本文将介绍如何使用Python调用Stable Diffusion API进行图像生成,实现文生图的功能。通过详细的步骤说明和示例代码,读者将能够轻松掌握这一技术,并运用它生成独特而富有创意的图像作品。无论你是编程爱好者还是设计师,都能从中获得启发和乐趣。
stable diffusion本地的部署方法可参考文章:文生图——stable diffusion生成有趣的动漫图像
part1:文生图概念及API简介
在数字艺术和创意设计的交汇点上,文生图(Text-to-Image)技术正以其独特的魅力吸引着无数创作者。这项技术允许用户通过输入文字描述,生成与之相对应的图像,从而打破了传统图像创作的界限,为艺术家和设计师们提供了全新的创作手段。
文生图技术的核心在于深度学习和自然语言处理。通过训练大量的图像和文字数据,模型能够理解文字与图像之间的关联,进而根据文字描述生成相应的图像。这种技术的出现,不仅降低了图像创作的门槛,还极大地丰富了图像创作的可能性和多样性。
在众多文生图技术中,Stable Diffusion以其出色的图像生成质量和稳定的性能脱颖而出。Stable Diffusion是一个基于扩散模型的文本到图像生成系统,它能够根据用户提供的文本提示,生成高质量、高分辨率的图像。而Stable Diffusion API则是这一强大功能的桥梁,它允许开发者通过编程方式调用Stable Diffusion模型,实现自定义的图像生成任务。
Stable Diffusion API的设计简洁而高效,用户只需通过API接口发送包含文本描述的请求,即可获得与之对应的图像输出。这种即插即用的方式,不仅方便了开发者的集成和应用,还大大降低了技术门槛,使得更多创作者能够轻松体验到文生图的魅力。
要获得stable Diffusion API 首先,我们进入stable diffusion官网:Stable Diffusion 3 — Stability AI
进入Stability AI Developer Platform  ,如左图,点击Platform API即可。进入网页后,我们首先登录自己的SD账号,点击账号,即可看到下方画面:
,如左图,点击Platform API即可。进入网页后,我们首先登录自己的SD账号,点击账号,即可看到下方画面: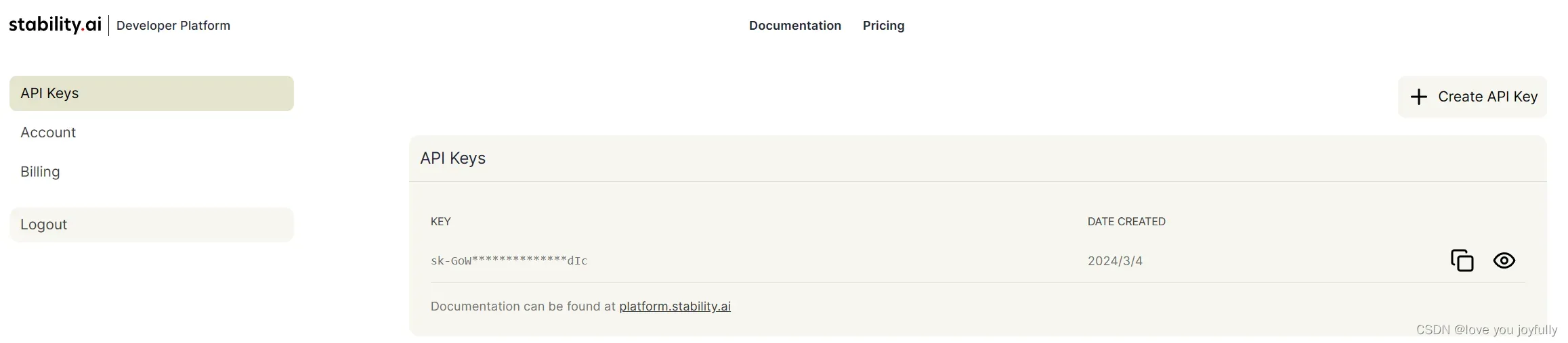
使用个人的API Keys,即可调用API进行创作了。在Billing界面,可以看到自己的API调用余额,调用不同的模型消耗不同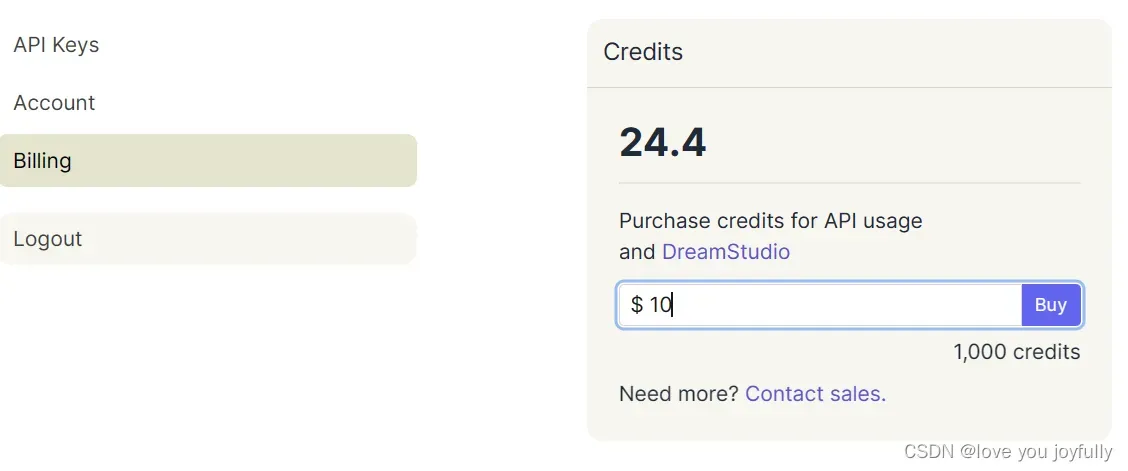
使用不同模型消耗的Credits可以通过Stability AI – Developer Platform查看。
part2:python调用stable diffusionAPI进行绘图
我们可以通过以下代码实现文生图的API调用:
import base64
import os
import requests
engine_id = "stable-diffusion-v1-6"
api_host = os.getenv('API_HOST', 'https://api.stability.ai')
api_key = "skxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxWdIc"
if api_key is None:
raise Exception("Missing Stability API key.")
response = requests.post(
f"{api_host}/v1/generation/{engine_id}/text-to-image",
headers={
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"Bearer {api_key}"
},
json={
"text_prompts": [
{
"text": "A lighthouse on a cliff"
}
],
"cfg_scale": 7,
"height": 1024,
"width": 1024,
"samples": 1,
"steps": 30,
},
)
if response.status_code != 200:
raise Exception("Non-200 response: " + str(response.text))
data = response.json()
for i, image in enumerate(data["artifacts"]):
with open(f"out/v1_txt2img_{i}.png", "wb") as f:
f.write(base64.b64decode(image["base64"]))这段代码来源并修改于stable diffusion官方文档Stability AI – Developer Platform,下面,我们对代码进行一些解释:
- engine_id代表你使用的文生图模型,用户可以根据需要选择不同的模型;
- api_key为用户的API key,这地方直接将自己的API key复制过来就好;
-
json={ “text_prompts”: [{ “text”: “A lighthouse on a cliff” } ], “cfg_scale”: 7, “height”: 1024, “width”: 1024, “samples”: 1, “steps”: 30, }中,我们可以对图片的输出内容进行设置, “text_prompts”即为提示词,如文中为“悬崖上的灯塔”,后边为对图片的参数设置。
在运行上述代码前,首先在与上述python文件同目录下创建一个out文件夹,这样代码会将图片输出到out文件夹当中。
接下来,让我们实操一下上述代码吧!
part3:代码实操
首先,我们先获取一些优秀的提示词:

接着我们将这些提示词整理好放入代码中,如下方代码所示:
import base64
import os
import requests
engine_id = "stable-diffusion-v1-6"
api_host = os.getenv('API_HOST', 'https://api.stability.ai')
api_key = "skxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxIc"
if api_key is None:
raise Exception("Missing Stability API key.")
response = requests.post(
f"{api_host}/v1/generation/{engine_id}/text-to-image",
headers={
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"Bearer {api_key}"
},
json={
"text_prompts": [
{
"text": "Sunset Glow,Anime Kids,Adorable Features,Bright Eyes,Cheerful Expressions,Colorful Backpacks,School Uniforms,Chibi Style,Golden Hour,Warm Light,Long Shadows,Rustling Trees,Birds Flying,Distant Houses,Country Road,Walking Home,Chattering Friends,Laughing Faces,Innocent Joy,Youthful Energy"
}
],
"cfg_scale": 7,
"height": 1024,
"width": 1024,
"samples": 1,
"steps": 30,
},
)
if response.status_code != 200:
raise Exception("Non-200 response: " + str(response.text))
data = response.json()
for i, image in enumerate(data["artifacts"]):
with open(f"out/v1_txt2img_{i}.png", "wb") as f:
f.write(base64.b64decode(image["base64"]))
运行后,在out文件夹中即可获得所需要的图片:

可以看到,图像整体风格没有太大问题,但是图片细节还是不太妙,读者可以尝试多生成几次,找到满意的图像。
Stable Diffusion模型原理简介
Stable Diffusion是一种基于扩散过程的生成模型,由多个关键组件和原理构成,以下是对其原理的详细分段介绍:
一、扩散过程
Stable Diffusion的核心思想是通过扩散过程来实现图像生成和图像修复。扩散过程是一种物理现象,描述了粒子随时间的随机运动。在Stable Diffusion中,扩散过程被应用于图像数据,通过向图像像素添加随机噪声并迭代地去除这些噪声,逐渐使图像从无序状态过渡到有序状态,最终生成符合目标分布的图像。
二、变分自编码器(VAE)
为了有效地处理图像数据,Stable Diffusion引入了变分自编码器(VAE)。VAE是一种生成模型,它能够将图像编码成一个隐变量向量,并通过解码器将其还原成图像。在编码过程中,VAE学习到数据分布的特征,从而能够生成与原始数据相似的图像。通过VAE,Stable Diffusion实现了对图像的高效压缩和编码,为后续的扩散过程提供了便利。
三、可逆网络
在Stable Diffusion中,可逆网络发挥着关键作用。可逆网络是一种特殊的神经网络结构,它允许数据在正向和反向过程中进行无损变换。在Stable Diffusion中,可逆网络被用于实现扩散过程的反向操作,即将扩散后的噪声数据还原成原始图像。通过可逆网络,模型能够在不损失信息的情况下对数据进行变换和处理,从而保证了生成图像的质量和准确性。
四、稳定性控制
Stable Diffusion通过控制扩散过程的时间步长来实现对生成图像稳定性的控制。时间步长决定了扩散过程中每一步的噪声添加量和去除量。较小的时间步长可以使扩散过程更加平稳,生成的图像更加稳定,但也会增加计算成本和生成时间。相反,较大的时间步长可以加速扩散过程,但可能会导致生成的图像出现不稳定或质量下降的情况。因此,在Stable Diffusion中需要权衡生成图像的稳定性和计算效率之间的关系。
五、条件机制与文本引导
Stable Diffusion还引入了条件机制来实现文本引导的图像生成功能。通过结合CLIP文本编码器和交叉注意力机制,模型能够根据用户提供的文本描述来调整生成图像的内容和风格。这使得Stable Diffusion能够灵活地应对不同的生成需求并提供个性化的图像生成服务。
以上是利用python调用stable diffusionAPI进行图像生成的方法, stable diffusion本地的部署方法可参考文章:文生图——stable diffusion生成有趣的动漫图像
版权声明:本文为博主作者:love you joyfully原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_60223645/article/details/137143897