目录

哈喽~今天学习记录的是数据分析实训小案例。
就用这个案例来好好巩固一下 python 数据分析三剑客。
前期准备:
- 确认 Jupyter Notebook 环境
- 准备实验数据:http://qn.yuanxinghua.love/%E5%AE%9E%E9%AA%8C.zip
1、实验一
1.1、题目总览
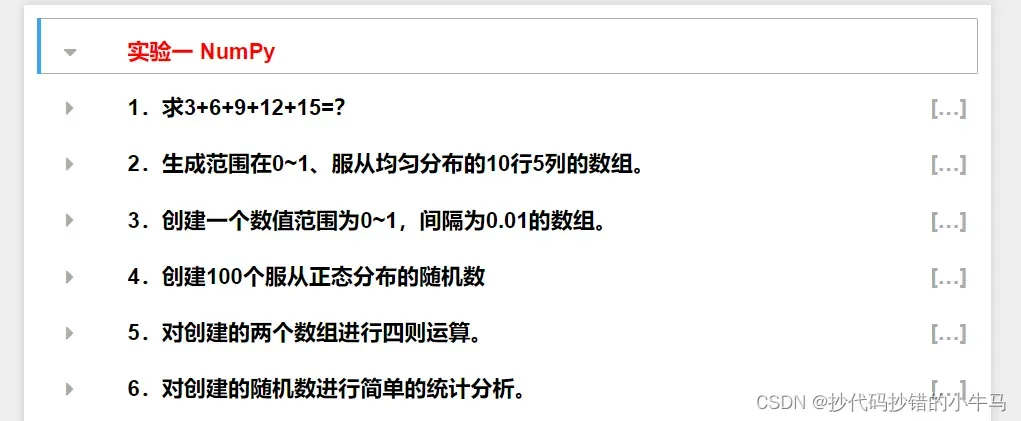
1.2、代码解析
1.求3+6+9+12+15= ?
import numpy as np
s = np.array([3,6,9,12,15])
np.sum(s)2.生成范围在0~1、服从均匀分布的10行5列的数组
arry = np.random.rand(10,5)
print(arry)3.创建一个数值范围为0~1,间隔为0.01的数组
arry1 = np.arange(0,1,0.01)
print(arry1)4.创建100个服从正态分布的随机数
arry2 = np.random.randn(100)
print(arry2)5.对创建的两个数组进行四则运算
arry1 = np.arange(0,1,0.01)
arry2 = np.random.randn(100)
print("加法",arry1 + arry2)
print("减法",arry1 - arry2)
print("乘法",arry1 * arry2)
print("除法",arry1 / arry2)6.对创建的随机数进行简单的统计分析
arry2 = np.random.randn(100).reshape(5,20)
print('排序\n',np.sort(arry2))
print('数据去重\n',np.unique(arry2))
print('数组求总和\n',np.sum(arry2))
print('数组纵轴和\n',np.sum(arry2,axis = 0))
print('数组横轴和\n',np.sum(arry2,axis = 1))
print('数组均值\n',np.mean(arry2))
print('数组纵轴均值\n',np.mean(arry2,axis = 0))
print('数组横轴均值\n',np.mean(arry2,axis = 1))
print('数组标准差\n',np.std(arry2))
print('数组纵轴标准差\n',np.std(arry2,axis = 0))
print('数组横轴标准差\n',np.std(arry2,axis = 1))
print('方差\n',np.var(arry2))
print('最小值\n',np.min(arry2))
print('最大值\n',np.max(arry2)) 2、实现二
2.1、题目总览

2.2、代码解析
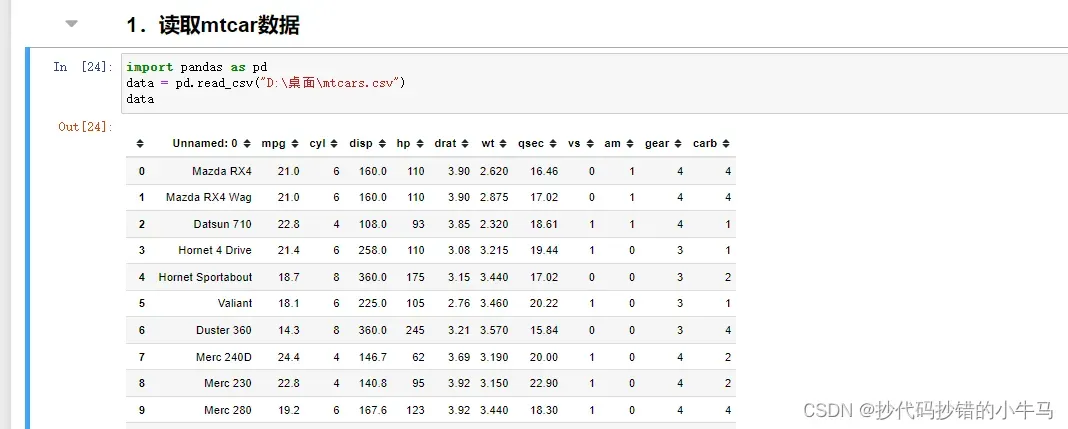
1.读取mtcar数据
import pandas as pd
data = pd.read_csv("D:\桌面\mtcars.csv")
data截图:
2.查看mtcar数据集的元素的个数、维度、大小等信息,输出表的列名
print('所有值为:\n',data.values)
print('索引:\n',data.index)
print('类型为:\n',data.dtypes)
print('元素个数为:',data.size)
print('维度为:',data.ndim)
print('大小为:',data.shape)
print('表的列名:\n',data.columns)3.使用describe方法对整个mtcar数据集进行描述性统计
data.describe()4.计算不同cyl(气缸数)、carb(化油器)对应的mpg(油耗)和hp(马力)的均值
a = data.loc[:,['cyl','carb','mpg','hp']]
b = a.groupby(['cyl','carb']).mean()
b5.输出mpg和hp前5个元素
c = data.loc[:4,['mpg','hp']]
c6.输出mtcar数据的前3行元素
d = data[:][:3]
d7.使用head()和tail()方法输出前后5行数据
print('前5行元素为:\n',data.head())
print('==================')
print('后5行元素为:\n',data.tail())8.用loc和iloc分别提取第1列和第3列的数据
print(data.loc[:,['mpg','disp']])
print('**---------------***-------------**')
print(data.iloc[:,[1,3]])9.取出列名为mpg、hp,行名为2,3,4的数据
e = data.loc[2:4,['mpg','hp']] # loc[索引/条件,名称/]
print(e)10.取出列位置为2和4,行位置为5,6,7的数据
f = data.iloc[5:8,[2,4]]
print(f) 11.取出列位置为3,行名为2-6的数据
j = data.loc[2:6,['disp']]
print(j)12.新增1列,名称为abc(abc=mpg+hp),输出前5行数据
data['abc'] = data['mpg'] + data['hp']
data.head()13.删除前两行数据
print('原数据长度:',len(data))
data.drop(labels=range(0,2),axis=0,inplace=True)
print('删除后长度:',len(data))14.删除abc列
data['abc'] = data['mpg'] + data['hp']
print('增加 abc 列后:\n',data.columns)
print('****************************************')
data.drop(labels='abc',axis=1,inplace=True)
print('删除 abc 列后:\n',data.columns)3、实验三
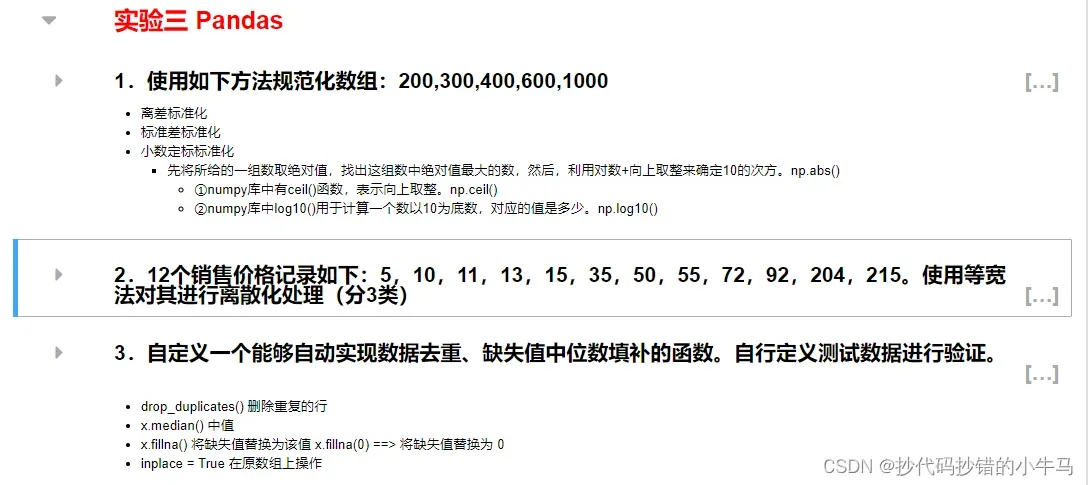
3.1、题目总览
3.2、代码解析
1.使用如下方法规范化数组:200,300,400,600,1000
- 离差标准化
- 标准差标准化
- 小数定标标准化
- 先将所给的一组数取绝对值,找出这组数中绝对值最大的数,然后,利用对数+向上取整来确定10的次方。np.abs()
- ①numpy库中有ceil()函数,表示向上取整。np.ceil()
- ②numpy库中log10()用于计算一个数以10为底数,对应的值是多少。np.log10()
- 先将所给的一组数取绝对值,找出这组数中绝对值最大的数,然后,利用对数+向上取整来确定10的次方。np.abs()
import numpy as np
import pandas as pd
arry = np.array([200,300,400,500,600,1000])
print('原数组:\n',arry)
# mean 均值 sta 标准差
def result(x):
x1 = (x - x.min())/(x.max() - x.min()) # 离差
x2 = (x - x.mean()/x.std()) # 标准差
x3 = x/10**np.ceil(np.log10(np.abs(x).max())) # 小数
return x1,x2,x3
print('离差:\n',result(arry)[0])
print('标准差:\n',result(arry)[1])
print('小数:\n',result(arry)[2])2.12个销售价格记录如下:5,10,11,13,15,35,50,55,72,92,204,215。使用等宽法对其进行离散化处理(分3类)
price = np.array([5,10,11,13,15,35,50,55,72,92,204,215])
pd.cut(price,3) # 精度默认为 3 3.自定义一个能够自动实现数据去重、缺失值中位数填补的函数。自行定义测试数据进行验证
- drop_duplicates() 删除重复的行
- x.median() 中值
- x.fillna() 将缺失值替换为该值 x.fillna(0) ==> 将缺失值替换为 0
- inplace = True 在原数组上操作
def test(x):
x.drop_duplicates(inplace = True)
x.fillna(x.median(),inplace = True)
return(x)
arr = pd.DataFrame(
{
'a':['1','2']*2,
'b':['1','2']*2,
}
)
print('============去重前的数组===================')
print(arr)
print('============去重===================')
print(test(arr))
print('============去重后的数组===================')
print(arr)4、实验四
3.1、题目总览

3.2、代码解析
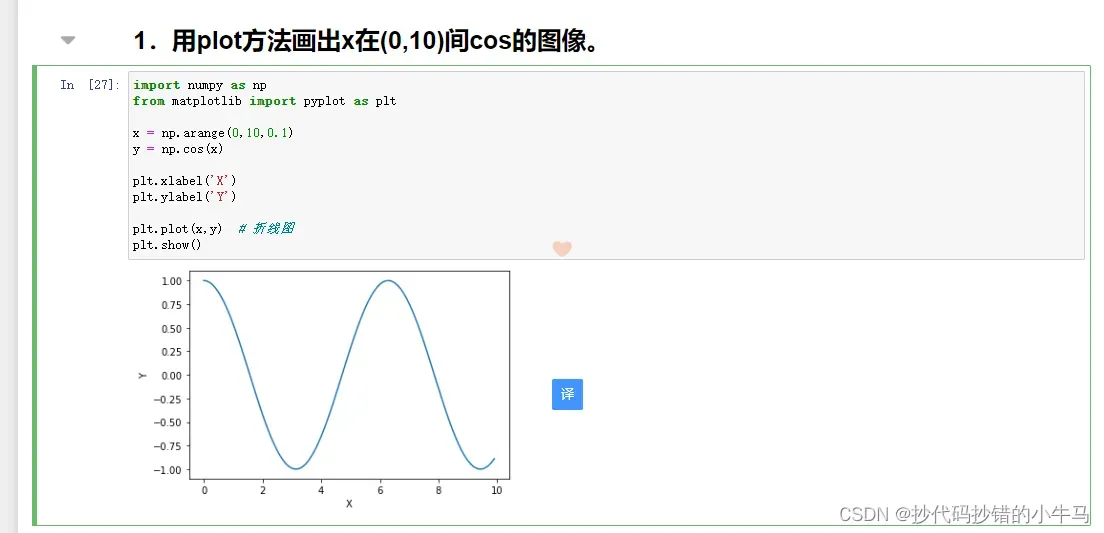
1.用plot方法画出x在(0,10)间cos的图像
import numpy as np
from matplotlib import pyplot as plt
x = np.arange(0,10,0.1)
y = np.cos(x)
plt.xlabel('X')
plt.ylabel('Y')
plt.plot(x,y) # 折线图
plt.show()运行截图:
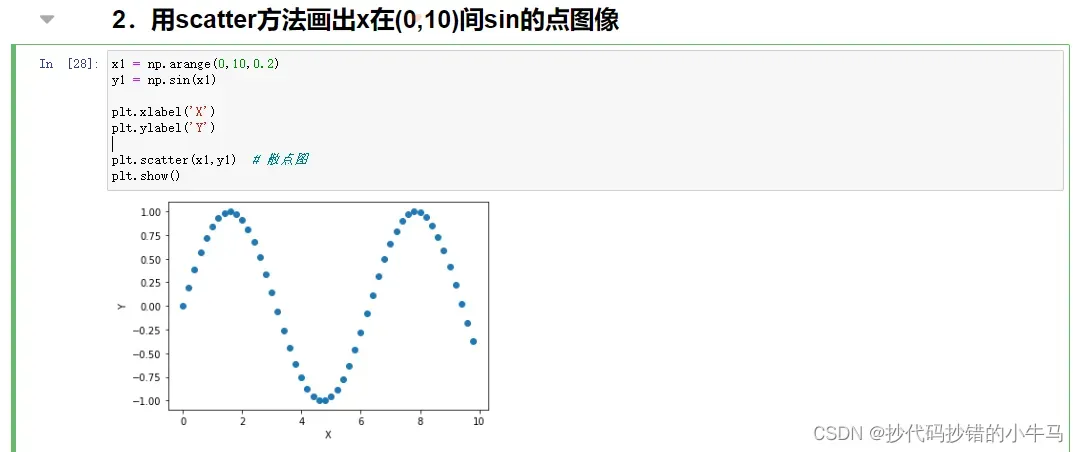
2.用scatter方法画出x在(0,10)间sin的点图像
x1 = np.arange(0,10,0.2)
y1 = np.sin(x1)
plt.xlabel('X')
plt.ylabel('Y')
plt.scatter(x1,y1) # 散点图
plt.show()运行截图:
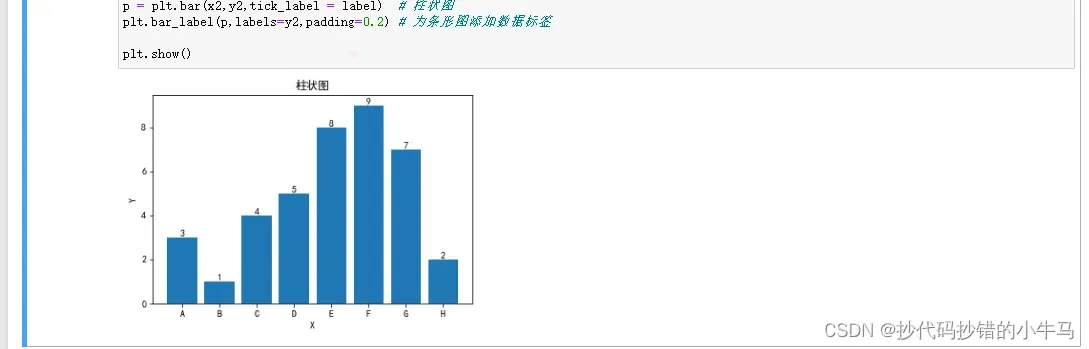
3.绘制一个高分别为3,1,4,5,8,9,7,2,X轴上值为A,B,C,D,E,F,G,H的柱状图
x2 = [1,2,3,4,5,6,7,8]
y2 = [3,1,4,5,8,9,7,2]
label=['A','B','C','D','E','F','G','H']
# 用来显示中文字符 不加中文显示 会报错
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title('柱状图')
plt.xlabel('X')
plt.ylabel('Y')
p = plt.bar(x2,y2,tick_label = label) # 柱状图
plt.bar_label(p,labels=y2,padding=0.2) # 为条形图添加数据标签
plt.show()运行截图:
4.人口数据总共拥有6个特征,分别为年末总人口、男性人口、女性人口、城镇人口、乡村人口和年份。查看各个特征随着时间推移发生的变化情况可以分析出未来男女人口比例、城乡人口变化的方向。使用NumPy库读取人口数据。创建画布,并添加子图。在两个子图,上分别绘制散点图和折线图。保存,显示图片。分析未来人口变化趋势
import numpy as np
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# ==========读取文件========================
data = np.load('D:\桌面\populations.npz',allow_pickle=True)
# print(type(data)) # class 'numpy.lib.npyio.NpzFile'>
# data.files # npz结尾的数据集是压缩文件,里面还有其他的文件 可用 data.files 进行查看 ['data', 'feature_names']
# print(data['data'])
# print(data['feature_names'])
# ['时间' '年末总人口(万人)' '男性人口(万人)' '女性人口(万人)' '城镇人口(万人)' '乡村人口(万人)']
# =========处理数据==========================
# 去除缺失值 print(data['data'][:-2])
new_data = np.delete(data['data'],[-1,-2], 0) # [-1,-2] 要删除的行 删除第 -1 行 和 第-2 行
y = new_data
# print(y)
# numpy 选取二维数组 ==> 转为一维 ==> 逆序取值 [-1::-1] 字符串 逆序 取值 不自动实现 排大小功能
y1 = y[:,:1][:,0][-1::-1] # 时间
y2 = y[:,1:2][:,0][-1::-1] # 年末总人口
y3 = y[:,2:3][:,0][-1::-1] # 男性人口
y4 = y[:,3:4][:,0][-1::-1] # 女性人口
y5 = y[:,4:5][:,0][-1::-1] # 城镇人口
y6 = y[:,5:6][:,0][-1::-1] # 乡村人口
# print(y1)
#y1 = y[:,:1][:,0]
x = y1
# x = x[-1::-1]
# print(y2)
# ===创建一个空白画布===
fig = plt.figure( figsize=(22,26) )
# ===创建一个子图===
ax1 = fig.add_subplot(2,1,1) # 位置: 2行1列 第1个
# ==============散点图===================================
line1 = ax1.scatter(x,y2)
line2 = ax1.scatter(x,y3)
line3 = ax1.scatter(x,y4)
line4 = ax1.scatter(x,y5)
line5 = ax1.scatter(x,y6)
plt.legend(handles=[line1,line2,line3,line4,line5],
labels=['年末总人口(万人)','男性人口(万人)','女性人口(万人)','城镇人口(万人)','乡村人口(万人)'], loc='best')
# ===创建一个子图===
ax2 = fig.add_subplot(2,1,2) # 位置: 2行1列 第2个
# ==============折线图====================================
line11, = ax2.plot(x,y2)
line22, = ax2.plot(x,y3)
line33, = ax2.plot(x,y4)
line44, = ax2.plot(x,y5)
line55, = ax2.plot(x,y6)
plt.legend(handles=[line11,line22,line33,line44,line55],
labels=['年末总人口(万人)','男性人口(万人)','女性人口(万人)','城镇人口(万人)','乡村人口(万人)'], loc='best')
# =====保存图片===========
plt.savefig('1996-2015年人口数据各个特征随时间推移的变化情况图') # 保存在当前路径下
# =====在本机显示图片=====
plt.show()
# ============问题=========================
# 之前会报错: A proxy artist may be used instead. ==> https://blog.csdn.net/weixin_39944233/article/details/110777868
# 原因: plt.plot( )返回的是一个二元组值,若要获取实例,必须用x, = plt.plot( )才能取出来实例对象运行截图:

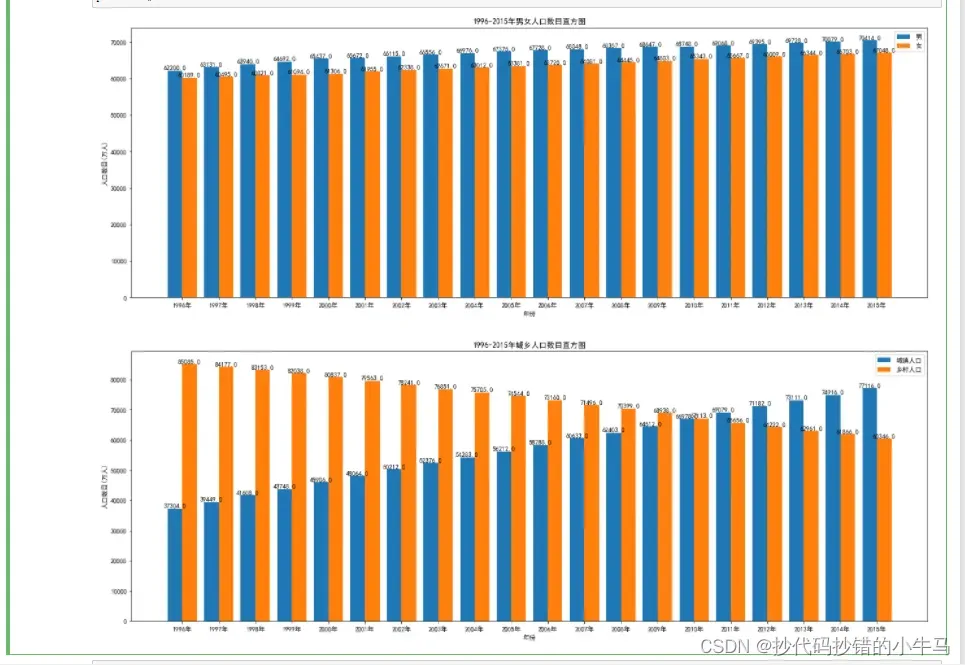
5.通过绘制各年份男女人口数目及城乡人口数目的直方图,男女人口比例及城乡人口比例的饼图可以发现人口结构的变化
- 各年份男女人口数目及城乡人口数目的直方图
# =====各年份男女人口数目及城乡人口数目的直方图
'''
y1 = y[:,:1][:,0][-1::-1] # 时间
y3 = y[:,2:3][:,0][-1::-1] # 男性人口
y4 = y[:,3:4][:,0][-1::-1] # 女性人口
y5 = y[:,4:5][:,0][-1::-1] # 城镇人口
y6 = y[:,5:6][:,0][-1::-1] # 乡村人口
'''
# ===创建一个空白画布===
fig = plt.figure( figsize=(22,26) )
# ===新建一个子图=== =====各年份男女人口数目直方图
ax3 = fig.add_subplot(3,1,1)
plt.title("1996-2015年男女人口数目直方图")
plt.xlabel('年份')
plt.ylabel('人口数目(万人)')
new_x = np.arange(len(y1))
man_y = y3
woman_y = y4
c_y = y5
x_y = y6
pb1 = plt.bar(new_x - 0.2,man_y,width=0.4) # 柱状图
pb2 = plt.bar(new_x + 0.2,woman_y,width=0.4)
plt.bar_label(pb1,labels=man_y,padding=0.2) # 每个条块加上其值
plt.bar_label(pb2,labels=woman_y,padding=0.2)
plt.legend(['男', '女'], loc='best')
plt.xticks(ticks= new_x, labels= y1) # ticks: x轴刻度的列表集合 labels:用文本或其他来代替刻度的值
# ===新建一个子图=== ======各年份城乡人口数目直方图
ax4 = fig.add_subplot(3,1,2)
plt.title("1996-2015年城乡人口数目直方图")
plt.xlabel('年份')
plt.ylabel('人口数目(万人)')
pb3 = plt.bar(new_x - 0.2,c_y,width=0.4) # 柱状图
pb4 = plt.bar(new_x + 0.2,x_y,width=0.4)
plt.bar_label(pb3,labels=c_y,padding=0.2) # 每个条块加上其值
plt.bar_label(pb4,labels=x_y,padding=0.2)
plt.xticks(ticks= new_x, labels= y1) # ticks: x轴刻度的列表集合 labels:用文本或其他来代替刻度的值
plt.legend(['城镇人口', '乡村人口'], loc='best')
plt.show()运行截图:
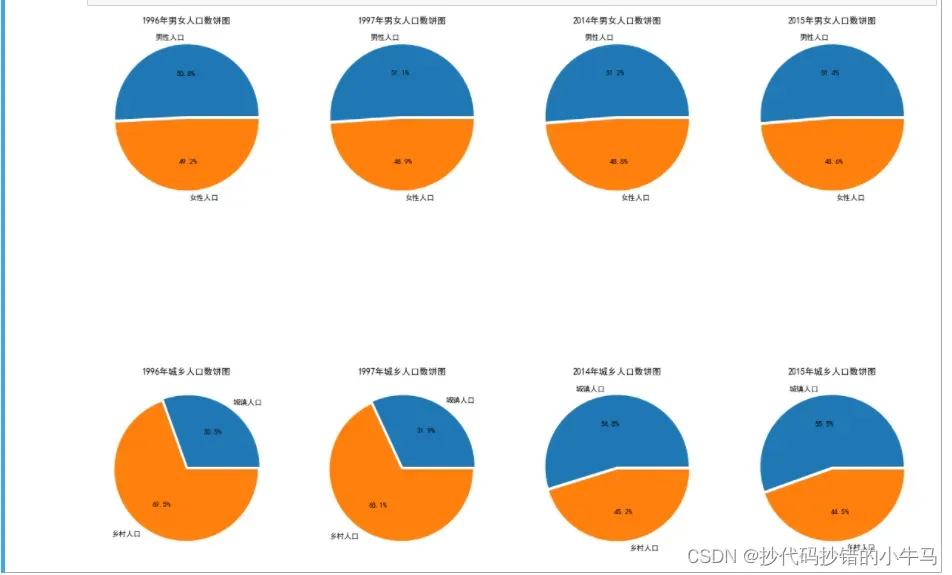
- 各年份男女人口比例及城乡人口比例的饼图
# =====各年份男女人口比例及城乡人口比例的饼图
'''
y1 = y[:,:1][:,0][-1::-1] # 时间
y3 = y[:,2:3][:,0][-1::-1] # 男性人口
y4 = y[:,3:4][:,0][-1::-1] # 女性人口
y5 = y[:,4:5][:,0][-1::-1] # 城镇人口
y6 = y[:,5:6][:,0][-1::-1] # 乡村人口
'''
# ===创建一个空白画布===
fig = plt.figure( figsize=(20,16) )
explode = (0.02,0.02)
# =====各年份男女人口数目饼图
labels = ['男性人口','女性人口']
labels1 = ['城镇人口','乡村人口']
v = [
[y3[0],y4[0]],
[y3[1],y4[1]],
[y3[-2],y4[-2]],
[y3[-1],y4[-2]],
]
v1 = [
[y5[0],y6[0]],
[y5[1],y6[1]],
[y5[-2],y6[-2]],
[y5[-1],y6[-2]],
]
# 男女人口数目饼图
ax5 = fig.add_subplot(2,4,1)
plt.pie(v[0],labels= labels, explode=explode, autopct='%1.1f%%')
plt.tick_params(labelsize=12)
plt.title('1996年男女人口数饼图')
ax6 = fig.add_subplot(2,4,2)
plt.pie(v[1],labels= labels, explode=explode, autopct='%1.1f%%')
plt.tick_params(labelsize=12)
plt.title('1997年男女人口数饼图')
ax7 = fig.add_subplot(2,4,3)
plt.pie(v[-2],labels= labels, explode=explode, autopct='%1.1f%%')
plt.tick_params(labelsize=12)
plt.title('2014年男女人口数饼图')
ax8 = fig.add_subplot(2,4,4)
plt.pie(v[-1],labels= labels, explode=explode, autopct='%1.1f%%')
plt.tick_params(labelsize=12)
plt.title('2015年男女人口数饼图')
# 城乡人口数目饼图
ax9 = fig.add_subplot(2,4,5)
plt.pie(v1[0],labels= labels1, explode=explode, autopct='%1.1f%%')
plt.tick_params(labelsize=12)
plt.title('1996年城乡人口数饼图')
ax10 = fig.add_subplot(2,4,6)
plt.pie(v1[1],labels= labels1, explode=explode, autopct='%1.1f%%')
plt.tick_params(labelsize=12)
plt.title('1997年城乡人口数饼图')
ax11 = fig.add_subplot(2,4,7)
plt.pie(v1[-2],labels= labels1, explode=explode, autopct='%1.1f%%')
plt.tick_params(labelsize=12)
plt.title('2014年城乡人口数饼图')
ax12 = fig.add_subplot(2,4,8)
plt.pie(v1[-1],labels= labels1, explode=explode, autopct='%1.1f%%')
plt.tick_params(labelsize=12)
plt.title('2015年城乡人口数饼图')
# =====保存图片===========
plt.savefig('1996,19967,2014,2015年男女人口比例及城乡人口比例的饼图')
plt.show()
运行截图:
ok`—– 小案例到这里就结束啦~
我们下次再见 ^_^
文章出处登录后可见!