前言
随着ChatGPT的爆火,AIGC(人工智能生成内容)再一次走到人们眼前。尤其是在文本、图像生成领域,通过GPT-4、Midjourney等应用生成各种令人惊叹定的文本和图片。

但 AI 在生成方面的能力,可远非如此如此。
我用长约一个小时的音频数据,训练了一个 AI 音色转换模型,生成了这首歌曲,效果如下所示,大家可以在评论区留言猜猜是谁?
小半-AI合成
视频里所使用的技术是 so-vits-svc,是音频转音频,属于音色转换算法,支持正常的说话,也支持歌声的音色转换。下面具体介绍如何使用so-vits-svc。
一、准备工作
训练数据很关键,越多高质量的音频数据,效果越好,建议至少准备一个小时以上的音频。
显卡建议使用 N 卡,且显存 8G 以上。
我将项目所需要的代码、工具整理了出来,如有需要可以在评论区留言或者通过下方链接联系我。
当然,也可以直接用开源代码直接部署,地址如下:
GitHub – svc-develop-team/so-vits-svc: SoftVC VITS Singing Voice Conversion
二、环境安装
1.安装pytorch深度学习框架
需要安装pytorch, torchaudio, torchvision三个库
参考我之前写的https://yunlord.blog.csdn.net/article/details/129812705?spm=1001.2014.3001.5502
2.安装相关依赖
可以看到下载的项目中包含两个requirements.txt,以windows为例:
进入到项目中,通过prompt输入以下指令:
pip install -r requirements_win.txt三、数据处理
训练音频、还有需要预测(或者说转换)的音频,都必须是人物的干声。换句话说,音频中不能包含背景音、伴奏、合声等,所以无论是训练和预测,都需要对数据进行处理。
1.提取人声
我们可以通过UVR5 这个软件实现伴奏与人声分离。
在 Windows 下可以直接使用,打开软件,按照如下配置:
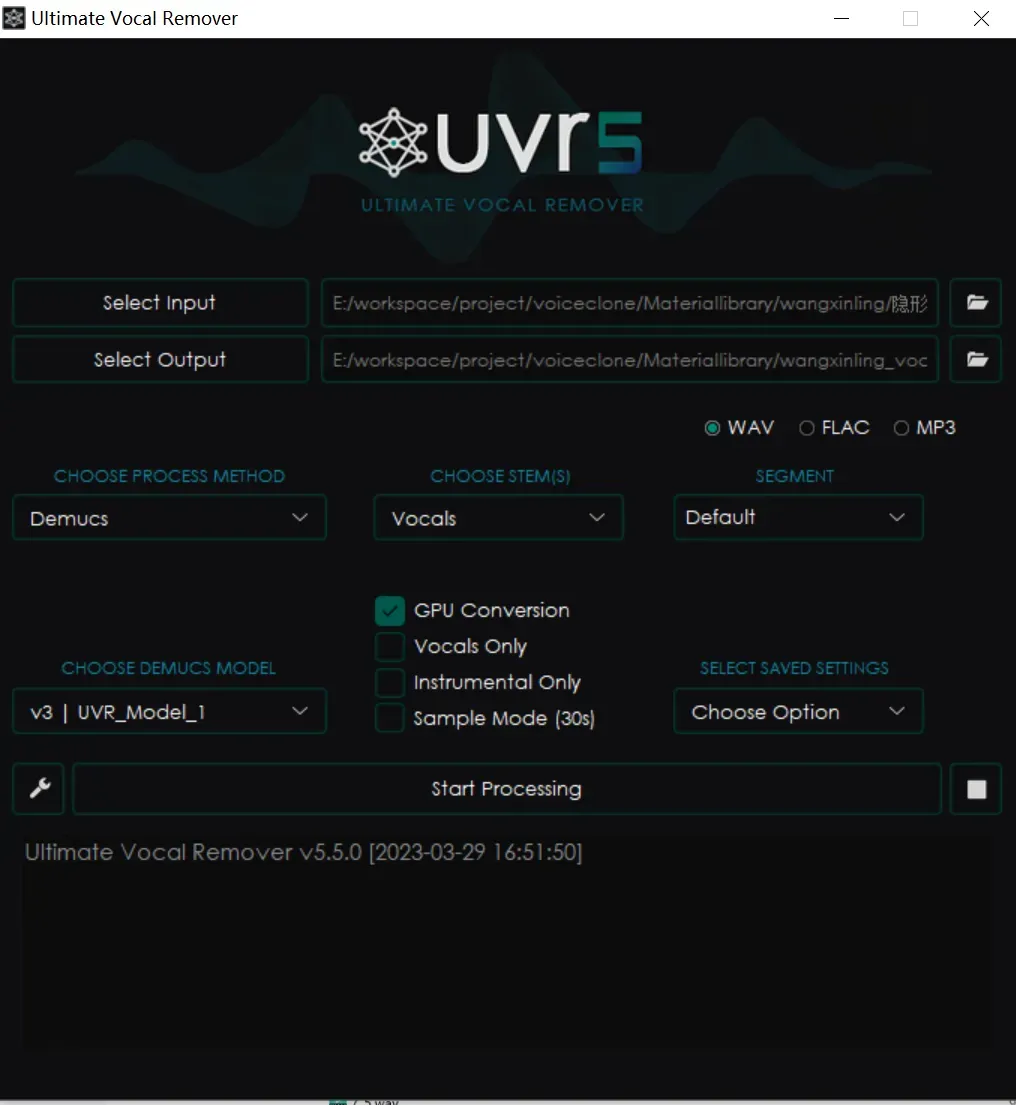
运行即可分离人声和伴奏。
然后再按照如下配置,去除合声:
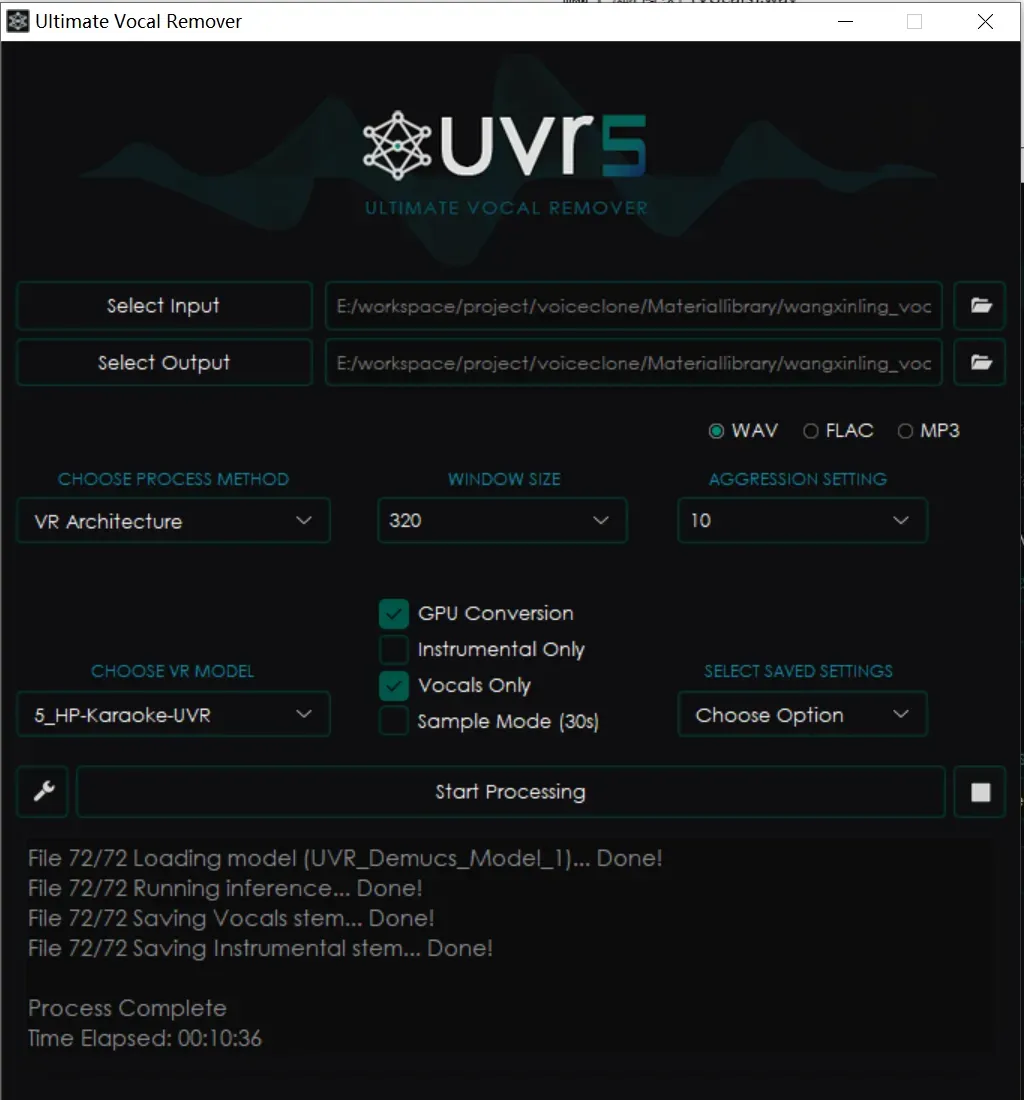
经过提取出的干净人声音频就可以用来训练。
2.切割音频
不过因为音频太长,不要超过三十秒,很容易爆显存,需要对音频文件进行切片。
我们通过 Audio Slicer这个工具实现音频切分 。
直接运行 slicer-gui.exe。
填写输入路径,填写输出路径,其它参数都默认即可,这样就会得到切分好的音频段。
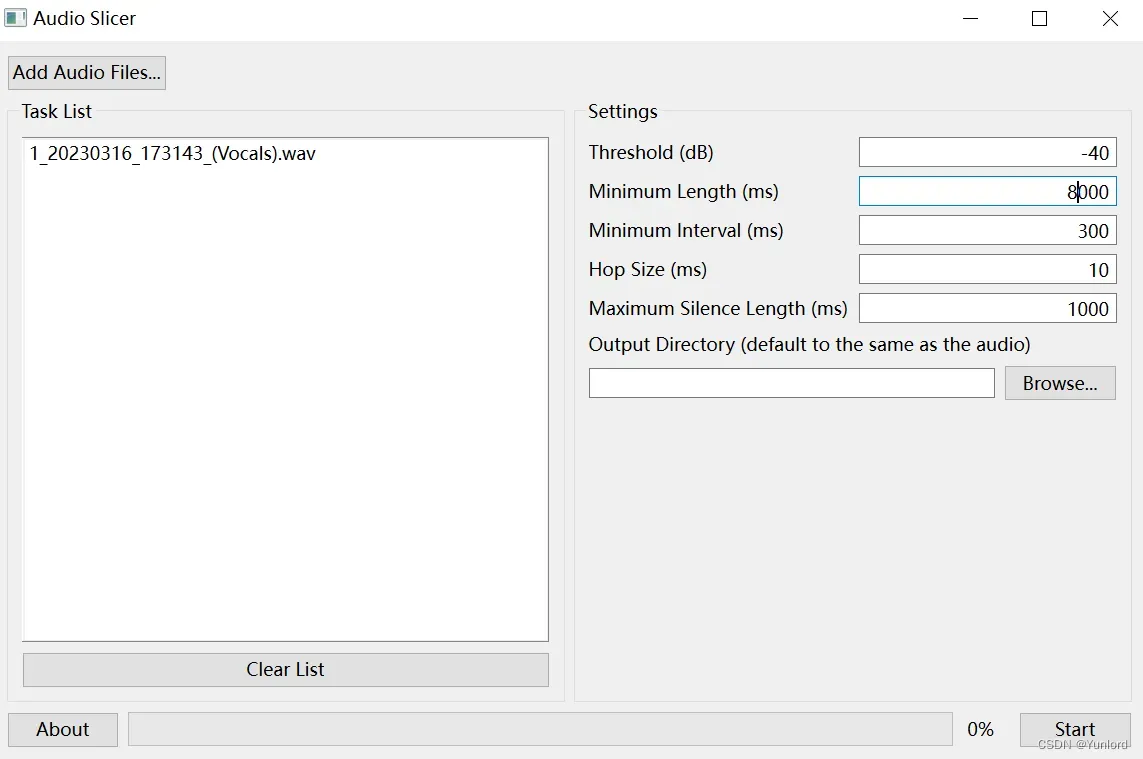
建议切完之后逐段听下,将效果不好的删除,高质量的音频比数量多的效果更好。并且如果还有时长超过30s的可以通过写的python音频切割代码,进行截切。
在项目的 so-vits-svc-4.0/dataset_raw 目录下创建一个文件夹,比如我的是 wang_processed,将处理好的数据放到里面。
四、训练模型
在训练模型前,我们需要下好原始模型,并将其放到对应位置
将checkpoint_best_legacy_500.pt放入hubert文件夹下将D_0.pth和G_0.pth放入logs/44k目录下
1.数据预处理
接下来可以直接运行项目里面的1.数据预处理.bat。
这个脚本就是按照步骤,运行各个 py 脚本:
(1) 重采样至44100Hz单声道
python resample.py(2)自动划分训练集、验证集,以及自动生成配置文件
python preprocess_flist_config.py(3)生成hubert与f0
python preprocess_hubert_f0.py处理完毕后,会在 datset/44k 下生成一个文件夹,里面的数据如下图所示:
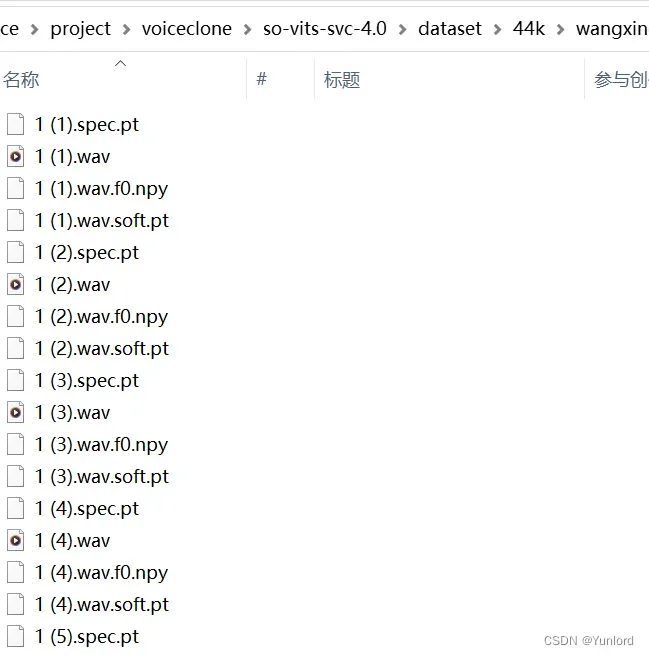
可以删除 dataset_raw 文件夹了。
2.模型训练
直接运行项目中的2.训练.bat 即可开启训练。
python train.py -c configs/config.json -m 44k如果显卡够好,可以增加 batch_size 提高训练速度,对应的配置文件在 configs/config.json 文件里。
这个训练时间很长,个人觉得如果数据较好的话,训练到30000轮以上就有一个不错的效果。
3.聚类模型训练
直接运行项目中的3.训练聚类模型.bat 即可开启训练,这个比较快,几分钟即可跑完。
这个主要是可以减小音色泄漏,使得模型训练出来更像目标的音色(但其实不是特别明显),但是单纯的聚类方案会降低模型的咬字(会口齿不清)(这个很明显),本模型采用了融合的方式,可以线性控制聚类方案与非聚类方案的占比,也就是可以手动在”像目标音色” 和 “咬字清晰” 之间调整比例,找到合适的折中点。
使用聚类前面的已有步骤不用进行任何的变动,只需要额外训练一个聚类模型,虽然效果比较有限,但训练成本也比较低。
- 训练过程:
- 执行
python cluster/train_cluster.py,模型的输出会在logs/44k/kmeans_10000.pt
- 执行
- 推理过程:
inference_main.py中指定cluster_model_pathinference_main.py中指定cluster_infer_ratio,0为完全不使用聚类,1为只使用聚类,通常设置0.5即可
4.推理预测
(1)准备干声
准备一首歌的干声,干声可以按上述音频素材准备那样处理,通过UVR5提取一段不超过90s的干声素材。
(2)修改模型名
修改 app.py 里的这一行:
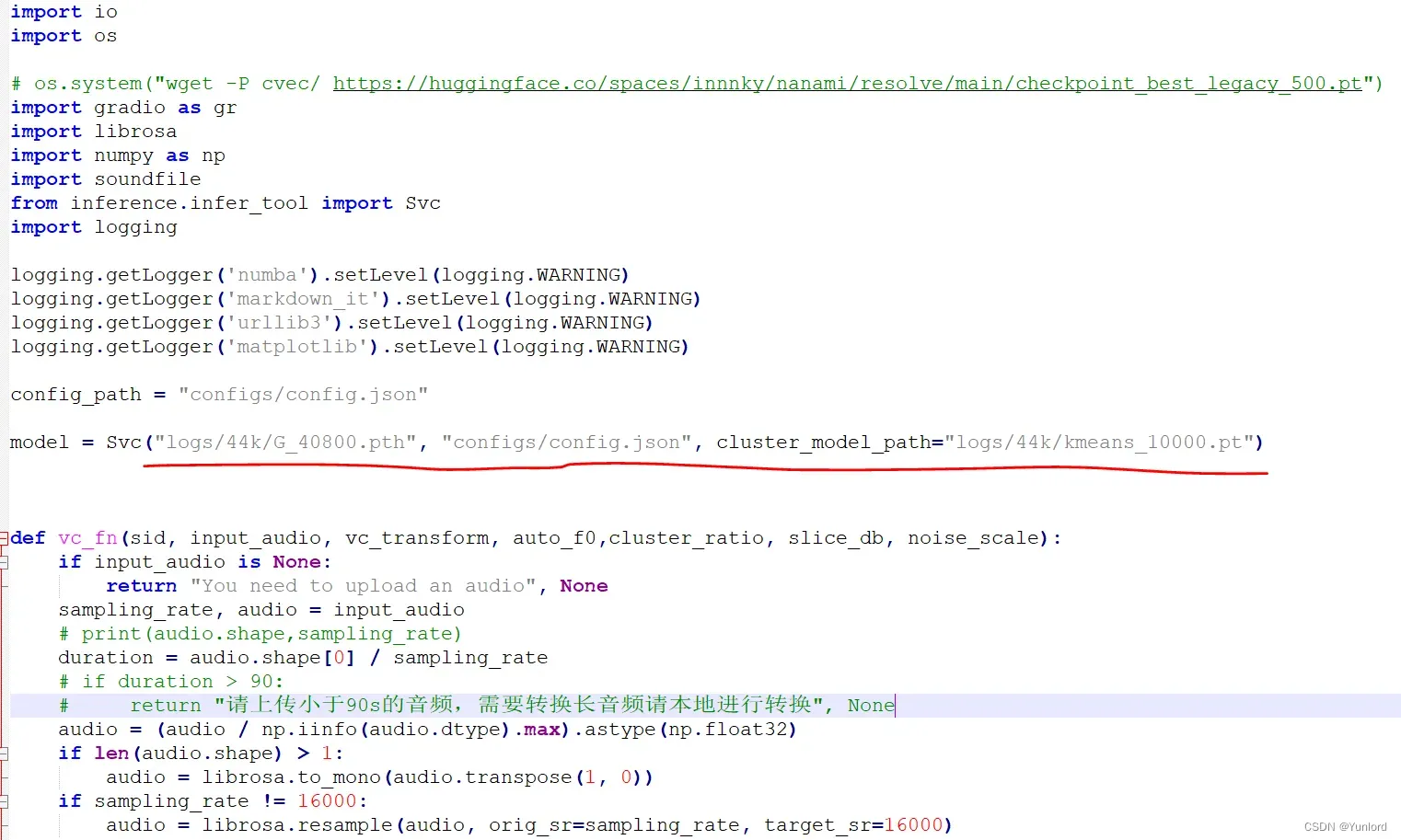
训练好的模型存放在了 logs/44k 目录下,这里改为训练好的模型地址,以及对应的配置文件,最后是第三步生成的 pt 文件路径。
(3)运行web
直接运行项目中的4.推理预测.bat。
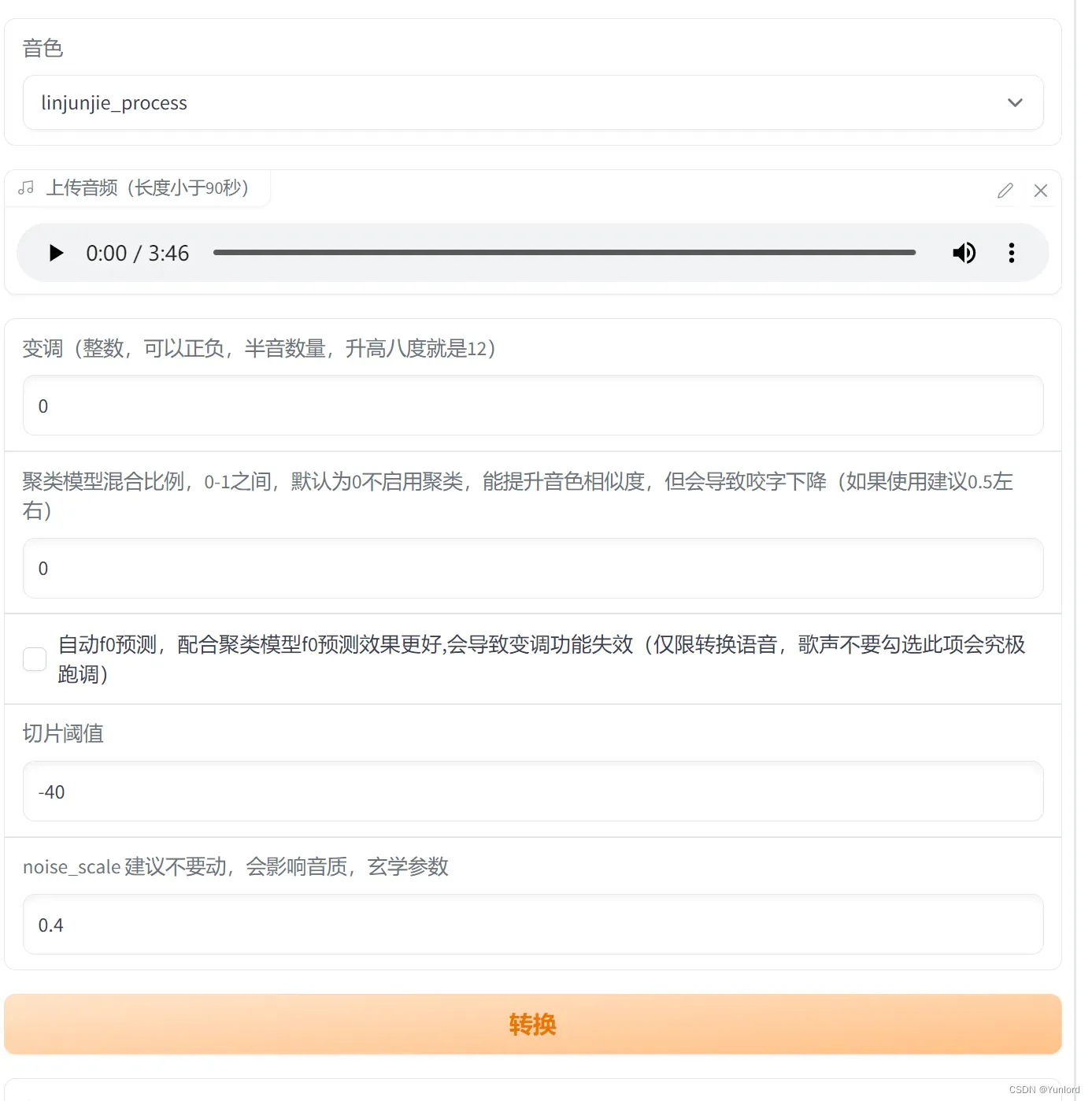
程序会直接开启一个 webui,将开启的 url,直接复制到浏览器地址栏中打开即可。
就是一个简单的 Web 页面,里面的参数,可以直接使用默认的,放入一个音频,即可转换音色。
总结
勿用技术做恶,这个必须强调来说。本教程仅供交流学习使用。
随着AI技术的不断发展,各种难以想象的事情AI都能够做到,我们能做到的就是规范技术发展,用AI做一些对社会有益的事情。
欢迎大家在评论区留言猜猜是谁?
参考:
1.AI声音克隆教程 – 哔哩哔哩
2.so-vits-svc3.0 中文详细安装、训练、推理使用教程_Sucial的博客-CSDN博客
3.so-vits-svc/README_zh_CN.md at 4.0 · svc-develop-team/so-vits-svc · GitHub
文章出处登录后可见!