文章目录
- 问题一
- 问题二
- 求出RFM数据
- 评分
- K- Means聚类
- 问题三
- 问题四
- 问题五
- 参考文献
问题一
利用该大型百货商场提供的附件一中的会员信息以及附件三中的会员消费明细,完善该商场的会员画像。本文从购买力、购买时间偏好两个维度分析会员的消费特征。以会员消费总金额、消费次数、商品购买数量代表会员购买力,同时按季节对会员消费行为进行分析。
同时对会员与非会员的消费次数和,商品购买金额💰进行分析。
代码详见以下链接
问题一代码
问题二
求出RFM数据
data_vip.to_csv('vip.csv',encoding = 'gb18030', index = None)
dvip = pd.read_csv('./vip.csv',encoding='gbk')
dvip
#获取日期数据精确到day
dvip['dtime']=pd.to_datetime(dvip.dtime).dt.date
#截取需要的数据
data_new = dvip[['kh','je','year','sl','dtime']]
data_new
#构建FRM模型需要选取时间段统计,本次统计的时间范围选为2017年至2018年1月3日
data_new = data_new[data_new.year>2016]
data_new.year.unique()
data_new.drop("year",inplace=True,axis=1)
#以2018-01-03为截止日期,计算登记日期与截止日期的天数
data_new['end_time'] = '2018-01-03'
pd.to_datetime(data_new.end_time)
data_days = pd.DataFrame(pd.to_datetime(data_new.end_time)-pd.to_datetime(data_new.dtime),columns=['R'])
data_new2 = pd.concat([data_new,data_days],axis=1)
data_new2
data_new2.R = data_new2.R.map(lambda x:str(x).split(' ')[0])
data_new2.reset_index(drop=True)
#构建RFM字段中的R字段,即客户最近购买的事件与截止时间相差的日期
data_new2.R = data_new2.R.map(lambda x:int(x))
data_R = data_new2.groupby('kh').agg({'R':'min'}).reset_index()
data_R
#构建FM字段
data_F = data_new2.groupby('kh').agg(F=pd.NamedAgg(column='kh',aggfunc='count')).reset_index()
data_M = data_new2.groupby('kh').agg(F=pd.NamedAgg(column='je',aggfunc='sum')).reset_index()
#合并3个字段,构建RFM数据
data_RF=pd.merge(data_R,data_F,on="kh",how="inner")
data_RFM=pd.merge(data_RF,data_M,on="kh",how="inner")
data_RFM
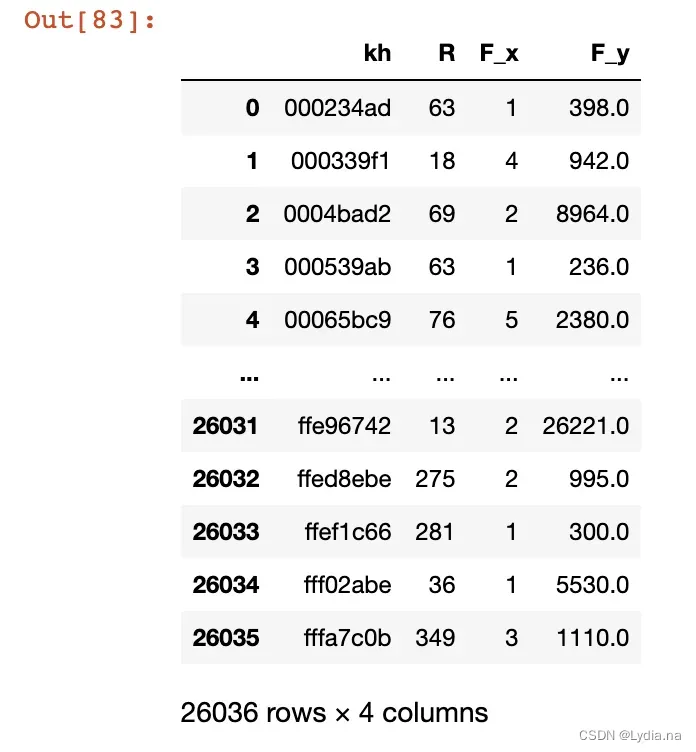
data_RFM.columns=['kh','R','F','M']
评分
train_data = data_RFM.iloc[:,[1,2,3]]
train_data
# 评分
for name in train_data.columns:
if name=="R":
ascending = False
else:
ascending = True
train_data.sort_values(by=[name],inplace=True, ascending=ascending)
train_data.reset_index(drop=True, inplace=True)
n = train_data.shape[0]
for i in range(1, 6):
b = 0.2*n*(i-1)
e = 0.2*n*i
train_data.loc[b:e, name] = i
for name in train_data.columns:
print(name," ", train_data[name].min()," ", train_data[name].max())
train_data.head()
K- Means聚类
#需要进行的聚类类别数
k = 8
kmodel = KMeans(n_clusters = k)
#训练模型
kmodel.fit(train_data)
#查看聚类中心
print(kmodel.cluster_centers_)
#查看各样本对应的类别
print(kmodel.labels_ )
print(kmodel.cluster_centers_.shape)
# 简单打印结果
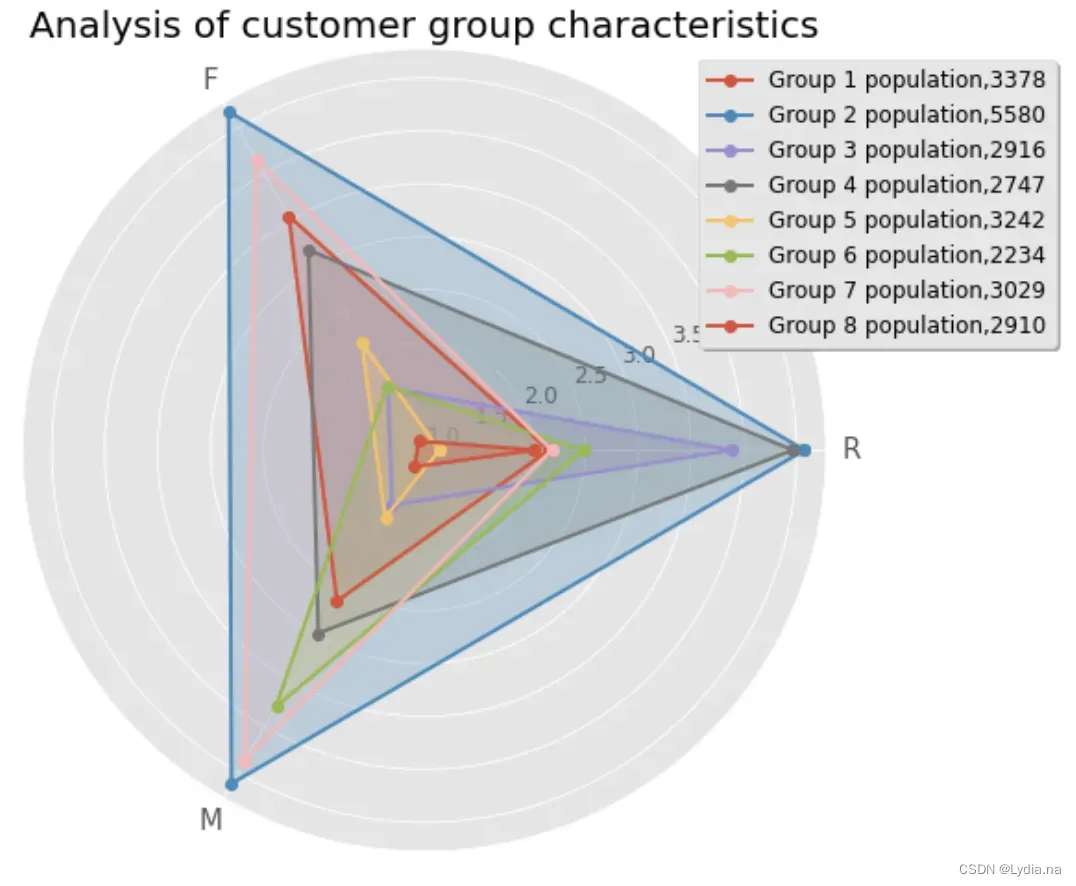
r1 = pd.Series(kmodel.labels_).value_counts() #统计各个类别的数目
r2 = pd.DataFrame(kmodel.cluster_centers_) #找出聚类中心
# 所有簇中心坐标值中最大值和最小值
max = r2.values.max()
min = r2.values.min()
r = pd.concat([r2, r1], axis = 1) #横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns = list(train_data.columns) + [u'类别数目'] #重命名表头
# 绘图
fig=plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, polar=True)
center_num = r.values
feature = list(train_data.columns)
#feature = ['消费总金额', '消费频率', '入会时长', '消费次数', '最近一次消费', '平均消费金额']
N =len(feature)
for i, v in enumerate(center_num):
# 设置雷达图的角度,用于平分切开一个圆面
angles=np.linspace(0, 2*np.pi, N, endpoint=False)
# 为了使雷达图一圈封闭起来,需要下面的步骤
center = np.concatenate((v[:-1],[v[0]]))
angles=np.concatenate((angles,[angles[0]]))
# 绘制折线图
ax.plot(angles, center, 'o-', linewidth=2, label = "Group %d population,%d"% (i+1,v[-1]))
# 填充颜色
ax.fill(angles, center, alpha=0.25)
# 添加每个特征的标签
ang = angles*180/np.pi
ax.set_thetagrids(ang[:-1], feature, fontsize=15)
# 设置雷达图的范围
ax.set_ylim(min-0.1, max+0.1)
# 添加标题
plt.title('Analysis of customer group characteristics', fontsize=20)
# 添加网格线
ax.grid(True)
# 设置图例
plt.legend(loc='upper right', bbox_to_anchor=(1.3,1.0),ncol=1,fancybox=True,shadow=True)
# 显示图形
#plt.savefig("%s类.png"%k)
plt.show()
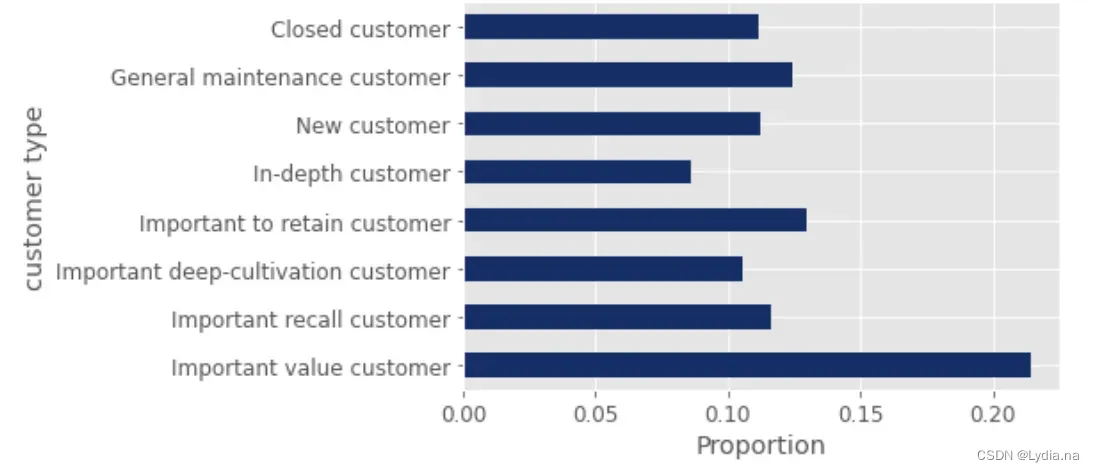
r['分数'] = r['R'] + r['F'] + r['M']
r.sort_values('分数', ascending=False, inplace=True)
tmp = r['类别数目']
tmp3 = tmp/r['类别数目'].sum()
ind = ['Important value customer', 'Important recall customer', 'Important deep-cultivation customer', 'Important to retain customer', 'In-depth customer', 'New customer', 'General maintenance customer', 'Closed customer']
tmp3.index = ind
print(tmp3)

ax = tmp3.plot.barh(stacked=True,colormap = 'Blues_r')
ax.figsize=(35, 35)
ax.set_xlabel('Proportion') # 设置x轴标签
ax.set_ylabel('customer type') # 设置y轴标签
fig = ax.get_figure() # 用于保存图片
#fig.savefig('客户价值分类图.png',bbox_inches = 'tight') # 保存为png格式
问题三
考虑到会员的消费行为对状态的影响,在问题二的RFMT 模型的基础上,运用spss modeler软件对会员的R、F、M、T 四个指标数据进行K-means 聚类,选取模型中的R 和F 指标作为聚类依据,建立聚类模型对会员状态进行分类。
根据会员的R、F、M、T 指标数据,运用Clementine 软件进行K-means 聚
类,建立聚类模型,选择聚类数为3 类,一共迭代六次。
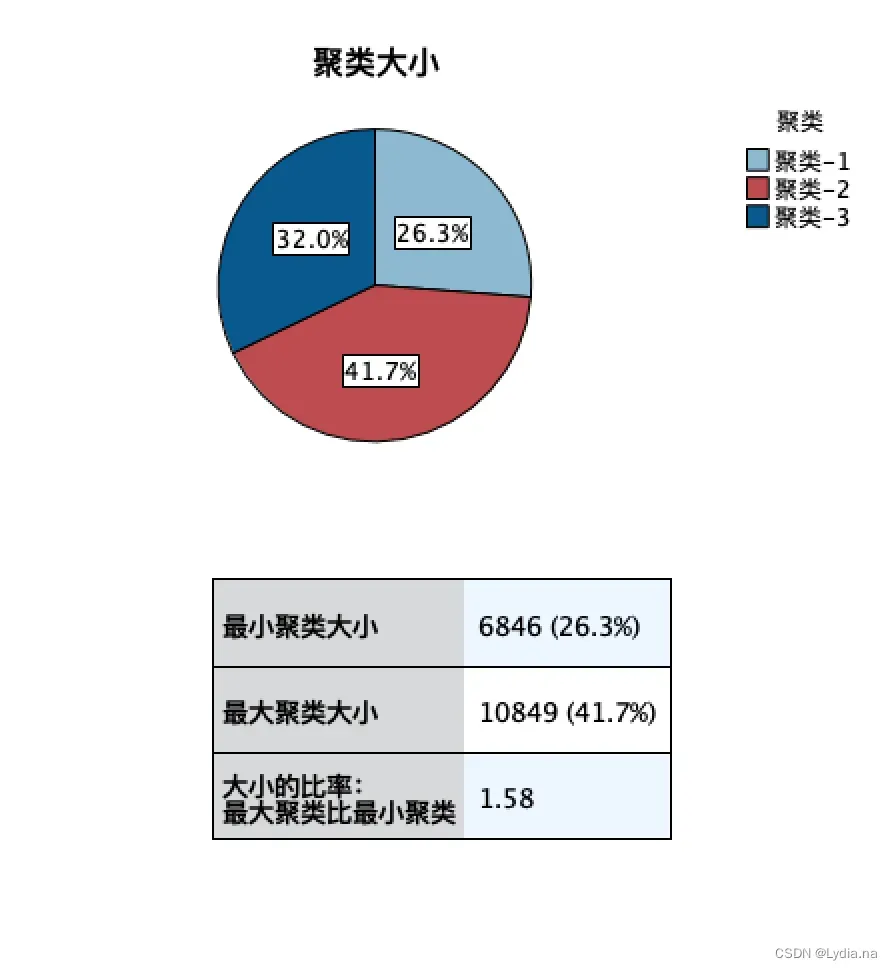
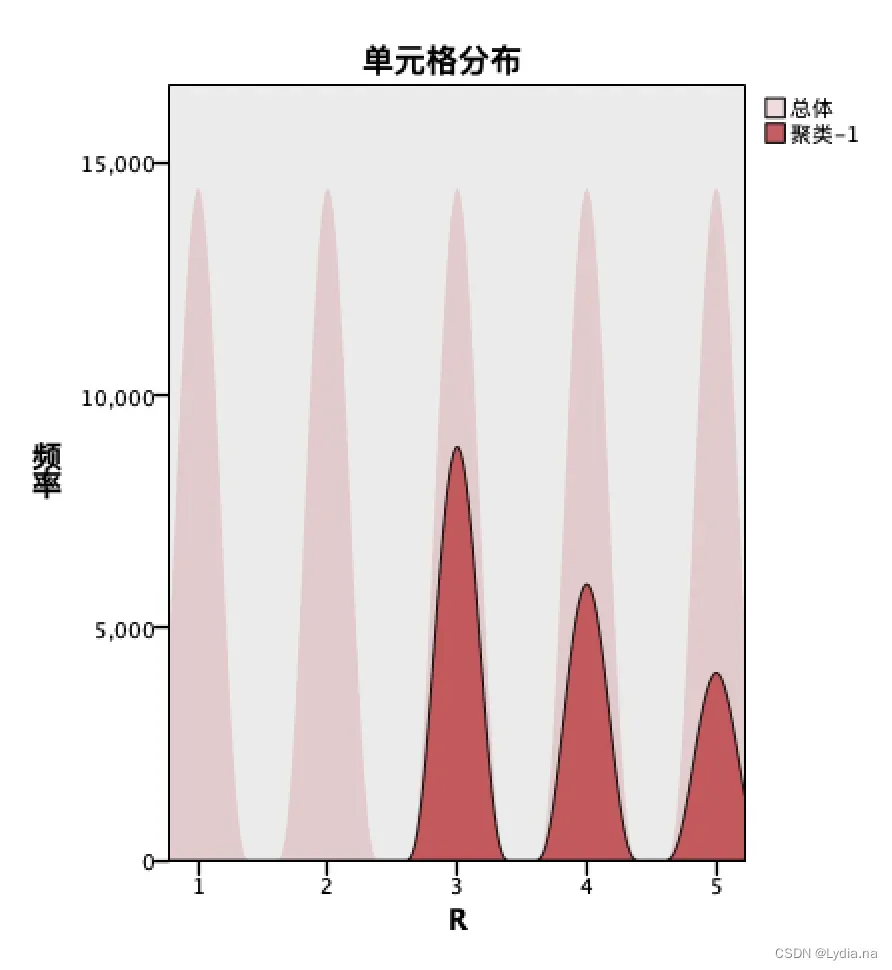
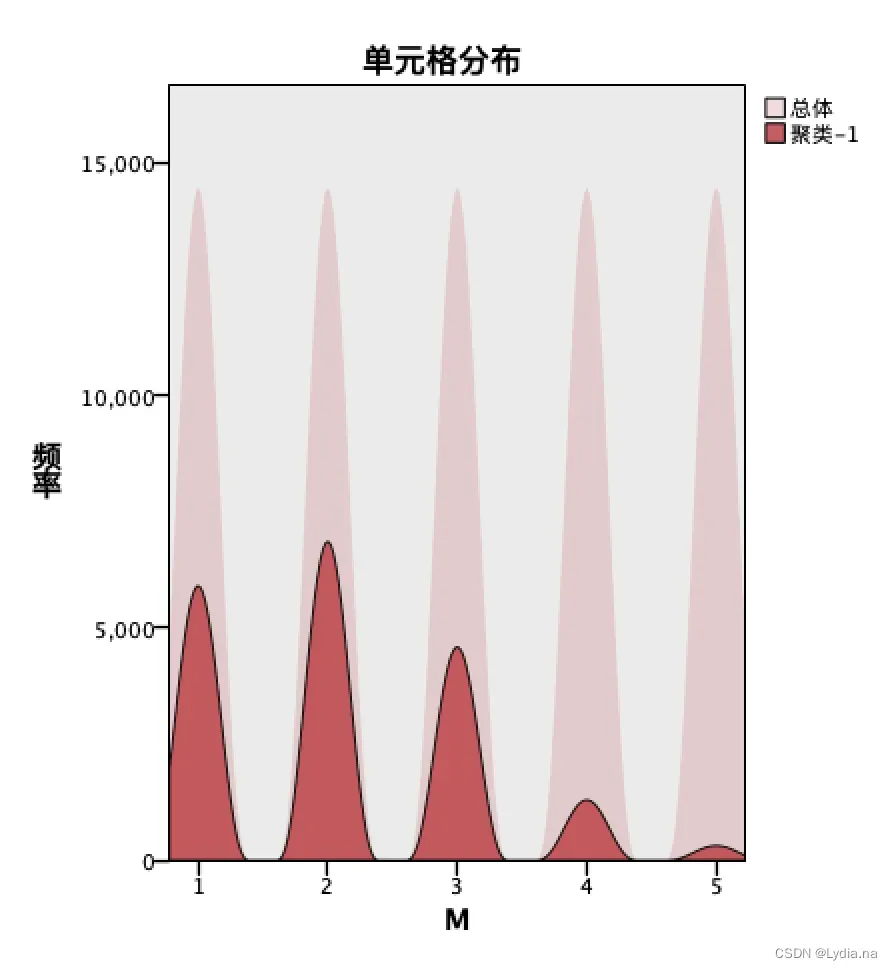
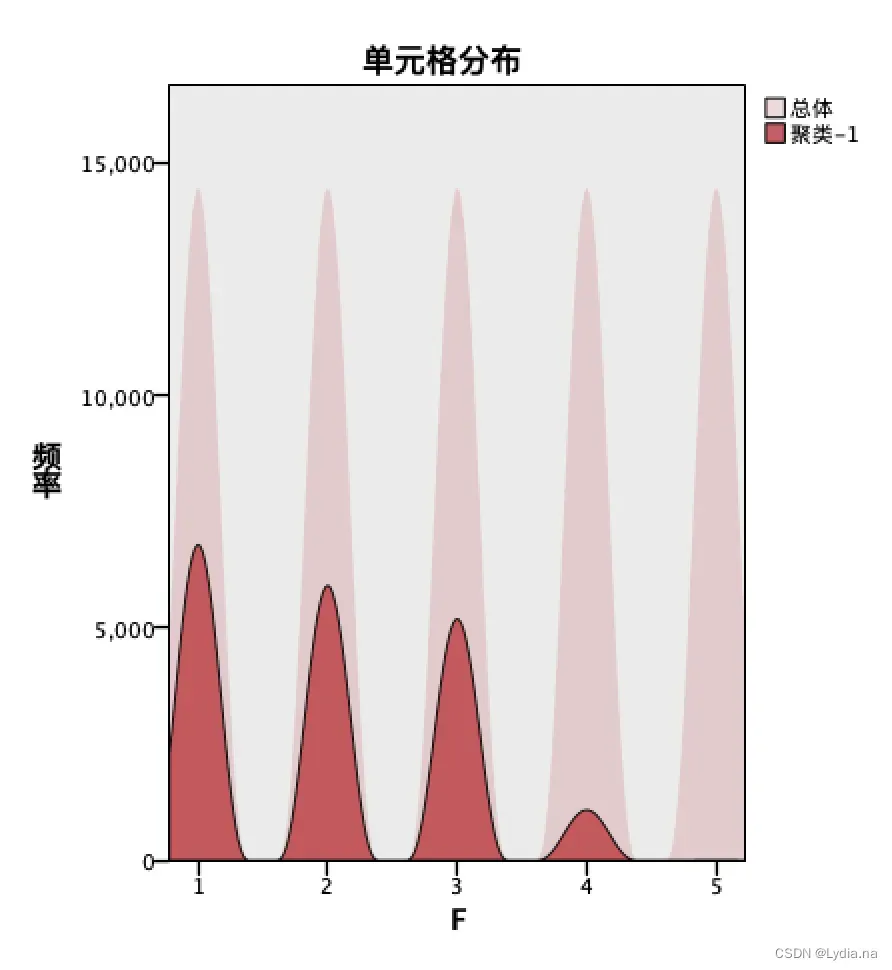
根据结果对会员类型划分为三类,分别为流失会员、活跃会员、沉默会员。
问题四
问题五
](https://aitechtogether.com/wp-content/uploads/2023/05/30ee5ff3-a84e-4ca5-8990-91ab1ba4111d.webp)
还未想到可实现的方法,未完待续。
参考文献
基于FRM模型的百货商场用户画像描绘与价值分析
Description-and-Value-analysis-of-user-portraits-in-department-stores
文章出处登录后可见!
已经登录?立即刷新