层次分析法(analytic hierarchy process),简称AHP。是建模比赛中比较基础的模型之一,其主要解决评价类的问题。如选择哪种方案最好,哪位员工表现最好等。
它是一个较为主观的评价方法,其在赋权得到权重向量的时候,主观因素占比很大。因而在建模比赛中,常常与客观方法得到的权重向量方法进行综合,而得出一个综合的权重向量。
目录
一、首先要思考以下三个问题
二、选择层次分析法解决问题
1.画层次结构图
2.构造判断矩阵
3.进行一致性检验
4.计算权重
方法1:算术平均法求权重
方法2:几何平均法求权重
方法3:特征值法求权重
5.填充权重矩阵计算得分并得出结果
三、层次分析法的一些局限性
四、层次分析法的代码实现
例题:小明同学想出去旅游。在查阅了网上的攻略后,他初步选择 了苏杭、北戴河和桂林三地之一作为目标景点。 请你确定评价指标、形成评价体系来为小明同学选择最佳的方案。
一、首先要思考以下三个问题
① 我们评价的目标是什么?
答:为小明同学选择最佳的旅游景点。
② 我们为了达到这个目标有哪几种可选的方案?
答:三种,分别是去苏杭、去北戴河和去桂林。
③ 评价的准则或者说指标是什么?(我们根据什么东西来评价好坏)
答:景色、花费、居住、饮食、交通。
一般而言,前两个问题的答案是显而易见的,第三个问题的答案需要我们根据题目中的背景材料、常识以及网上搜集到的参考资料进行结合,从中筛选出最合适的指标。(优先选择知网等搜索相关的文献,同时可以借鉴别人所用方法)。
二、选择层次分析法解决问题
1.画层次结构图
分析系统中各因素之间的关系,建立系统的递阶层次结构。

注:使用工具——亿图图示
2.构造判断矩阵
对于同一层次的个元素关于上一层次中某一准则的重要性两两比较,构造两两比较矩阵(判断矩阵)
①为什么要构造判断矩阵?
首先,我们先来看看层次分析法最终要得出的结果是什么样子的:

实际上的建模结果就是要填满权重矩阵,即这个表格:
- 蓝色一列代表景色、花费、居住、饮食以及交通的权重,加和为1。(实际上就是准则层关于上一层目标层的重要性)
- 同一颜色每一横行,就是三种方案相对于准则层的重要性。如:橙色一行代表的就是苏杭、北戴河以及桂林关于景色的权重,以此类推。
如何填满这个表格,就需要用判断矩阵得出,这也是构造判断矩阵的意义!
②要构造几个判断矩阵?
由上文可知得到这个判断矩阵实际上要分别得出准则层关于目标层的一组权重向量,方案层关于准则层的五组权重向量,实际上我们就需要构造出一个准则层关于目标层的判断矩阵以及五个方案层关于准则层的矩阵,一共六个判断矩阵。(这里采用分治的思想)最终在经过权重计算每组得出一组权重向量,填到相应的表格中。构造的6个判断矩阵如下:
③如何构造矩阵?
两两比较得出重要性填到矩阵中。重要程度如下表:
| 标度 | 含义 |
|---|---|
| 1 | 表示两个因素相比,具有同样重要性 |
| 3 | 表示两个因素相比,一个因素比另一个因素稍微重要 |
| 5 | 表示两个因素相比,一个因素比另一个因素明显重要 |
| 7 | 表示两个因素相比,一个因素比另一个因素强烈重要 |
| 9 | 表示两个因素相比,一个因素比另一个因素极端重要 |
| 2、4、6、8 | 上述两相邻判断的中值 |
| 倒数 | A和B相比如果标度为3,那么B和A相比就是1/3 |
根据以上这个表格,我们人为的进行填充,得到了下面这个判断矩阵:(实际情况下都是专家填的,但是比赛中大都是我们自己填的,最好有一些理论的依据支撑)
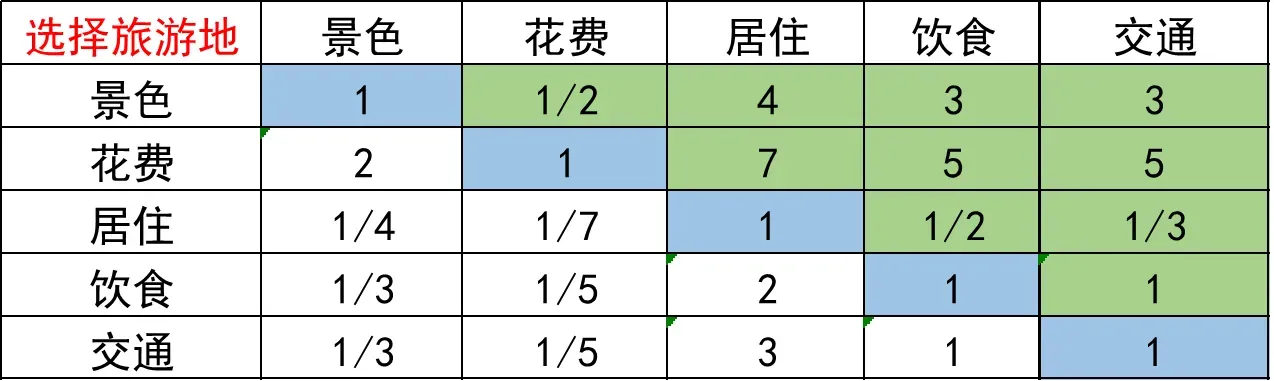
上面这个判断矩阵有如下特点:
- aij 表示的意义是,与指标j相比, i的重要程度。
- 当i= j时,两个指标相同,因此同等重要记为1,这就解释了主对角线元素为1
- aj >0 且满足 aij × aji = 1 (我们称满足这一条件的矩阵为正互反矩阵)
其余五个矩阵如下图:


3.进行一致性检验
①什么是一致性检验?
思考一个问题,拿方案层关于景色的矩阵说明,假设我们填写的判断矩阵是这个样子:
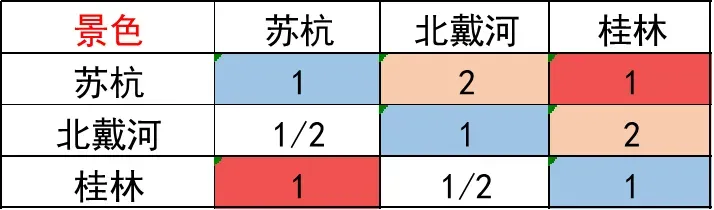
假设:苏杭 = A、北戴河 = B、桂林 = C,
那么由矩阵可以看出,苏杭比北戴河景色好一点 A > B,苏杭和桂林景色一样好 A = C,北戴河比桂林景色好一点 B > C,出现了 矛盾!
这里就不得不提出一个概念叫做 一致矩阵,它在正互反矩阵性质的基础上没有以上的矛盾,可以说:一致矩阵是正互反矩阵的特例。
将上面的矩阵进行改良,得到一致矩阵:

它比正互反矩阵多出两个性质:
- aij = i的重要程度 / j的重要程度,ajk = j的重要程度 / k的重要程度,aik = i的重要程度 / k的重要程度 = aij × ajk。
- 矩阵各行(各列)之间成倍数关系。
我们进行构造矩阵大多是正互反矩阵,难免会出现矛盾,即不容易构造出一致性矩阵,但是我们可以向一致性矩阵靠拢,只要这个差距(CR)不超过一个范围(0.1)那么这个判断矩阵也是可以使用的。这个判断差距的过程叫做 一致性检验。
②如何进行一致性检验?
第一步:计算一致性指标CI
![]()
第二步:查找对应的平均随机一致性指标 RI

注:在实际运用中,n很少超过10,如果指标的个数大于10,则可考虑建立二级指标体系,或使用其他模型。此外,RI 可以直接查表使用即可。
第三步:计算一致性比例CR
如果 CR < 0.1, 则可认为判断矩阵的一致性可以接受;否则需要对判断矩阵进行修正。
4.计算权重
计算权重的方法有三种:算数平均法求权重、几何平均法求权重和特征值法求权重。
一般情况下:第三种特征值法求权重是最常用的,但是建议可以综合三种方法来求得一个综合的权重向量。
下面拿下面这个判断矩阵进行说明:
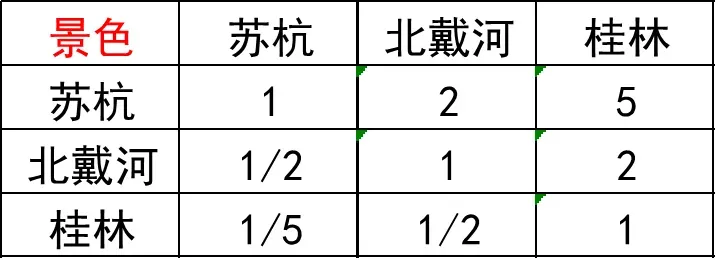
方法1:算术平均法求权重
第一步: 按列归一化
每个元素除以其所在列的和,如1/(1+0.5+0.2)=0.5882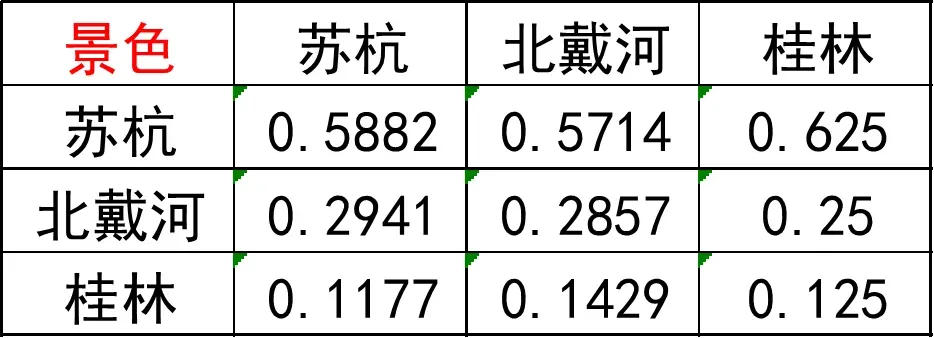
第二步: 按行求和
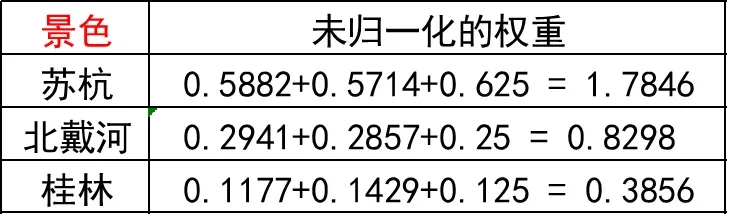
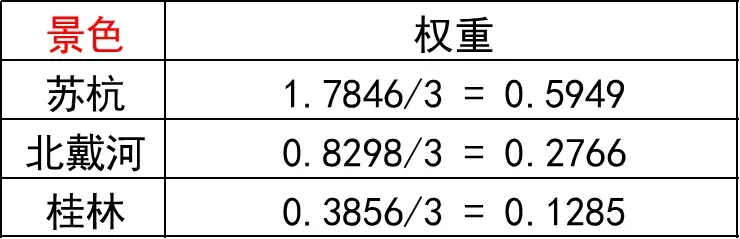
第三步: 归一化权重
将相加后得到的向量中的每个元素除以 n 即可得到权重向量。
表达式解释:

方法2:几何平均法求权重
第一步: 将A的元素按照行相乘得到一个新的列向量
第二步: 将新的向量的每个分量开n次方
第三步: 对该列向量进行归一化即可得到权重向量
表达式解释:

方法3:特征值法求权重
一致矩阵有一个特征值为 n,其余特征值均为 0。
另外,我们很容易可以得到,特征值为 n 时,对应的特征向量刚好为:
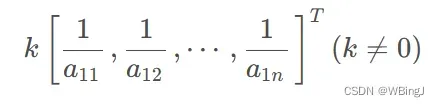
那么我们我们直接可以将特征向量归一化即可求得特征向量。
三种方法求得的权重向量的最终结果:
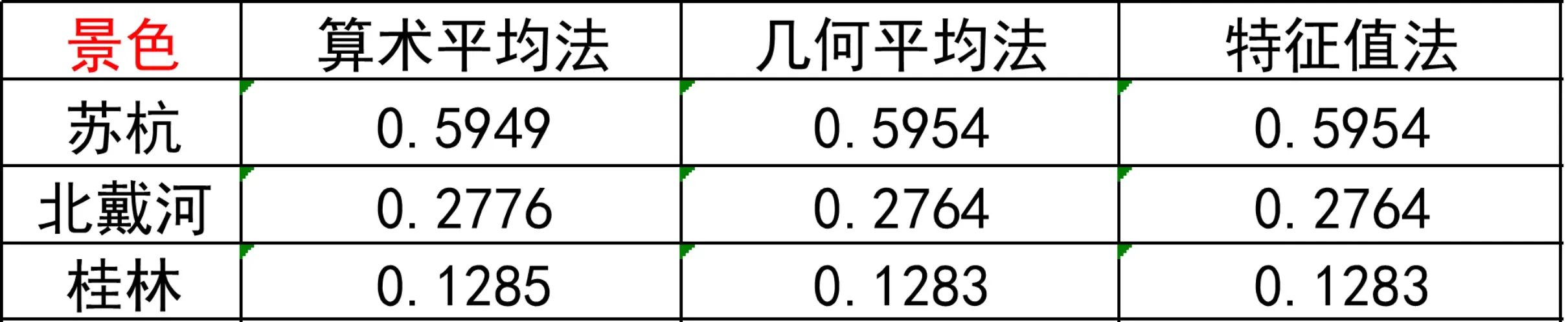
在实际建模中建议综合三种方法求得的权重得到一个综合的权重向量更具有说服力!
5.填充权重矩阵计算得分并得出结果
这里只拿第三种的结果填充权重矩阵:
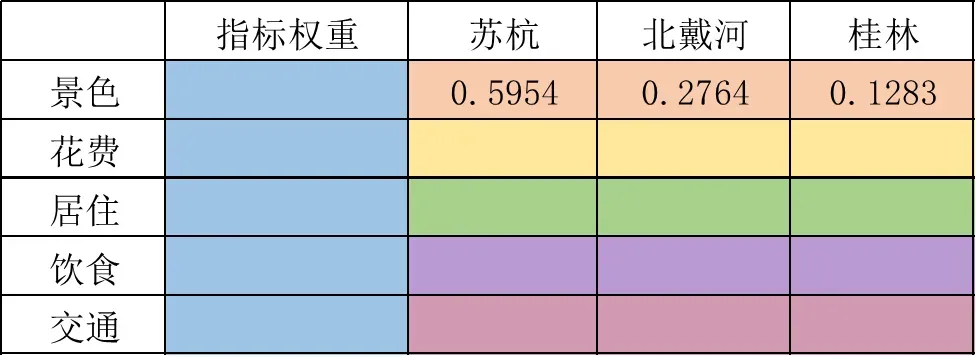
其余的矩阵以此类推,最终得到如下图所示的权重矩阵:

苏杭得分:指标权重×苏杭权重,即前两列相乘再相加:
0.5954×0.2636+0.0819×0.4758+0.4286×0.0538+0.6337×0.0981+0.1667×0.1087=0.299
同理:北戴河得分为0.245,桂林得分为0.455。
因此最佳的旅游景点是桂林。
注:使用Excel表计算得分非常方便。
三、层次分析法的一些局限性
-
评价的决策层不能太多,太多的话n会很大,判断矩阵和一致矩阵差异可能会很大。因为平均随机一致性指标 RI 的表格中 n 最多是15,因此应该根据实际情况选择是否应用此方法。
- 如果决策层中指标的数据是已知的,那么层次分析法不容易将这些已知数据应用在其中。如拿上面的例题举例:如果已知景色 、花费、居住、饮食以及交通在三个旅游景点的一些数据,那么如何将这些数据转化为构造判断矩阵的依据,只能为其提供一定的文字说明,而不容易将数据应用到其中。
- 在实际建模中,判断矩阵的数值都是人为填的,具有一定的主观性存在,这时应该搜寻相应的数据让人信服,不能空口无凭。
- 如果说只想拿到的决策因素的权重向量,那大可不必这么麻烦,在第一步递阶层次结构的时候,只需要目标层和准则层即可,构造判断矩阵也只需要构造出一个,并进行检验,检验通过了,差不多就拿到了权重向量。
四、层次分析法的代码实现
%% 注意:在论文写作中,应该先对判断矩阵进行一致性检验,然后再计算权重,因为只有判断矩阵通过了一致性检验,其权重才是有意义的。
%% 在下面的代码中,我们先计算了权重,然后再进行了一致性检验,这是为了顺应计算过程,事实上在逻辑上是说不过去的。
%% 因此大家自己写论文中如果用到了层次分析法,一定要先对判断矩阵进行一致性检验。
%% 而且要说明的是,只有非一致矩阵的判断矩阵才需要进行一致性检验。
%% 如果你的判断矩阵本身就是一个一致矩阵,那么就没有必要进行一致性检验。
%% 输入判断矩阵
clear;clc
disp('请输入判断矩阵A: ')
% A = input('判断矩阵A=')
A =[1 1 4 1/3 3;
1 1 4 1/3 3;
1/4 1/4 1 1/3 1/2;
3 3 3 1 3;
1/3 1/3 2 1/3 1]
% matlab矩阵有两种写法,可以直接写到一行:
% [1 1 4 1/3 3;1 1 4 1/3 3;1/4 1/4 1 1/3 1/2;3 3 3 1 3;1/3 1/3 2 1/3 1]
% 也可以写成多行:
[1 1 4 1/3 3;
1 1 4 1/3 3;
1/4 1/4 1 1/3 1/2;
3 3 3 1 3;
1/3 1/3 2 1/3 1]
% 两行之间以分号结尾(最后一行的分号可加可不加),同行元素之间以空格(或者逗号)分开。
%% 方法1:算术平均法求权重
% 第一步:将判断矩阵按照列归一化(每一个元素除以其所在列的和)
Sum_A = sum(A)
[n,n] = size(A) % 也可以写成n = size(A,1)
% 因为我们的判断矩阵A是一个方阵,所以这里的r和c相同,我们可以就用同一个字母n表示
SUM_A = repmat(Sum_A,n,1) %repeat matrix的缩写
% 另外一种替代的方法如下:
SUM_A = [];
for i = 1:n %循环哦,这一行后面不能加冒号(和Python不同),这里表示循环n次
SUM_A = [SUM_A; Sum_A]
end
clc;A
SUM_A
Stand_A = A ./ SUM_A
% 这里我们直接将两个矩阵对应的元素相除即可
% 第二步:将归一化的各列相加(按行求和)
sum(Stand_A,2)
% 第三步:将相加后得到的向量中每个元素除以n即可得到权重向量
disp('算术平均法求权重的结果为:');
disp(sum(Stand_A,2) / n)
% 首先对标准化后的矩阵按照行求和,得到一个列向量
% 然后再将这个列向量的每个元素同时除以n即可(注意这里也可以用./哦)
%% 方法2:几何平均法求权重
% 第一步:将A的元素按照行相乘得到一个新的列向量
clc;A
Prduct_A = prod(A,2)
% prod函数和sum函数类似,一个用于乘,一个用于加 dim = 2 维度是行
% 第二步:将新的向量的每个分量开n次方
Prduct_n_A = Prduct_A .^ (1/n)
% 这里对每个元素进行乘方操作,因此要加.号哦。 ^符号表示乘方哦 这里是开n次方,所以我们等价求1/n次方
% 第三步:对该列向量进行归一化即可得到权重向量
% 将这个列向量中的每一个元素除以这一个向量的和即可
disp('几何平均法求权重的结果为:');
disp(Prduct_n_A ./ sum(Prduct_n_A))
%% 方法3:特征值法求权重
% 第一步:求出矩阵A的最大特征值以及其对应的特征向量
clc
[V,D] = eig(A) %V是特征向量, D是由特征值构成的对角矩阵(除了对角线元素外,其余位置元素全为0)
Max_eig = max(max(D)) %也可以写成max(D(:))哦~
% 那么怎么找到最大特征值所在的位置了? 需要用到find函数,它可以用来返回向量或者矩阵中不为0的元素的位置索引。
% 那么问题来了,我们要得到最大特征值的位置,就需要将包含所有特征值的这个对角矩阵D中,不等于最大特征值的位置全变为0
% 这时候可以用到矩阵与常数的大小判断运算
D == Max_eig
[r,c] = find(D == Max_eig , 1)
% 找到D中第一个与最大特征值相等的元素的位置,记录它的行和列。
% 第二步:对求出的特征向量进行归一化即可得到我们的权重
V(:,c)
disp('特征值法求权重的结果为:');
disp( V(:,c) ./ sum(V(:,c)) )
% 我们先根据上面找到的最大特征值的列数c找到对应的特征向量,然后再进行标准化。
%% 计算一致性比例CR
clc
CI = (Max_eig - n) / (n-1);
RI=[0 0 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59]; %注意哦,这里的RI最多支持 n = 15
CR=CI/RI(n);
disp('一致性指标CI=');disp(CI);
disp('一致性比例CR=');disp(CR);
if CR<0.10
disp('因为CR < 0.10,所以该判断矩阵A的一致性可以接受!');
else
disp('注意:CR >= 0.10,因此该判断矩阵A需要进行修改!');
end
% % 注意:代码文件仅供参考,一定不要直接用于自己的数模论文中
% % 国赛对于论文的查重要求非常严格,代码雷同也算作抄袭
% % 如何修改代码避免查重的方法:https://www.bilibili.com/video/av59423231(必看)注:本文参考清风数学建模课程与CSDN博主「Xiu Yan」的文章,供个人参考学习。
版权声明:本文为博主作者:WBingJ原创文章,版权归属原作者,如果侵权,请联系我们删除!