机器学习——鸢尾花数据集
- 数据集简介
- 导入数据集
- 可视化
- 主成分分析
鸢尾花数据集即iris
iris数据集文件: https://pan.baidu.com/s/1saL_4Q9PbFJluU4htAgFdQ .提取码:1234
数据集简介
- 数据集包含150个样本(数据集的行)
- 数据集包含4个属性(数据集的列):Sepal Length,Sepal Width,Petal Length,Petal Width:‘feature_names’
- 利用numpy.ndarray存储这150×4的数据:‘data’
- 分类标签取自array[‘Setosa’,‘Versicolour’,‘Virginica’]:‘target_names’
Setosa,Versicolour,Virginica是数据集所包含的3中品种的鸢尾花
这3个分类标签(即150×1数据)用np.ndarray存储:‘target’
总之,这个数据存储了150×4的特征数据和150×1的分类标签,其中特征数据又放在‘data’里,分类标签放在‘target’里
导入数据集
import matplotlib.pyplot as plt #绘图
from mpl_toolkits.mplot3d import Axes3D #可视化
from sklearn import datasets #sklearn中包含很多数据集,其中就有鸢尾花数据集
from sklearn.decomposition import PCA #主成分分析
import numpy as np #机器学习中通常将数据以数组的形式存储,特别是这里包含了特征数据和分类数据
iris = datasets.load_iris() #利用load函数装载数据集
print('鸢尾花数据集的数据类型是:',type(iris))
print('鸢尾花数据集的数据有:',dir(iris))
for i in dir(iris):
eval('print(i,"/t",type(iris.'+i+'))') #遍历数据集中的数据,查看每个数据的数据类型
print()
print('鸢尾花数据集中feature_names取值:',iris.feature_names)
print('鸢尾花数据集中数据的行列数:',iris.data.shape)
print('鸢尾花数据集中target取值:',np.unique(iris.target))
print('鸢尾花数据集中target_names的取值:',iris.target_names)
结果:
可视化
figure(num=None, figsize=None, dpi=None, facecolor=None, edgecolor=None, frameon=True)
- num:图像编号或名称,数字为编号 ,字符串为名称
- figsize:指定figure的宽和高,单位为英寸;
- dpi参数指定绘图对象的分辨率,即每英寸多少个像素,缺省值为80 1英寸等于2.5cm,A4纸是 21*30cm的纸张
- facecolor:背景颜色
- edgecolor:边框颜色
- frameon:是否显示边框
matplotlib中cla/clf/close用法及相关清除效果
- 在使用matplotlib画图时,画完图之后需要进行一定的清理工作,否则后续画图的结果中可能混入前一幅图的数据,或者造成频繁创建绘图对象。下面解释一下matplotlib中的相关清理操作和效果。主要包括以下方法:
- gca获取当前的axes,cla清理当前的axes
- gcf获取当前的figure,clf清理当前的figure
- close,关闭figure
a,b=0,1
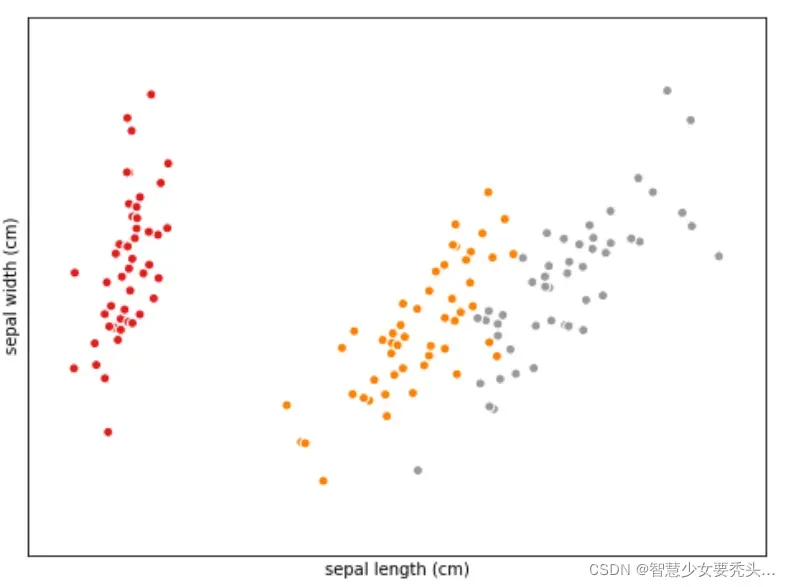
X = iris.data[:,[a,b]] #二维可视化,即只取两个属性,这里取的是全部行和前两列(sepal length和sepal width)
y = iris.target #由上述程序结果可知取值为0,1,2,代表3种品种的鸢尾花
x_min,x_max = X[:,0].min()-.5, X[:,0].max()+.5 #x值的最小值和最大值分别是第一列最小值和最大值-5和+5
y_min,y_max = X[:,1].min()-.5, X[:,1].max()+.5 #y值的最小值和最大值分别是第二列最小值和最大值-5和+5
plt.figure(2,figsize=(8,6))
plt.clf
plt.scatter(X[:,0],X[:,1],c=y,cmap=plt.cm.Set1,edgecolor='w') #绘制散点图,c即color,cmap是将y不同的值画出不同颜色,edgecolor为白色
plt.xlabel(iris.feature_names[a]) #x轴名称
plt.ylabel(iris.feature_names[b]) #y轴名称
plt.xlim(x_min,x_max) #x轴的作图范围
plt.ylim(y_min,y_max) #y轴的作图范围
plt.xticks(()) #x轴的刻度内容的范围
plt.yticks(()) #y轴的刻度内容的范围
结果:
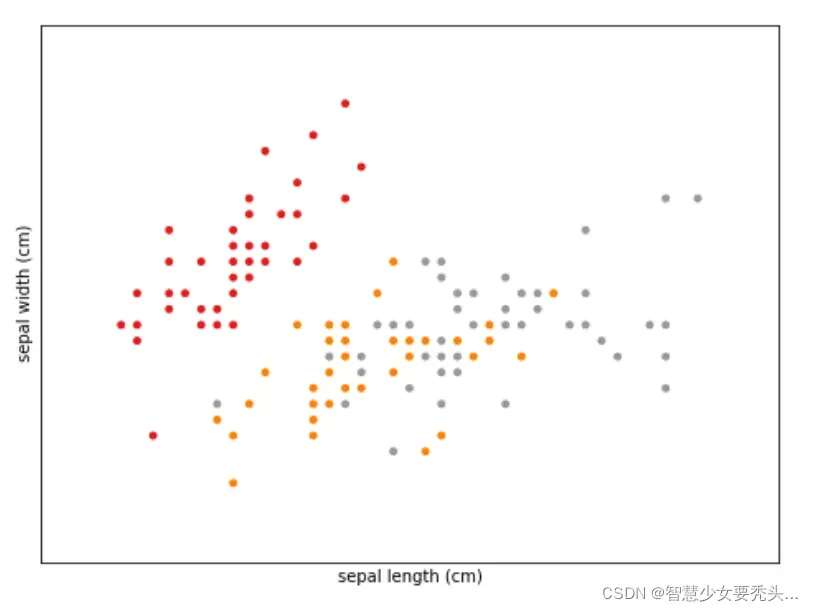
经过以上尝试,无论a,b取何值(即无论选择哪两列)进行二维绘图,都无法很好的区分红、橙、灰三色点(分布有重叠),所以尝试三维绘图
fig = plt.figure(1,figsize=(8,6))
ax = Axes3D(fig,elev=-150,azim=110) #???????????????
X_reduced = iris.data[:,:3] #可以改变列看图形分布X_reduced = iris.data[:,[0,2,3]]
ax.scatter(X_reduced[:, 0],X_reduced[:, 1],X_reduced[:, 2],c=y,cmap=plt.cm.Set1,edgecolor='w',s=40)
ax.set_title('Iris 3D')
ax.set_xlabel(iris.feature_names[0])
ax.w_xaxis.set_ticklabels([])
ax.set_ylabel(iris.feature_names[1])
ax.w_yaxis.set_ticklabels([])
ax.set_zlabel(iris.feature_names[2])
ax.w_zaxis.set_ticklabels([])
plt.show()
结果:
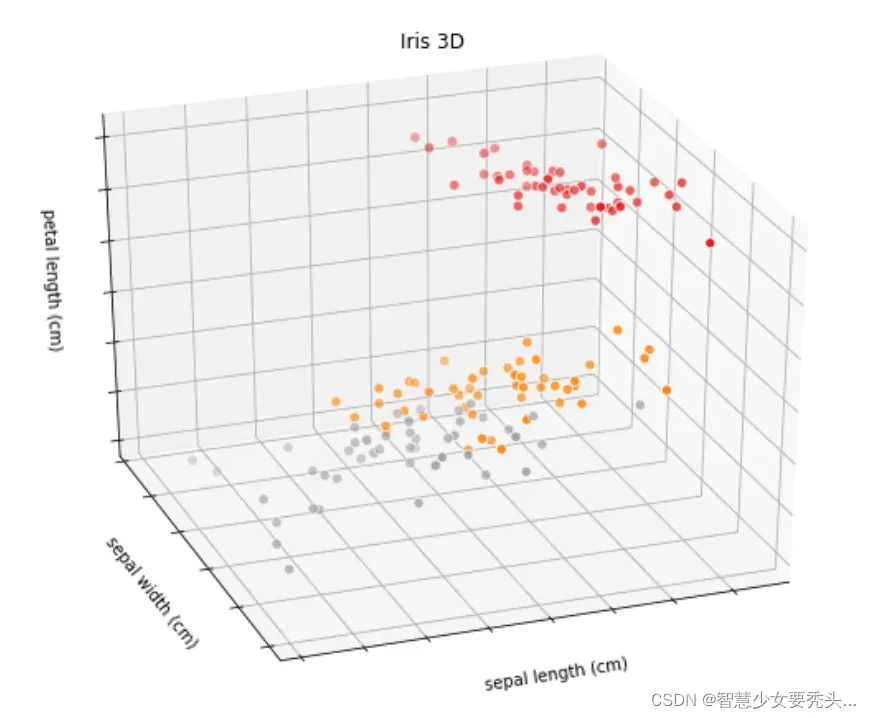
进行三维作图也没有很好的区分三种点,所以鸢尾花数据集还要进行四维作图才能区分三种数据,但是四维很难可视化,因此采用主成分分析
主成分分析
- 主成分分析(PCA)是降维方法,利用正交变换将以线性相关变量表示的观测数据转化为少数几个以线性无关变量表示的数据,这些线性无关的量称为主成分
- 这里就是将四维数据降为三维
fig = plt.figure(1,figsize=(8,6))
ax = Axes3D(fig,elev=-150,azim=110)
X_reduced = PCA(n_components=3).fit_transform(iris.data)
#n_components是PCA算法中所要保留的主成分个数n,也即保留下来的特征个数n,这里四维降三维n_components=3
#fit_transform 对数据先拟合 fit,找到数据的整体指标,如均值、方差、最大值最小值等,然后对数据集进行转换transform,从而实现数据的标准化、归一化操作
ax.scatter(X_reduced[:,0],X_reduced[:,1],X_reduced[:,2],c=y,cmap=plt.cm.Set1,edgecolor='w',s=40)
ax.set_title('First three PCA directions')
ax.set_xlabel('1st eigen vector')
ax.w_xaxis.set_ticklabels([])
ax.set_ylabel('2nd eigen vector')
ax.w_yaxis.set_ticklabels([])
ax.set_zlabel('3rd eigen vector')
ax.w_zaxis.set_ticklabels([])
plt.show()
结果:
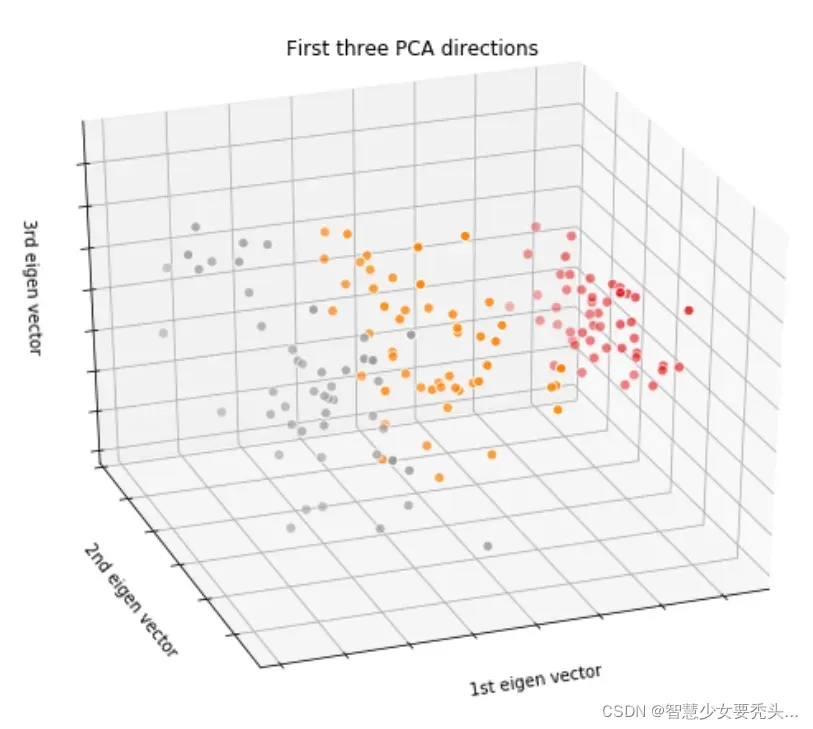
这时候,三种颜色的区分比较明显,还可以试试降为二维
a,b=0,1
X_reduced = PCA(n_components=2).fit_transform(iris.data)
X = X_reduced[:,[a,b]] #二维可视化,即只取两个属性,这里取的是全部行和前两列(sepal length和sepal width)
y = iris.target #由上述程序结果可知取值为0,1,2,代表3种品种的鸢尾花
x_min,x_max = X[:,0].min()-.5, X[:,0].max()+.5 #x值的最小值和最大值分别是第一列最小值和最大值-5和+5
y_min,y_max = X[:,1].min()-.5, X[:,1].max()+.5 #y值的最小值和最大值分别是第二列最小值和最大值-5和+5
plt.figure(2,figsize=(8,6))
plt.clf
plt.scatter(X[:,0],X[:,1],c=y,cmap=plt.cm.Set1,edgecolor='w') #绘制散点图,c即color,cmap是将y不同的值画出不同颜色,edgecolor为白色
plt.xlabel(iris.feature_names[a]) #x轴名称
plt.ylabel(iris.feature_names[b]) #y轴名称
plt.xlim(x_min,x_max) #x轴的作图范围
plt.ylim(y_min,y_max) #y轴的作图范围
plt.xticks(()) #x轴的刻度内容的范围
plt.yticks(()) #y轴的刻度内容的范围
结果:
文章出处登录后可见!
已经登录?立即刷新