例题一

解法: 算法思路:典型的回溯题⽬,我们需要在每⼀个位置上考虑所有的可能情况并且不能出现重复。通过深度优先搜索的⽅式,不断地枚举每个数在当前位置的可能性,并回溯到上⼀个状态,直到枚举完所有可能性,得到正确的结果。每个数是否可以放⼊当前位置,只需要判断这个数在之前是否出现即可。具体地,在这道题⽬中,我们可以通过⼀个递归函数 dfs 和标记数组 check来实现全排列。 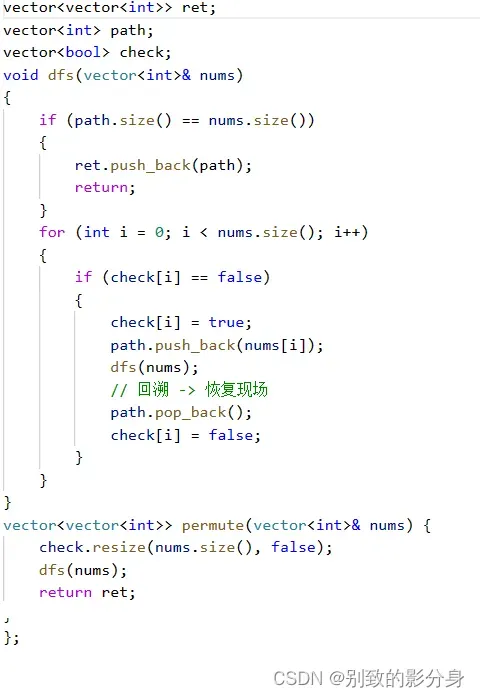
例题二

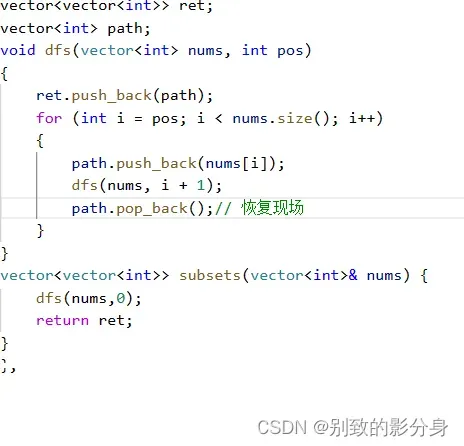
例题三

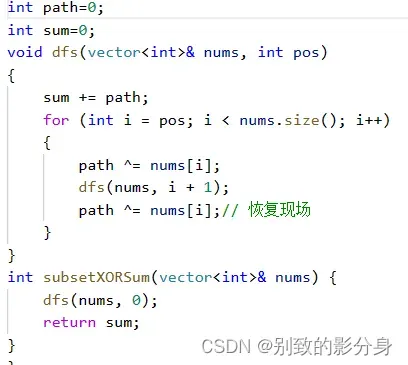
例题四

解法: 算法思路: 因为题⽬不要求返回的排列顺序,因此我们可以对初始状态排序,将所有相同的元素放在各⾃相邻的位置,⽅便之后操作。因为重复元素的存在,我们在选择元素进⾏全排列时,可能会存在重复排列,例如:[1, 2, 1],所有的 下标排列 为: 123 132 213 231 312 321 按照以上下标进⾏排列的结果为: 121 112 211 211 112 121 可以看到,有效排列只有三种[1, 1, 2],[1, 2, 1],[2, 1, 1],其中每个排列都出现两次。因此,我们需要对相同元素定义⼀种规则,使得其组成的排列不会形成重复的情况: 1. 我们可以将相同的元素按照排序后的下标顺序出现在排列中,通俗来讲,若元素 s 出现 x 次,则排序后的第 2 个元素 s ⼀定出现在第 1 个元素 s 后⾯,排序后的第 3 个元素 s ⼀定出现在第 2 个元素 s 后⾯,以此类推,此时的全排列⼀定不会出现重复结果。 2. 例如:a1=1,a2=1,a3=2,排列结果为 [1, 1, 2] 的情况只有⼀次,即 a1 在 a2 前⾯,因为 a2 不会出现在 a1 前⾯从⽽避免了重复排列。 3. 我们在每⼀个位置上考虑所有的可能情况并且不出现重复; 4. *注意*:若当前元素的前⼀个相同元素未出现在当前状态中,则当前元素也不能直接放⼊当前状态的数组,此做法可以保证相同元素的排列顺序与排序后的相同元素的顺序相同,即避免了重复排列出现。 5. 通过深度优先搜索的⽅式,不断地枚举每个数在当前位置的可能性,并在递归结束时回溯到上⼀个状态,直到枚举完所有可能性,得到正确的结果。 递归函数设计:void backtrack(vector<int>& nums, int pos) 参数:pos(当前需要填⼊的位置); 返回值:⽆; 函数作⽤:查找所有合理的排列并存储在答案列表中。 递归流程如下: 1. 定义⼀个⼆维数组 ret ⽤来存放所有可能的排列,⼀个⼀维数组 path ⽤来存放每个状态的排列,⼀个⼀维数组 check 标记元素,然后从第⼀个位置开始进⾏递归; 2. 在每个递归的状态中,我们维护⼀个步数 pos,表⽰当前已经处理了⼏个数字; 3. 递归结束条件:当 pos 等于 nums 数组的⻓度时,说明我们已经处理完了所有数字,将当前数组存⼊结果中; 4. 在每个递归状态中,枚举所有下标 i,若这个下标未被标记,并且在它之前的相同元素被标记过,则使⽤ nums 数组中当前下标的元素: a. 将 check[i] 标记为 true; b. 将 nums[i] 添加⾄ path 数组末尾; c. 对第 i+1 个位置进⾏递归; d. 将 check[i] 重新赋值为 false,并删除 path 末尾元素表⽰回溯; 5. 最后,返回 ret。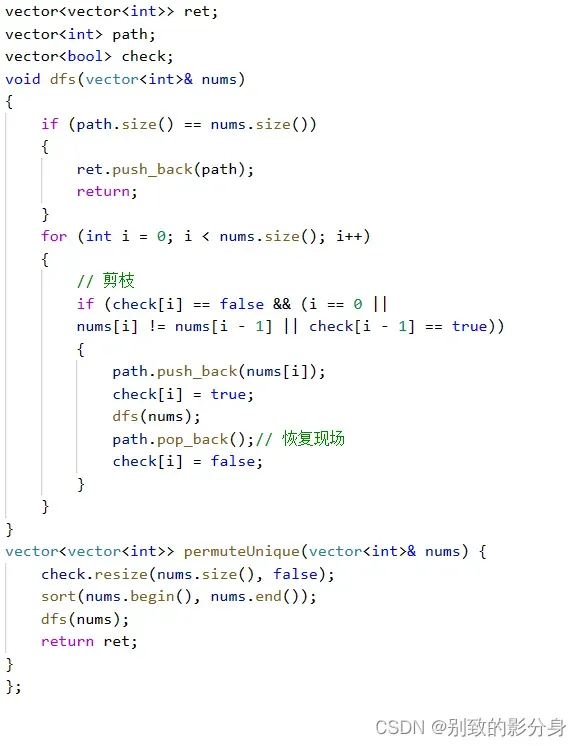
例题五

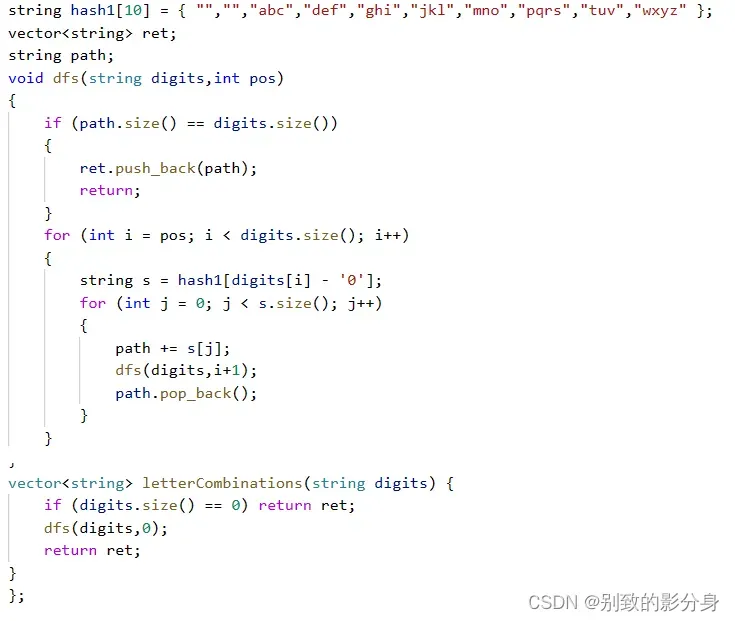
.解法: 算法思路: 每个位置可选择的字符与其他位置并不冲突,因此不需要标记已经出现的字符,只需要将每个数字对应的字符依次填⼊字符串中进⾏递归,在回溯时撤销填⼊操作即可。• 在递归之前我们需要定义⼀个字典 hash1,记录 2~9 各⾃对应的字符。 全局变量:
string hash1[10] = { “”,””,”abc”,”def”,”ghi”,”jkl”,”mno”,”pqrs”,”tuv”,”wxyz” };
vector<string> ret;
string path;
递归函数设计:void dfs(string digits,int pos)
参数:pos (已经处理的元素个数); 返回值:⽆ 函数作⽤:查找所有合理的字⺟组合并存储在答案列表中。 递归函数流程如下: 1. 递归结束条件:当 path 等于 digits 的⻓度时,将 path 加⼊到 ret 中并返回; 2. 取出当前处理的数字 digit,根据 hash1 取出对应的字⺟列表 s; 3. 遍历字⺟列表 s,将当前字⺟加⼊到组合字符串 path 的末尾,然后递归处理下⼀个数字(传 ⼊ i + 1,表⽰处理下⼀个数字); 4. 递归处理结束后,将加⼊的字⺟从 path 的末尾删除,表⽰回溯。 5. 最终返回 ret 即可。
例题六

解法: 算法思路: 从左往右进⾏递归,在每个位置判断放置左右括号的可能性,若此时放置左括号合理,则放置左括号继续进⾏递归,右括号同理。 ⼀种判断括号是否合法的⽅法:从左往右遍历,左括号的数量始终⼤于等于右括号的数量,并且左括号的总数量与右括号的总数量相等。因此我们在递归时需要进⾏以下判断: 1. 放⼊左括号时需判断此时左括号数量是否⼩于字符串总⻓度的⼀半(若左括号的数量⼤于等于字符串⻓度的⼀半时继续放置左括号,则左括号的总数量⼀定⼤于右括号的总数量); 2. 放⼊右括号时需判断此时右括号数量是否⼩于左括号数量。 全局变量:vector<string> ret;
string path;
int l, r;
int _n;递归函数设计:void dfs() 参数:无; 返回值:⽆; 函数作⽤:查找所有合理的括号序列并存储在答案列表中。 递归函数参数设置为当前状态的字符串⻓度以及当前状态的左括号数量,递归流程如下: 1. 递归结束条件:当前r与 n 相等,记录当前状态并返回; 2. 若此时左括号数量⼩于字符串总⻓度的⼀半,则在当前状态的字符串末尾添加左括号并继续递归,递归结束撤销添加操作; 3. 若此时右括号数量⼩于左括号数量(右括号数量可以由当前状态的字符串⻓度减去左括号数量求 得),则在当前状态的字符串末尾添加右括号并递归,递归结束撤销添加操作;
例题七

解法(回溯): 算法思路: 题⽬要求我们从 1 到 n 中选择 k 个数的所有组合,其中不考虑顺序。也就是说,[1,2] 和 [2,1] 等价。我们需要找出所有的组合,但不能重复计算相同元素的不同顺序的组合。对于选择组合,我们需要进⾏ 如下流程: 1. 所有元素分别作为⾸位元素进⾏处理; 2. 在之后的位置上同理,选择所有元素分别作为当前位置元素进⾏处理; 3. 为避免计算重复组合,规定选择之后位置的元素时必须⽐前⼀个元素⼤,这样就不会有重复的组合 ([1,2] 和 [2,1] 中 [2,1] 不会出现)。 全局变量:vector<vector<int>> ret;
vector<int> path;
int _n, _k;递归函数设计:void dfs(int pos) 参数:pos(当前需要进⾏处理的位置);返回值:⽆; 函数作⽤:某个元素作为⾸位元素出现时,查找所有可能的组合。 递归流程如下: a. 结束条件:当前组合中已经有 k 个元素,将当前组合存进⼆维数组并返回。 ▪ 剪枝:如果当前位置之后的所有元素放⼊组合也不能满⾜组合中存在 k 个元素,直接返回。 b. 从当前位置的下⼀个元素开始遍历到 n,将元素赋值到当前位置,递归下⼀个位置。
例题八

解法(回溯): 算法思路: 对于每个数,可以选择加上或减去它,依次枚举每⼀个数字,在每个数都被选择时检查得到的和是否等于⽬标值。如果等于,则记录结果。 需要注意的是,为了优化时间复杂度,可以提前计算出数组中所有数字的和 sum,以及数组的⻓度 len。这样可以快速判断当前的和减去剩余的所有数是否已经超过了⽬标值 target ,或者当前的和加上剩下的数的和是否⼩于⽬标值 target,如果满⾜条件,则可以直接回溯。 递归流程: 1. 递归结束条件:位置pos 与数组⻓度相等,判断当前状态的 sum 是否与⽬标值相等,若是计数加⼀; 2. 选择当前元素进⾏加操作,递归下⼀个位置,并更新参数 sum; 3. 选择当前元素进⾏减操作,递归下⼀个位置,并更新参数 sum; 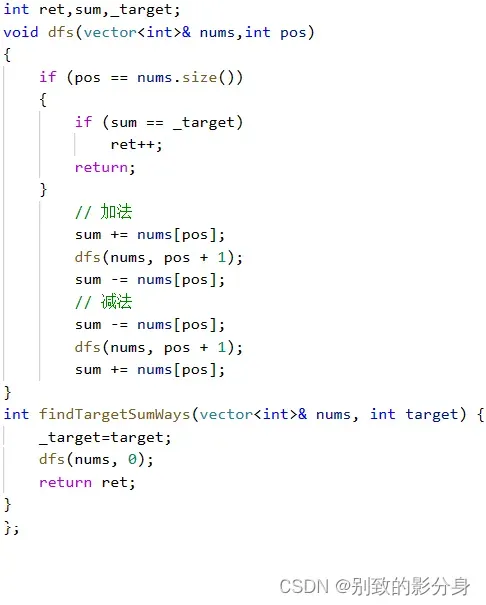
例题九

解法: 算法思路: candidates 的所有元素 互不相同,因此我们在递归状态时只需要对每个元素进⾏如下判断: 1. 跳过,对下⼀个元素进⾏判断; 2. 将其添加⾄当前状态中,我们在选择添加当前元素时,之后仍可以继续选择当前元素(可以重复选择同⼀元素)。 • 因此,我们在选择当前元素并向下传递下标时,应该直接传递当前元素下标。 全局变量:vector<vector<int>> ret;
vector<int> path;
int _target;递归函数设计:void dfs(vector<int>& candidates, int sum,int pos)
参数:sum(当前状态和),pos(当前需要处理的元素下标); 返回值:⽆; 函数作⽤:向下传递两个状态(跳过或者选择当前元素),找出所有组合使得元素和为⽬标值。 递归函数流程如下: 1. 结束条件: a. 当前需要处理的元素下标越界; b. 当前状态的元素和已经与⽬标值相同; 2. 跳过当前元素,当前状态不变,对下⼀个元素进⾏处理; 3. 选择将当前元素添加⾄当前状态,并保留状态继续对当前元素进⾏处理,递归结束时撤销添加操 作。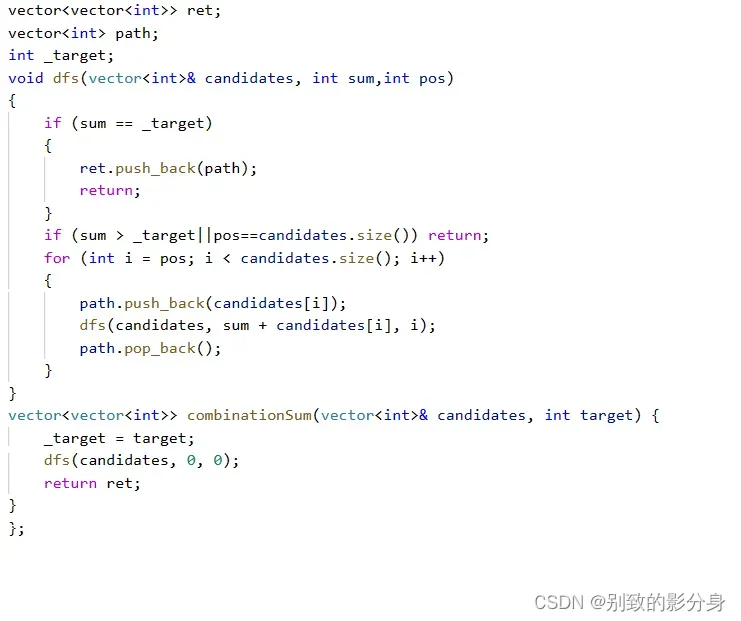
例题十

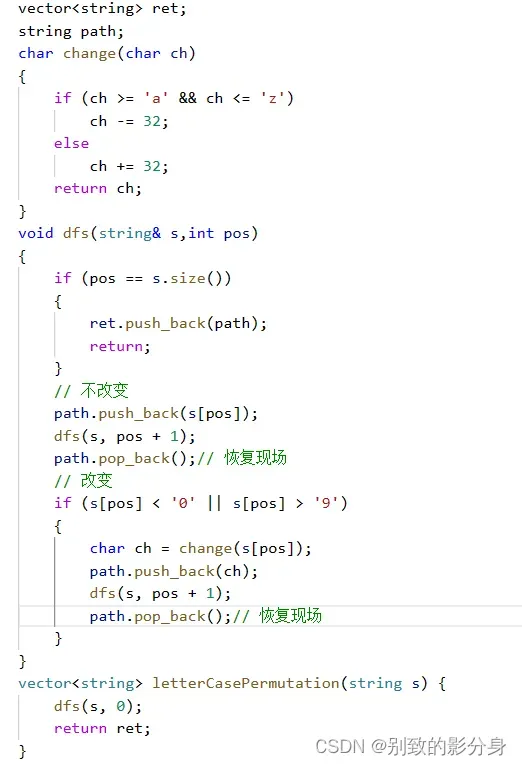
解法: 算法思路: 只需要对英⽂字⺟进⾏处理,处理每个元素时存在三种情况: 1. 不进⾏处理; 2. 若当前字⺟是英⽂字⺟并且是⼤写,将其修改为⼩写; 3. 若当前字⺟是英⽂字⺟并且是⼩写,将其修改为⼤写。 递归函数设计:void dfs(string& s,int pos)
参数:pos(当前需要处理的位置); 返回值:⽆; 函数作⽤:查找所有可能的字符串集合,并将其记录在答案列表。 从前往后按序进⾏递归,递归流程如下: 1. 递归结束条件:当前需要处理的元素下标越界,表⽰处理完毕,记录当前状态并返回; 2. 对当前元素不进⾏任何处理,直接递归下⼀位元素; 3. 判断当前元素是否为⼩写字⺟,若是,将其修改为⼤写字⺟并递归下⼀个元素,递归结束时撤销修改操作; 4. 判断当前元素是否为⼤写字⺟,若是,将其修改为⼩写字⺟并递归下⼀个元素,递归结束时撤销修改操作;
例题十一

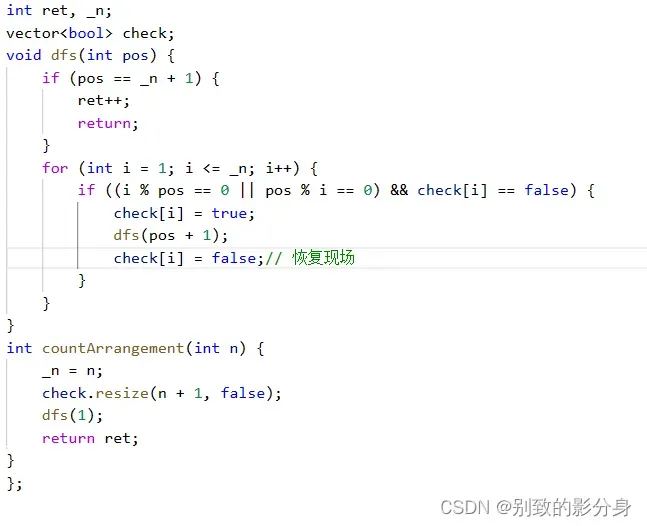
解法: 算法思路: 我们需要在每⼀个位置上考虑所有的可能情况并且不能出现重复。通过深度优先搜索的⽅式,不断地枚举每个数在当前位置的可能性,并回溯到上⼀个状态,直到枚举完所有可能性,得到正确的结果。 我们需要定义⼀个变量 ⽤来记录所有可能的排列数量,⼀个⼀维数组 check 标记元素,然后从第⼀个位置开始进⾏递归; 递归函数设计:void dfs(int pos)参数:pos(当前需要处理的位置); 返回值:⽆; 函数作⽤:在当前位置填⼊⼀个合理的数字,查找所有满⾜条件的排列。 递归流程如下:1. 递归结束条件:当 pos 等于 n+1 时,说明已经处理完了所有数字,将当前数组存⼊结果中; 2. 在每个递归状态中,枚举所有下标 x,若这个下标未被标记,并且满⾜题⽬条件之⼀: a. 将 check[x] 标记为 ture; b. 对第 pos+1 个位置进⾏递归; c. 将 check[x] 重新赋值为 false,表⽰回溯;
版权声明:本文为博主作者:别致的影分身原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/2301_79881188/article/details/137838682