一、引言
购物篮分析是商业领域最前沿、最具挑战性的问题之一,也是许多企业重点研究的问题。购物篮分析是通过发现顾客在一次购买行为中放入购物篮中不同商品之间的关联,研究顾客的购买行为,从而辅助零售企业制定营销策略的一种数据分析方法。
本篇文章使用 Apriori 关联规则算法实现购物篮分析,发现超市不同商品之间的关联关系,并根据商品之间的关联规则制定销售策略。
二、数据探索分析
2.1 查看数据特征
搜索数据的特征,查看每列属性、最大值、最小值、是了解数据的第一步。
import numpy as np
import pandas as pd
inputfile = './data/GoodsOrder.csv' # 输入的数据文件
data = pd.read_csv(inputfile,encoding = 'gbk') # 读取数据
data .info() # 查看数据属性
data = data['id']
description = [data.count(),data.min(), data.max()] # 依次计算总数、最小值、最大值
description = pd.DataFrame(description, index = ['Count','Min', 'Max']).T # 将结果存入数据框
print('描述性统计结果:\n',np.round(description)) # 输出结果结果如下
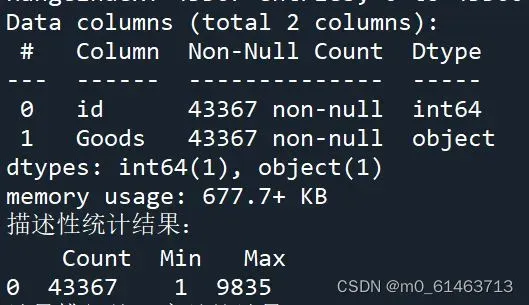
可到每列属性共有43367个观测值,并不存在缺失值。“id”属性的最大值和最小值,可得某商品零售企业共收集9835个购物篮数据,其中包含169个不同的商品类别,售出商品总数43367件。
2.2 分析热销商品
热销情况分析可以助力商品优选。计算销量排名前10的商品销量及占比,并绘制条形图显示销量前10的商品销量情况。
# 销量排行前10商品的销量及其占比
import pandas as pd
inputfile = './data/GoodsOrder.csv' # 输入的数据文件
data = pd.read_csv(inputfile,encoding = 'gbk') # 读取数据
group = data.groupby(['Goods']).count().reset_index() # 对商品进行分类汇总
sorted=group.sort_values('id',ascending=False)
print('销量排行前10商品的销量:\n', sorted[:10]) # 排序并查看前10位热销商品
# 画条形图展示出销量排行前10商品的销量
import matplotlib.pyplot as plt
x=sorted[:10]['Goods']
y=sorted[:10]['id']
plt.figure(figsize = (8, 4)) # 设置画布大小
plt.barh(x,y)
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.xlabel('销量') # 设置x轴标题
plt.ylabel('商品类别') # 设置y轴标题
plt.title('商品的销量TOP10(3001)') # 设置标题
plt.savefig('./data//top10.png') # 把图片以.png格式保存
plt.show() # 展示图片
# 销量排行前10商品的销量占比
data_nums = data.shape[0]
for idnex, row in sorted[:10].iterrows():
print(row['Goods'],row['id'],row['id']/data_nums)结果如下
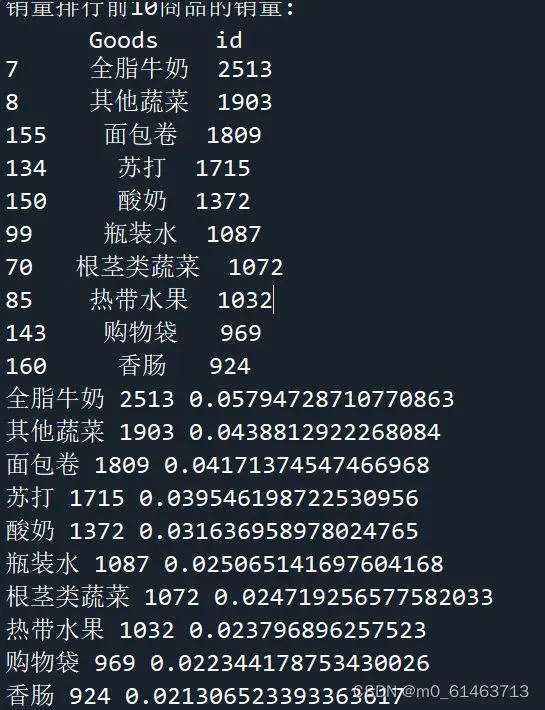
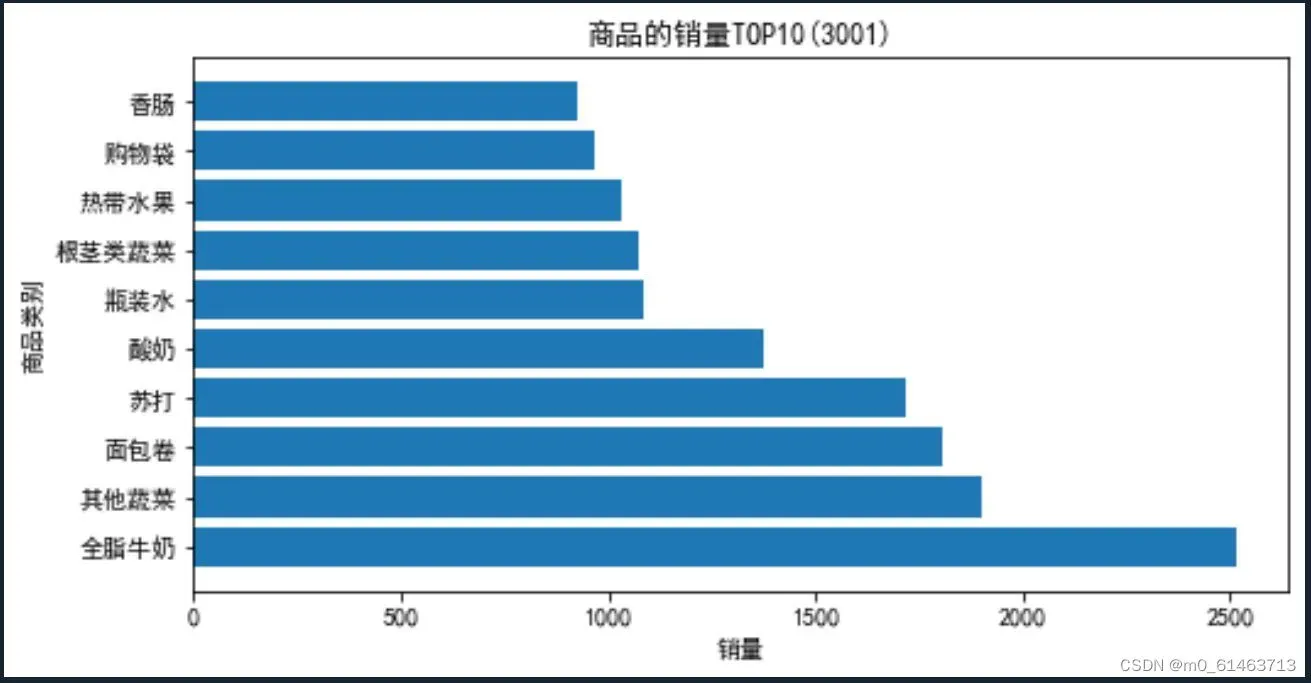
通过分析热销商品的结果可知,全脂牛奶的销量最高,为2513件,占比5.795%;其次是其他蔬菜、面包卷和苏打,占比分别为4.388%、4.171%、3.955%。
2.3 分析商品结构
对每一类商品的热销程度进行分析,有利于商品制定商品在货架上的摆放策略和位置。分析归类后各类别商品的销量及其占比后,绘制饼图显示各类商品的销量占比情况
import pandas as pd
inputfile1 = './data/GoodsOrder.csv'
inputfile2 = './data/GoodsTypes.csv'
data = pd.read_csv(inputfile1,encoding = 'gbk')
types = pd.read_csv(inputfile2,encoding = 'gbk') # 读入数据
group = data.groupby(['Goods']).count().reset_index()
sort = group.sort_values('id',ascending = False).reset_index()
data_nums = data.shape[0] # 总量
del sort['index']
sort_links = pd.merge(sort,types) # 合并两个datafreame 根据type
# 根据类别求和,每个商品类别的总量,并排序
sort_link = sort_links.groupby(['Types']).sum().reset_index()
sort_link = sort_link.sort_values('id',ascending = False).reset_index()
del sort_link['index'] # 删除“index”列
# 求百分比,然后更换列名,最后输出到文件
sort_link['count'] = sort_link.apply(lambda line: line['id']/data_nums,axis=1)
sort_link.rename(columns = {'count':'percent'},inplace = True)
print('各类别商品的销量及其占比:\n',sort_link)
outfile1 = './data/percent.csv'
sort_link.to_csv(outfile1,index = False,header = True,encoding='gbk') # 保存结果
# 画饼图展示每类商品销量占比
import matplotlib.pyplot as plt
data = sort_link['percent']
labels = sort_link['Types']
plt.figure(figsize=(8, 6)) # 设置画布大小
plt.pie(data,labels=labels,autopct='%1.2f%%')
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.title('每类商品销量占比(3001)') # 设置标题
plt.savefig('./data/persent.png') # 把图片以.png格式保存
plt.show()结果如下
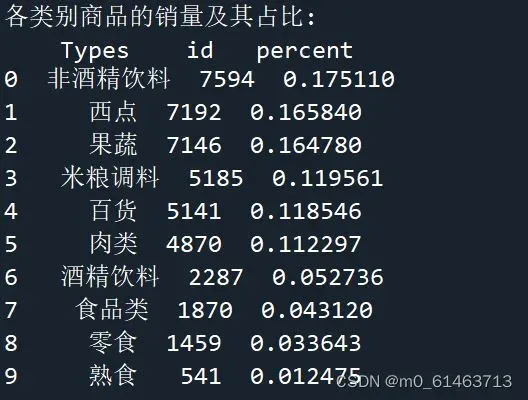
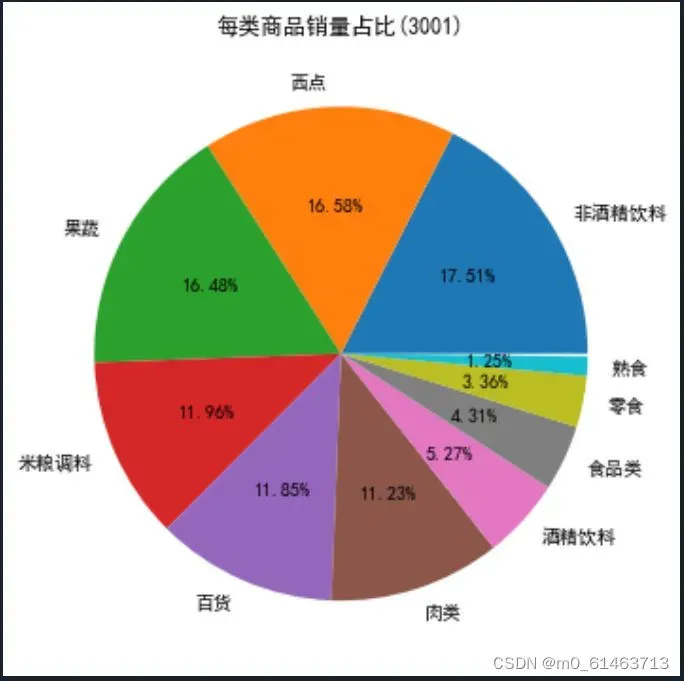
通过分析各类别商品的销量及其占比情况可知,非酒精饮料、西点、果蔬3类商品的销量差距不大,占比总销量的50%左右
进一步查看销量第一的非酒精饮料类商品和销量第二的西点的内部结构,并绘制饼图显示其销量占比情况
# 筛选“非酒精饮料”类型的商品,然后求百分比。
alcohol = sort_links.loc[sort_links['Types'] == '非酒精饮料'] # 挑选商品类别为“非酒精饮料”并排序
child_nums = alcohol['id'].sum() # 对所有的“非酒精饮料”求和
alcohol['child_percent'] = alcohol.apply(lambda line: line['id']/child_nums,axis = 1) # 求百分比
alcohol.rename(columns = {'id':'count'},inplace = True)
print('非酒精饮料内部商品的销量及其占比:\n',alcohol)
# 筛选“西点”类型的商品,然后求百分比。
desserts = sort_links.loc[sort_links['Types'] == '西点'] # 挑选商品类别为“西点”并排序
child_nums = desserts['id'].sum() # 对所有的“西点”求和
desserts['child_percent'] = desserts.apply(lambda line: line['id']/child_nums,axis = 1) # 求百分比
desserts.rename(columns = {'id':'count'},inplace = True)
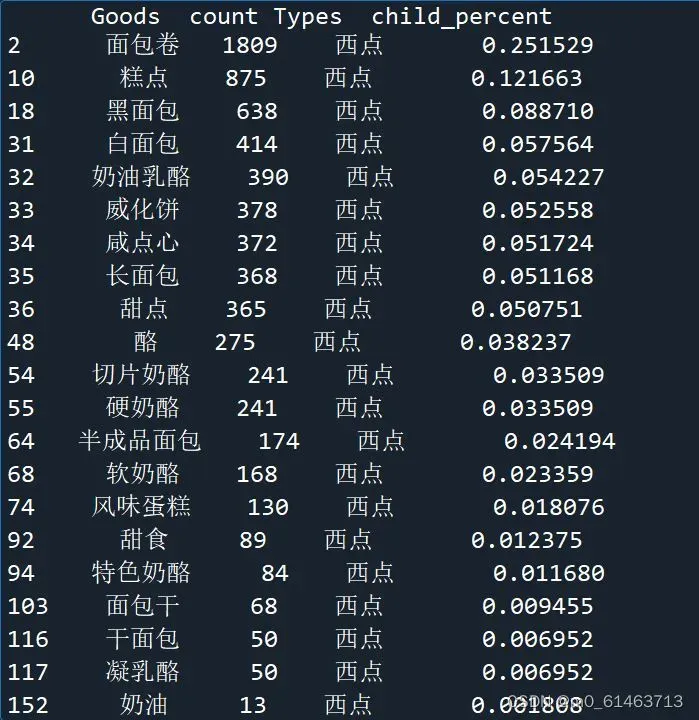
print('西点内部商品的销量及其占比:\n',desserts)
# 画饼图展示非酒精饮品内部各商品的销量占比
import matplotlib.pyplot as plt
data = alcohol['child_percent']
labels = alcohol['Goods']
plt.figure(figsize = (8,6)) # 设置画布大小
explode = (0.02,0.03,0.04,0.05,0.06,0.07,0.08,0.08,0.3,0.1,0.3) # 设置每一块分割出的间隙大小
plt.pie(data,explode = explode,labels = labels,autopct = '%1.2f%%',
pctdistance = 1.1,labeldistance = 1.2)
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.title("非酒精饮料内部各商品的销量占比(3001)") # 设置标题
plt.axis('equal')
plt.show() # 展示图形
# 画饼图展示西点内部各商品的销量占比
data = desserts['child_percent']
labels = desserts['Goods']
plt.figure(figsize = (8,6)) # 设置画布大小
plt.pie(data,explode = None ,labels = labels,autopct = '%1.2f%%',
pctdistance = 1.1,labeldistance = 1.2)
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.title("西点内部各商品的销量占比(3001)") # 设置标题
plt.axis('equal')
plt.show() # 展示图形结果如下
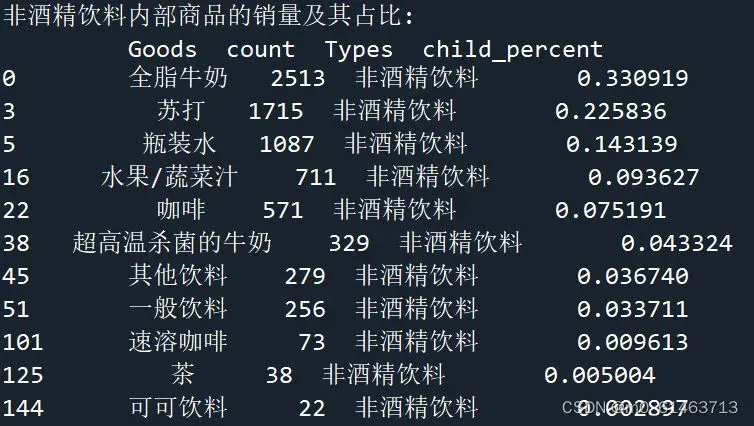
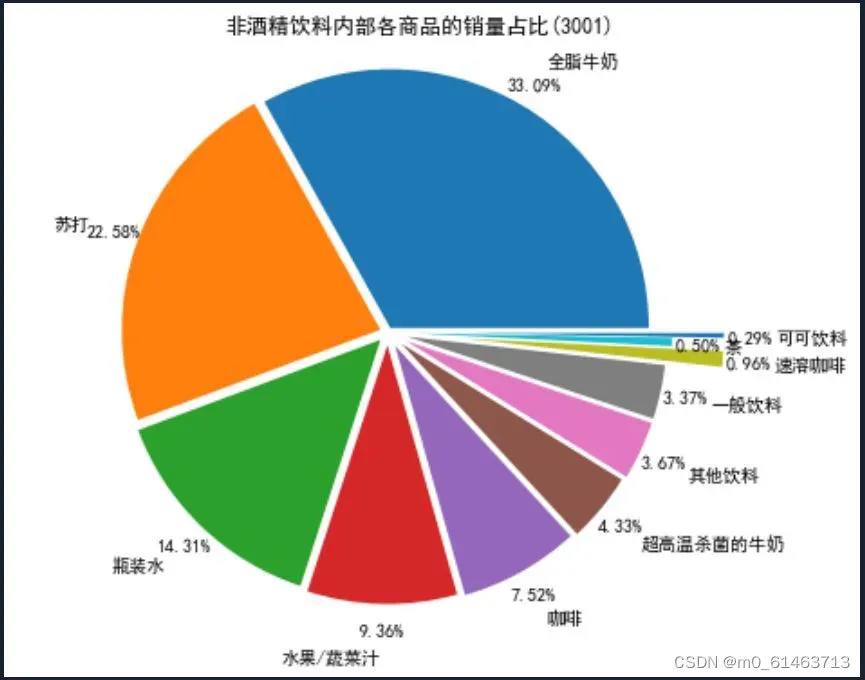
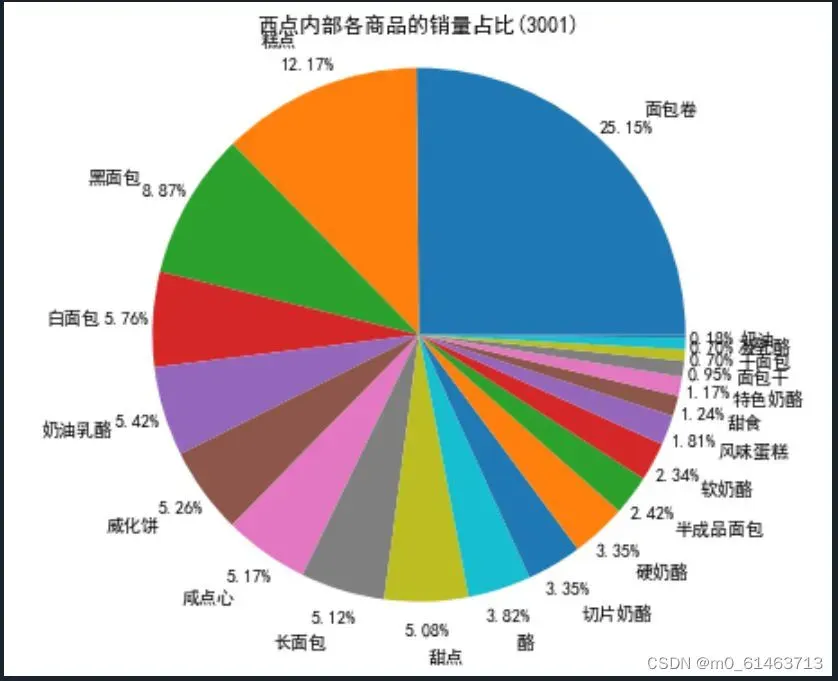
通过分析非酒精饮料内部商品的销量及其情况可知,全脂牛奶的销量在非酒精饮料的总销量中占比超过33%,前3种非酒精饮料的销量在非酒精饮料的总销量中的占比接近70%。
同理分析西点内部商品的销量及其情况可知,面包卷的销量在西点的总销量中占比超过25%,其次是糕点,占比12.17%
三、数据预处理
3.1 数据转换
通过对数据探索分析发现数据完整,并不存在缺失值。建模之前需要转变数据的格式,才能使用Apriori函数进行关联分析
import pandas as pd
inputfile='./data/GoodsOrder.csv'
data = pd.read_csv(inputfile,encoding = 'gbk')
# 根据id对“Goods”列合并,并使用“,”将各商品隔开
data['Goods'] = data['Goods'].apply(lambda x:','+x)
data = data.groupby('id').sum().reset_index()
# 对合并的商品列转换数据格式
data['Goods'] = data['Goods'].apply(lambda x :[x[1:]])
data_list = list(data['Goods'])
# 分割商品名为每个元素
data_translation = []
for i in data_list:
p = i[0].split(',')
data_translation.append(p)
print('数据转换结果的前5个元素:\n', data_translation[0:5])结果如下

四、模型构建
4.1商品购物篮关联规则模型构建
建模流程如图:
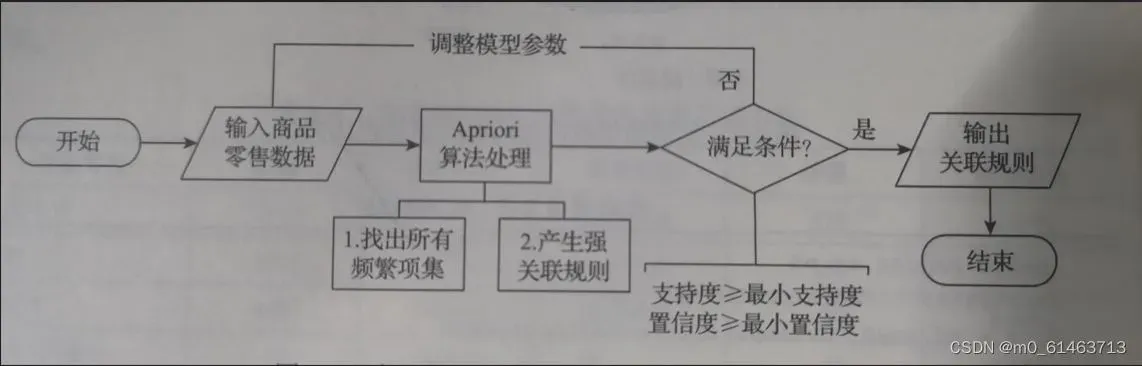
模型主要由输入、算法处理、输出3个部分组成。输入部分包括建模样本数据的输入和建模参数的输入。算法处理部分是采用 Apriori 关联规则算法进行处理。输出部分为采用 Apriori 关联规则算法进行处理后的结果。
模型具体实现步骤:首先设置建模参数最小支持度、最小置信度,输入建模样本数据;然后采用 Apriori 关联规则算法对建模的样本数据进行分析,以模型参数设置的最小支持度、最小置信度以及分析目标作为条件,如果所有的规则都不满足条件,则需要重新调整模型参数,否则输出关联规则结果。
目前,如何设置最小支持度与最小置信度并没有统一的标准。大部分都是根据业务经验设置初始值,然后经过多次调整,获取与业务相符的关联规则结果。本案例经过多次调整并结合实际业务分析,选取模型的输入参数为:最小支持度0.02、最小置信度0.35。
from numpy import *
def loadDataSet():
return [['a', 'c', 'e'], ['b', 'd'], ['b', 'c'], ['a', 'b', 'c', 'd'], ['a', 'b'], ['b', 'c'], ['a', 'b'],
['a', 'b', 'c', 'e'], ['a', 'b', 'c'], ['a', 'c', 'e']]
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
# 映射为frozenset唯一性的,可使用其构造字典
return list(map(frozenset, C1))
# 从候选K项集到频繁K项集(支持度计算)
def scanD(D, Ck, minSupport):
ssCnt = {}
for tid in D: # 遍历数据集
for can in Ck: # 遍历候选项
if can.issubset(tid): # 判断候选项中是否含数据集的各项
if not can in ssCnt:
ssCnt[can] = 1 # 不含设为1
else:
ssCnt[can] += 1 # 有则计数加1
numItems = float(len(D)) # 数据集大小
retList = [] # L1初始化
supportData = {} # 记录候选项中各个数据的支持度
for key in ssCnt:
support = ssCnt[key] / numItems # 计算支持度
if support >= minSupport:
retList.insert(0, key) # 满足条件加入L1中
supportData[key] = support
return retList, supportData
def calSupport(D, Ck, min_support):
dict_sup = {}
for i in D:
for j in Ck:
if j.issubset(i):
if not j in dict_sup:
dict_sup[j] = 1
else:
dict_sup[j] += 1
sumCount = float(len(D))
supportData = {}
relist = []
for i in dict_sup:
temp_sup = dict_sup[i] / sumCount
if temp_sup >= min_support:
relist.append(i)
# 此处可设置返回全部的支持度数据(或者频繁项集的支持度数据)
supportData[i] = temp_sup
return relist, supportData
# 改进剪枝算法
def aprioriGen(Lk, k):
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i + 1, lenLk): # 两两组合遍历
L1 = list(Lk[i])[:k - 2]
L2 = list(Lk[j])[:k - 2]
L1.sort()
L2.sort()
if L1 == L2: # 前k-1项相等,则可相乘,这样可防止重复项出现
# 进行剪枝(a1为k项集中的一个元素,b为它的所有k-1项子集)
a = Lk[i] | Lk[j] # a为frozenset()集合
a1 = list(a)
b = []
# 遍历取出每一个元素,转换为set,依次从a1中剔除该元素,并加入到b中
for q in range(len(a1)):
t = [a1[q]]
tt = frozenset(set(a1) - set(t))
b.append(tt)
t = 0
for w in b:
# 当b(即所有k-1项子集)都是Lk(频繁的)的子集,则保留,否则删除。
if w in Lk:
t += 1
if t == len(b):
retList.append(b[0] | b[1])
return retList
def apriori(dataSet, minSupport=0.2):
# 前3条语句是对计算查找单个元素中的频繁项集
C1 = createC1(dataSet)
D = list(map(set, dataSet)) # 使用list()转换为列表
L1, supportData = calSupport(D, C1, minSupport)
L = [L1] # 加列表框,使得1项集为一个单独元素
k = 2
while (len(L[k - 2]) > 0): # 是否还有候选集
Ck = aprioriGen(L[k - 2], k)
Lk, supK = scanD(D, Ck, minSupport) # scan DB to get Lk
supportData.update(supK) # 把supk的键值对添加到supportData里
L.append(Lk) # L最后一个值为空集
k += 1
del L[-1] # 删除最后一个空集
return L, supportData # L为频繁项集,为一个列表,1,2,3项集分别为一个元素
# 生成集合的所有子集
def getSubset(fromList, toList):
for i in range(len(fromList)):
t = [fromList[i]]
tt = frozenset(set(fromList) - set(t))
if not tt in toList:
toList.append(tt)
tt = list(tt)
if len(tt) > 1:
getSubset(tt, toList)
def calcConf(freqSet, H, supportData, ruleList, minConf=0.7):
for conseq in H: #遍历H中的所有项集并计算它们的可信度值
conf = supportData[freqSet] / supportData[freqSet - conseq] # 可信度计算,结合支持度数据
# 提升度lift计算lift = p(a & b) / p(a)*p(b)
lift = supportData[freqSet] / (supportData[conseq] * supportData[freqSet - conseq])
if conf >= minConf and lift > 1:
print(freqSet - conseq, '-->', conseq, '支持度', round(supportData[freqSet], 6), '置信度:', round(conf, 6),
'lift值为:', round(lift, 6))
ruleList.append((freqSet - conseq, conseq, conf))
# 生成规则
def gen_rule(L, supportData, minConf = 0.7):
bigRuleList = []
for i in range(1, len(L)): # 从二项集开始计算
for freqSet in L[i]: # freqSet为所有的k项集
# 求该三项集的所有非空子集,1项集,2项集,直到k-1项集,用H1表示,为list类型,里面为frozenset类型,
H1 = list(freqSet)
all_subset = []
getSubset(H1, all_subset) # 生成所有的子集
calcConf(freqSet, all_subset, supportData, bigRuleList, minConf)
return bigRuleList
if __name__ == '__main__':
dataSet = data_translation
L, supportData = apriori(dataSet, minSupport = 0.02)
rule = gen_rule(L, supportData, minConf = 0.35)
结果如下
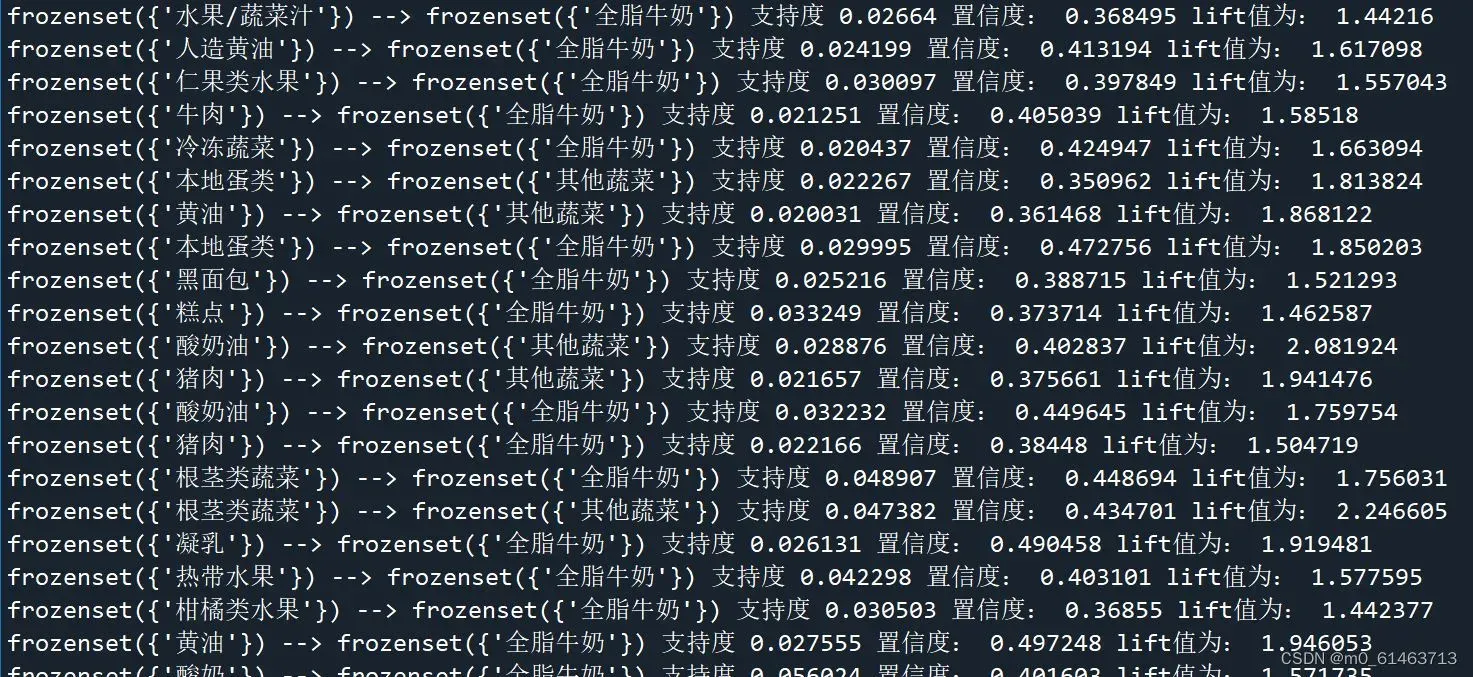
以 frozenset({‘水果/蔬菜汁’}) –> frozenset({‘全脂牛奶’}) 支持度为0.02664 置信度:0.368495 life值为:1.44216 为例可得:顾客同时购买水果、蔬菜汁和全脂牛奶这3种商品的概率约为36.85%,而这种情况发生的可能性约为2.66%
综合分析可得顾客同时购买其他蔬菜、根茎类蔬菜和全脂牛奶的概率较高。
文章出处登录后可见!