thunlp chatglm 6B是一款基于海量高质量中英文语料训练的面向文本对话场景的语言模型。
THUDM/ChatGLM-6B: ChatGLM-6B:开源双语对话语言模型 | An Open Bilingual Dialogue Language Model (github.com)
国内的一位大佬把chatglm ptuning 的训练改成了多层多卡并行训练的实现
zero_nlp/Chatglm6b_ModelParallel_ptuning at main · yuanzhoulvpi2017/zero_nlp (github.com)
用到了神秘的perf库
希望大家能支持一下我的工作
用我的专用邀请链接,注册 OpenBayes,双方各获得 60 分钟 RTX 3090 使用时长,支持累积,永久有效:
注册 – OpenBayes
通过我的链接注册并充值openbayes平台。
找到了一些中国大百科的一对一对的数据集来ptuning chatglm 6B的对话模型。

添加图片注释,不超过 140 字(可选)
在双卡3080环境中进行了训练后。二十五个小时二十九分钟训练了3000次迭代。多卡分层ptuning的效果感觉并不理想。可能是因为训练的轮次太少了。loss竟然高达4.1447。那我们扩大100倍步数来等一下看看拟合效果。
把我们双3080训练的参数摆出来
PRE_SEQ_LEN=8 LR=1e-2 CUDA_VISIBLE_DEVICES=0,1 python3 main_parallel.py \ –do_train \ –train_file AdvertiseGen/train.json \ –validation_file AdvertiseGen/dev.json \ –prompt_column content \ –response_column summary \ –overwrite_cache \ –model_name_or_path /root/autodl-tmp/zero_nlp/Chatglm6b_ModelParallel_ptuning/output/adgen-chatglm-6b-pt-8-1e-2/checkpoint-3000 \ –output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \ –overwrite_output_dir \ –max_source_length 256 \ –max_target_length 512 \ –per_device_train_batch_size 1 \ –per_device_eval_batch_size 1 \ –gradient_accumulation_steps 16 \ –predict_with_generate \ –max_steps 30000 \ –logging_steps 10 \ –save_steps 2000 \ –learning_rate $LR \ –pre_seq_len $PRE_SEQ_LEN

添加图片注释,不超过 140 字(可选)
双卡3080训练31个小时损失及学习率相关情况截图。
60小时双卡3080训练一万六千步,形成了8个训练节点checkpoint。开始面向最新一轮的展开模型效果测试。
import os import platform import signal from transformers import AutoTokenizer, AutoModel import json os_name = platform.system() clear_command = ‘cls’ if os_name == ‘Windows’ else ‘clear’ stop_stream = False def build_prompt(history): prompt = “欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序” for query, response in history: prompt += f”\n\n用户:{query}” prompt += f”\n\nChatGLM-6B:{response}” return prompt def signal_handler(signal, frame): global stop_stream stop_stream = True def main(): global stop_stream print(“欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序”) tokenizer = AutoTokenizer.from_pretrained(“/root/autodl-tmp/zero_nlp/Chatglm6b_ModelParallel_ptuning/output/adgen-chatglm-6b-pt-8-1e-2/checkpoint-16000”, trust_remote_code=True) model = AutoModel.from_pretrained(“/root/autodl-tmp/zero_nlp/Chatglm6b_ModelParallel_ptuning/output/adgen-chatglm-6b-pt-8-1e-2/checkpoint-16000”, trust_remote_code=True).quantize(4).half().cuda() model = model.eval() AdvertiseGen = json.load(open(“/root/autodl-tmp/zero_nlp/Chatglm6b_ModelParallel_ptuning/AdvertiseGen/dev.json”)) for AdvertiseGen_one in AdvertiseGen: history = [] count = 0 response, history = model.chat(tokenizer, AdvertiseGen_one[‘content’], history=history) print(AdvertiseGen_one) print(response) if __name__ == “__main__”: main()

添加图片注释,不超过 140 字(可选)
所以这里面我感觉是因为我的数据集长短分布差异较大导致的问题。于是痛定思痛。决定下一步从两个方向改进,第一输入输出长度设置为64、128。第二我要减小十倍的学习率,观察一下减小十倍的学习率能不能提升ptuning的效果。
在预测推理阶段发生了形状错误问题。 已经解决。本来是想着tokenizer部分要用原来的tockenizer,后来发现换成了训练好的tokenizer之后才不报错。
import os from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained(“/root/autodl-tmp/checkpoint-3000”, trust_remote_code=True) model = AutoModel.from_pretrained(“/root/autodl-tmp/checkpoint-3000”, trust_remote_code=True).half().cuda() model = model.eval()
用这样的方式去加载已经ptuning训练好的模型就可以开始测试我们自己训练的数据集的效果了。
单卡官方原生ptuning训练
单卡A5000 Ptuning V2 chatglm 6B任务基于chatglm 6B官方开源ptuning V2版本代码运行。
在单卡A5000 混合精度训练推理。更改参数 –max_source_length 256 –max_target_length 512,个人感觉输入太短、输出太短,训练出来也没什么意义。所以把source和target的长度拉长到256、512。理论上只要长加起来不超过2048,就不会报错。我们把完整的训练参数show一下
PRE_SEQ_LEN=4 LR=1e-2 CUDA_VISIBLE_DEVICES=0 python3 main.py \ –do_train \ –train_file ./train.json \ –validation_file ./dev.json \ –prompt_column content \ –response_column summary \ –overwrite_cache \ –model_name_or_path THUDM/chatglm-6b \ –output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR-dev \ –overwrite_output_dir \ –max_source_length 256 \ –max_target_length 512 \ –per_device_train_batch_size 1 \ –per_device_eval_batch_size 1 \ –gradient_accumulation_steps 16 \ –predict_with_generate \ –max_steps 30000000 \ –logging_steps 1000 \ –save_steps 10000\ –learning_rate $LR \ –pre_seq_len $PRE_SEQ_LEN \ –quantization_bit 8
那么按照这个参数,模型将会占用A5000多少显存呢?
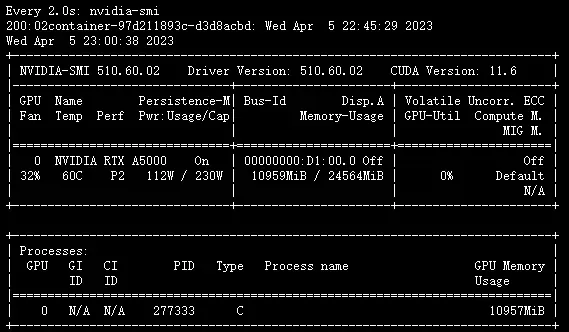
添加图片注释,不超过 140 字(可选)
显存占用10GB左右。
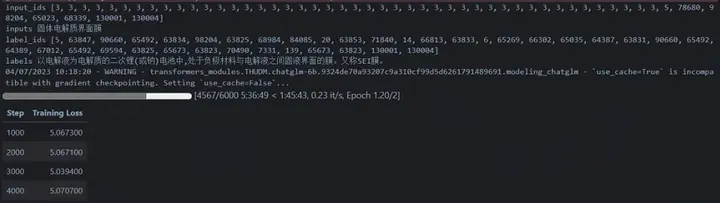
大家肯定很好奇10000步的时候ptuning V2 在chatglm 6B模型上的表现。

添加图片注释,不超过 140 字(可选)
而结果中的损失依旧让人看起来比较窒息。损失一直降不下去。
2023 04 07 实验
控制语料严格符合输入长度小于128输出长度小于512、学习率1e-3。
添加图片注释,不超过 140 字(可选)
前4000个epoch表现效果如上。依旧不理想。损失竟然变得更大了。
把官方代码通过修改bash为多卡运行。
PRE_SEQ_LEN=128 LR=2e-2 CUDA_VISIBLE_DEVICES=0,1 python3 main.py \ –do_train \ –train_file AdvertiseGen/train.json \ –validation_file AdvertiseGen/dev.json \ –prompt_column content \ –response_column summary \ –overwrite_cache \ –model_name_or_path THUDM/chatglm-6b \ –output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \ –overwrite_output_dir \ –max_source_length 64 \ –max_target_length 64 \ –per_device_train_batch_size 1 \ –per_device_eval_batch_size 1 \ –gradient_accumulation_steps 16 \ –predict_with_generate \ –max_steps 3000 \ –logging_steps 10 \ –save_steps 1000 \ –learning_rate $LR \ –pre_seq_len $PRE_SEQ_LEN \ –quantization_bit 8
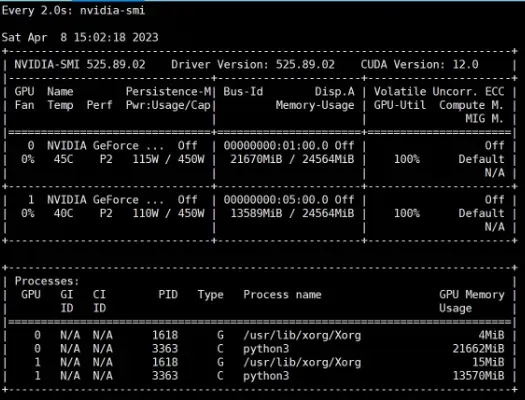
添加图片注释,不超过 140 字(可选)
不过目前看如果是简单的将训练代码中的显卡序号添加为多卡。

单卡训练需要两个小时

多卡需要30个小时
单卡两小时训练完,多卡30个小时训练完成。而多卡的显卡利用率竟然是百分之百。所以简单的将模型横向并行在某些设备上是不可取的。
20230408,zero_nlp的多卡分层并行训练目前出现了一些小问题。
痛定思痛,为什么官方的数据集表现得很好,但是我的数据集表现得并不是那么好呢。于是我准备给我的数据集截图看一看到底是哪里出现了问题。
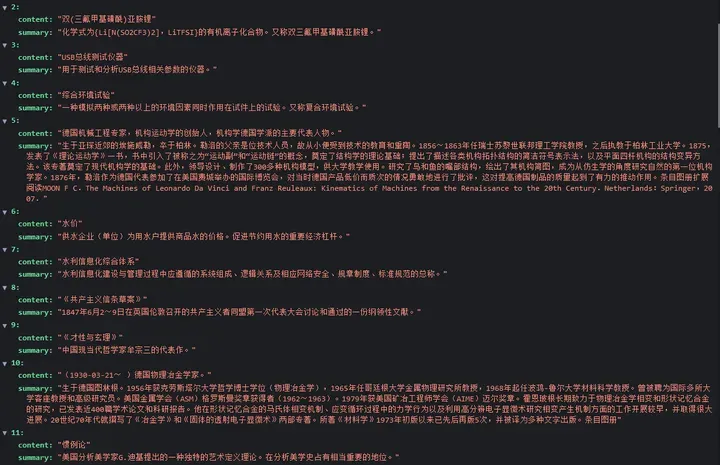
添加图片注释,不超过 140 字(可选)
从中国大百科爬下来的数据,有一些标题的输入是比较短的。那么好,接下来我准备加入数据最短长度的限制。
喜欢大模型的小伙伴可以加我的 15246115202 一起交流训练大模型所需要的细节都有哪些。
目前官方给了三个交互解决方案。基于终端的交互,基于简单界面的交互,基于fastapi框架提供的接口进行交互。
文章出处登录后可见!