简介
yolov7自提出便号称在速度和精度方面超过了所有的目标检测器,并能够同时支持边缘设备到云端的移动GPU和GPU设备,而yolov7则具有以下优势:
1、更高的检测精度:相较于其前身 YOLOv5,YOLOv7 在保持速度优势的同时,通过改进骨干网络和特征融合方法等方式,进一步提升了检测精度。
2、更快的检测速度:YOLOv7 采用了一系列的技术手段来提高检测速度,例如使用 SPP-PANet 进行多尺度特征融合、采用自适应卷积等。这些优化使得 YOLOv7 在保持较高的检测精度的同时,能够实现更快的检测速度。
3、更好的可扩展性:YOLOv7 的架构相对简单,易于扩展和修改。此外,YOLOv7 还提供了许多实用的工具和接口,使得用户能够快速地进行模型训练和应用部署。
4、更好的通用性:YOLOv7 不仅能够在大规模的、多类别的数据集上取得较好的表现,同时还能够在小样本、小类别的数据集上进行有效的训练和检测。
- 架构优化
- 提出几种免费袋(模块和优化方法)
- 模型重参数
- 动态标签分配
边缘设备:是指在网络中靠近用户或物联网终端设备的计算设备,通常用于收集、处理和存储数据。这些设备可以是智能手机、平板电脑、传感器、智能家居设备、安全摄像头等。与云计算相比,边缘设备更加接近数据源和数据使用者,可以实现更快速的数据处理和响应,并减少网络延迟和带宽消耗。边缘设备在智能城市、智能工厂、智能交通、智能医疗等领域有着广泛的应用。
相关工作
模型重参数
在 YOLOv7 中,模型重参数是指将模型的层数和参数量减少,同时保持模型性能不变或提高模型性能。YOLOv7 的模型重参数是通过以下步骤实现的:
-
CSPNet 网络结构:YOLOv7 采用了 CSPNet 网络结构,它将一个较大的卷积层分成两个较小的卷积层,从而减少了模型的参数数量。此外,CSPNet 还采用了跨阶段连接技术,使得网络可以在不增加参数数量的情况下获得更高的性能。
-
剪枝:YOLOv7 采用了通道剪枝技术,将网络中一些不重要的通道删除,从而减少模型的参数数量。通道剪枝技术可以通过对每个通道的重要性进行评估来实现。具体而言,可以使用结构感知剪枝(Structural-Aware Pruning)或自适应剪枝(Adaptive Pruning)等技术来评估每个通道的重要性。
-
SPP 网络结构:YOLOv7 中使用了 SPP 网络结构,该结构可以在不增加参数数量的情况下增加感受野,从而提高网络的性能。具体而言,SPP 网络结构通过使用不同尺寸的池化核来提取不同大小的特征图,然后将这些特征图拼接在一起,从而形成一个具有更大感受野的特征图。
-
模型微调:在模型训练过程中,YOLOv7 采用了模型微调技术,通过微调模型的参数来进一步提高模型的性能。具体而言,YOLOv7 通过在较小的数据集上进行微调,使得模型可以更好地适应新的数据集。
YOLOv7 的模型重参数是一种有效的模型优化方法,可以减少模型的参数量和计算量,同时提高模型的推理速度和性能。
总结:YOLOv7 中的模型重参数主要是通过 CSPNet 网络结构、剪枝、SPP 网络结构和模型微调等技术来实现的
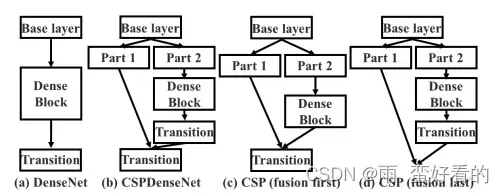
CSPNet提出主要是为了解决三个问题:增强CNN的学习能力,能够在轻量化的同时保持准确性,降低计算瓶颈,降低内存成本
将feature map拆成两个部分,一部分进行卷积操作,另一部分和上一部分卷积操作的结果进行concate
模型缩放
模型缩放方法通常使用不同的缩放因子,如resolution(输入图像的大小)、深度(层数)、宽度(通道数)和阶段(特征pyramid的数量),以便对网络参数量、计算、推理速度和ac-curacy进行良好的权衡。
论文提到,所有基于串联的模型,如DenseNet[32]或VoVNet[39],当此类模型的深度被缩放时,会改变一些层的输入宽度。由于提出的架构是基于串联的,我们必须为这个模型设计一个新的复合缩放方法。
-
多尺度训练:YOLOv7 采用了多尺度训练技术,即在训练过程中使用不同尺度的图像来训练模型。这可以让模型学习到不同尺度的目标,从而提高模型的鲁棒性和泛化能力。具体而言,YOLOv7 使用了 3 个不同的尺度来训练模型,分别为 640×640、960×960 和 1280×1280。
-
PANet 网络结构:YOLOv7 中采用了 PANet 网络结构,它可以将不同尺度的特征图融合在一起,从而提高模型的检测精度。具体而言,PANet 网络结构通过自顶向下和自底向上的方式来进行特征融合,使得模型可以更好地处理不同尺度的目标。
体系结构
E-ELAN
yolov7的基础模块ELAN,论文还提出了ELAN的扩展E-ELAN(扩展的高效层聚合网络),将两个并行的ELAN,输出按位置相加,E-ELAN只在yolov7-e6中使用。
E-ELAN利用expand、shuffle、merge cardinality来实现不破坏原来梯度路径的情况下不断增强网络学习能力的能力。它使用组卷积来增加特征的基数(cardinality),并以shuffle和merge cardinality的方式组合不同组的特征。这种操作方式可以增强不同特征图学到的特征,改进参数的使用和计算效率。
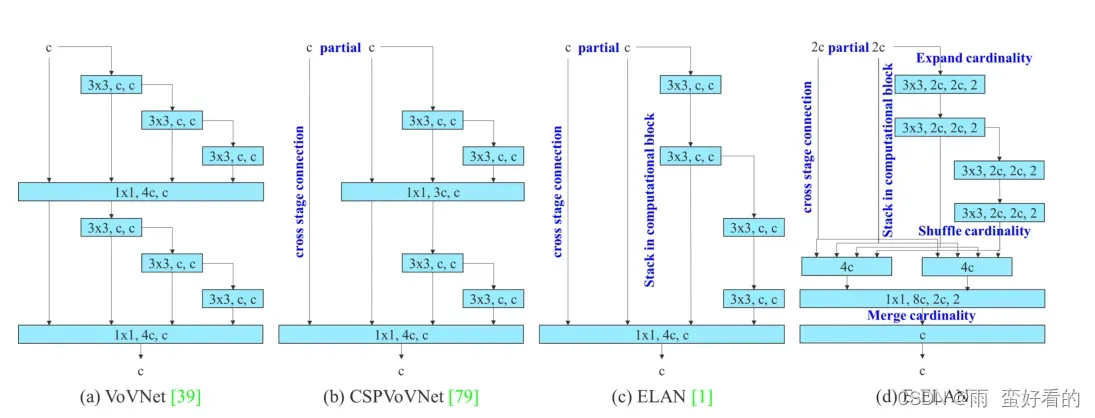
深入浅出 Yolo 系列之 Yolov7 基础网络结构详解 – 知乎 (zhihu.com)
模型缩放方法
yolov7x是对模型进行了宽度和深度的缩放
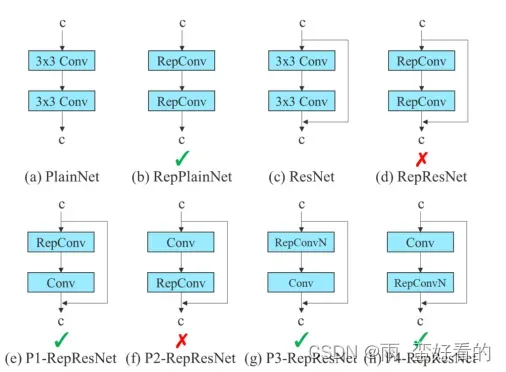
计划的重参数化卷积
虽然RepConv在VGG上取得了出色的表现,但当我们直接将其应用于ResNet和DenseNet以及其他架构时,其准确性将大大降低。,比如不带残差的3×3卷积可以直接替换成重参数化卷积,但是对于resnet的残差模块,本来就有一个恒等连接,再替换成重参数化卷积效果只会更差,我们发现RepConv中的身份连接破坏了ResNet中的残差和DenseNet中的拼接,为不同的特征映射提供了更多样化的梯度。基于上述原因,使用无单位连接的RepConv (RepConvN)来设计规划的重新参数化卷积的体系结构。在我们的思维中,当一个带有残差或串联的卷积层被重新参数化的卷积所取代时,应该没有恒等连接。
标签分配方法
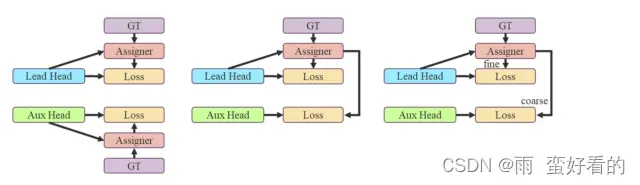
深度监督:在模型训练的过程中,除了最终的检测头(Lead Head)外,给中间的一些层也增加一些辅助头(Aux Head),辅助检测头也会参与损失值的计算。
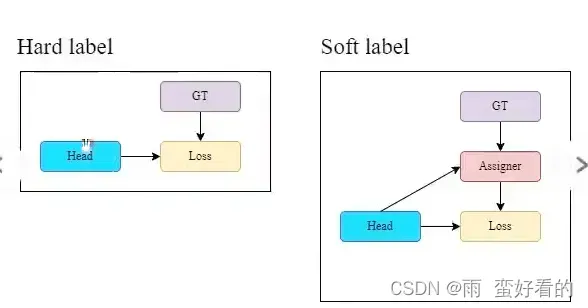
标签分配:把输入图像中的标注框和最终预测的预测值对应起来,便于进一步求损失值,硬标签和软标签(trian中的OTA算法)
过去,在深度网络的训练中,标签赋值通常是直接参考ground truth,根据给定的规则生成硬标签。然而,近年来,如果我们以物体检测为例,研究人员往往利用网络输出的预测质量和分布,然后与ground truth一起考虑,使用一些计算和优化方法来生成可靠的软标签。例如,YOLO使用边界盒回归预测的IoU和地面真实作为物体的软标签。在本文中,我们把把网络预测结果和地面实况一起考虑,然后分配软标签的机制称为 “标签分配器”。
本文提出的方法是一种新的标签分配方法,通过先导头预测来指导辅助头和先导头。
换句话说,我们使用先导头预测作为指导,生成粗到细的分层标签,分别用于辅助头和先导头学习。本文提出的两种深度监督标签分配策略分别如图5 (d)和(e)所示。
引线头导向标签分配器主要是根据引线头的预测结果和地面真实值进行计算,通过优化过程生成软标签。这套软标签将作为辅助头和带头头的目标训练模型。
注:
①我们为边缘GPU、普通GPU和云GPU设计了基本模型,它们分别被称为YOLOv7- tiny、YOLOv7和YOLOv7-W6。②同时,我们还利用基本模型为不同的服务需求进行模型扩展,得到不同类型的模型。对于YOLOv7,我们在颈部做了堆叠缩放,并使用所提出的复合缩放方法对整个模型的深度和宽度进行了缩放,并以此获得了YOLOv7-X。③至于YOLOv7-W6,我们使用新提出的复合缩放方法来获得YOLOv7-E6和YOLOv7-D6。此外,我们对YOLOv7-E6使用提议的E-ELAN,从而完成YOLOv7- E6E。
文章出处登录后可见!