、线程安全的队列实现方式,对于蓝桥杯Python组考试来说是一个非常有用的工具。
8.itertools
itertools模块提供了一些用于操作迭代器的工具函数。这些工具函数可以帮助我们高效地处理大量数据,并且通常是在内存中进行操作,因此对于处理大型数据集非常有用。
以下是itertools模块中一些常用的函数:
- itertools.permutations()
此函数来生成一个序列的全排列。这个函数接受两个参数,第一个参数是需要排列的序列,第二个参数是排列的长度(可选,默认为序列的长度)。
下面是一个示例代码:
import itertools
生成1~3的全排列
for p in permutations:print(p)
输出结果:
(1, 2, 3)
(1, 3, 2)
(2, 1, 3)
(2, 3, 1)
(3, 1, 2)
(3, 2, 1)
以上代码中,我们使用itertools.permutations()函数生成了1~3的全排列,并使用for循环依次输出每个排列。如果想生成指定长度的排列,可以在第二个参数中指定排列的长度,如下所示:
import itertools# 生成1~3的2个元素排列permutations = itertools.permutations([1, 2, 3], 2)
for p in permutations:print(p)
输出结果:
(1, 2)
(1, 3)
(2, 1)
(2, 3)
(3, 1)
(3, 2)
以上代码中,我们生成了1~3的2个元素排列,并使用for循环依次输出每个排列。
- itertools.count(start=0, step=1)
这个函数返回一个无限迭代器,从 start 开始,以 step 为步长不断地生成整数。可以使用 itertools.islice() 函数来控制生成的元素个数。 - itertools.cycle(iterable)
这个函数接受一个可迭代对象作为参数,并不断重复生成该对象中的元素。可以使用 itertools.islice() 函数来控制生成的元素个数。 - itertools.repeat(object, times=None)
这个函数返回一个无限迭代器,不断重复生成指定的对象。如果指定了 times 参数,则迭代指定的次数。 - itertools.chain(*iterables)
这个函数接受一些可迭代对象作为参数,返回一个迭代器,依次将它们中的元素连接在一起。 - itertools.compress(data, selectors)
这个函数接受两个可迭代对象作为参数,data 和 selectors。它返回一个迭代器,依次返回 data 中与 selectors 中对应位置为 True 的元素。 - itertools.filterfalse(function or None, iterable)
这个函数接受一个函数和一个可迭代对象作为参数,返回一个迭代器,依次返回 iterable 中不满足函数 function 的元素。 - itertools.groupby(iterable, key=None)
这个函数接受一个可迭代对象和一个 key 函数作为参数,返回一个迭代器,将 iterable 中的元素按照 key 函数的结果进行分组。 - itertools.product(*iterables, repeat=1)
这个函数接受一些可迭代对象作为参数,返回一个迭代器,依次返回它们中的元素的笛卡尔积。 - itertools.permutations(iterable, r=None)
这个函数接受一个可迭代对象和一个整数 r 作为参数,返回一个迭代器,依次返回它们中的元素的 r 元排列。 - itertools.combinations(iterable, r)
这个函数接受一个可迭代对象和一个整数 r 作为参数,返回一个迭代器,依次返回它们中的元素的 r 元组合。
9.zip_longest
在Python中, zip() 函数和 zip_longest() 函数都是用于将多个可迭代对象中的元素进行配对。它们的作用是将多个可迭代对象中相同位置的元素打包成一个元组,并返回一个迭代器。
zip() 函数接受任意数量的可迭代对象作为参数,并返回一个迭代器,该迭代器生成一个元组,其中包含每个可迭代对象相同位置的元素。如果可迭代对象的长度不同, zip() 函数将以最短的可迭代对象为准进行迭代。
下面是 zip() 函数的示例:
numbers = [1, 2, 3]
letters = ['a', 'b', 'c']
result = zip(numbers, letters)
for item in result:
print(item)
输出:
(1, 'a')
(2, 'b')
(3, 'c')
zip_longest() 函数也类似于 zip() 函数,但是它会以最长的可迭代对象为准进行迭代,并使用 fillvalue 参数来填充长度不足的可迭代对象。
下面是 zip_longest() 函数的示例:
from itertools import zip_longest
numbers = [1, 2, 3]
letters = ['a', 'b']
result = zip_longest(numbers, letters, fillvalue='')
for item in result:
print(item)
输出:
(1, 'a')
(2, 'b')
(3, '')
总结来说, zip() 函数和 zip_longest() 函数都是用于将多个可迭代对象的元素进行配对。 zip() 函数以最短的可迭代对象为准进行迭代,而 zip_longest() 函数以最长的可迭代对象为准,并使用 fillvalue 参数填充长度不足的可迭代对象。
10.collections模块
一、模块概述
1、模块作用
官方说法: collections模块实现了特定目标的容器,以提供Python标准内建容器dict ,list , set , 和tuple的替代选择。
通俗说法: Python内置的数据类型和方法,collections模块在这些内置类型的基础提供了额外的高性能数据类型,比如基础的字典是不支持顺序的,collections模块的OrderedDict类构建的字典可以支持顺序,collections模块的这些扩展的类用处非常大,熟练掌握该模块,可以大大简化Python代码,提高Python代码逼格和效率,高手入门必备。
2、模块资料
关于该模块,官方的参考资料写的非常详细,也很有价值,大家可以参考
中文文档:https://docs.python.org/zh-cn/3/library/collections.html#module-collections
英文文档:https://docs.python.org/3/library/collections.html#module-collections
3、模块子类
用collections.__all__查看所有的子类,一共包含9个
import collections print(collections.all) [‘deque’, ‘defaultdict’, ‘namedtuple’, ‘UserDict’, ‘UserList’, ‘UserString’, ‘Counter’, ‘OrderedDict’, ‘ChainMap’]
这个模块实现了特定目标的容器,以提供Python标准内建容器dict , list , set , 和tuple 的替代选择。
| namedtuple() | 创建命名元组子类的工厂函数,生成可以使用名字来访问元素内容的tuple子类 |
|---|---|
| deque | 类似列表(list)的容器,实现了在两端快速添加(append)和弹出(pop) |
| ChainMap | 类似字典(dict)的容器类,将多个映射集合到一个视图里面 |
| Counter | 字典的子类,提供了可哈希对象的计数功能 |
| OrderedDict | 字典的子类,保存了他们被添加的顺序,有序字典 |
| defaultdict | 字典的子类,提供了一个工厂函数,为字典查询提供一个默认值 |
| UserDict | 封装了字典对象,简化了字典子类化 |
| UserList | 封装了列表对象,简化了列表子类化 |
| UserString | 封装了字符串对象,简化了字符串子类化(中文版翻译有误) |
二、计数器-Counter
1、基础介绍
一个计数器工具提供快速和方便的计数,Counter是一个dict的子类,用于计数可哈希对象。它是一个集合,元素像字典键(key)一样存储,它们的计数存储为值。计数可以是任何整数值,包括0和负数,Counter类有点像其他语言中的bags或multisets。简单说,就是可以统计计数,来几个例子看看就清楚了,比如
#计算top10的单词
from collections import Counter
import re
text = 'remove an existing key one level down remove an existing key one level down'
words = re.findall(r'\w+', text)
Counter(words).most_common(10) [('remove', 2),('an', 2),('existing', 2),('key', 2),('one', 2)('level', 2),('down', 2)] #计算列表中单词的个数*
cnt = Counter() for word in ['red', 'blue', 'red', 'green', 'blue', 'blue']: cnt[word] += 1 cnt Counter({'red': 2, 'blue': 3, 'green': 1})
*#上述这样计算有点嘛,下面的方法更简单,直接计算就行*
L = ['red', 'blue', 'red', 'green', 'blue', 'blue'] Counter(L) Counter({'red': 2, 'blue': 3, 'green': 1}
#元素从一个iterable 被计数或从其他的mapping (or counter)初始化:
from collections import Counter
#字符串计数
Counter('gallahad') Counter({'g': 1, 'a': 3, 'l': 2, 'h': 1, 'd': 1})
#字典计数
Counter({'red': 4, 'blue': 2}) Counter({'red': 4, 'blue': 2})
#是个啥玩意计数*
Counter(cats=4, dogs=8) Counter({'cats': 4, 'dogs': 8}) Counter(['red', 'blue', 'red', 'green', 'blue', 'blue']) Counter({'red': 2, 'blue': 3, 'green': 1})
计数器对象除了字典方法以外,还提供了三个其他的方法:
1、elements()
**描述:**返回一个迭代器,其中每个元素将重复出现计数值所指定次。 元素会按首次出现的顺序返回。 如果一个元素的计数值小于1,elements() 将会忽略它。
**语法:**elements( )
**参数:**无
c = Counter(a=4, b=2, c=0, d=-2) list(c.elements()) ['a', 'a', 'a', 'a', 'b', 'b'] sorted(c.elements()) ['a', 'a', 'a', 'a', 'b', 'b'] c = Counter(a=4, b=2, c=0, d=5) list(c.elements()) ['a', 'a', 'a', 'a', 'b', 'b', 'd', 'd', 'd', 'd', 'd']
most_common()
- 返回一个列表,包含n个最常见的元素及其出现次数,按常见程度由高到低排序。
- 如果n被省略或为None,
most_common()将返回计数器中的所有元素。 - 计数值相等的元素按首次出现的顺序排序。
- 常用于计算top词频。
Counter('abracadabra').most_common(3) # [('a', 5), ('b', 2), ('r', 2)] Counter('abracadabra').most_common(5) # [('a', 5), ('b', 2), ('r', 2), ('c', 1), ('d', 1)]
subtract()
从迭代对象或映射对象减去元素,类似dict.update()但用于减法。
输入和输出都可以是0或负数。
c = Counter(a=4, b=2, c=0, d=-2)
d = Counter(a=1, b=2, c=3, d=4)
c.subtract(d) # Counter({'a': 3, 'b': 0, 'c': -3, 'd': -6})
str0 = Counter('aabbccdde')
str0.subtract('abcd')
str0 # Counter({'a': 1, 'b': 1, 'c': 1, 'd': 1, 'e': 1})
- 字典方法
Counter对象支持常规字典方法,但有些方法工作方式不同。
fromkeys(iterable):未在Counter中实现。
update([iterable-or-mapping]):从迭代对象计数元素或从另一个映射对象添加。类似dict.update()但用于加法。
sum(c.values()) # total of all counts
c.clear() # reset all counts
list(c) # list unique elements
set(c) # convert to a set
dict(c) # convert to a regular dictionary
c.items() # convert to a list of (elem, cnt) pairs
c.most_common()[:-n-1:-1] # n least common elements
+c # remove zero and negative counts
- 数学操作
提供了几种数学操作来结合Counter对象,生产multisets(计数器中大于0的元素)。
支持加减法、交集和并集。
c = Counter(a=3, b=1)
d = Counter(a=1, b=2)
c + d # Counter({'a': 4, 'b': 3})
c - d # Counter({'a': 2})
c & d # Counter({'a': 1, 'b': 1})
c | d # Counter({'a': 3, 'b': 2})
+c # Counter({'a': 2})
-c # Counter({'b': 4})
- 文本相似度算法
计算两个字符串的相似度。
def str_sim(str_0, str_1, topn):
topn = int(topn)
collect0 = Counter(dict(Counter(str_0).most_common(topn)))
collect1 = Counter(dict(Counter(str_1).most_common(topn)))
jiao = collect0 & collect1
bing = collect0 | collect1
sim = float(sum(jiao.values())) / float(sum(bing.values()))
return sim
str_0 = '定位手机定位汽车定位GPS定位人定位位置查询'
str_1 = '导航定位手机定位汽车定位GPS定位人定位位置查询'
三、 有序字典-OrderedDict
有序词典就像常规词典一样,但有一些与排序操作相关的额外功能,popitem() 方法有不同的签名。它接受一个可选参数来指定弹出哪个元素。move_to_end() 方法,可以有效地将元素移动到任一端。
有序词典就像常规词典一样,但有一些与排序操作相关的额外功能。由于内置的 dict 类获得了记住插入顺序的能力(在 Python 3.7 中保证了这种新行为),它们变得不那么重要了。
一些与 dict 的不同仍然存在:
- 常规的 dict 被设计为非常擅长映射操作。 跟踪插入顺序是次要的。
- OrderedDict 旨在擅长重新排序操作。 空间效率、迭代速度和更新操作的性能是次要的。
- 算法上, OrderedDict 可以比 dict 更好地处理频繁的重新排序操作。 这使其适用于跟踪最近的访问(例如在 LRU cache 中)。
- 对于 OrderedDict ,相等操作检查匹配顺序。
- OrderedDict 类的 popitem() 方法有不同的签名。它接受一个可选参数来指定弹出哪个元素。
- OrderedDict 类有一个 move_to_end() 方法,可以有效地将元素移动到任一端。
- Python 3.8之前, dict 缺少 reversed() 方法。
| 传统字典方法 | OrderedDict方法 | 差异 |
|---|---|---|
| clear | clear | |
| copy | copy | |
| fromkeys | fromkeys | |
| get | get | |
| items | items | |
| keys | keys | |
| pop | pop | |
| popitem | popitem | OrderedDict 类的 popitem() 方法有不同的签名。它接受一个可选参数来指定弹出哪个元素。 |
| setdefault | setdefault | |
| update | update | |
| values | values | |
| move_to_end | 可以有效地将元素移动到任一端。 |
1、popitem
语法:popitem(last=True)
功能:有序字典的 popitem() 方法移除并返回一个 (key, value) 键值对。 如果 last 值为真,则按 LIFO 后进先出的顺序返回键值对,否则就按 FIFO 先进先出的顺序返回键值对。
from collections import OrderedDict d = OrderedDict.fromkeys(‘abcde’) d.popitem() (‘e’, None) d OrderedDict([(‘a’, None), (‘b’, None), (‘c’, None), (‘d’, None)]) #last=False时,弹出第一个 d = OrderedDict.fromkeys(‘abcde’) ‘’.join(d.keys()) ‘abcde’ d.popitem(last=False) ‘’.join(d.keys()) ‘bcde’
2、move_to_end
from collections import OrderedDict d = OrderedDict.fromkeys(‘abcde’) d.move_to_end(‘b’) ‘’.join(d.keys()) ‘acdeb’ d OrderedDict([(‘a’, None), (‘c’, None), (‘d’, None), (‘e’, None), (‘b’, None)]) d.move_to_end(‘b’, last=False) ‘’.join(d.keys()) ‘bacde’
3、reversed()
相对于通常的映射方法,有序字典还另外提供了逆序迭代的支持,通过reversed() 。
d = OrderedDict.fromkeys(‘abcde’) list(reversed(d)) [‘e’, ‘d’, ‘c’, ‘b’, ‘a’]
**四、**可命名元组-namedtuple
生成可以使用名字来访问元素内容的tuple子类,命名元组赋予每个位置一个含义,提供可读性和自文档性。它们可以用于任何普通元组,并添加了通过名字获取值的能力,通过索引值也是可以的。
1、参数介绍
namedtuple(typename,field_names,*,verbose=False, rename=False, module=None)
1)typename:该参数指定所创建的tuple子类的类名,相当于用户定义了一个新类。
2)field_names:该参数是一个字符串序列,如 [‘x’,‘y’]。此外,field_names 也可直接使用单个字符串代表所有字段名,多个字段名用空格、逗号隔开,如 ‘x y’ 或 ‘x,y’。任何有效的 Python 标识符都可作为字段名(不能以下画线开头)。有效的标识符可由字母、数字、下画线组成,但不能以数字、下面线开头,也不能是关键字(如 return、global、pass、raise 等)。
3)rename:如果将该参数设为 True,那么无效的字段名将会被自动替换为位置名。例如指定 [‘abc’,‘def’,‘ghi’,‘abc’],它将会被替换为 [‘abc’, ‘_1’,‘ghi’,‘_3’],这是因为 def 字段名是关键字,而 abc 字段名重复了。
4)verbose:如果该参数被设为 True,那么当该子类被创建后,该类定义就被立即打印出来。
5)module:如果设置了该参数,那么该类将位于该模块下,因此该自定义类的 module 属性将被设为该参数值。
2、应用案例
1)水族箱案例
Python元组是一个不可变的,或不可改变的,有序的元素序列。元组经常用来表示纵列数据;例如,一个CSV文件中的行数或一个SQL数据库中的行数。一个水族箱可以用一系列元组来记录它的鱼类的库存。
一个单独的鱼类元组:
![]()
这个元组由三个字符串元素组成。
虽然在某些方面很有用,但是这个元组并没有清楚地指明它的每个字段代表什么。实际上,元素0是一个名称,元素1是一个物种,元素2是一个饲养箱。
鱼类元组字段说明:
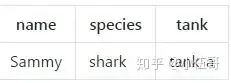
这个表清楚地表明,该元组的三个元素都有明确的含义。
来自collections模块的namedtuple允许你向一个元组的每个元素添加显式名称,以便在你的Python程序中明确这些元素的含义。
让我们使用namedtuple来生成一个类,从而明确地命名鱼类元组的每个元素:

from collections import namedtuple
可以让你的Python程序访问namedtuple工厂函数。namedtuple()函数调用会返回一个绑定到名称Fish的类。namedtuple()函数有两个参数:我们的新类“Fish”的期望名称和命名元素[“name”、“species”、“tank”]的一个列表。
我们可以使用Fish类来表示前面的鱼类元组:

如果我们运行这段代码,我们将看到以下输出:
![]()
sammy是使用Fish类进行实例化的。sammy是一个具有三个明确命名元素的元组。
sammy的字段可以通过它们的名称或者一个传统的元组索引来访问:

如果我们运行这两个print调用,我们将看到以下输出:

访问.species会返回与使用[1]访问sammy的第二个元素相同的值。
使用collections模块中的namedtuple可以在维护元组(即它们是不可变的、有序的)的重要属性的同时使你的程序更具可读性。
此外,namedtuple工厂函数还会向Fish实例添加几个额外的方法。
使用._asdict()将一个实例转换为字典:
![]()
如果我们运行print,你会看到如下输出:
![]()
在sammy上调用.asdict()将返回一个字典,该字典会将三个字段名称分别映射到它们对应的值。
大于3.8的Python版本输出这一行的方式可能略有不同。例如,你可能会看到一个OrderedDict,而不是这里显示的普通字典。
2)加法器案例
from collections import namedtuple # 定义命名元组类:Point Point = namedtuple(‘Point’, [‘x’, ‘y’]) # 初始化Point对象,即可用位置参数,也可用命名参数 p = Point(11, y=22) # 像普通元组一样用根据索引访问元素 print(p[0] + p[1]) 33 #执行元组解包,按元素的位置解包 a, b = p print(a, b) 11, 22 #根据字段名访问各元素 print(p.x + p.y) 33 print§ Point(x=11, y=22)
3、三个方法
备注: 在Python中,带有前导下划线的方法通常被认为是“私有的”。但是,namedtuple提供的其他方法(如._asdict()、._make()、._replace()等)是公开的。
除了继承元组的方法,命名元组还支持三个额外的方法和两个属性。为了防止字段名冲突,方法和属性以下划线开始。
_make(iterable)
类方法从存在的序列或迭代实例创建一个新实例。
t = [14, 55] Point._make(t)
_asdict()
返回一个新的 dict ,它将字段名称映射到它们对应的值:
p = Point(x=11, y=22) p._asdict() OrderedDict([(‘x’, 11), (‘y’, 22)])
*_replace(*kwargs)
返回一个新的命名元组实例,并将指定域替换为新的值
p = Point(x=11, y=22) p._replace(x=33) Point(x=33, y=22)
4、两个属性
_fields
字符串元组列出了字段名。用于提醒和从现有元组创建一个新的命名元组类型。
p._fields # view the field names (‘x’, ‘y’) Color = namedtuple(‘Color’, ‘red green blue’) Pixel = namedtuple(‘Pixel’, Point._fields + Color._fields) Pixel(11, 22, 128, 255, 0) Pixel(x=11, y=22, red=128, green=255, blue=0)
_field_defaults
字典将字段名称映射到默认值。
Account = namedtuple(‘Account’, [‘type’, ‘balance’], defaults=[0]) Account._field_defaults {‘balance’: 0} Account(‘premium’) Account(type=‘premium’, balance=0)
5、其他函数
getattr()
要获取这个名字域的值,使用 getattr() 函数 :
getattr(p, ‘x’) 11
转换一个字典到命名元组,使用 ** 两星操作符
d = {‘x’: 11, ‘y’: 22} Point(**d) Point(x=11, y=22)
因为一个命名元组是一个正常的Python类,它可以很容易的通过子类更改功能。这里是如何添加一个计算域和定宽输出打印格式:
class Point(namedtuple(‘Point’, [‘x’, ‘y’])): slots = () @property def hypot(self): return (self.x ** 2 + self.y ** 2) ** 0.5 def str(self): return ‘Point: x=%6.3f y=%6.3f hypot=%6.3f’ % (self.x, self.y, self.hypot) for p in Point(3, 4), Point(14, 5/7): print§ Point: x= 3.000 y= 4.000 hypot= 5.000 Point: x=14.000 y= 0.714 hypot=14.018
**五、**默认字典-defaultdict
在Python字典中收集数据通常是很有用的。
在字典中获取一个 key 有两种方法, 第一种 get , 第二种 通过 [] 获取.
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict。
当我使用普通的字典时,用法一般是dict={},添加元素的只需要dict[element] =value即,调用的时候也是如此,dict[element] = xxx,但前提是element字典里,如果不在字典里就会报错
这时defaultdict就能排上用场了,defaultdict的作用是在于,当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值,这个默认值是什么呢,下面会说
1、基础介绍
defaultdict([default_factory[, …]])
返回一个新的类似字典的对象。 defaultdict是内置dict类的子类。它重载了一个方法并添加了一个可写的实例变量。其余的功能与dict类相同,此处不再重复说明。
本对象包含一个名为default_factory的属性,构造时,第一个参数用于为该属性提供初始值,默认为 None。所有其他参数(包括关键字参数)都相当于传递给 dict 的构造函数。
defaultdict 对象除了支持标准 dict 的操作,还支持以下方法作为扩展:
missing(key)
如果 default_factory 属性为 None,则调用本方法会抛出 KeyError 异常,附带参数 key。
如果 default_factory 不为 None,则它会被(不带参数地)调用来为 key 提供一个默认值,这个值和 key 作为一对键值对被插入到字典中,并作为本方法的返回值返回。
如果调用 default_factory 时抛出了异常,这个异常会原封不动地向外层传递。
在无法找到所需键值时,本方法会被 dict 中的 getitem() 方法调用。无论本方法返回了值还是抛出了异常,都会被 getitem() 传递。
注意,missing() 不会 被 getitem() 以外的其他方法调用。意味着 get() 会像正常的 dict 那样返回 None,而不是使用 default_factory。
2、示例介绍
使用 list 作为 default_factory,很轻松地将(键-值对组成的)序列转换为(键-列表组成的)字典
s = [(‘yellow’, 1), (‘blue’, 2), (‘yellow’, 3), (‘blue’, 4), (‘red’, 1)] d = defaultdict(list) for k, v in s: d[k].append(v) sorted(d.items()) [(‘blue’, [2, 4]), (‘red’, [1]), (‘yellow’, [1, 3])]
当每个键第一次遇见时,它还没有在字典里面,所以自动创建该条目,即调用default_factory方法,返回一个空的 list。 list.append() 操作添加值到这个新的列表里。当再次存取该键时,就正常操作,list.append() 添加另一个值到列表中。这个计数比它的等价方法dict.setdefault()要快速和简单:
s = [(‘yellow’, 1), (‘blue’, 2), (‘yellow’, 3), (‘blue’, 4), (‘red’, 1)] d = {} for k, v in s: d.setdefault(k, []).append(v) sorted(d.items()) [(‘blue’, [2, 4]), (‘red’, [1]), (‘yellow’, [1, 3])]
设置 default_factory为int,使defaultdict用于计数(类似其他语言中的 bag或multiset):
s = ‘mississippi’ d = defaultdict(int) for k in s: d[k] += 1 sorted(d.items()) [(‘i’, 4), (‘m’, 1), (‘p’, 2), (‘s’, 4)]
设置 default_factory 为 set 使 defaultdict 用于构建 set 集合:
s = [(‘red’, 1), (‘blue’, 2), (‘red’, 3), (‘blue’, 4), (‘red’, 1), (‘blue’, 4)] d = defaultdict(set) for k, v in s: d[k].add(v) sorted(d.items()) [(‘blue’, {2, 4}), (‘red’, {1, 3})]
defaultdict绝不会引发一个KeyError。如果一个键不存在,defaultdict会插入并返回一个占位符值来代替:

如果我们运行这段代码,我们将看到如下输出:

defaultdict会插入并返回一个占位符值,而不是引发一个KeyError。在本例中,我们将占位符值指定为一个列表。
相比之下,常规字典会在缺失的键上引发一个KeyError:

如果我们运行这段代码,我们将看到如下输出:
当我们试图访问一个不存在的键时,常规字典my_regular_dict会引发一个KeyError。
defaultdict的行为与常规字典不同。defaultdict会不带任何参数调用占位符值来创建一个新对象,而不是在缺失的键上引发一个KeyError。在本例中,是调用list()创建一个空列表。
继续我们虚构的水族箱示例,假设我们有一个表示水族箱清单的鱼类元组列表:

水族箱中有三种鱼——它们的名字、种类和饲养箱在这三个元组中都有指出。
我们的目标是按饲养箱组织我们的清单—我们想知道每个饲养箱中存在的鱼的列表。换句话说,我们需要一个能将“tank-a”映射到[“Jamie”, “Mary”] ,并且将“tank-b”映射到[“Jamie”]的字典。
我们可以使用defaultdict来按饲养箱对鱼进行分组:

运行这段代码,我们将看到以下输出:
![]()
fish_names_by_tank被声明为一个defaultdict,它默认会插入list()而不是引发一个KeyError。由于这保证了fish_names_by_tank中的每个键都将指向一个list,所以我们可以自由地调用.append()来将名称添加到每个饲养箱的列表中。
这里,defaultdict帮助你减少了出现未预期的KeyErrors的机会。减少未预期的KeyErrors意味着你可以用更少的行更清晰地编写你的程序。更具体地说,defaultdict习惯用法让你避免了手动地为每个饲养箱实例化一个空列表。
如果没有 defaultdict, for循环体可能看起来更像这样:
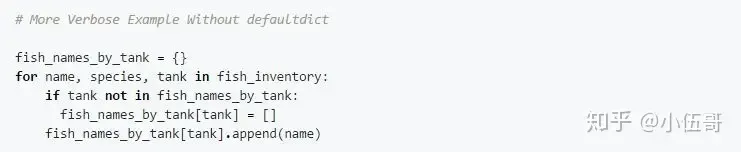
使用常规字典(而不是defaultdict)意味着for循环体总是必须检查fish_names_by_tank中给定的tank是否存在。只有在验证了fish_names_by_tank中已经存在tank,或者已经使用一个[]初始化了tank之后,我们才可以添加鱼类名称。
在填充字典时,defaultdict可以帮助我们减少样板代码,因为它从不引发KeyError。
六、映射链-ChainMap
1、ChainMap是什么
ChainMap最基本的使用,可以用来合并两个或者更多个字典,当查询的时候,从前往后依次查询。
ChainMap:将多个字典视为一个,解锁Python超能力。
ChainMap是由Python标准库提供的一种数据结构,允许你将多个字典视为一个。换句话说:ChainMap是一个基于多dict的可更新的视图,它的行为就像一个普通的dict。
ChainMap类用于快速链接多个映射,以便将它们视为一个单元。它通常比创建新字典和多次调用update()快得多。
你以前可能从来没有听说过ChainMap,你可能会认为ChainMap的使用情况是非常特定的。坦率地说,你是对的。
我知道的用例包括:
- 通过多个字典搜索
- 提供链缺省值
- 经常计算字典子集的性能关键的应用程序
2、特性
1)找到一个就不找了:这个列表是按照第一次搜索到最后一次搜索的顺序组织的,搜索查询底层映射,直到一个键被找到。
2)更新原始映射:不同的是,写,更新和删除只操作第一个映射。
3)支持所有常用字典方法。
简而言之ChainMap:将多个字典视为一个,解锁Python超能力。
Python标准库中的集合模块包含许多为性能而设计的实用的数据结构。著名的包括命名元组或计数器。
今天,通过实例,我们来看看鲜为人知的ChainMap。通过浏览具体的示例,我希望给你一个提示,关于在更高级的Python工作中使用ChainMap将如何从中受益。
3、应用案例-基础案例
from collections import ChainMap baseline = {‘music’: ‘bach’, ‘art’: ‘rembrandt’} adjustments = {‘art’: ‘van gogh’, ‘opera’: ‘carmen’} ChainMap(adjustments, baseline) ChainMap({‘art’: ‘van gogh’, ‘opera’: ‘carmen’}, {‘music’: ‘bach’, ‘art’: ‘rembrandt’}) list(ChainMap(adjustments, baseline)) [‘music’, ‘art’, ‘opera’] #存在重复元素时,也不会去重 dcic1 = {‘label1’: ‘11’, ‘label2’: ‘22’} dcic2 = {‘label2’: ‘22’, ‘label3’: ‘33’} dcic3 = {‘label4’: ‘44’, ‘label5’: ‘55’} last = ChainMap(dcic1, dcic2,dcic3) last ChainMap({‘label1’: ‘11’, ‘label2’: ‘22’}, {‘label2’: ‘22’, ‘label3’: ‘33’}, {‘label4’: ‘44’, ‘label5’: ‘55’})
new_child()方法
用法:new_child(m=None)
返回一个新的ChainMap类,包含了一个新映射(map),后面跟随当前实例的全部映射map。如果m被指定,它就成为不同新的实例,就是在所有映射前加上 m,如果没有指定,就加上一个空字典,这样的话一个 d.new_child() 调用等价于ChainMap({}, *d.maps) 。这个方法用于创建子上下文,不改变任何父映射的值。
last.new_child(m={‘key_new’:888}) ChainMap({‘key_new’: 888}, {‘label1’: ‘11’, ‘label2’: ‘22’}, {‘label2’: ‘22’, ‘label3’: ‘33’}, {‘label4’: ‘44’, ‘label5’: ‘55’})
parents属性
属性返回一个新的ChainMap包含所有的当前实例的映射,除了第一个。这样可以在搜索的时候跳过第一个映射。使用的场景类似在 nested scopes 嵌套作用域中使用nonlocal关键词。用例也可以类比内建函数super() 。一个d.parents 的引用等价于ChainMap(*d.maps[1:]) 。 last.parents ChainMap({'label2': '22', 'label3': '33'}, {'label4': '44', 'label5': '55'})
4、应用案例-购物清单
作为使用ChainMap的第一个例子,让我们考虑一张购物清单。我们的清单可能包含玩具,电脑,甚至衣服。所有这些条目都有价格,所以我们将把我们的条目存储在名称价格映射中。
toys = {'Blocks':30,'Monopoly':20} computers = {'iMac':1000,'Chromebook':1000,'PC':400} clothing = {'Jeans':40,'T-shirt':10}
现在我们可以使用ChainMap在这些不同的集合上建立一个单一的视图:
from collections import ChainMap inventory = ChainMap(toys,computers,clothing)
这使得我们可以查询清单,就像它是一个单一的字典:
inventory['Monopoly'] 20 inventory['Jeans']40
正如官方文档所述,ChainMap支持所有常用的字典方法。我们可以使用.get()来搜索可能不存在的条目,或者使用 .pop()删除条目。
inventory.get('Blocks-1') None inventory.get('Chromebook') 1000 inventory.pop('Blocks') inventory ChainMap({'Monopoly': 20}, {'iMac': 1000, 'Chromebook': 1000, 'PC': 400}, {'Jeans': 40, 'T-shirt': 10})
如果我们现在把玩具添加到toys字典里,它也将在清单中可用。这是ChainMap的可更新的方面。
toys[‘Nintendo’] = 20 inventory[‘Nintendo’] = 20
Oh和ChainMap有一个恰当的字符串表示形式:
str(inventory) “ChainMap({‘Monopoly’: 20, ‘Nintendo’: 20}, {‘iMac’: 1000, ‘Chromebook’: 1000, ‘PC’: 400}, {‘Jeans’: 40, ‘T-shirt’: 10})”
一个很好的特点是,在我们的例子中,toys, computers和clothing都是在相同的上下文中(解释器),它们可以来自完全不同的模块或包。这是因为ChainMap通过引用存储底层字典。
第一个例子是使用ChainMap一次搜索多个字典。
事实上,当构建ChainMap时,我们所做的就是有效地构建一系列字典。当查找清单中的一个项时,toys首先被查找,然后是computers,最后是clothing。

ChainMap真的只是一个映射链!
实际上,ChainMap的另一个任务是维护链的默认值。
我们将以一个命令行应用程序的例子来说明这是什么意思。
5、应用案例-CLI配置
让我们面对现实,管理命令行应用程序的配置可能是困难的。配置来自多个源:命令行参数、环境变量、本地文件等。
我们通常实施优先级的概念:如果A和B都定义参数P,A的P值将被使用,因为它的优先级高于B。
例如,如果传递了命令行参数,我们可能希望在环境变量上使用命令行参数。如何轻松地管理配置源的优先级?
一个答案是将所有配置源存储在ChainMap中。
因为ChainMap中的查找是按顺序连续地对每个底层映射执行的(按照他们传给构造函数的顺序),所以我们可以很容易地实现我们寻找的优先级。
下面是一个简单的命令行应用程序。调试参数从命令行参数、环境变量或硬编码默认值中提取:
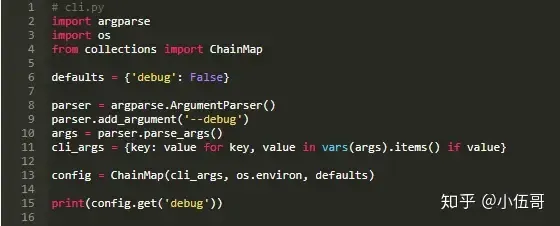
在执行脚本时,我们可以检查是否首先在命令行参数中查找debug,然后是环境变量,最后是默认值:
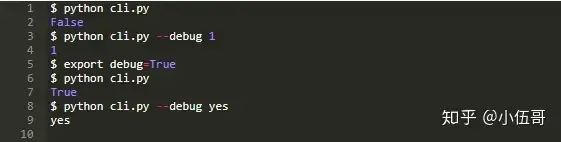
这样看上去就非常整洁,对吧?
6、我为什么关心?
坦率地说,ChainMap是那些你可以忽略的Python特性之一。
还有其他ChainMap的替代方案。例如,使用更新循环—例如创建一个dict并用字典update()它—可能奏效。但是,这只有在您不需要跟踪项目的起源时才有效,就像我们的多源CLI配置示例中的情况一样。但是,当你知道ChainMap存在的时候,ChainMap可以让你更轻松,你的代码更优雅。
7、总结
总而言之,我们一起看了ChainMap是什么,一些具体的使用示例,以及如何在现实生活中,性能关键的应用程序中使用ChainMap。如果您想了解更多关于Python的高性能数据容器的信息,请务必从Python的标准库中collections模块中查看其他出色类和函数。
七、UserDict
UserDict类是用作字典对象的外包装。对这个类的需求已部分由直接创建dict的子类的功能所替代;不过这个类处理起来更容易,因为底层的字典可以作为属性来访问。
模拟一个字典类。这个实例的内容保存为一个正常字典,可以通过UserDict实例的data属性存取。如果提供了initialdata 值, data 就被初始化为它的内容,注意一个 initialdata 的引用不会被保留作为其他用途。
UserDict 实例提供了以下属性作为扩展方法和操作的支持:data一个真实的字典,用于保存 UserDict 类的内容。
八、UserList
这个类封装了列表对象。它是一个有用的基础类,对于你想自定义的类似列表的类,可以继承和覆盖现有的方法,也可以添加新的方法。这样我们可以对列表添加新的行为。
对这个类的需求已部分由直接创建 list 的子类的功能所替代;不过,这个类处理起来更容易,因为底层的列表可以作为属性来访问。
模拟一个列表。这个实例的内容被保存为一个正常列表,通过 UserList 的 data 属性存取。实例内容被初始化为一个 list 的copy,默认为 [] 空列表。 list可以是迭代对象,比如一个Python列表,或者一个UserList 对象。
UserList 提供了以下属性作为可变序列的方法和操作的扩展:data
一个 list 对象用于存储 UserList 的内容。
子类化的要求: UserList 的子类需要提供一个构造器,可以无参数调用,或者一个参数调用。返回一个新序列的列表操作需要创建一个实现类的实例。它假定了构造器可以以一个参数进行调用,这个参数是一个序列对象,作为数据源。
如果一个分离的类不希望依照这个需求,所有的特殊方法就必须重写;请参照源代码进行修改。
九、UserString
UserString类是用作字符串对象的外包装。对这个类的需求已部分由直接创建str的子类的功能所替代,不过这个类处理起来更容易,因为底层的字符串可以作为属性来访问。
模拟一个字符串对象。这个实例对象的内容保存为一个正常字符串,通过UserString的data属性存取。实例内容初始化设置为seq的copy。seq 参数可以是任何可通过内建str()函数转换为字符串的对象。
UserString 提供了以下属性作为字符串方法和操作的额外支持:data一个真正的str对象用来存放 UserString 类的内容。
版权声明:本文为博主作者:第欧根尼的酒桶原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Iconicdusk/article/details/137011337