基于stable – diffusion 的本地部署AI绘画教程
自从Stable Diffusion 1.0模型发布以来,“AI文本图片生成”真正的变成普通人也能使用的技术。同时各种国内外AI绘图软件,也不断频繁更新,AI绘画的关注度也越来越高。
以下是本人自己生成出来的一些AI绘图(夹带私货木木枭^ ^)


对应的提示语prompt为:
"a cute portrait of rowlet,anime,warm style,suit , highly detailed, oil painting, concept art, smooth, sharp focus,high quality artwork"
那么如果我们想要本地部署一个真正属于自己的AI绘画模型,需要哪些东西呢。
要完成本次部署,我们需要导入一些包并且用里面封装好的参数来实现相应的功能,从而实现我们要的文字出图的功能.
接下来详细介绍一下大概的步骤。
| 操作环境: | python 3.8.13 |
| 操作软件: | VsCode |
| 文件格式: | ipynb |
需要下载的包在后面会有讲到
1. 连接显卡
!nvidia-smi
首先要让GPU连接到notebook上
单独运行该语句后,成功后会显示如下提示

2. 本地下载transformershe和diffusers包:
%pip install diffusers==0.4.0
%pip install transformers scipy ftfy
由于这里是jupyter所以和python 的pip的方式有点不一样
或者通过conda下载也可以
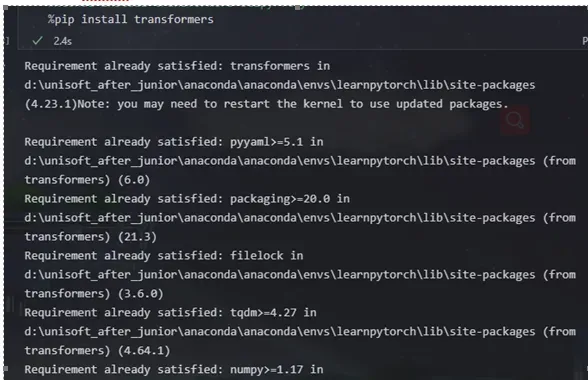
下载成功后会有如上提示
如果后面有
RuntimeError: CUDA error: no kernel image is available for execution on the device
类似这种提示,则说明一般是cuda或者python的版本出了问题
可能是版本不对,一般要求是3.8
3. 获取hugging face官网的access token:
安装好两个包后,就要开始获取用户的权限了,由于stable diffusion的hugging face上面的产品,要使用它的模型的时候需要一个token的申请。
因此我们看一下如何获得申请
1. from huggingface_hub import notebook_login
2.
3. notebook_login()
这里的代码只有两行
如果没有安装huggingface_hub这个包的话用conda下载一下就可以了
也是比较容易的
Conda install huggingface_hub
成功运行后会出现如下内容
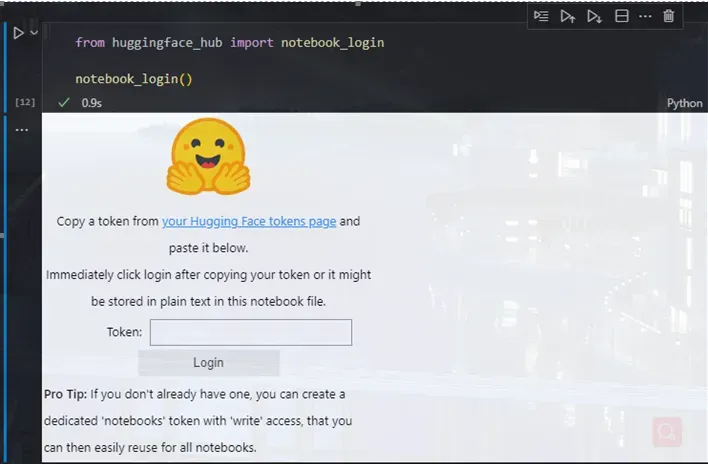
要拿到这个token需要我们登录hugging face的官网
注册一个账号,不需要手机号什么的,比较容易注册
-
注册成功之后到个人设置这里
-
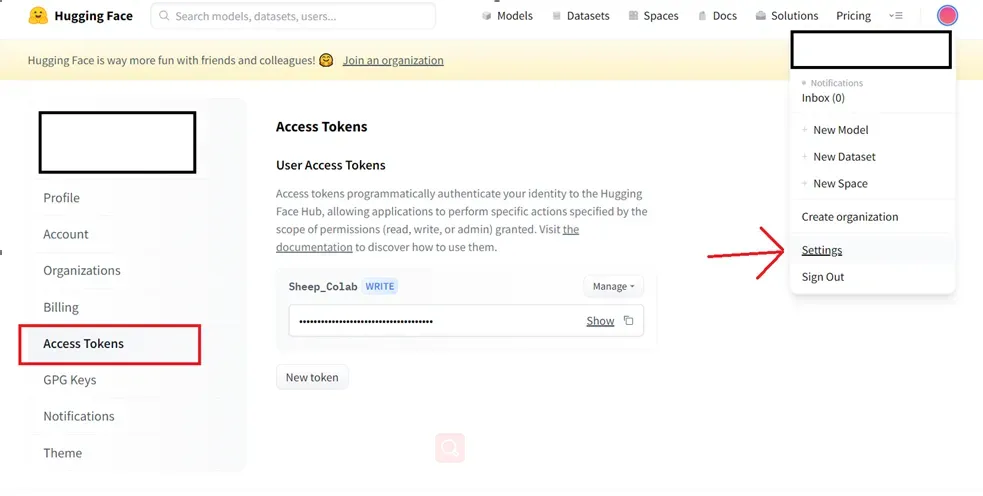
-
获取token之后就可以正常运行了
-
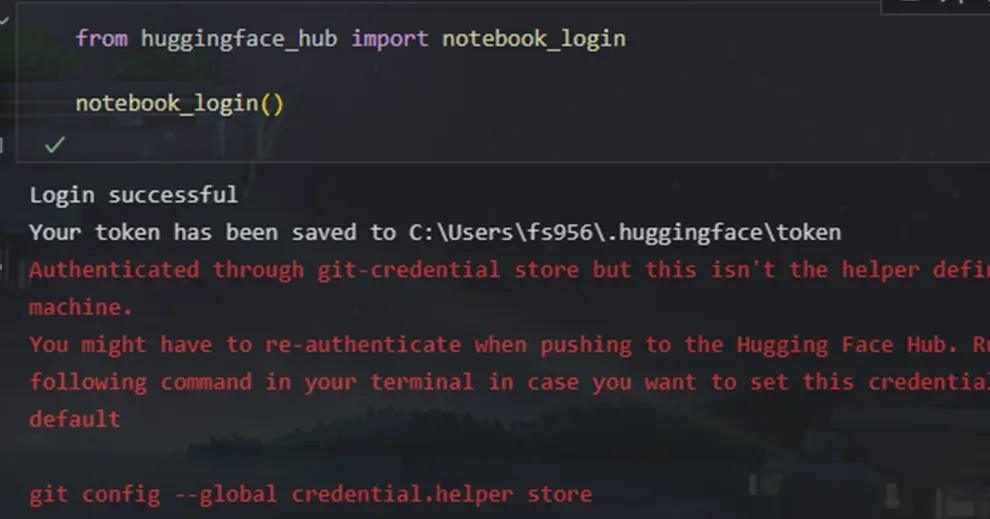
成功登录获取之后如上图提示内容
4. 获取diffusers数据集并生成pipe管道
首先看一下这个的代码
1. import torch
2. #from torch import autocast
3. from diffusers import StableDiffusionPipeline
4.
5. # make sure you're logged in with `huggingface-cli login`
6. #pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16)
7. pipe = StableDiffusionPipeline.from_pretrained("./stable-diffusion-v1-4")
这里导入了torch包和之前下载的diffusers包
进行模型,然后进行模型的加载
Pipe就是加载成功后获得模型的管道了
而这一句也是所有代码当中最核心的一句
这里的文件路径是一个模型包
可以在github或者huggingface上面都有,下载模型包
CompVis/stable-diffusion-v1-4 · Hugging Face
以上是官网链接
整个模型大概10GB(现在可能不止了)
运行成功后没有提示语出现
5.将pipe管道部署到GPU上运行
如果我们使用CPU去跑这个模型,需要等待的时间将会非常非常的长,为了解决这个问题,这里提供了一个方法,可以将pipe管道移动到GPU上面去运行。
pipe = pipe.to("cuda")
但是这里会跟资源的分配有关,本地的电脑如果显卡没有这么强的话,很有可能会失败,例如提示显存不够给予去运算,例如本人的电脑如果开了其他运行程序就很容易出现内存分配不够的问题
如果内存不够建议可以使用谷歌提供的colab云平台来运行自己的服务,谷歌会免费分配一个显卡资源给colab的账号。
内存不足的时候运行上述代码会有相应的报错,注意看报错内容即可。
6. 使用prompt生成图片
当我们可以正常使用GPU来跑模型之后,就可以正式开始生成我们的图片啦!
我们只需要简单地输入一个字符串,就可以生成图片
1. #提示语输入内容
2. prompt = "a photograph of an astronaut riding a horse"
3. #放入pipe中运行
4. image = pipe(prompt).images[0]
5.
6.
7. #直接显示图片
8. image
运行该代码,会出现一个进度条进行等待,运行成功后如下所示。
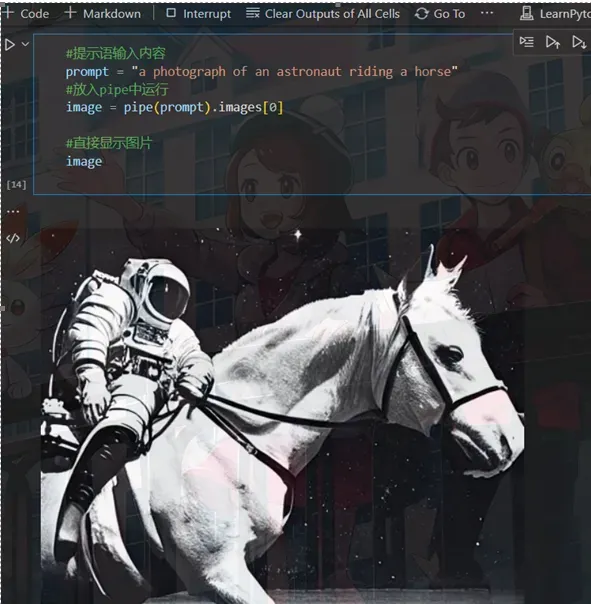
上图就是通过stable-diffusion模型生成的图片了
给出的提示语是“a photograph of an astronauut riding a horse”
可以看出给出的图片还是比较符合描述语的内容的,同时也有一种荒诞的感觉
最后:如果想要让画面更加精美,需要给prompt的内容加上更加细节的描述
如果自己想不到什么好的英文提示语,可以参考网站Lexica
这个网站允许用户上传自己的prompt生成的图片
给出的图片还是比较符合描述语的内容的,同时也有一种荒诞的感觉
最后:如果想要让画面更加精美,需要给prompt的内容加上更加细节的描述
如果自己想不到什么好的英文提示语,可以参考网站Lexica
这个网站允许用户上传自己的prompt生成的图片
文章出处登录后可见!