应用于图像的自注意力机制
自注意力机制应用于图像主要结合CNN或transformer实现相关任务,如图像分割、识别和定位等。
自注意力可以分为对通道的或对空间的自注意力,或者两者的结合
参考原文:Pytorch 图像处理中注意力机制的解析与代码详解
经典网络模型1——SENet 详解与复现
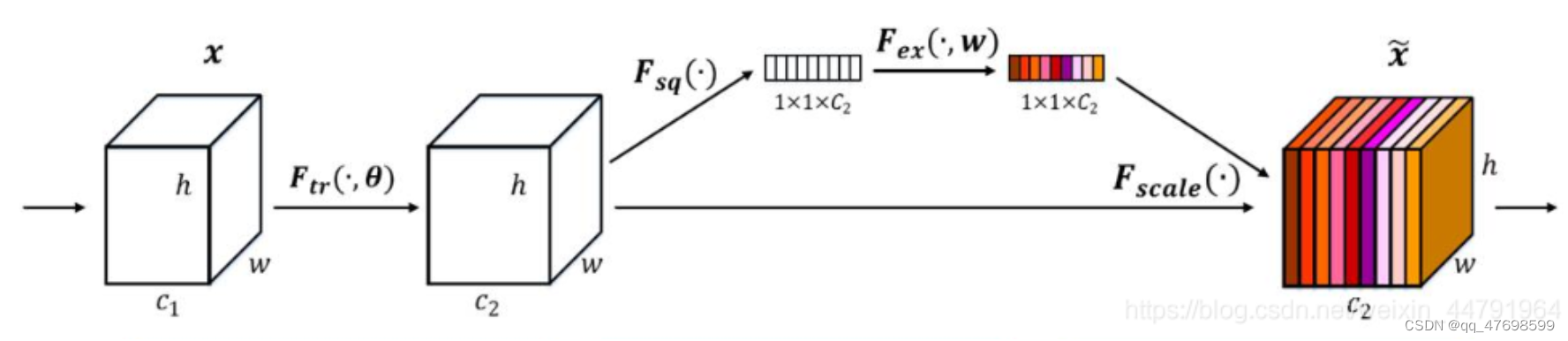
SENet
SENet使用了通道注意力机制
如下图所示,SENet是将原始数据通过一个卷积操作Ftr,得到c2通道h高w宽的数据,然后再使用全局池化(avgpooling平均池化)将h*w降阶为平均值,则输出数据为C2通道的1高1宽,再通过两个全连接操作得到其注意力向量,将通道注意力与池化前的输入相乘,再使用Sigmoid将值固定到0-1之间,此时我们获得了输入特征层每一个通道的权值,之后将注意力矩阵与未经降维前的矩阵相乘,得到最终的输出。
CBAM
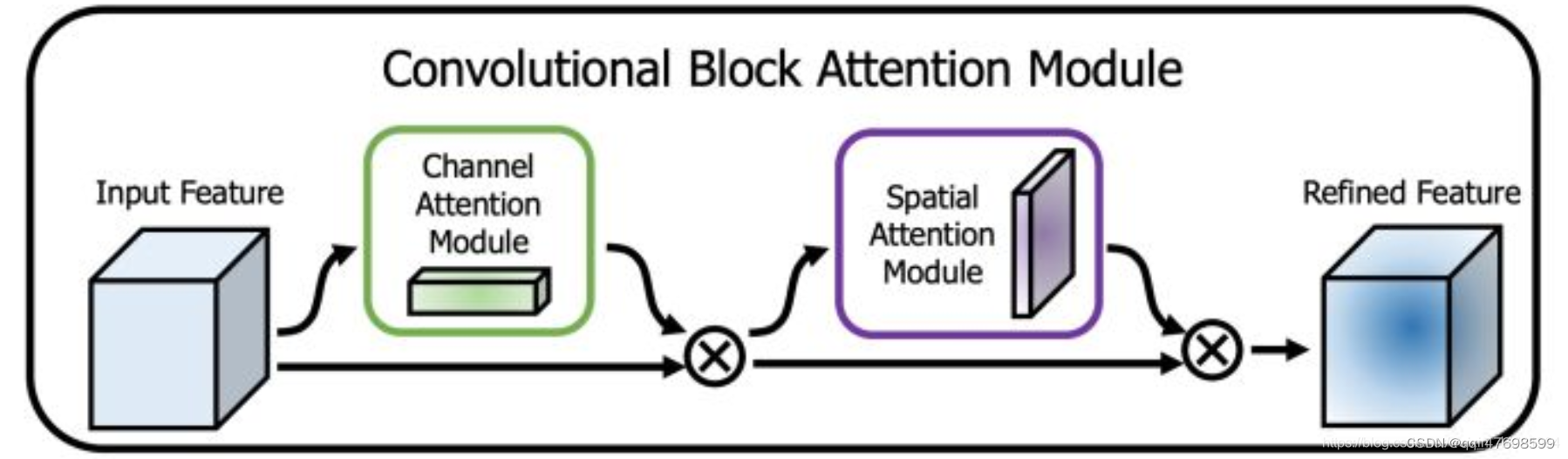
CBAM使用了通道注意力和空间注意力结合
下面是CBAM的整体结构,先进行了通道注意力的运用,再使用空间注意力机制
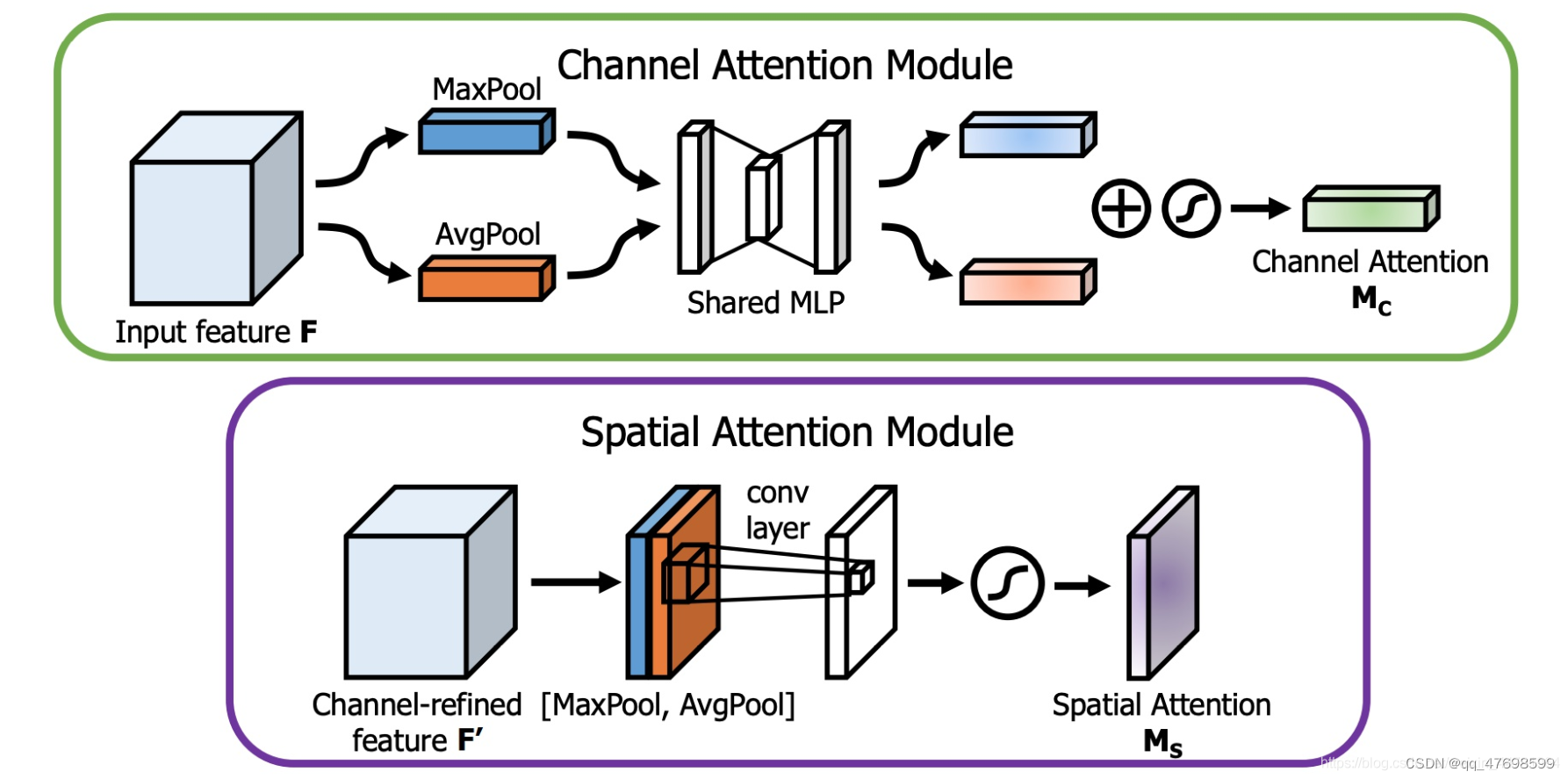
下图的上部分是通道注意力机制,将输入数据使用最大池化和平均池化将数据降维(保留通道维度),然后再通过全连接层(这里可以用1维卷积代替)进行信息综合,最后相加输出的两个向量,通过sigmoid将值放缩到0-1区间,得到注意力
下图的下半部分是空间注意力机制,将输入数据使用最大池化和平均池化将数据降维(整合通道维度),然后使用卷积将两个池化后的数据通道综合(卷积先对h*w维度进行处理,再将多个通道数据相加),最后经过sigmoid得到空间注意力
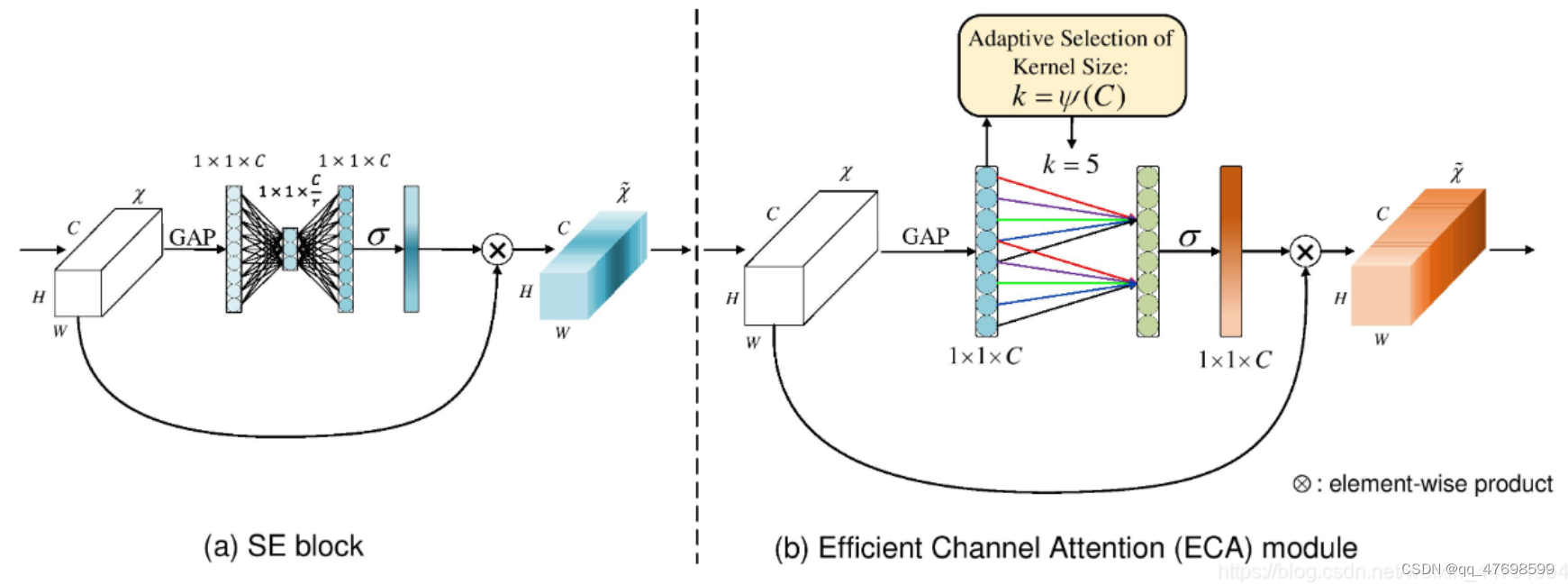
ECA
相较于传统的SENet模型,ECA不同的点是其使用1D卷积算子对avgpooling之后的向量进行了信息综合,而不是使用全连接。
上面主要需要明白注意力在图像上的体现:
- 通道上就是先综合其他维度信息,综合处理降维后的通道向量,最后附加注意力
- 空间上先综合通道维度信息,得到图像尺寸数据,再通过卷积等方式进行综合2D数据信息
yolo浅析
参考博文:写给小白的YOLO介绍
Pytorch搭建YoloV4目标检测平台
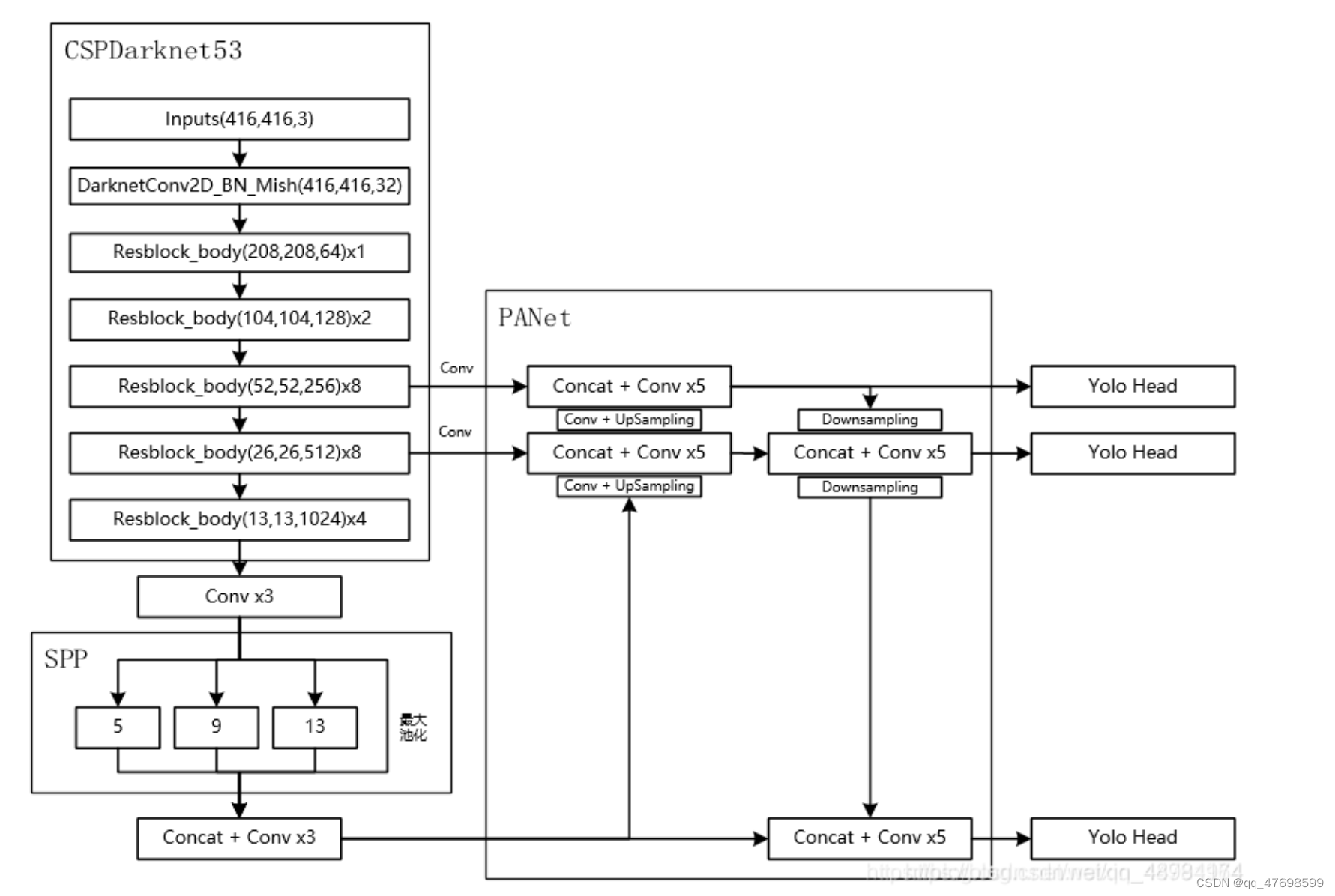
CSPDarkNet53学习
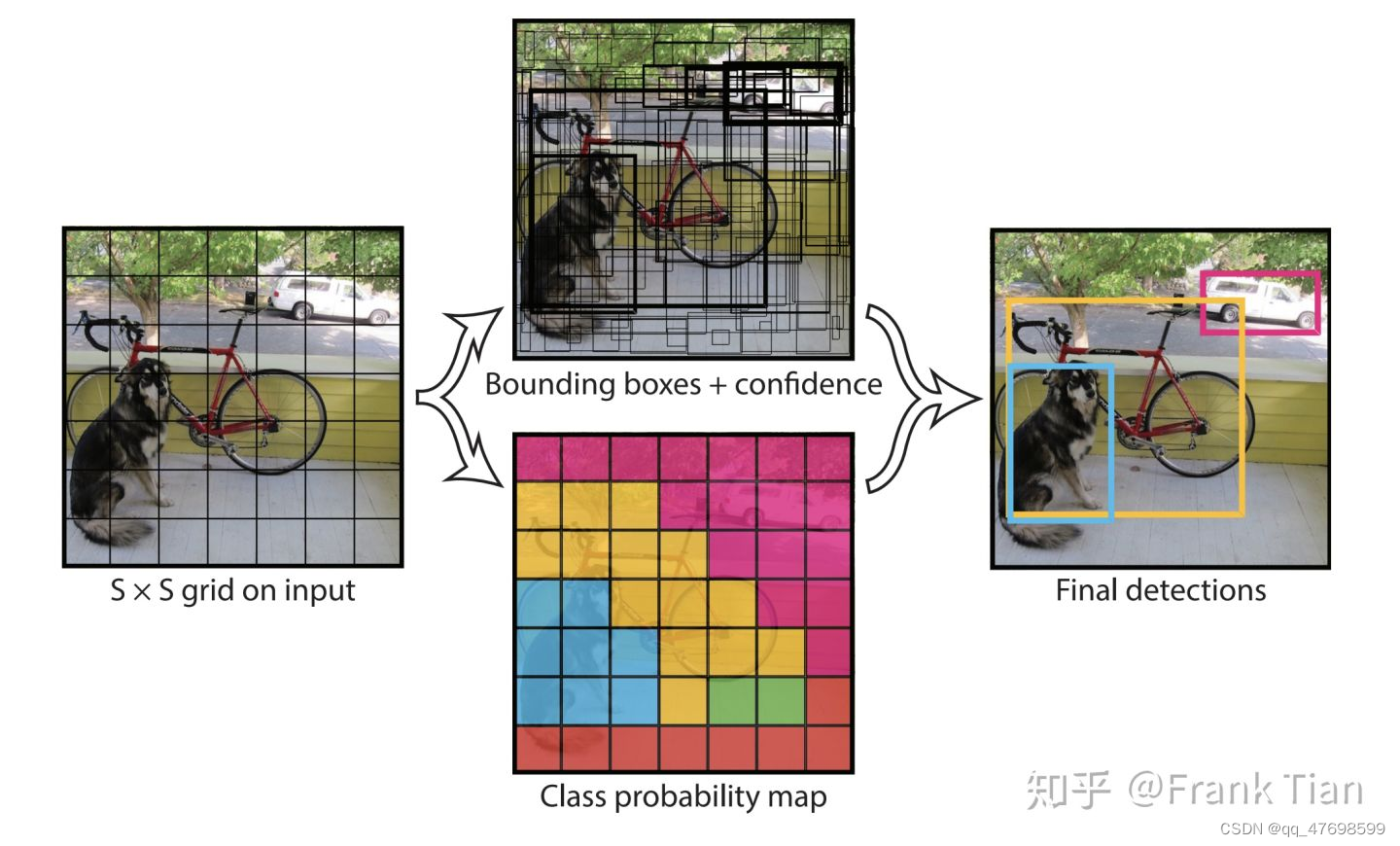
YOLO是目标检测模型,利用grid、bounding box、confidence、中心点坐标、预测长宽来实现一张图像中多个目标的识别、定位、分类和分割。
yolo的思想:将一张图像分割为多个块,形成一个grid,再在一个网格中预测B个Bounding Box,Box的中心一定在网格内,Box的属性还有长宽,分类信息另外表示,由grid每个网格来预测该网格中的对象属于什么类别。对于图像的多目标检测,还引入了非极大值抑制技术,再多个grid都被预测为统一类别且相邻时,选择这些grid中置信度最高的一个Bounding Box,再取这群Box中置信度最高的,以该Box为基础,判断与其他Box之间的IOU,超过则包含进来,否则剔除。
CSPDarkNet53
该方法相对于DarkNet的改进:1. 使用了mish激活函数,使得梯度更加平滑,收敛效果更好;2. 改善了resblock的结构,分流执行处理。
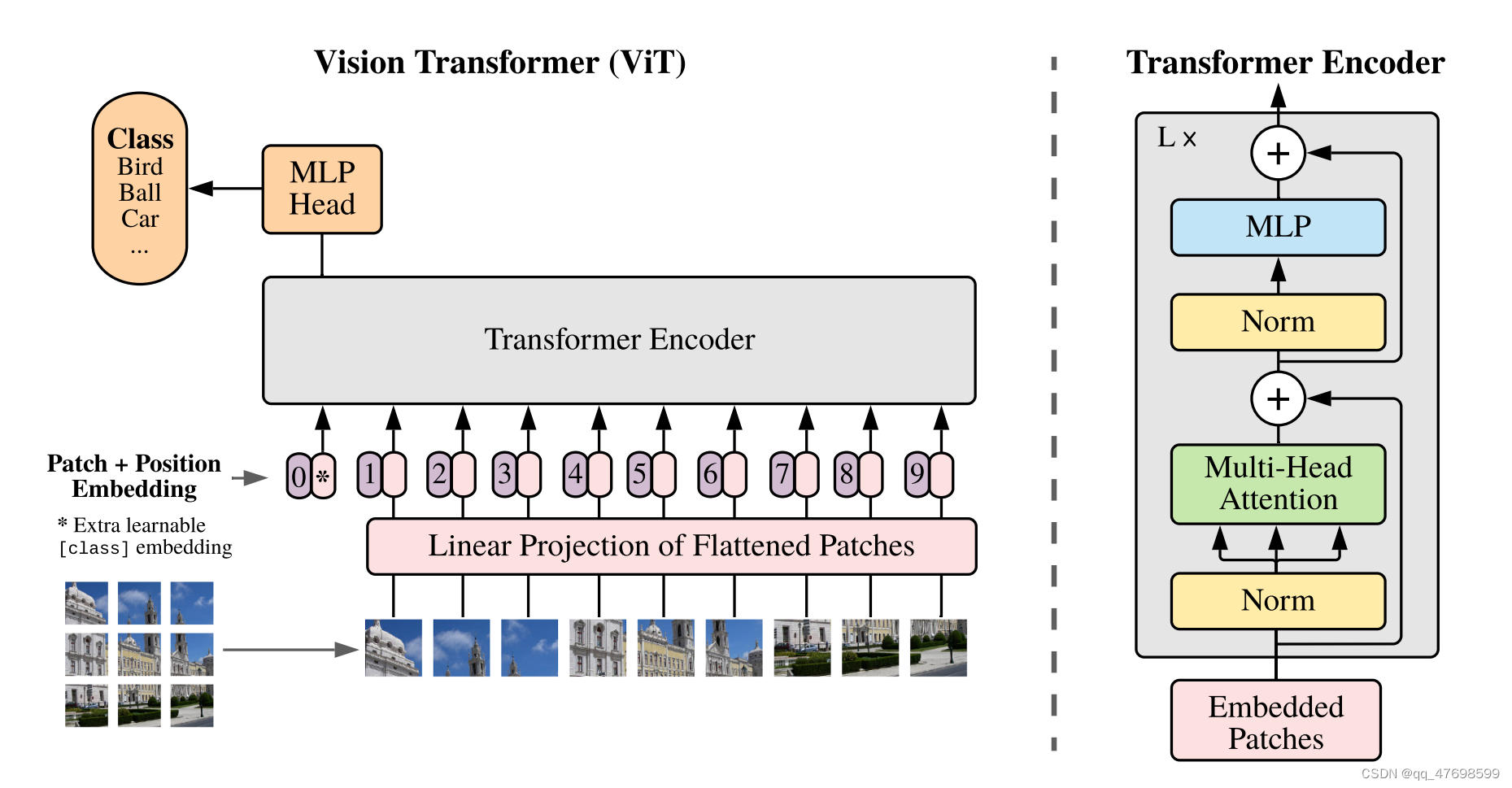
ViT
ViT实现的是将图像分割为多个patches,再继续linear embedding,利用transformer encoder输出,再通过多层感知机处理,得到最终的class分类可能性
文章出处登录后可见!