本文章由三部分组成:
1.Segment Anything Model(SAM)概述:是我学习概念做的记录可以不看直接跳过。
2.SAM衍生的标注工具使用:试用了两个开源的SAM衍生的标注工具记录
3.遇到的问题
参考:
1.segment-anything官方demo演示
2.SA基础模型图像分割的介绍
3.segment-anything项目
一、Segment Anything Model(SAM)概述
Segment Anything Model(SAM)——致力于图像分割的第一个基础模型。
分割——识别哪些图像像素属于一个对象——是计算机视觉的核心任务之一。
Segment Anything项目是mata AI提出的一种用于图像分割的新任务、数据集和模型。发布了通用Segment Anything 模型 (SAM)和Segment Anything 1-Billion 掩码数据集 (SA-1B),这是有史以来最大的分割数据集。
Segment Anything 项目的核心是减少对特定于任务的建模专业知识、训练计算和用于图像分割的自定义数据注释的需求。目标是建立一个图像分割的基础模型:一个可提示的模型,它在不同的数据上进行训练并且可以适应特定的任务,类似于在自然语言处理模型中使用提示的方式。然而,与互联网上丰富的图像、视频和文本不同,训练这种模型所需的分割数据在网上或其他地方并不容易获得。因此,借助 Segment Anything,同时开发一个通用的、可提示的分割模型,并使用它来创建一个规模空前的分割数据集。
SAM 已经了解了对象是什么的一般概念,它可以为任何图像或任何视频中的任何对象生成掩码,甚至包括它在训练期间没有遇到的对象和图像类型。SAM 的通用性足以涵盖广泛的用例,并且可以开箱即用地用于新的图像“领域”——无论是水下照片还是细胞显微镜——无需额外培训(这种能力通常被称为零样本迁移)。
将来,SAM 可用于帮助需要在任何图像中查找和分割任何对象的众多领域中的应用程序。对于 AI 研究社区和其他人来说,SAM 可以成为更大的 AI 系统的一个组成部分,用于对世界进行更一般的多模态理解,例如,理解网页的视觉和文本内容。在 AR/VR 领域,SAM 可以根据用户的视线选择对象,然后将其“提升”为 3D。对于内容创作者,SAM 可以改进创意应用,例如提取图像区域以进行拼贴或视频编辑。SAM 还可用于帮助对地球上甚至太空中的自然事件进行科学研究,例如,通过定位动物或物体以在视频中进行研究和跟踪。可能性是广泛的,
通用性
以前,要解决任何类型的分割问题,有两类方法。第一种是交互式分割,允许分割任何类别的对象,但需要一个人通过迭代细化掩码来指导该方法。第二种,自动分割,允许分割提前定义的特定对象类别(例如,猫或椅子),但需要大量的手动注释对象来训练(例如,数千甚至数万个分割猫的例子),连同计算资源和技术专长一起训练分割模型。这两种方法都没有提供通用的、全自动的分割方法。
SAM 是这两类方法的概括。它是一个单一的模型,可以轻松地执行交互式分割和自动分割。该模型的可提示界面允许以灵活的方式使用它,只需为模型设计正确的提示(点击、框、文本等),就可以完成范围广泛的分割任务。此外,SAM 在包含超过 10 亿个掩码(作为该项目的一部分收集)的多样化、高质量数据集上进行训练,这使其能够泛化到新类型的对象和图像,超出其在训练期间观察到的内容。这种概括能力意味着从业者将不再需要收集他们自己的细分数据并为他们的用例微调模型。
这些功能使 SAM 能够泛化到新任务和新领域。这种灵活性在图像分割领域尚属首创。
SAM功能描述
(1)允许用户通过单击或通过交互式单击点来分割对象以包含和排除对象。还可以使用边界框提示模型。
(2) 在面对被分割对象的歧义时可以输出多个有效掩码,这是解决现实世界中分割问题的重要且必要的能力。
(3) 可以自动发现并屏蔽图像中的所有对象。
(4) 可以在预计算图像嵌入后实时为任何提示生成分割掩码,允许与模型进行实时交互。
介绍
基础模型是一个很有前途的发展,它可以通过使用“提示”技术对新的数据集和任务执行零样本和少样本学习。
基于基础模型在NLP领域的成功实现,同样的在计算机视觉领域中也开始了基础模型的探索。例如,CLIP和ALIGN使用对比训练来对齐两种模式的图像和文本编码器。设计的文本提示可以对新的视觉概念和数据分布进行零概率泛化。这种编码器还可以与其他模块有效组合,以实现下游任务,例如图像生成。虽然在视觉和语言编码器方面已经取得了很大的进展,但计算机视觉包括超出这个范围的广泛问题,并且对于其中的许多问题,没有丰富的训练数据。
**任务:**目标是建立一个图像分割的基础模型,寻求开发一个提示模型,并使用一个能够实现强大泛化的任务在广泛的数据集上对其进行预训练。有了这个模型就能够使用即时工程解决新数据分布上的一系列下游分割问题。
提出了一个提示分割任务,目标是在给定任何分割提示的情况下返回一个有效的分割掩码。
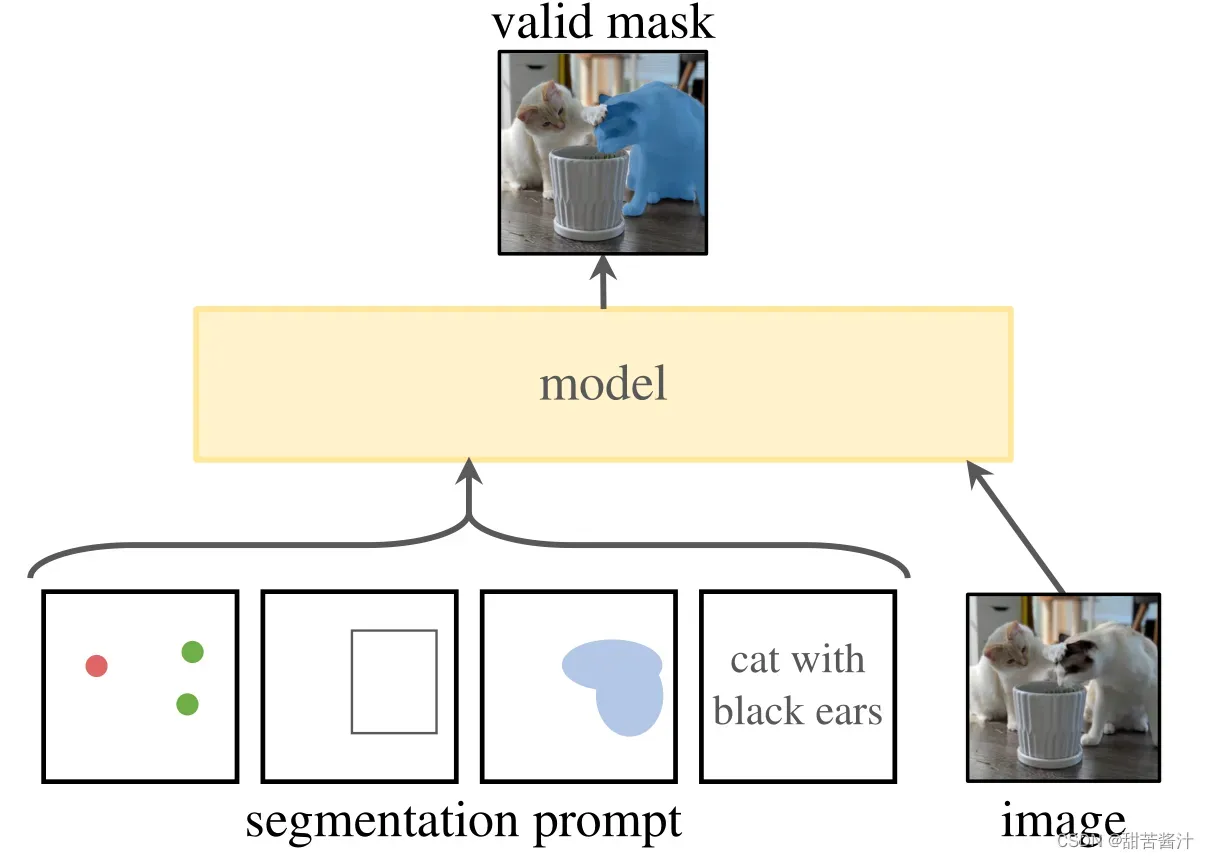
提示符只是指定图像中要分割的内容,例如,提示符可以包括识别对象的空间或文本信息。有效输出掩码的要求意味着,即使提示是模糊的,并且可能引用多个对象(例如,衬衫上的一个点可能表示衬衫或穿着它的人),输出也应该是这些对象中至少一个对象的合理掩码。使用提示分割任务作为预训练目标,并通过提示工程解决一般的下游分割任务。
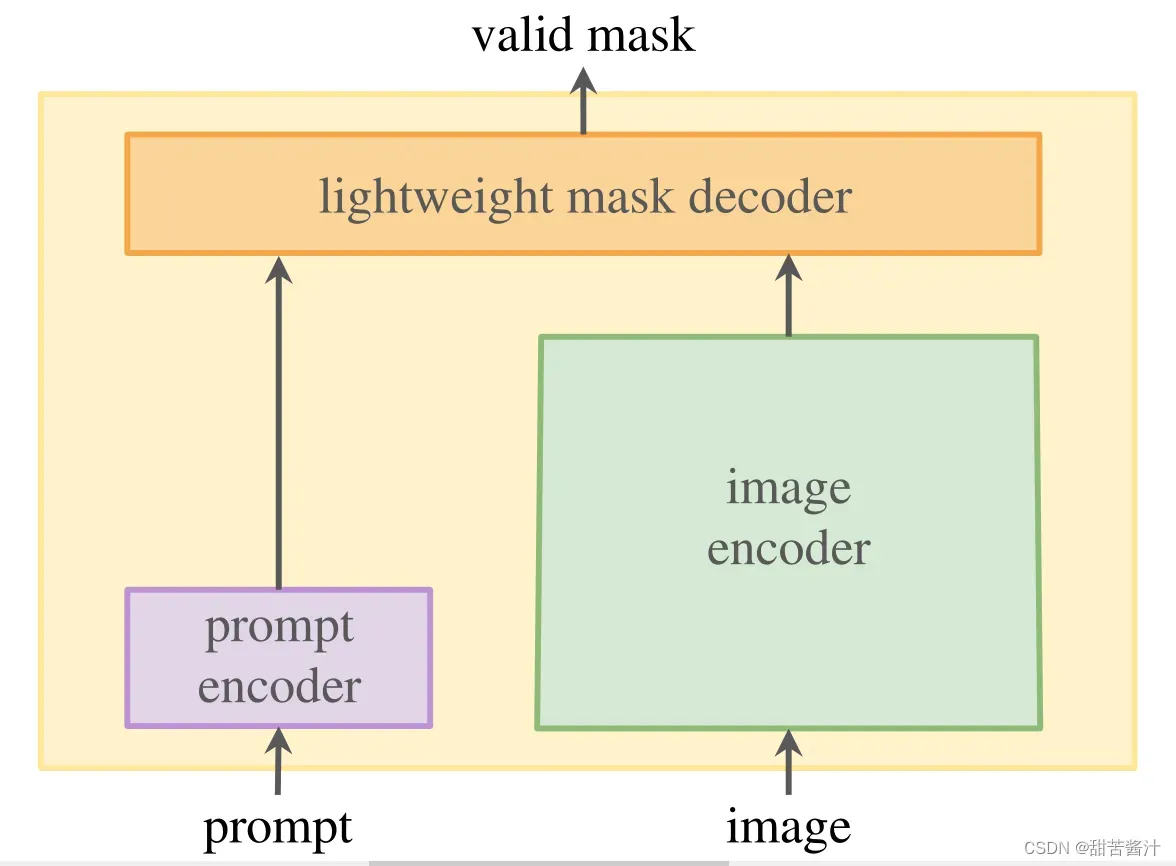
**模型:**可提示的分割任务和实际的目标对模型体系结构施加了约束。模型必须支持灵活的提示,需要在平摊实时中计算掩码以允许交互使用,并且必须具有歧义意识。
一个简单的设计可以满足所有三个约束:一个强大的图像编码器计算图像嵌入,一个提示编码器嵌入提示,然后将两个信息源组合在一个轻量级的掩码解码器中,该解码器预测分割掩码。我们将此模型称为分段任意模型(Segment Anything model,简称SAM)。通过将SAM分为图像编码器和快速提示编码器/掩码解码器,可以使用不同的提示重复使用相同的图像嵌入(并平摊其成本)。
给定图像嵌入,提示编码器和掩码解码器在web浏览器中从提示符预测掩码,时间为~ 50ms。将重点放在点、框和掩码提示上,并使用自由格式的文本提示来呈现初始结果。为了使SAM能够感知歧义,将其设计为预测单个提示的多个掩码,从而允许SAM自然地处理歧义,例如衬衫与人的例子。
**数据引擎:**有三个阶段:辅助手动、半自动和全自动。在第一阶段,SAM帮助注释者注释掩码,类似于经典的交互式分段设置。在第二阶段,SAM可以通过提示可能的目标位置来自动为目标子集生成掩码,而注释器则专注于注释剩余的目标,从而帮助增加掩码的多样性。在最后阶段,用前景点的规则网格提示SAM,平均每张图像产生约100个高质量掩模。
**实验:**广泛评估SAM。首先,使用23个不同的新分割数据集,我们发现SAM从单个前景点产生高质量的掩模,通常仅略低于手动注释的地面真值。其次,在零样本传输协议下使用即时工程的各种下游任务上发现了一致的强定量和定性结果,包括边缘检测,目标提案生成,实例分割以及文本到掩码预测的初步探索。这些结果表明,SAM可以使用开箱即用的快速工程来解决涉及SAM训练数据之外的对象和图像分布的各种任务。
任务
提示分割任务是在给定任何提示的情况下返回一个有效的分段掩码。
提示分割任务目标是制造一个功能广泛的模型,可以通过快速工程适应许多(尽管不是全部)现有的和新的分割任务。在这些工作中,经过提示分割训练的模型可以作为一个更大系统中的一个组件,在推理时间执行一个新的、不同的任务,
提示和组合是功能强大的工具,可以以可扩展的方式使用单个模型,从而潜在地完成模型设计时未知的任务。预计,可组合的系统设计,由提示工程等技术提供动力,将比专门为固定任务集训练的系统实现更广泛的应用。
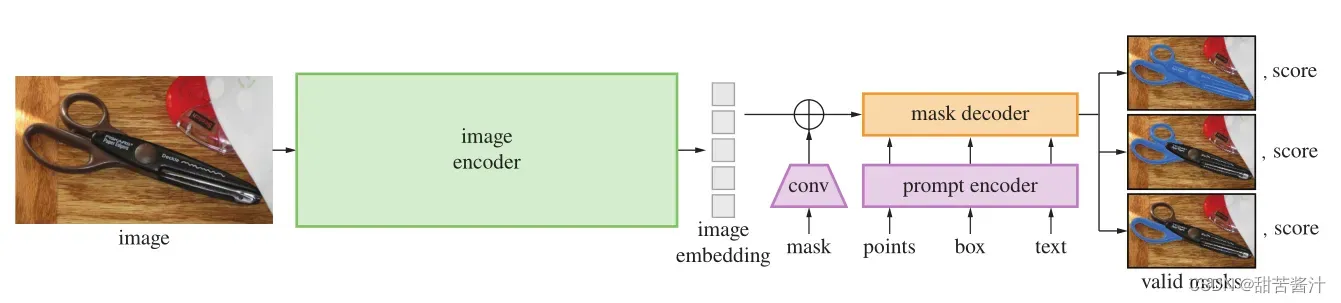
重量级图像编码器输出图像嵌入,然后可以通过各种输入提示有效地查询,以平摊实时速度生成对象掩码。对于对应于多个目标的模糊提示,SAM可以输出多个有效掩码和相关的置信度分数。
一个图像编码器,一个灵活的提示编码器和一个快速掩码解码器。
图像编码器:受可扩展性和强大的预训练方法的推动,我们使用 MAE 预训练的 VisionTransformer (ViT),最低限度地适应处理高分辨率输入。 图像编码器每张图像运行一次,可以在提示模型之前应用。
提示编码器:考虑两组提示:稀疏(points, boxes, text) 和 密集 (masks)。 通过位置编码和每个提示类型的学习嵌入相加来表示点和框,并使用来自 CLIP 的现成文本编码器来表示自由格式文本。 密集提示(即掩码)使用卷积嵌入,并与图像嵌入逐元素求和。
掩码解码器:掩码解码器有效地将图像嵌入、提示嵌入和输出令牌映射到掩码。采用修改过后的Transformer解码器块,然后是动态掩码预测头。改进的解码器块在两个方向上使用提示自注意和交叉注意(提示到图像嵌入,反之亦然)来更新所有嵌入。在运行两个块之后,对图像嵌入进行上采样,MLP将输出标记映射到动态线性分类器,然后该分类器计算每个图像位置的掩码前景概率。
整体模型设计很大程度上是由效率驱动的。给定预先计算的图像嵌入,提示编码器和掩码解码器在web浏览器中运行,在CPU上,大约50ms。这种运行时性能支持模型的无缝、实时交互式提示。
数据引擎有三个阶段:(1)模型辅助的手动注释阶段,(2)混合了自动预测掩码和模型辅助注释的半自动阶段,以及(3)模型在没有注释器输入的情况下生成掩码的全自动阶段。
二、SAM衍生的标注工具使用
尝试过的项目:
1.https://github.com/haochenheheda/segment-anything-annotator
2.https://github.com/anuragxel/salt
3.https://github.com/zhouayi/SAM-Tool(和2.的salt差不多,我这里没有尝试)
note:这里的两个项目我在服务器上开启标注工具会报错(见三),都选择在windows上使用。
两个项目都按照git上配好环境,按照步骤就可以操作们这里不详细演示。
SAA项目:https://github.com/haochenheheda/segment-anything-annotator
1.启动标注平台
python annnotator.py --app_resolution 1000,1600 --model_type vit_b --keep_input_size True --max_size 720
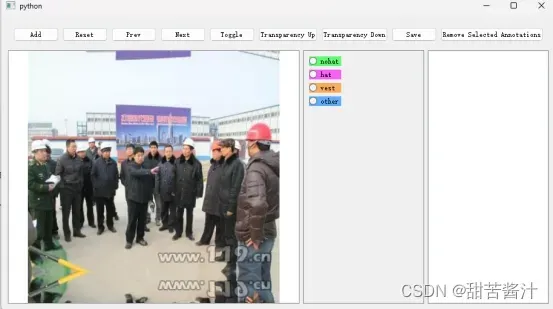
界面如下:
–model_type: vit_b, vit_l, vit_h
–keep_input_size: True: 保留 SAM 的原始图像大小;False:将输入图像调整为–max_size(节省 GPU 内存)
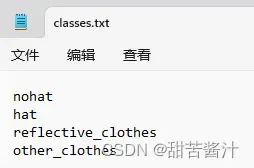
2.类别的txt文件

其中的classes.txt内容如下(数据集的标签):
在界面中点击
3.指定图像文件夹和标签存放文件夹
4.加载SAM模型
![]()
点击后终端会出现:

4.其他功能
经过以上操作界面如图所示:
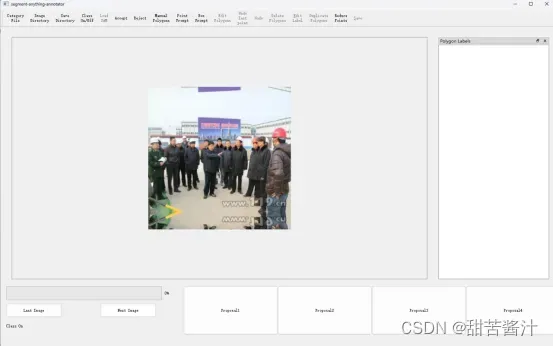
Zoom in/out:按“CTRL”和鼠标滚轮 调整大小
手工绘制:
![]()
通过点击对象的边界手动添加mask,按下右键并拖动绘制弧线。
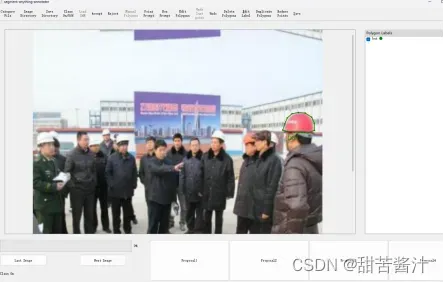
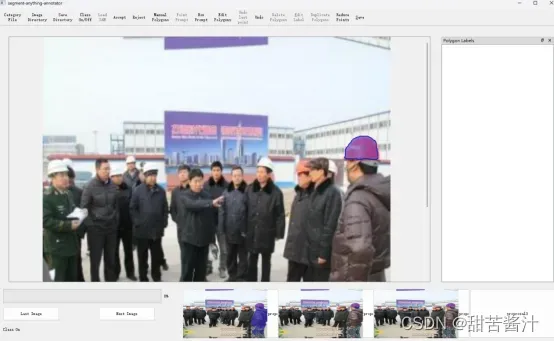
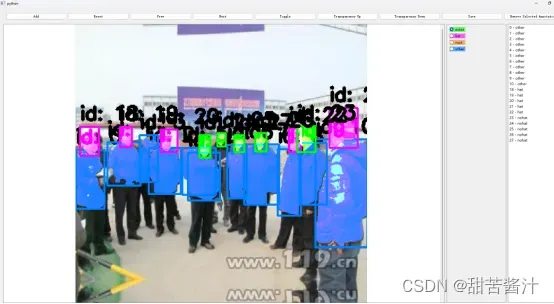
通过点击生成mask proposal。鼠标左键/右键分别代表正/负点击。在下面的框中看到几个mask proposal:可以通过单击或快捷键1、2、3、4。
操作:点击point promopt,选择1234,点击a。
这里选择3,然后点击a选择标签:
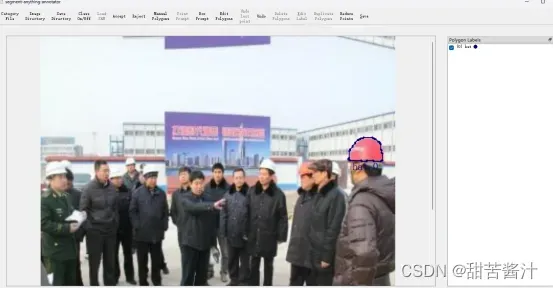
生成带有框的mask proposal
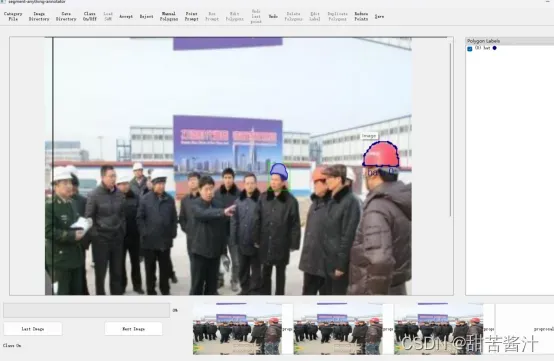
Accept(快捷键:a):接受选择的建议并添加到注释栏。
Reject(快捷方式r:):拒绝建议并清理工作区。
可以修改注释对象,通过双击注释栏中的对象项来更改类别标签或id;通过拖动边界上的点来修改边界。
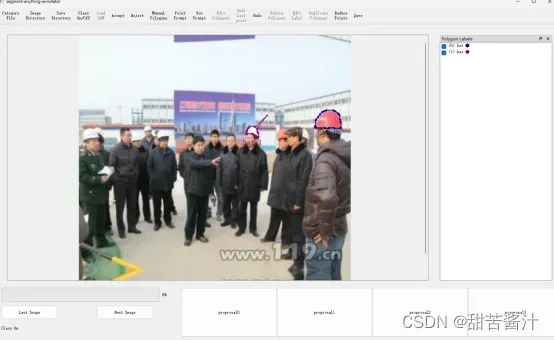
Delete(快捷键:‘d’):Edit Mode,从注释停靠栏中删除选定/突出显示的对象
Edit Mode,如果多边形太密集无法编辑,可以使用此按钮减少所选多边形上的点。但这会略微降低注释质量。
其他:
Zoom in/out:按“CTRL”和鼠标滚轮
Class On/Off:如果开启了Class,接受掩码后会出现一个对话框来记录类别和id,否则catgeory将是默认值“Object”。
编辑完需要点击
储存否则会丢失。
完成后,savedir中便会生成json文件:
[
#object1
{
‘label’:,
‘group_id’:,
‘shape_type’:‘polygon’,
‘points’:[[x1,y1],[x2,y2],[x3,y3],…]
},
#object2
…
]
SALT项目https://github.com/anuragxel/salt
1.转onnx:

转出的onnx模型:
2.提取数据集所有图像的embeddings
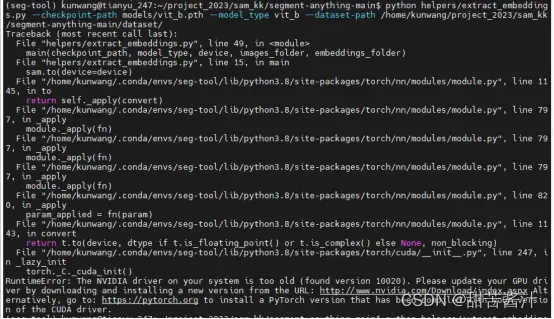
python helpers/extract_embeddings.py --checkpoint-path models/vit_b.pth --model_type vit_b --dataset-path /home/kunwang/project_2023/sam_kk/segment-anything-main/dataset/
报错:英伟达驱动版本过低
因此修改代码,device使用cpu
“/home/kunwang/project_2023/sam_kk/segment-anything-main/helpers/extract_embeddings.py”

可以看到,路径:
/home/kunwang/project_2023/sam_kk/segment-anything-main/dataset/embeddings/下生成了对应的embeddings:
note:
由于在服务器上还是遇到了错误(见三)。
因此在windows配环境 (一些依赖和linux下的不同,找到对应的win64即可)
如该项目中environment.yaml中要求conda安装ncurses=6.4 ,这里在win中就用conda安装win-ncurses,在官网中找对应版本。有时候会报冲突,能安装相近的版本也可以。
进入salt-main路径下:
运行命令:
python segment_anything_annotator.py --categories "nohat,hat,vest,other"

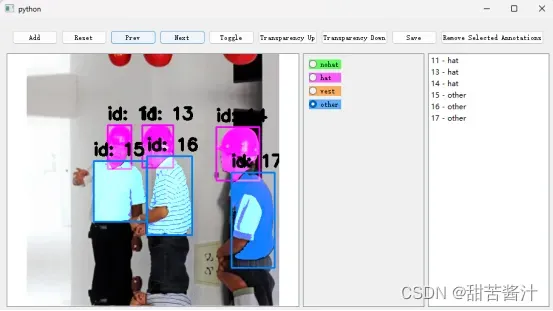
生成的部分json展示:
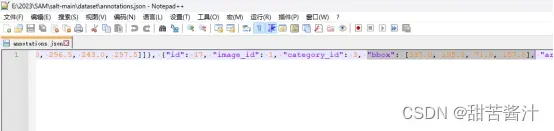
总的来说使用这个工具要分两步
1.转onnx模型,对dataset所有待标注的图片生成embeddings
2.打开标注工具进行标注
优点:可以生成标注框。
缺点:以上两个项目中工具并存的,密集目标标注起来效果一般费时间(sam自身缺点引起的)。
三、遇到问题
项目1和项目2requiments.txt安装之后,尝试启动标注平台:
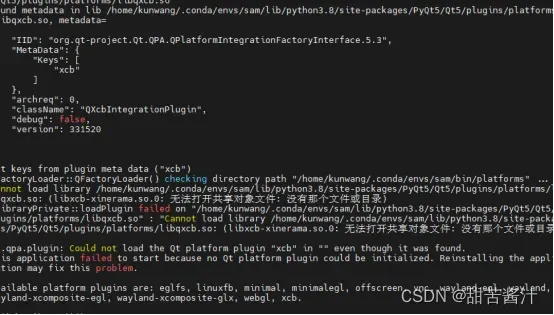
都会报错:
Got keys from plugin meta data (“xcb”)
QFactoryLoader::QFactoryLoader() checking directory path “/home/kunwang/.conda/envs/sam/bin/platforms” …
loaded library “/home/kunwang/.conda/envs/sam/lib/python3.8/site-packages/cv2/qt/plugins/platforms/libqxcb.so”
QObject::moveToThread: Current thread (0x55c4efa86610) is not the object’s thread (0x55c4f292d870).
Cannot move to target thread (0x55c4efa86610)
qt.qpa.plugin: Could not load the Qt platform plugin “xcb” in “/home/kunwang/.conda/envs/sam/lib/python3.8/site-packages/cv2/qt/plugins” even though it was found.
This application failed to start because no Qt platform plugin could be initialized. Reinstalling the application may fix this problem.
Available platform plugins are: xcb, eglfs, linuxfb, minimal, minimalegl, offscreen, vnc, wayland-egl, wayland, wayland-xcomposite-egl, wayland-xcomposite-glx, webgl.
解决:
1.尝试重新安装opencv-python、降低opencv-python版本,都还是报错。
并且我没有sudo权限,因此这个方法无法解决,最后才选择了在win下启动标注。
搜索相关问题是PyQt5和Opencv的冲突(待解决)
参考:
1.http://www.manongjc.com/detail/63-wjnshoygnkrqpsf.html
2.https://www.cnblogs.com/isLinXu/p/15876688.html
因为OpenCV的版本过高,与pyqt5的读写不兼容—无法解决
3.https://github.com/opencv/opencv-python/issues/46 问题集合
但我用了以上方法都未解决【悲】。
有用的:
4.https://zhuanlan.zhihu.com/p/471661231
5.https://blog.csdn.net/hxxjxw/article/details/115936461
6.https://my.visualstudio.com/Downloads?q=build%20tools
文章出处登录后可见!