前言
提示:记录一下自己的第一个博客,写点啥呢????要么写点理论吧,代码后续准备录制视频讲解
提示:以下是本篇文章正文内容,下面案例可供参考
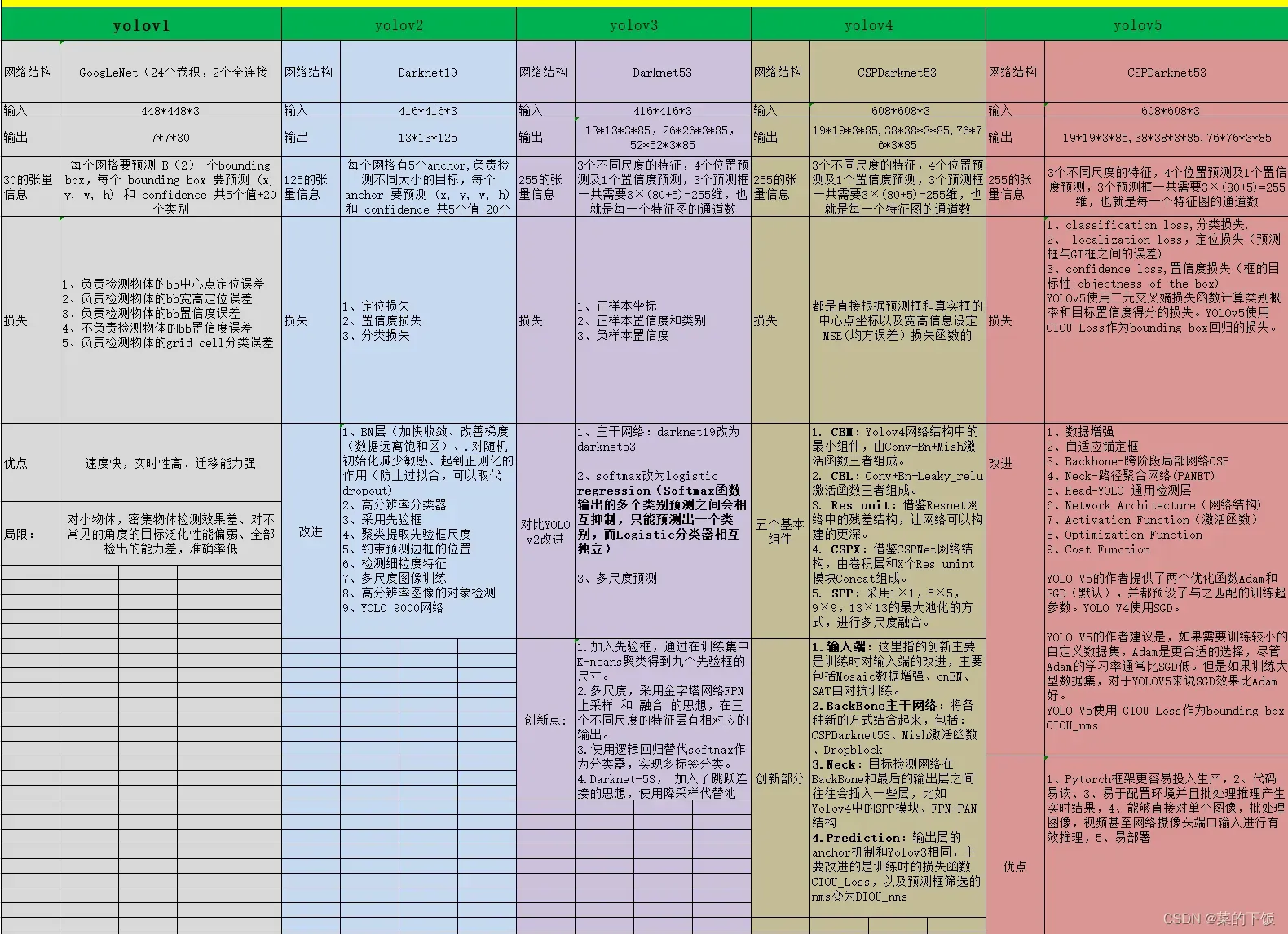
一、yolov1-v5表格图
这张图是在找工作前,回忆yolo系列的发展历程,进行梳理的图。内容可能有一些不准确的地方,请指出。
只是提到一个看图回忆的作用,脑中形成一个体系
二、YOLOv5网络结构
1.网络结构
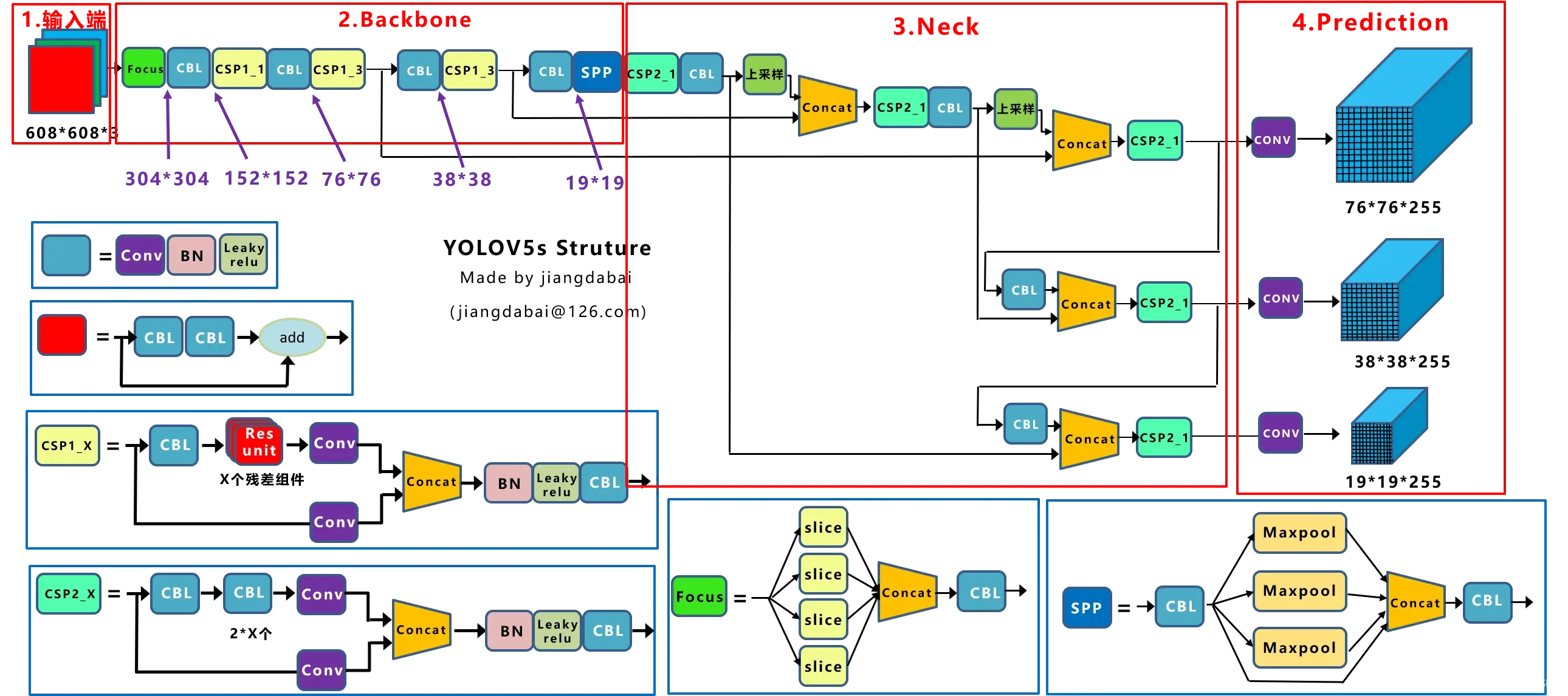
- 输入端:Mosaic数据增强、自适应锚框计算
- Backbone:Focus结构,CSP结构
- Neck:FPN+PAN结构
- Prediction:GIOU_Loss(后已经将CIOU、DIOU集成进代码内,默认为CIOU_loss)
(1.1)Mosaic数据增强
mosaic数据增强则利用了四张图片,对四张图片进行拼接,每一张图片都有其对应的框框,将四张图片拼接之后就获得一张新的图片,同时也获得这张图片对应的框框,然后我们将这样一张新的图片传入到神经网络当中去学习,相当于一下子传入四张图片进行学习了。论文中说这极大丰富了检测物体的背景!且在标准化BN计算的时候一下子会计算四张图片的数据!如下图所示:
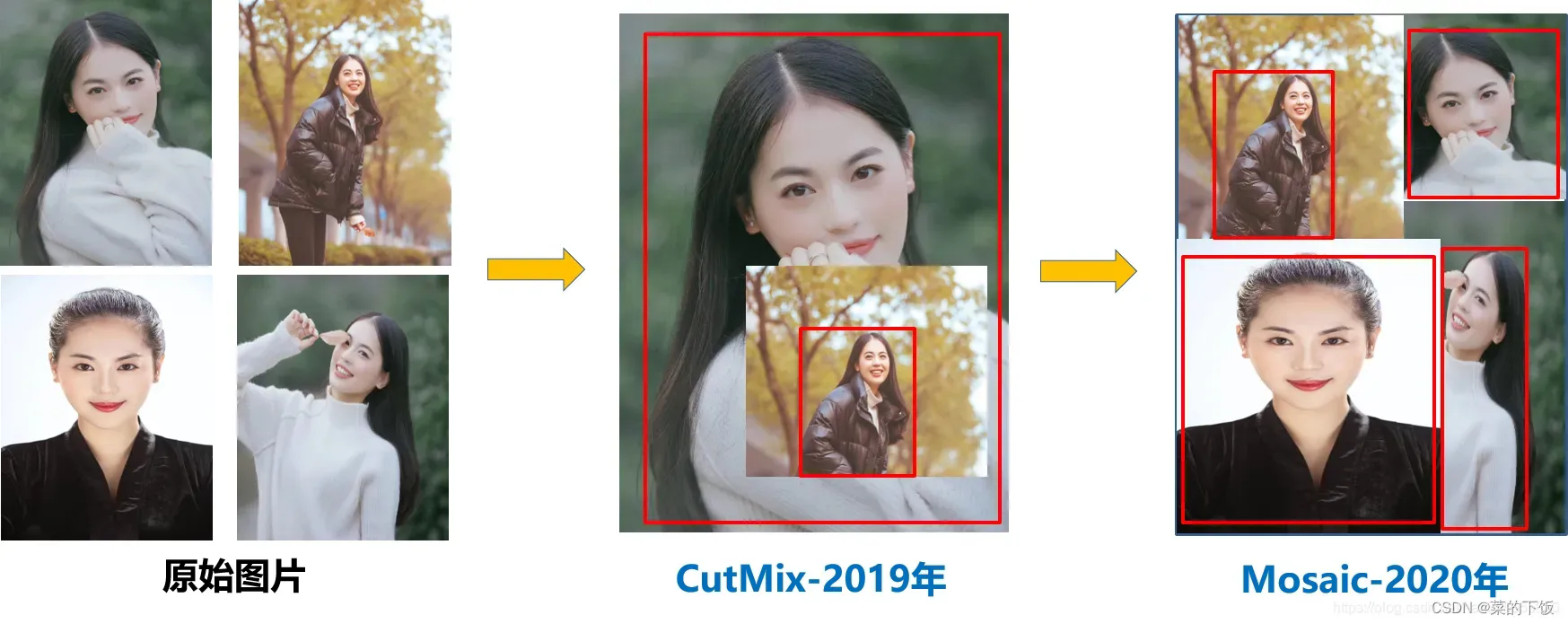
1、首先随机取四张图片
2、分别对四张图片进行数据扩增操作,并分别粘贴至与最终输出图像大小相等掩模的对应位置。
1、翻转(对原始图片进行左右的翻转);
2、缩放(对原始图片进行大小的缩放);
3、色域变化(对原始图片的明亮度、饱和度、色调进行改变)等操作。
3、进行图片的组合和框的组合
这个yaml文件,是控制数据增强的。设置百分比来控制增强的比例。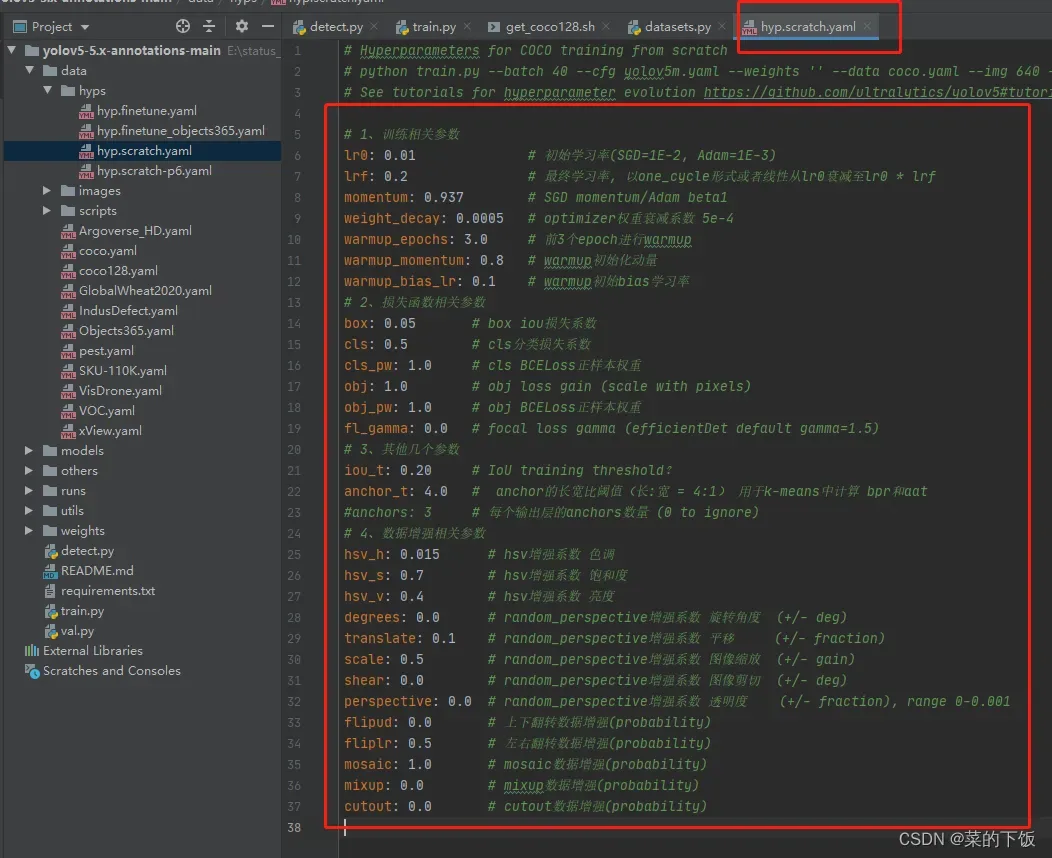
这块代码就是数据增强了,有Mosaic、mixup、random_perspective、Augment colorspace等等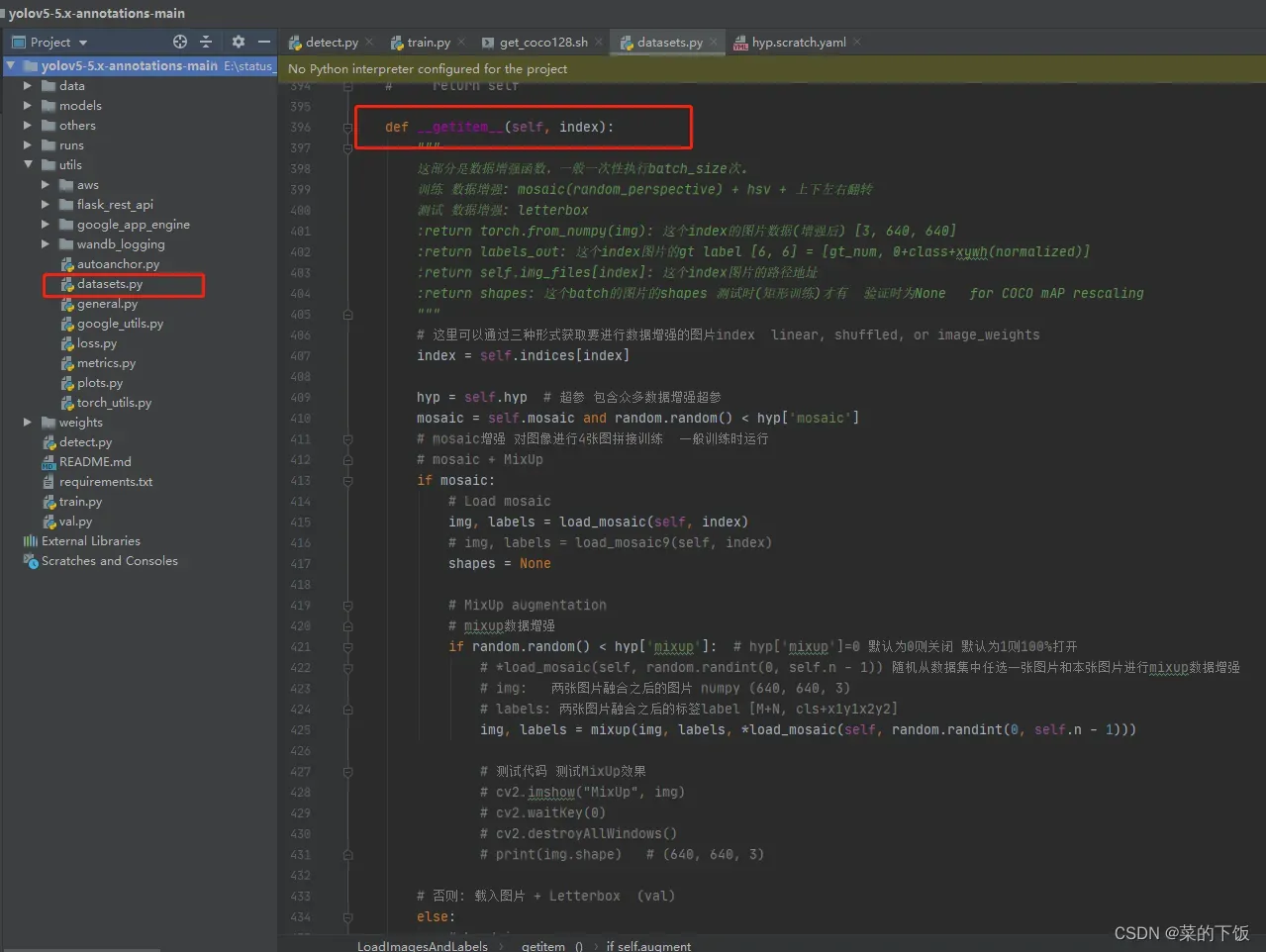
def __getitem__(self, index):
"""
这部分是数据增强函数,一般一次性执行batch_size次。
训练 数据增强: mosaic(random_perspective) + hsv + 上下左右翻转
测试 数据增强: letterbox
:return torch.from_numpy(img): 这个index的图片数据(增强后) [3, 640, 640]
:return labels_out: 这个index图片的gt label [6, 6] = [gt_num, 0+class+xywh(normalized)]
:return self.img_files[index]: 这个index图片的路径地址
:return shapes: 这个batch的图片的shapes 测试时(矩形训练)才有 验证时为None for COCO mAP rescaling
"""
# 这里可以通过三种形式获取要进行数据增强的图片index linear, shuffled, or image_weights
index = self.indices[index]
hyp = self.hyp # 超参 包含众多数据增强超参
mosaic = self.mosaic and random.random() < hyp['mosaic']
# mosaic增强 对图像进行4张图拼接训练 一般训练时运行
# mosaic + MixUp
if mosaic:
# Load mosaic
img, labels = load_mosaic(self, index)
# img, labels = load_mosaic9(self, index)
shapes = None
# MixUp augmentation
# mixup数据增强
if random.random() < hyp['mixup']: # hyp['mixup']=0 默认为0则关闭 默认为1则100%打开
# *load_mosaic(self, random.randint(0, self.n - 1)) 随机从数据集中任选一张图片和本张图片进行mixup数据增强
# img: 两张图片融合之后的图片 numpy (640, 640, 3)
# labels: 两张图片融合之后的标签label [M+N, cls+x1y1x2y2]
img, labels = mixup(img, labels, *load_mosaic(self, random.randint(0, self.n - 1)))
# 测试代码 测试MixUp效果
# cv2.imshow("MixUp", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img.shape) # (640, 640, 3)
# 否则: 载入图片 + Letterbox (val)
else:
# Load image
# 载入图片 载入图片后还会进行一次resize 将当前图片的最长边缩放到指定的大小(512), 较小边同比例缩放
# load image img=(343, 512, 3)=(h, w, c) (h0, w0)=(335, 500) numpy index=4
# img: resize后的图片 (h0, w0): 原始图片的hw (h, w): resize后的图片的hw
# 这一步是将(335, 500, 3) resize-> (343, 512, 3)
img, (h0, w0), (h, w) = load_image(self, index)
# 测试代码 测试load_image效果
# cv2.imshow("load_image", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img.shape) # (640, 640, 3)
# Letterbox
# letterbox之前确定这张当前图片letterbox之后的shape 如果不用self.rect矩形训练shape就是self.img_size
# 如果使用self.rect矩形训练shape就是当前batch的shape 因为矩形训练的话我们整个batch的shape必须统一(在__init__函数第6节内容)
shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
# letterbox 这一步将第一步缩放得到的图片再缩放到当前batch所需要的尺度 (343, 512, 3) pad-> (384, 512, 3)
# (矩形推理需要一个batch的所有图片的shape必须相同,而这个shape在init函数中保持在self.batch_shapes中)
# 这里没有缩放操作,所以这里的ratio永远都是(1.0, 1.0) pad=(0.0, 20.5)
img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
# 图片letterbox之后label的坐标也要相应变化 根据pad调整label坐标 并将归一化的xywh -> 未归一化的xyxy
labels = self.labels[index].copy()
if labels.size: # normalized xywh to pixel xyxy format
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
# 测试代码 测试letterbox效果
# cv2.imshow("letterbox", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img.shape) # (640, 640, 3)
if self.augment:
# Augment imagespace
if not mosaic:
# 不做mosaic的话就要做random_perspective增强 因为mosaic函数内部执行了random_perspective增强
# random_perspective增强: 随机对图片进行旋转,平移,缩放,裁剪,透视变换
img, labels = random_perspective(img, labels,
degrees=hyp['degrees'],
translate=hyp['translate'],
scale=hyp['scale'],
shear=hyp['shear'],
perspective=hyp['perspective'])
# 色域空间增强Augment colorspace
augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
# 测试代码 测试augment_hsv效果
# cv2.imshow("augment_hsv", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img.shape) # (640, 640, 3)
# Apply cutouts 随机进行cutout增强 0.5的几率使用 这里可以自行测试
if random.random() < hyp['cutout']: # hyp['cutout']=0 默认为0则关闭 默认为1则100%打开
labels = cutout(img, labels)
# 测试代码 测试cutout效果
# cv2.imshow("cutout", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img.shape) # (640, 640, 3)
nL = len(labels) # number of labels
if nL:
# xyxy to xywh normalized
labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0])
# 平移增强 随机左右翻转 + 随机上下翻转
if self.augment:
# 随机上下翻转 flip up-down
if random.random() < hyp['flipud']:
img = np.flipud(img) # np.flipud 将数组在上下方向翻转。
if nL:
labels[:, 2] = 1 - labels[:, 2] # 1 - y_center label也要映射
# 随机左右翻转 flip left-right
if random.random() < hyp['fliplr']:
img = np.fliplr(img) # np.fliplr 将数组在左右方向翻转
if nL:
labels[:, 1] = 1 - labels[:, 1] # 1 - x_center label也要映射
# 6个值的tensor 初始化标签框对应的图片序号, 配合下面的collate_fn使用
labels_out = torch.zeros((nL, 6))
if nL:
labels_out[:, 1:] = torch.from_numpy(labels) # numpy to tensor
# Convert BGR->RGB HWC->CHW
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3 x img_height x img_width
img = np.ascontiguousarray(img) # img变成内存连续的数据 加快运算
return torch.from_numpy(img), labels_out, self.img_files[index], shapes
(1.2)自适应锚框计算
借鉴此博主
- 载入数据集,得到数据集中所有数据的wh;
- 将每张图片中wh的最大值等比例缩放到指定大小img_size,较小边也相应缩放;
- 将bboxes从相对坐标改成绝对坐标(乘以缩放后的wh);
- 筛选bboxes,保留wh都大于等于两个像素的bboxes;
- 使用k-means聚类得到n个anchors(掉k-means包 涉及一个白化操作);
- 使用遗传算法随机对anchors的wh进行变异,如果变异后效果变得更好(使用anchor_fitness方法计算得到的fitness(适应度)进行评估)就将变异后的结果赋值给anchors,如果变异后效果变差就跳过,默认变异1000次;
比如Yolov5在Coco数据集上初始设定的锚框:
Yolov5在Coco数据集上初始设定的锚框:
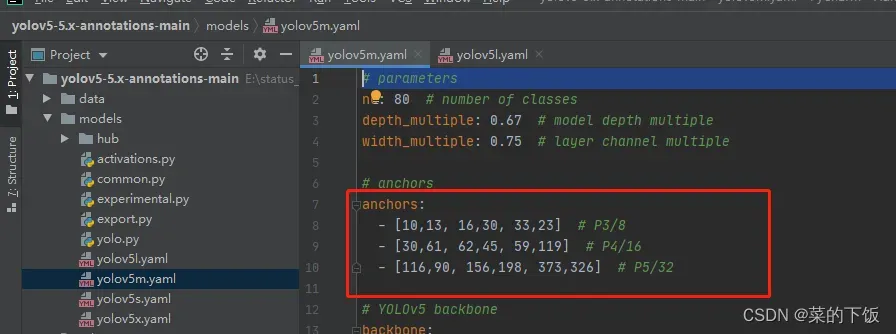
yolov5 每次训练时,自适应的计算不同训练集中的最佳锚框值,需要关闭的话,关闭参数指定即可。
(2.1)Focus结构
Foucus总结很到位
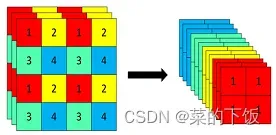
- Focus模块在v5中是图片进入backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长的差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
以yolov5s为例,原始的640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 ×
12的特征图,再经过一次卷积操作,最终变成320 × 320 × 32的特征图。切片操作如下:
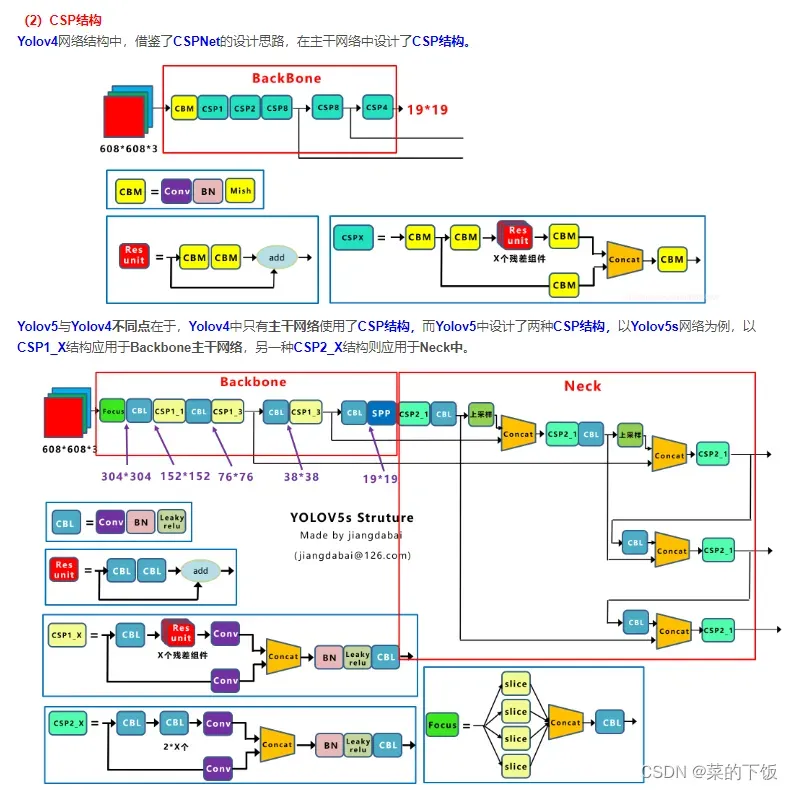
(2.2)CSP结构
借鉴
(2.3)FPN+PAN结构
Yolov5现在的Neck和Yolov4中一样,都采用FPN+PAN的结构,但在Yolov5刚出来时,只使用了FPN结构,后面才增加了PAN结构,此外网络中其他部分也进行了调整。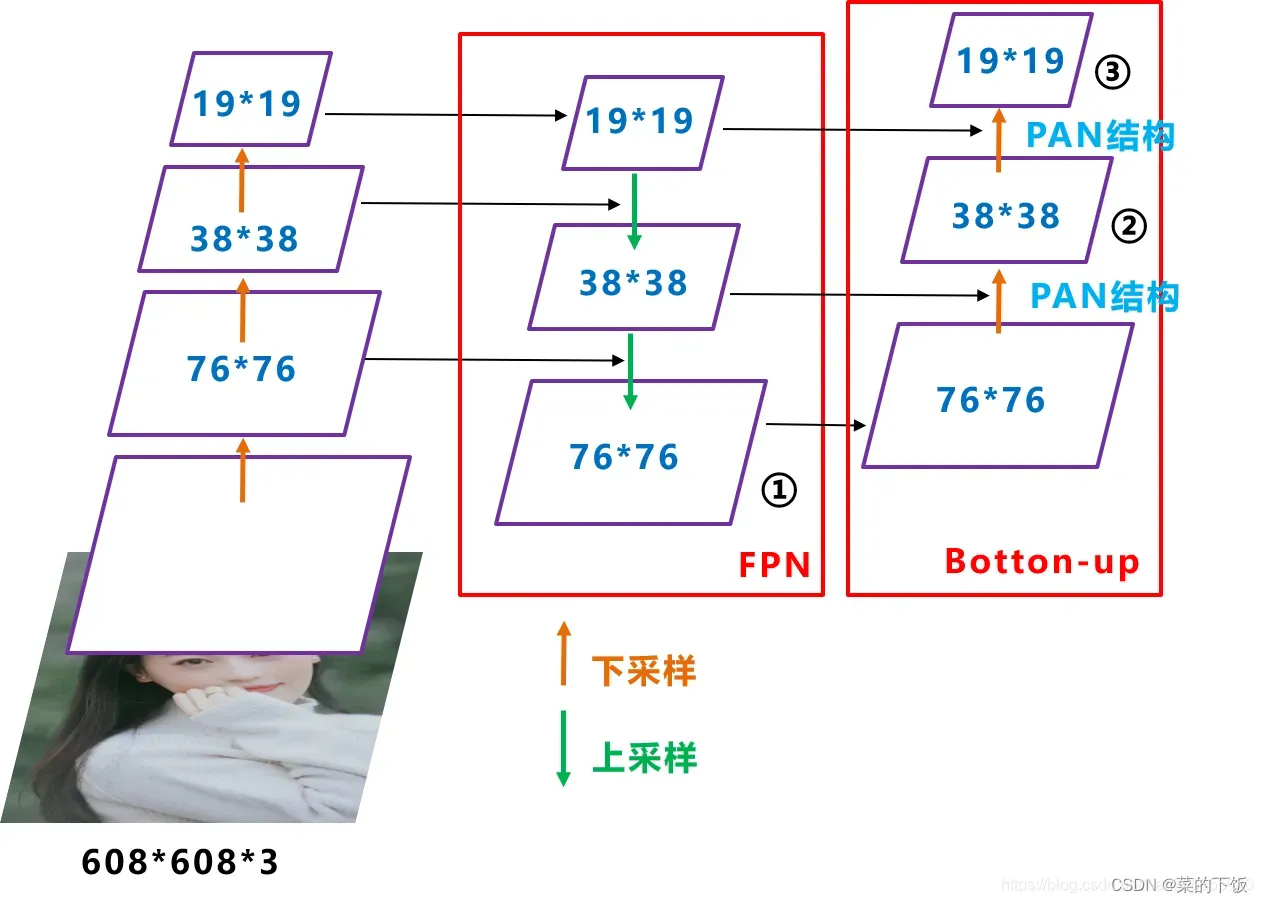
但如上面CSPNet中讲到,Yolov5和Yolov4的不同点在于,Yolov4的Neck中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPNet设计的CSP2结构,加强网络特征融合的能力。
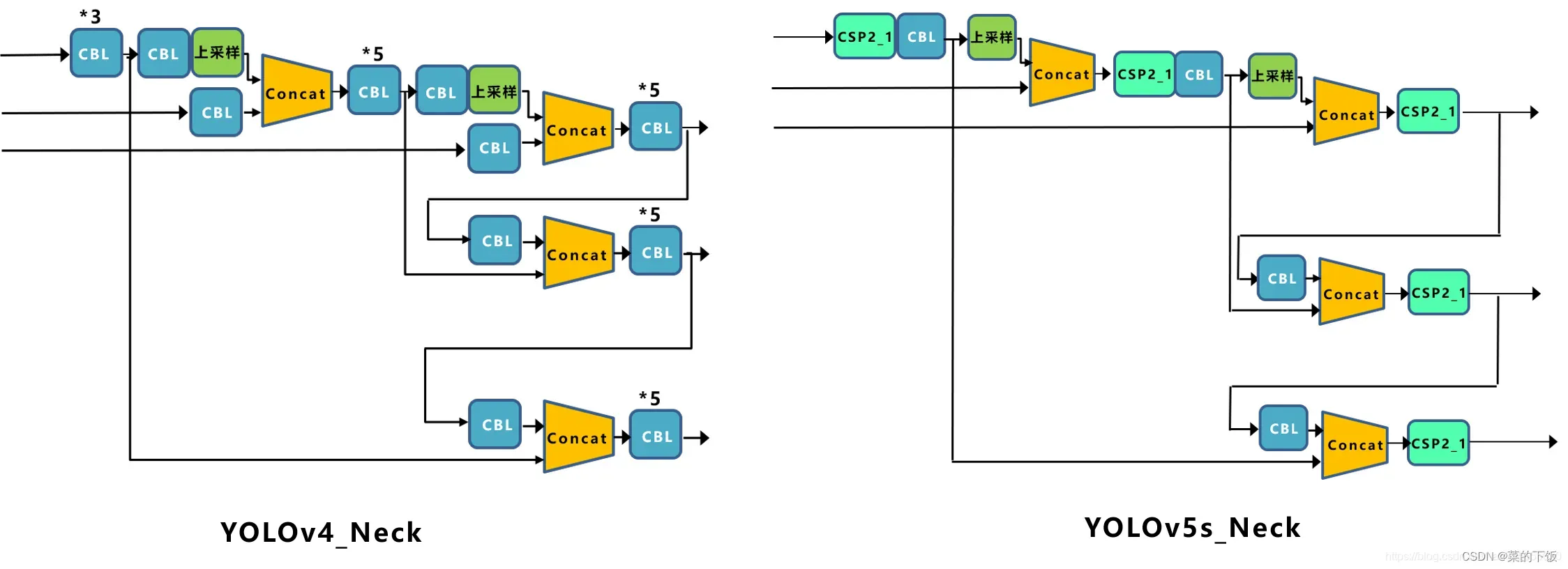
(3)Prediction部分
(1)Bounding box损失函数

(2)nms非极大值抑制
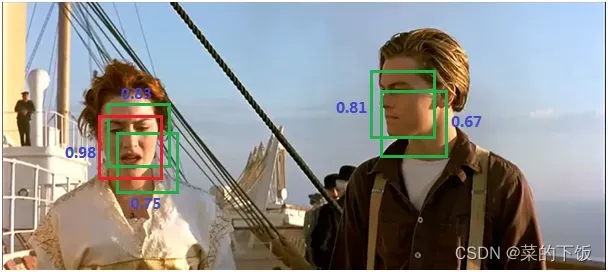
所谓非极大值抑制:先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A<B<C<D<E<F。
(1) 从最大概率矩形框F开始,分别判断A、B、C、D、E与F的重叠度IOU是否大于某个设定的阈值;
(2) 假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3) 从剩下的矩形框A、C、E中,选择概率最大的E,然后判断A、C与E的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
(4) 重复这个过程,找到所有被保留下来的矩形框。
总结—IOU
一、IoU
优点:
IOU算法是目标检测中最常用的指标,具有尺度不变性,满足非负性;同一性;对称性;三角不等性等特点
缺点:
1.如果两个框不相交,不能反映两个框距离远近
2.无法精确的反映两个框的重合度大小
二、GIoU
优点:
GIOU在基于IOU特性的基础上引入最小外接框解决检测框和真实框没有重叠时loss等于0问题。
缺点:
1.当检测框和真实框出现包含现象的时候GIOU退化成IOU
2.两个框相交时,在水平和垂直方向上收敛慢
三、DIoU
优点:
DIOU在基于IOU特性的基础上考虑到GIOU的缺点,直接回归两个框中心点的欧式距离,加速收敛。
缺点:
回归过程中未考虑Bounding box的纵横比,精确度上尚有进一步提升的空间
四、CIoU
优点:
CIOU就是在DIOU的基础上增加了检测框尺度的loss,增加了长和宽的loss,这样预测框就会更加的符合真实框。
缺点:
1. 纵横比描述的是相对值,存在一定的模糊
2. 未考虑难易样本的平衡问题
五、EIoU
优点:
EIOU在CIOU的基础上分别计算宽高的差异值取代了纵横比,同时引入Focal Loss解决难易样本不平衡的问题。
对比:
IOU Loss:考虑了重叠面积,归一化坐标尺度
GIOU Loss:考虑了重叠面积,基于IOU解决边界框不相交时loss等于0的问题
DIOU Loss:考虑了重叠面积和中心点距离,基于IOU解决GIOU收敛慢的问题
CIOU Loss:考虑了重叠面积、中心点距离、纵横比,基于DIOU提升回归精确度
EIOU Loss:考虑了重叠面积,中心点距离、长宽边长真实差,基于CIOU解决了纵横比的模糊定义,并添加Focal Loss解决BBox回归中的样本不平衡问题。
感谢各位优秀的博主,如有侵权及时联系。
文章出处登录后可见!