
一、框架介绍
**LangChain是何方神圣?**远的不说,我们就拿当下火热的项目Auto-GPT来说,该项目集成了:自动推理、联网搜索、LLM推理。那么现在好了,你可能会好奇他是怎么做到的!那么告诉你LangChain这个框架可以帮你从零到一实现一个比Auto-GPT还要强大的产品!
**难道你还不心动吗!**😍

先看一段来自官方的解释:
LangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。
讲点大白话就是:
LangChain正如他的名字所言,他就是一个链条工具,作为一个功能连接性框架,它允许你将LLM(Large Language Model)大语言模型和行业中的各类软件的能力结合在一起,进一步扩宽AI大模型的使用场景和能力边界。
正如其官网介绍所说:
一个强大的应用程序,我们不能只是满足于简单地语言模型API的调用,我们应该好好利用大模型的API去让他变得为数据服务、变得更智能的为我们的日常使用的交互服务!
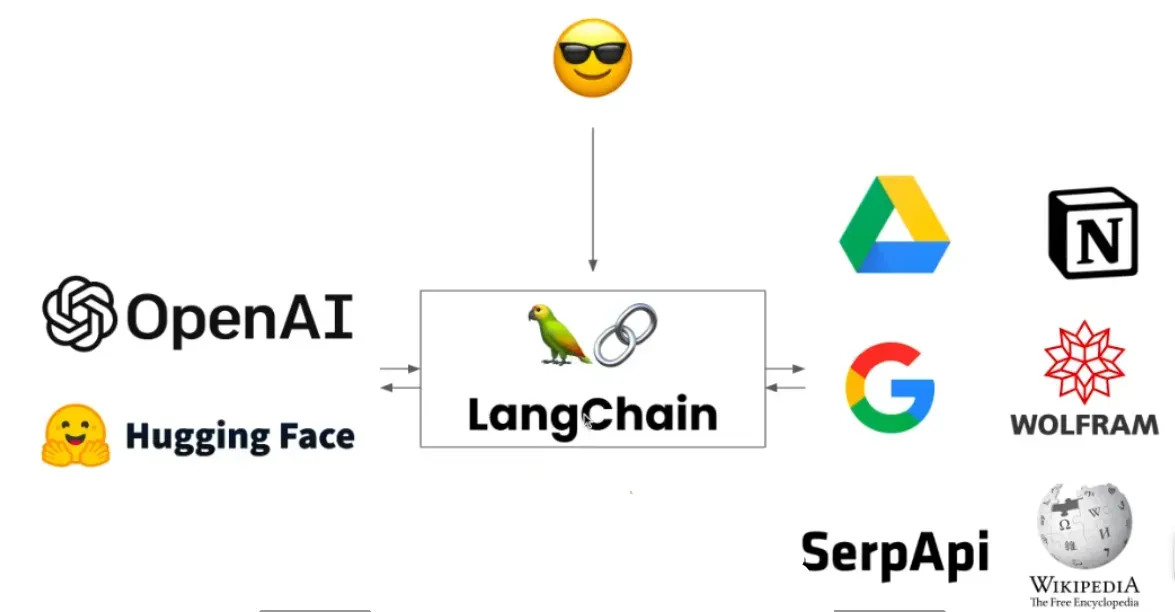
官方文档:LangChain 功能详细介绍文档
二、LangChain功能案例
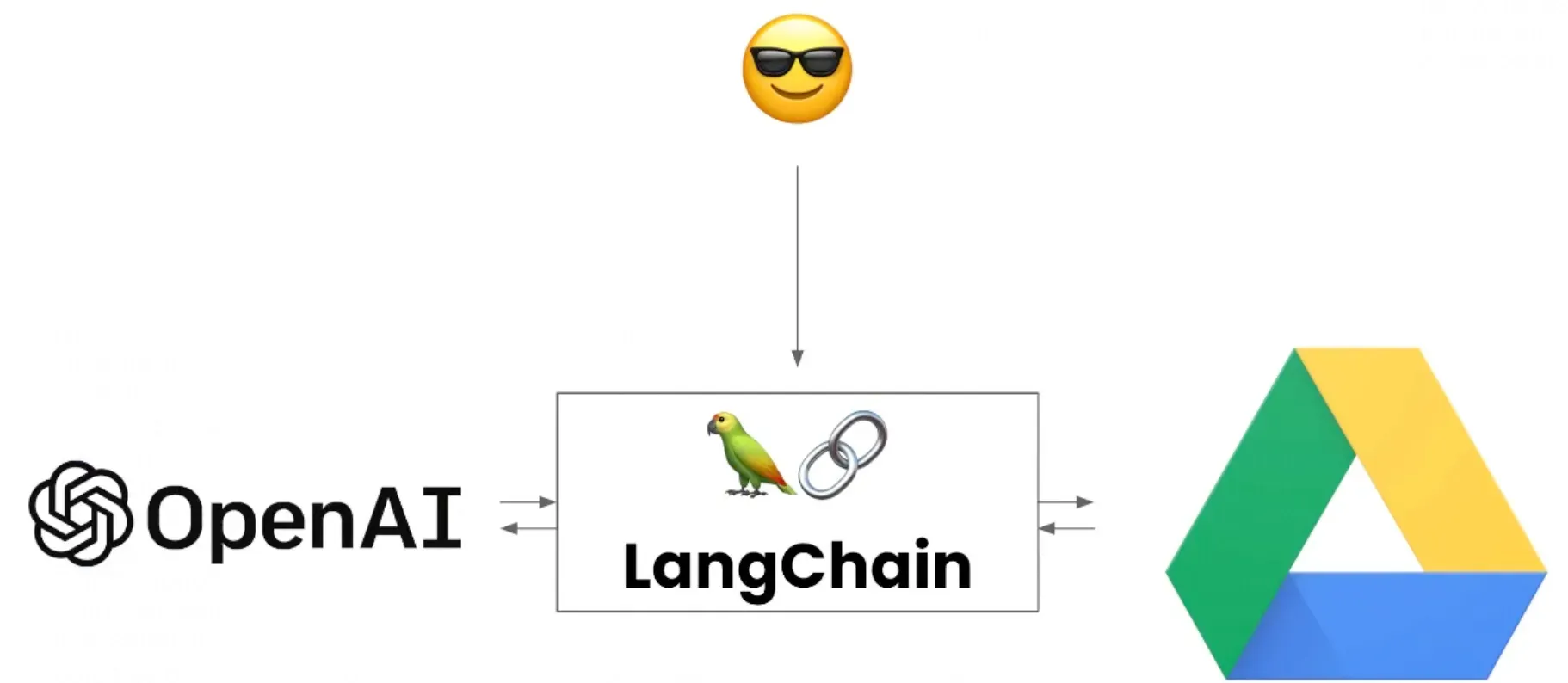
2.1 读取谷歌网盘文件
通过LangChain连接谷歌Driver,实现文件内容的读取和总结。
我们只需要在LangChain中输入“提取云盘中的某个文件内容的命令”,其即可帮助我们自动阅读文件并总结!
调用代码:
from langchain.document_loaders import GoogleDriveLoader
import os
from langchain.llms import OpenAI
from langchain.chains.summarize import load_summarize_chain
loader = GoogleDriveLoader(document_ids=["1BT5apJMTUvG9_59-ceHbuZXVTJKeyyknQsz9ZNIEwQ8"],
credentials_path="../../desktop_credetnaisl.json")
docs = loader.load()
# %set_env OPENAI_API_KEY = ... // 设置你的OpenAI Key为环境变量,供模型调用
llm = OpenAI(temperature=0, openai_api_key=os.environ['OPENAI_API_KEY'])
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=True)
chain.run(docs)
2.2 总结YouTuBe视频
LangChain支持对YouTube视频内容进行摘要内容生成,通过调用
document_loaders模块中的YoutubeLoader,同时传入YouTube的视频链接,然后即可支持视频内容的摘要提取。
调用代码:
from langchain.document_loaders import YoutubeLoader
from langchain.llms import OpenAI
from langchain.chains.summarize import load_summarize_chain
OPENAI_API_KEY = '...'
loader = YoutubeLoader.from_youtube_url("https://www.youtube.com/watch?v=QsYGlZkevEg", add_video_info=True)
result = loader.load()
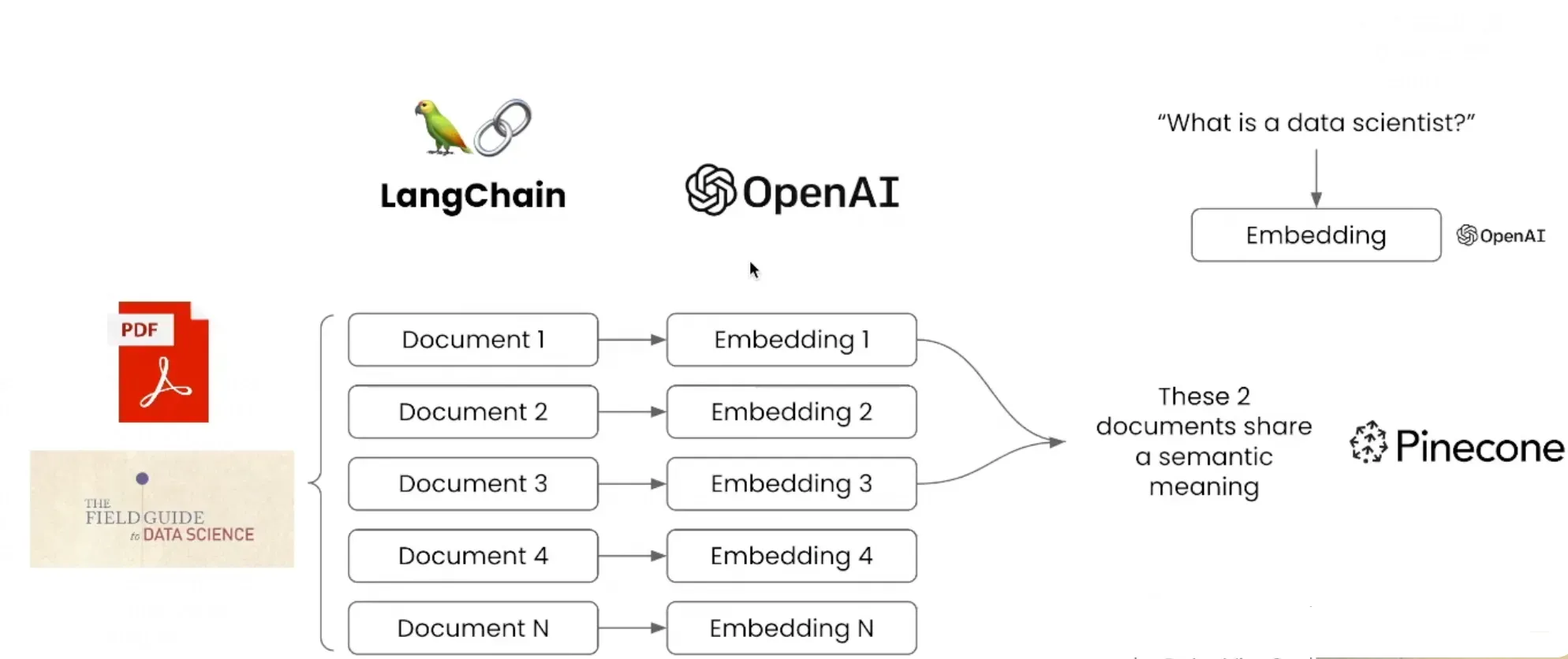
3.3 实现PDF文件语义搜索
LangChain在面对非机构化数据时,通过借助
Embedding的能力,对PDF文件数据进行向量化,LangChain在此基础上允许用户将输入的数据与PDF中的数据进行语义匹配,从而实现用户在PDF文件中的内容搜索。
调用代码:
from langchain.document_loaders import UnstructuredPDFLoader, OnlinePDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
oader = UnstructuredPDFLoader("../data/field-guide-to-data-science.pdf")
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(data)
# Create embeddings of your documents to get ready for semantic search
from langchain.vectorstores import Chroma, Pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
import pinecone
OPENAI_API_KEY = '...'
PINECONE_API_KEY = '...'
PINECONE_API_ENV = 'us-east1-gcp'
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
# initialize pinecone
pinecone.init(
api_key=PINECONE_API_KEY, # find at app.pinecone.io
environment=PINECONE_API_ENV # next to api key in console
)
index_name = "langchaintest" # put in the name of your pinecone index here
docsearch = Pinecone.from_texts([t.page_content for t in texts], embeddings, index_name=index_name)
query = "What are examples of good data science teams?"
docs = docsearch.similarity_search(query, include_metadata=True)
#. Query those docs to get your answer back
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chain
llm = OpenAI(temperature=0, openai_api_key=OPENAI_API_KEY)
chain = load_qa_chain(llm, chain_type="stuff")
query = "What is the collect stage of data maturity?"
docs = docsearch.similarity_search(query, include_metadata=True)
chain.run(input_documents=docs, question=query)
#. OUTPUT: ' The collect stage of data maturity focuses on collecting internal or external datasets. Examples include gathering sales records and corresponding weather data.'
三、模块介绍
3.1 模型集成
3.1.1 集成后的附加功能
(1)如何将自定义的LLM 包装到LangChain?
自定义LLM只需要实现一件必需的事情:
- 一个
_call 方法,它接受一个字符串、一些可选的非索引字,并返回一个字符串- 一个
_identifying_params 属性,用于帮助打印此类。应该返回字典。
自定义CustomLLM代码:
from typing import Any, List, Mapping, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun
from langchain.llms.base import LLM
class CustomLLM(LLM):
n: int
@property
def _llm_type(self) -> str:
return "custom"
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
) -> str:
if stop is not None:
raise ValueError("stop kwargs are not permitted.")
return prompt[:self.n]
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {"n": self.n}
llm = CustomLLM(n=10)
llm("This is a foobar thing")
(2)如何实现LLM的流式效果?
LangChain在支持代理封装ChatGPT接口的基础上,也同样地把ChatGPT API接口的流式数据返回集成了进来。具体实现如下:
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI, ChatAnthropic
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.schema import HumanMessage
llm = OpenAI(streaming=True, callbacks=[StreamingStdOutCallbackHandler()], temperature=0)
resp = llm("Write me a song about sparkling water.")
(3)如何缓存LLM的数据返回?
因为调用ChatGPT的API接口往往会存在网络延时的情况,为了更优雅的实现LLM语言生成模型,LangChain同时提供了数据缓存的接口如果用户问了同样的问题,LangChain支持直接将所缓存的数据直接响应!
import langchain
from langchain.cache import InMemoryCache
langchain.llm_cache = InMemoryCache()
# To make the caching really obvious, lets use a slower model.
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2)
(4)如何实现LLM的数据异步返回?
在我们构建复杂的LLM模型调用链的过程中,往往存在接口的多次调用,而且很多时候我们并不能保证接口的实时性返回,这个时候我们可以使用接口异步返回的模型来提升功能的服务质量!进而提升系统的性能!
import time
import asyncio
from langchain.llms import OpenAI
def generate_serially():
llm = OpenAI(temperature=0.9)
for _ in range(10):
resp = llm.generate(["Hello, how are you?"])
print(resp.generations[0][0].text)
async def async_generate(llm):
resp = await llm.agenerate(["Hello, how are you?"])
print(resp.generations[0][0].text)
async def generate_concurrently():
llm = OpenAI(temperature=0.9)
tasks = [async_generate(llm) for _ in range(10)]
await asyncio.gather(*tasks)
s = time.perf_counter()
# If running this outside of Jupyter, use asyncio.run(generate_concurrently())
await generate_concurrently()
elapsed = time.perf_counter() - s
print('\033[1m' + f"Concurrent executed in {elapsed:0.2f} seconds." + '\033[0m')
s = time.perf_counter()
generate_serially()
elapsed = time.perf_counter() - s
print('\033[1m' + f"Serial executed in {elapsed:0.2f} seconds." + '\033[0m')
3.1.2 整合多个模型
作为LangChain中的核心模块,LangChain不止支持简单的LLM,它从简单的文本生成功能、会话聊天功能以及文本向量化功能均集成,并且将其封装成一个一个的链条节点!
由于本文篇幅有限,这里只是列举几个时下流行的LLM。详细内容可以参考官网文档。
(1)大语言模型
1️⃣ Open AI
import os
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
from langchain.llms import OpenAI
from langchain import PromptTemplate, LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm = OpenAI()
llm_chain = LLMChain(prompt=prompt, llm=llm)
question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
llm_chain.run(question)
2️⃣ Azure OpenAI
import os
os.environ["OPENAI_API_TYPE"] = "azure"
os.environ["OPENAI_API_VERSION"] = "2022-12-01"
os.environ["OPENAI_API_BASE"] = "..."
os.environ["OPENAI_API_KEY"] = "..."
# Import Azure OpenAI
from langchain.llms import AzureOpenAI
# Create an instance of Azure OpenAI
# Replace the deployment name with your own
llm = AzureOpenAI(
deployment_name="td2",
model_name="text-davinci-002",
)
# Run the LLM
llm("Tell me a joke")
3️⃣ Hugging Face Hub
import os
os.environ["HUGGINGFACEHUB_API_TOKEN"] = HUGGINGFACEHUB_API_TOKEN
from langchain import HuggingFaceHub
repo_id = "google/flan-t5-xl" # See https://huggingface.co/models?pipeline_tag=text-generation&sort=downloads for some other options
llm = HuggingFaceHub(repo_id=repo_id, model_kwargs={"temperature":0, "max_length":64})
from langchain import PromptTemplate, LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm_chain = LLMChain(prompt=prompt, llm=llm)
question = "Who won the FIFA World Cup in the year 1994? "
print(llm_chain.run(question))
(2)聊天模型
这一块主要介绍OpenAI所提供的多角色聊天,他允许用户设定信息归属不同的角色,从而丰富用户的聊天背景,构造出更加拟人化的聊天效果!
1️⃣ 使用 Open AI 进行聊天角色内容的预设
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
chat = ChatOpenAI(temperature=0)
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="Translate this sentence from English to French. I love programming.")
]
chat(messages)
2️⃣ 对Open AI的聊天记录通过模版化编排
template="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
# get a chat completion from the formatted messages
chat(chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_messages())
(3)语言向量化模型
向量化技术是自然语言处理中的基石,我们要让计算机能够读懂并理解人类的自然语言,特别是掌握其中的语义及语气,将文本内容进行向量化转化为向量,通过向量的空间运算从而使得计算机能够理解和处理我们的自然语言,这一技术就是Embbeding
LangChain为了进一步方便模型的内容计算和存储,同时引入了向量化技术。
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
3.2 提示词模型
对于语言模型来说,我们所投入的训练的语料以及后续引导模型进行训练的引导语是生成准确回复的基础!
提示模板是指生成提示的可重现方式。它包含一个文本字符串(“模板”),可以从最终用户那里获取一组参数并生成提示。
3.2.1 Template 的类型
1️⃣ PromptTemplate
from langchain import PromptTemplate
# An example prompt with no input variables
no_input_prompt = PromptTemplate(input_variables=[], template="Tell me a joke.")
no_input_prompt.format()
# -> "Tell me a joke."
# An example prompt with one input variable
one_input_prompt = PromptTemplate(input_variables=["adjective"], template="Tell me a {adjective} joke.")
one_input_prompt.format(adjective="funny")
# -> "Tell me a funny joke."
# An example prompt with multiple input variables
multiple_input_prompt = PromptTemplate(
input_variables=["adjective", "content"],
template="Tell me a {adjective} joke about {content}."
)
multiple_input_prompt.format(adjective="funny", content="chickens")
# -> "Tell me a funny joke about chickens."
2️⃣ FewShot PromptTemplate
在我们所建立的语料内容基础上,模板可以根据语料库中的内容进行匹配,最终可按照特定的格式匹配出样例中的内容。
from langchain.prompts.few_shot import FewShotPromptTemplate
from langchain.prompts.prompt import PromptTemplate
examples = [
{
"question": "Who lived longer, Muhammad Ali or Alan Turing?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
"""
},
{
"question": "When was the founder of craigslist born?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who was the founder of craigslist?
Intermediate answer: Craigslist was founded by Craig Newmark.
Follow up: When was Craig Newmark born?
Intermediate answer: Craig Newmark was born on December 6, 1952.
So the final answer is: December 6, 1952
"""
},
{
"question": "Who was the maternal grandfather of George Washington?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who was the mother of George Washington?
Intermediate answer: The mother of George Washington was Mary Ball Washington.
Follow up: Who was the father of Mary Ball Washington?
Intermediate answer: The father of Mary Ball Washington was Joseph Ball.
So the final answer is: Joseph Ball
"""
},
{
"question": "Are both the directors of Jaws and Casino Royale from the same country?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who is the director of Jaws?
Intermediate Answer: The director of Jaws is Steven Spielberg.
Follow up: Where is Steven Spielberg from?
Intermediate Answer: The United States.
Follow up: Who is the director of Casino Royale?
Intermediate Answer: The director of Casino Royale is Martin Campbell.
Follow up: Where is Martin Campbell from?
Intermediate Answer: New Zealand.
So the final answer is: No
"""
}
]
example_prompt = PromptTemplate(input_variables=["question", "answer"], template="Question: {question}\n{answer}")
print(example_prompt.format(**examples[0]))
=========================
Question: Who lived longer, Muhammad Ali or Alan Turing?
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
3️⃣ Partial PromptTemplate
3.2.2 Template的自定义与使用
LangChain 提供了一组默认的提示模板,可用于为各种任务生成提示。但是,在某些情况下,默认提示模板可能无法满足您的需求。例如,您可能希望创建一个提示模板,其中包含语言模型的特定动态说明。在这种情况下,您可以创建自定义提示模板。
我们将创建一个自定义提示模板,该模板将函数名称作为输入,并设置提示格式以提供函数的源代码。为了实现这一点,让我们首先创建一个函数,该函数将返回给定其名称的函数的源代码。
import inspect
def get_source_code(function_name):
# Get the source code of the function
return inspect.getsource(function_name)
from langchain.prompts import StringPromptTemplate
from pydantic import BaseModel, validator
class FunctionExplainerPromptTemplate(StringPromptTemplate, BaseModel):
""" A custom prompt template that takes in the function name as input, and formats the prompt template to provide the source code of the function. """
@validator("input_variables")
def validate_input_variables(cls, v):
""" Validate that the input variables are correct. """
if len(v) != 1 or "function_name" not in v:
raise ValueError("function_name must be the only input_variable.")
return v
def format(self, **kwargs) -> str:
# Get the source code of the function
source_code = get_source_code(kwargs["function_name"])
# Generate the prompt to be sent to the language model
prompt = f"""
Given the function name and source code, generate an English language explanation of the function.
Function Name: {kwargs["function_name"].__name__}
Source Code:
{source_code}
Explanation:
"""
return prompt
def _prompt_type(self):
return "function-explainer"
fn_explainer = FunctionExplainerPromptTemplate(input_variables=["function_name"])
# Generate a prompt for the function "get_source_code"
prompt = fn_explainer.format(function_name=get_source_code)
print(prompt)
======================================================
OutPut:
Given the function name and source code, generate an English language explanation of the function.
Function Name: get_source_code
Source Code:
def get_source_code(function_name):
# Get the source code of the function
return inspect.getsource(function_name)
Explanation:
======================================================
3.2.3 输出解析器
1️⃣ 格式化普通文本交互
语言模型输出文本。但很多时候,您可能希望获得更结构化的信息,而不仅仅是文本回复。这就是输出解析器的用武之地。
按照自定义的数据格式数据数据
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
response_schemas = [
ResponseSchema(name="answer", description="answer to the user's question"),
ResponseSchema(name="source", description="source used to answer the user's question, should be a website.")
]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
prompt = PromptTemplate(
template="answer the users question as best as possible.\n{format_instructions}\n{question}",
input_variables=["question"],
partial_variables={"format_instructions": format_instructions}
)
model = OpenAI(temperature=0)
_input = prompt.format_prompt(question="what's the capital of france")
output = model(_input.to_string())
output_parser.parse(output)
2️⃣ 格式化Chat模型文本交互
chat_model = ChatOpenAI(temperature=0)
prompt = ChatPromptTemplate(
messages=[
HumanMessagePromptTemplate.from_template("answer the users question as best as possible.\n{format_instructions}\n{question}")
],
input_variables=["question"],
partial_variables={"format_instructions": format_instructions}
)
_input = prompt.format_prompt(question="what's the capital of france")
output = chat_model(_input.to_messages())
output_parser.parse(output.content)
========================
{'answer': 'Paris', 'source': 'https://en.wikipedia.org/wiki/Paris'}
3.3 数据索引
索引是指构建文档的方法,以便LLM可以最好地与它们交互。此模块包含用于处理文档的实用程序函数、不同类型的索引,以及在链中使用这些索引的示例。
3.3.1数据源加载
🎨 加载B站(BiliBili)视频数据
#!pip install bilibili-api
from langchain.document_loaders.bilibili import BiliBiliLoader
loader = BiliBiliLoader(
["https://www.bilibili.com/video/BV1xt411o7Xu/"]
)
loader.load()
🎨 加载CSV数据
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv')
data = loader.load()
🎨 加载Email数据
#!pip install unstructured
from langchain.document_loaders import UnstructuredEmailLoader
loader = UnstructuredEmailLoader('example_data/fake-email.eml')
data = loader.load()
🎨 加载电子书Epub数据
#!pip install pandocs
from langchain.document_loaders import UnstructuredEPubLoader
loader = UnstructuredEPubLoader("winter-sports.epub", mode="elements")
data = loader.load()
🎨 加载Git数据
!pip install GitPython
from git import Repo
repo = Repo.clone_from(
"https://github.com/hwchase17/langchain", to_path="./example_data/test_repo1"
)
branch = repo.head.reference
from langchain.document_loaders import GitLoader
loader = GitLoader(repo_path="./example_data/test_repo1/", branch=branch)
data = loader.load()
🎨 加载HTML数据
from langchain.document_loaders import UnstructuredHTMLLoader
loader = UnstructuredHTMLLoader("example_data/fake-content.html")
data = loader.load()
🎨 加载Image图片数据
#!pip install pdfminer
from langchain.document_loaders.image import UnstructuredImageLoader
loader = UnstructuredImageLoader("layout-parser-paper-fast.jpg")
data = loader.load()
🎨 加载Word文档数据
from langchain.document_loaders import Docx2txtLoader
loader = Docx2txtLoader("example_data/fake.docx")
data = loader.load()
========================
[Document(page_content='Lorem ipsum dolor sit amet.', metadata={'source': 'example_data/fake.docx'})]
🎨 加载PDF文件数据
!pip install pypdf
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
pages[0]
3.3.2 字符文本拆分器
默认推荐的文本拆分器是 RecursiveCharacterTextSplitter。此文本拆分器采用字符列表。它尝试基于第一个字符的拆分来创建块,但如果任何块太大,它就会移动到下一个字符,依此类推。默认情况下,它尝试拆分的字符是 ["\n\n", "\n", " ", ""]
除了控制可以拆分的角色之外,你还可以控制其他一些东西:
-
length_function :如何计算块的长度。默认只计算字符数,但在此处传递令牌计数器是很常见的。
-
chunk_size :块的最大大小(由长度函数测量)。
-
chunk_overlap :块之间的最大重叠。有一些重叠以保持块之间的一些连续性(例如做一个滑动窗口)可能会很好。
👑 HugginFace 普通文本拆分器
字符文本拆分器的作用在于:解决各大LLM模型对于单次会话中的Token限制!
- 其中特别要注意的是,对于即将要传递给模型的文本内容而言,字符文本的数量和LLM模型所限制的Token数量并不是一一对等的,而若只是通过人工的计算和拆分这是不现实的,所以我们可以将HuggingFace中的Transform模型的Token计算功能实现文本的拆分。
from transformers import GPT2TokenizerFast
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
# This is a long document we can split up.
with open('../../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_huggingface_tokenizer(tokenizer, chunk_size=100, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
👑 MarkDown 文本拆分器
from langchain.text_splitter import MarkdownTextSplitter
markdown_text = """
# 🦜️🔗 LangChain
⚡ Building applications with LLMs through composability ⚡
## Quick Install
As an open source project in a rapidly developing field, we are extremely open to contributions.
"""
markdown_splitter = MarkdownTextSplitter(chunk_size=100, chunk_overlap=0)
docs = markdown_splitter.create_documents([markdown_text])
👑 Python 代码拆分器
from langchain.text_splitter import PythonCodeTextSplitter
python_text = """
class Foo:
def bar():
def foo():
def testing_func():
def bar():
"""
python_splitter = PythonCodeTextSplitter(chunk_size=30, chunk_overlap=0)
docs = python_splitter.create_documents([python_text])
👑 OpenAI官方Token计数拆分器
# This is a long document we can split up.
with open('../../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=100, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
3.3.3 向量数据库
向量作为文本进行Embedding后的数据格式,选择一个合适的数据库进行存储尤为重要!
🎈 Chroma 数据库
!pip install chromadb
# get a token: https://platform.openai.com/account/api-keys
from getpass import getpass
OPENAI_API_KEY = getpass()
import os
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import TextLoader
from langchain.document_loaders import TextLoader
loader = TextLoader('../../../state_of_the_union.txt')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
db = Chroma.from_documents(docs, embeddings)
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
🎈 Milvus数据库
!pip install pymilvus
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Milvus
from langchain.document_loaders import TextLoader
from langchain.document_loaders import TextLoader
loader = TextLoader('../../../state_of_the_union.txt')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
vector_db = Milvus.from_documents(
docs,
embeddings,
connection_args={"host": "127.0.0.1", "port": "19530"},
)
docs = vector_db.similarity_search(query)
3.3.4 文本检索器
检索器接口是一个通用接口,可以轻松地将文档与语言模型组合在一起。此接口公开一个 get_relevant_documents 方法,该方法接受查询(字符串)并返回文档列表。
💡 ChatGPT 插件检索
from langchain.retrievers import ChatGPTPluginRetriever
retriever = ChatGPTPluginRetriever(url="http://0.0.0.0:8000", bearer_token="foo")
retriever.get_relevant_documents("alice's phone number")
💡 ElasticSearch
from langchain.retrievers import ElasticSearchBM25Retriever
elasticsearch_url="http://localhost:9200"
retriever = ElasticSearchBM25Retriever.create(elasticsearch_url, "langchain-index-4")
# Alternatively, you can load an existing index
# import elasticsearch
# elasticsearch_url="http://localhost:9200"
# retriever = ElasticSearchBM25Retriever(elasticsearch.Elasticsearch(elasticsearch_url), "langchain-index")
retriever.add_texts(["foo", "bar", "world", "hello", "foo bar"])
💡 KNN
from langchain.retrievers import KNNRetriever
from langchain.embeddings import OpenAIEmbeddings
retriever = KNNRetriever.from_texts(["foo", "bar", "world", "hello", "foo bar"], OpenAIEmbeddings())
result = retriever.get_relevant_documents("foo")
💡 TF-IDF
from langchain.retrievers import TFIDFRetriever
# !pip install scikit-learn
retriever = TFIDFRetriever.from_texts(["foo", "bar", "world", "hello", "foo bar"])
result = retriever.get_relevant_documents("foo")
3.4 数据记忆
记忆涉及在用户与语言模型的交互中保持状态的概念。用户与语言模型的交互是在ChatMessages的概念中捕获的,因此这可以归结为从一系列聊天消息中摄取、捕获、转换和提取知识。有许多不同的方法可以做到这一点,每一种都以自己的内存类型存在。
一般来说,对于每种类型的记忆,有两种方法来理解使用记忆。这些是从消息序列中提取信息的独立函数,然后是在链中使用这种类型内存的方法。
内存可以返回多条信息(例如,最近的N条消息和所有先前消息的摘要)。返回的信息可以是字符串或消息列表。
我们目前使用的记忆形式:“缓冲”存储器,其仅涉及保持所有先前消息的缓冲区。我们将在这里展示如何使用模块化实用函数,然后展示如何在链中使用它(既返回字符串又返回消息列表)。
3.4.1 会话记忆方式
🍿 会话缓存
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
llm = OpenAI(temperature=0)
conversation = ConversationChain(
llm=llm,
verbose=True,
memory=ConversationBufferMemory()
)
conversation.predict(input="Hi there!")
" Hi there! It's nice to meet you. How can I help you today?"
conversation.predict(input="I'm doing well! Just having a conversation with an AI.")
" That's great! It's always nice to have a conversation with someone new. What would you like to talk about?"
🍿 会话窗口缓存
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
conversation_with_summary = ConversationChain(
llm=OpenAI(temperature=0),
# We set a low k=2, to only keep the last 2 interactions in memory
memory=ConversationBufferWindowMemory(k=2),
verbose=True
)
conversation_with_summary.predict(input="Hi, what's up?")
=======================
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Hi, what's up?
AI:
> Finished chain.
===================================
conversation_with_summary.predict(input="What's their issues?")
🍿 会话知识图谱缓存
llm = OpenAI(temperature=0)
from langchain.prompts.prompt import PromptTemplate
from langchain.chains import ConversationChain
template = """The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context.
If the AI does not know the answer to a question, it truthfully says it does not know. The AI ONLY uses information contained in the "Relevant Information" section and does not hallucinate.
Relevant Information:
{history}
Conversation:
Human: {input}
AI:"""
prompt = PromptTemplate(
input_variables=["history", "input"], template=template
)
conversation_with_kg = ConversationChain(
llm=llm,
verbose=True,
prompt=prompt,
memory=ConversationKGMemory(llm=llm)
)
conversation_with_kg.predict(input="Hi, what's up?")
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context.
If the AI does not know the answer to a question, it truthfully says it does not know. The AI ONLY uses information contained in the "Relevant Information" section and does not hallucinate.
Relevant Information:
Conversation:
Human: Hi, what's up?
AI:
> Finished chain.
conversation_with_kg.predict(input="Hi, what's up?")
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context.
If the AI does not know the answer to a question, it truthfully says it does not know. The AI ONLY uses information contained in the "Relevant Information" section and does not hallucinate.
Relevant Information:
Conversation:
Human: Hi, what's up?
AI:
> Finished chain.
🍿 会话摘要缓存
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
llm = OpenAI(temperature=0)
conversation_with_summary = ConversationChain(
llm=llm,
memory=ConversationSummaryMemory(llm=OpenAI()),
verbose=True
)
conversation_with_summary.predict(input="Hi, what's up?")
🍿 会话令牌缓存
将对话内容用Token数量来限制,从而实现准确控制会话历史记录的最佳效果!
from langchain.chains import ConversationChain
conversation_with_summary = ConversationChain(
llm=llm,
# We set a very low max_token_limit for the purposes of testing.
memory=ConversationTokenBufferMemory(llm=OpenAI(), max_token_limit=60),
verbose=True
)
conversation_with_summary.predict(input="Hi, what's up?")
3.4.2 如何使用记忆方式
🍚 在多输入链使用缓存记忆功能
在本示例中使用到了
Template模板+LLM Model+memory
from langchain.memory import ConversationBufferMemory
from langchain import OpenAI, LLMChain, PromptTemplate
template = """You are a chatbot having a conversation with a human.
{chat_history}
Human: {human_input}
Chatbot:"""
prompt = PromptTemplate(
input_variables=["chat_history", "human_input"],
template=template
)
memory = ConversationBufferMemory(memory_key="chat_history")
llm_chain = LLMChain(
llm=OpenAI(),
prompt=prompt,
verbose=True,
memory=memory,
)
llm_chain.predict(human_input="Hi there my friend")
🍚 在同一个链使用多个缓存记忆功能
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
from langchain.docstore.document import Document
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts(texts, embeddings, metadatas=[{"source": i} for i in range(len(texts))])
Running Chroma using direct local API.
Using DuckDB in-memory for database. Data will be transient.
query = "What did the president say about Justice Breyer"
docs = docsearch.similarity_search(query)
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory
template = """You are a chatbot having a conversation with a human.
Given the following extracted parts of a long document and a question, create a final answer.
{context}
{chat_history}
Human: {human_input}
Chatbot:"""
prompt = PromptTemplate(
input_variables=["chat_history", "human_input", "context"],
template=template
)
memory = ConversationBufferMemory(memory_key="chat_history", input_key="human_input")
chain = load_qa_chain(OpenAI(temperature=0), chain_type="stuff", memory=memory, prompt=prompt)
query = "What did the president say about Justice Breyer"
chain({"input_documents": docs, "human_input": query}, return_only_outputs=True)
{'output_text': ' Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service.'}
print(chain.memory.buffer)
Human: What did the president say about Justice Breyer
AI: Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service.
3.5 链式调用
在学了LangChain的这么多功能之后,如何合理使用以满足开发需求才是最重要的!要想使用好链,我们需要从一下三个模块入手:
- 使用简单的LLM链
- 创建顺序链
- 创建自定义链
链允许我们将多个组件组合在一起,以创建一个单一的、连贯的应用程序。例如,我们可以创建一个链,它接受用户输入,使用PromptTemplate对其进行格式化,然后将格式化的响应传递给LLM。我们可以通过将多个链组合在一起,或将链与其他组件组合来构建更复杂的链。
3.5.1 链的创建与使用
若现实的链已经无法满住你的需求,这个时候你可以尝试自定义链,LangChain对于自定义链也有自己的一套方法,我们只需要继承Chain接口并且在特定方法中实现自己的逻辑即可!
from __future__ import annotations
from typing import Any, Dict, List, Optional
from pydantic import Extra
from langchain.base_language import BaseLanguageModel
from langchain.callbacks.manager import (
AsyncCallbackManagerForChainRun,
CallbackManagerForChainRun,
)
from langchain.chains.base import Chain
from langchain.prompts.base import BasePromptTemplate
class MyCustomChain(Chain):
"""
An example of a custom chain.
"""
prompt: BasePromptTemplate
"""Prompt object to use."""
llm: BaseLanguageModel
output_key: str = "text" #: :meta private:
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
@property
def input_keys(self) -> List[str]:
"""Will be whatever keys the prompt expects.
:meta private:
"""
return self.prompt.input_variables
@property
def output_keys(self) -> List[str]:
"""Will always return text key.
:meta private:
"""
return [self.output_key]
def _call(
self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None,
) -> Dict[str, str]:
# Your custom chain logic goes here
# This is just an example that mimics LLMChain
prompt_value = self.prompt.format_prompt(**inputs)
# Whenever you call a language model, or another chain, you should pass
# a callback manager to it. This allows the inner run to be tracked by
# any callbacks that are registered on the outer run.
# You can always obtain a callback manager for this by calling
# `run_manager.get_child()` as shown below.
response = self.llm.generate_prompt(
[prompt_value],
callbacks=run_manager.get_child() if run_manager else None
)
# If you want to log something about this run, you can do so by calling
# methods on the `run_manager`, as shown below. This will trigger any
# callbacks that are registered for that event.
if run_manager:
run_manager.on_text("Log something about this run")
return {self.output_key: response.generations[0][0].text}
async def _acall(
self,
inputs: Dict[str, Any],
run_manager: Optional[AsyncCallbackManagerForChainRun] = None,
) -> Dict[str, str]:
# Your custom chain logic goes here
# This is just an example that mimics LLMChain
prompt_value = self.prompt.format_prompt(**inputs)
# Whenever you call a language model, or another chain, you should pass
# a callback manager to it. This allows the inner run to be tracked by
# any callbacks that are registered on the outer run.
# You can always obtain a callback manager for this by calling
# `run_manager.get_child()` as shown below.
response = await self.llm.agenerate_prompt(
[prompt_value],
callbacks=run_manager.get_child() if run_manager else None
)
# If you want to log something about this run, you can do so by calling
# methods on the `run_manager`, as shown below. This will trigger any
# callbacks that are registered for that event.
if run_manager:
await run_manager.on_text("Log something about this run")
return {self.output_key: response.generations[0][0].text}
@property
def _chain_type(self) -> str:
return "my_custom_chain"
3.5.2 经典链的使用
🍗 路由链的使用
路由链在LangChain生态中可以自定义连接多个链节点的调用,实现参数的传递!通过路由链我们可以自定义更多的灵活操作!
本示例中用 RouterChain 范例来创建一个链,该链动态地选择下一个链用于给定的输入。
from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser
from langchain.chains.router.multi_prompt_prompt import MULTI_PROMPT_ROUTER_TEMPLATE
destinations = [f"{p['name']}: {p['description']}" for p in prompt_infos]
destinations_str = "\n".join(destinations)
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(
destinations=destinations_str
)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
router_chain = LLMRouterChain.from_llm(llm, router_prompt)
chain = MultiPromptChain(router_chain=router_chain, destination_chains=destination_chains, default_chain=default_chain, verbose=True)
print(chain.run("What is black body radiation?"))
> Entering new MultiPromptChain chain...
physics: {'input': 'What is black body radiation?'}
> Finished chain.
Black body radiation is the term used to describe the electromagnetic radiation emitted by a “black body”—an object that absorbs all radiation incident upon it. A black body is an idealized physical body that absorbs all incident electromagnetic radiation, regardless of frequency or angle of incidence. It does not reflect, emit or transmit energy. This type of radiation is the result of the thermal motion of the body's atoms and molecules, and it is emitted at all wavelengths. The spectrum of radiation emitted is described by Planck's law and is known as the black body spectrum.
🍗 分析文档
本示例先读取了文件中的内容,通过
摘要总结链+问答链实现了对文档内容的对话分析!
with open("../../state_of_the_union.txt") as f:
state_of_the_union = f.read()
from langchain import OpenAI
from langchain.chains.summarize import load_summarize_chain
llm = OpenAI(temperature=0)
summary_chain = load_summarize_chain(llm, chain_type="map_reduce")
from langchain.chains import AnalyzeDocumentChain
summarize_document_chain = AnalyzeDocumentChain(combine_docs_chain=summary_chain)
summarize_document_chain.run(state_of_the_union)
from langchain.chains.question_answering import load_qa_chain
qa_chain = load_qa_chain(llm, chain_type="map_reduce")
qa_document_chain = AnalyzeDocumentChain(combine_docs_chain=qa_chain)
qa_document_chain.run(input_document=state_of_the_union, question="what did the president say about justice breyer?")
' The president thanked Justice Breyer for his service.'
3.6 功能代理
LangChain的大招同样还包括功能代理,LangChain支持LLM结合不同工具的API,实现除基本功能外的一些强大到没朋友的操作!快来自己动手实现一个Auto-GPT!
🍤 必应搜索代理
import os
os.environ["BING_SUBSCRIPTION_KEY"] = ""
os.environ["BING_SEARCH_URL"] = ""
from langchain.utilities import BingSearchAPIWrapper
search = BingSearchAPIWrapper()
search.run("python")
🍤 谷歌搜索代理(ChatGPT联网原理)
from langchain.utilities import GoogleSerperAPIWrapper
from langchain.llms.openai import OpenAI
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
llm = OpenAI(temperature=0)
search = GoogleSerperAPIWrapper()
tools = [
Tool(
name="Intermediate Answer",
func=search.run,
description="useful for when you need to ask with search"
)
]
self_ask_with_search = initialize_agent(tools, llm, agent=AgentType.SELF_ASK_WITH_SEARCH, verbose=True)
self_ask_with_search.run("What is the hometown of the reigning men's U.S. Open champion?")
> Entering new AgentExecutor chain...
Yes.
Follow up: Who is the reigning men's U.S. Open champion?
Intermediate answer: Current champions Carlos Alcaraz, 2022 men's singles champion.
Follow up: Where is Carlos Alcaraz from?
Intermediate answer: El Palmar, Spain
So the final answer is: El Palmar, Spain
> Finished chain.
🍤 Python编译器代理
from langchain.agents import Tool
from langchain.utilities import PythonREPL
python_repl = PythonREPL()
python_repl.run("print(1+1)")
'2\n'
🍤 网络爬虫代理
from langchain.agents import load_tools
requests_tools = load_tools(["requests_all"])
from langchain.utilities import TextRequestsWrapper
requests = TextRequestsWrapper()
requests.get("https://www.google.com")
🍤 天气预报代理
pip install pyowm
import os
os.environ["OPENWEATHERMAP_API_KEY"] = ""
from langchain.utilities import OpenWeatherMapAPIWrapper
weather = OpenWeatherMapAPIWrapper()
weather_data = weather.run("London,GB")
print(weather_data)
In London,GB, the current weather is as follows:
Detailed status: overcast clouds
Wind speed: 4.63 m/s, direction: 150°
Humidity: 67%
Temperature:
- Current: 5.35°C
- High: 6.26°C
- Low: 3.49°C
- Feels like: 1.95°C
Rain: {}
Heat index: None
Cloud cover: 100%
文章出处登录后可见!