主题建模:BERTopic(理论篇)
在我的博客中已经写了很多关于 主题建模 的内容,当你准备了解 BERTopic 时,默认你已经知道了 LSA、pLSA、NFM、LDA 等传统的主题建模方法。关于主题建模的前置知识我在这里不做赘述,感兴趣的同学可以看看我前几篇博客。学习 BERTopic 需要一定的机器学习基础,让我们一起开始吧!
1.总体概述
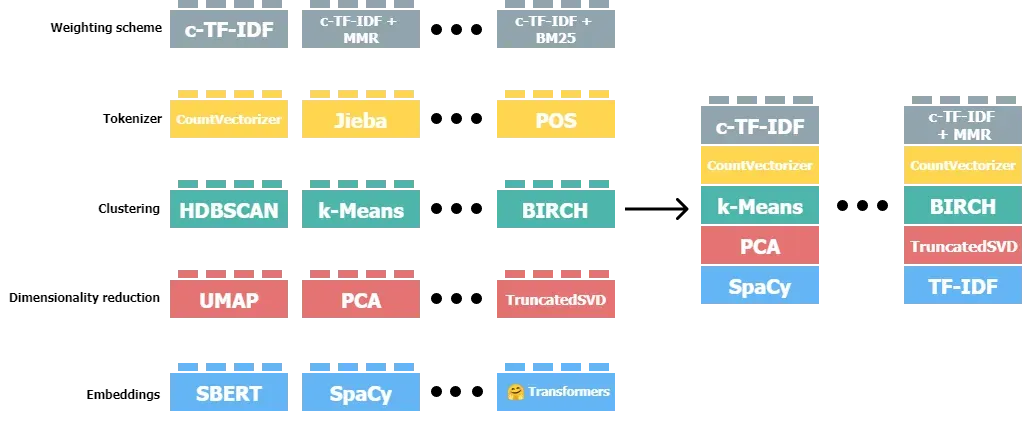
利用 BERTopic 进行主题建模可按照以下五个步骤进行:嵌入(Embeddings)、降维(Dimensionality Reduction)、聚类(Clustering)、分词(Tokenizer)、加权(Weighting scheme)。

尽管上述步骤有默认的处理方法,但 BERTopic 在一定程度上是模块化的,你可以自主选择每个步骤的处理方法,构建属于自己的主题模型。
2.代码示例
下面的代码演示了如何使用 BERTopic 算法。使用 BERTopic 的一个优点是算法中的每个主要步骤都可以明确定义,从而使过程透明且直观。
from sentence_transformers import SentenceTransformer
from umap import UMAP
from hdbscan import HDBSCAN
from sklearn.feature_extraction.text import CountVectorizer
from bertopic.vectorizers import ClassTfidfTransformer
from bertopic import BERTopic
# Step 1 - Extract embeddings
embedding_model = SentenceTransformer("all-MiniLM-L6-v2")
# Step 2 - Reduce dimensionality
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine')
# Step 3 - Cluster reduced embeddings
hdbscan_model = HDBSCAN(min_cluster_size=15, metric='euclidean', cluster_selection_method='eom', prediction_data=True)
# Step 4 - Tokenize topics
vectorizer_model = CountVectorizer(stop_words="english")
# Step 5 - Create topic representation
ctfidf_model = ClassTfidfTransformer()
# All steps together
topic_model = BERTopic(
embedding_model=embedding_model, # Step 1 - Extract embeddings
umap_model=umap_model, # Step 2 - Reduce dimensionality
hdbscan_model=hdbscan_model, # Step 3 - Cluster reduced embeddings
vectorizer_model=vectorizer_model, # Step 4 - Tokenize topics
ctfidf_model=ctfidf_model, # Step 5 - Extract topic words
diversity=0.5 # Step 6 - Diversify topic words
)
3.步骤详解
3.1 文档嵌入(Embed documents)
我们首先需要将文档转换为数字表示。BERTopic 中的默认处理方法是 sentence-transformers。其中的模型通常针对语义相似性进行了优化,有助于后续的聚类任务。此外,它们也非常适合创建文档或句子嵌入。
在 BERTopic 中,可以选择任何一个 sentence-transformers 模型,但有两个模型被设置为默认值:
all-MiniLM-L6-v2paraphrase-multilingual-MiniLM-L12-v2
第一个是专门为语义相似性任务训练的英语语言模型,它对大多数用例都非常有效。第二种模型与第一种模型非常相似,主要区别在于多语言模型适用于 多种语言。该模型比第一个模型大很多,只有在选择英语以外的语言时才会被选中。
3.2 降维(Dimensionality reduction)
降维作为机器学习的四大任务(分类、回归、聚类、降维)之一,应该并不陌生了哈。
在将文档数字化表示后,必须降低表示的维度。由于维数灾难,聚类模型通常难以处理高维数据。降维的方法有很多,但 BERTopic 默认选择的是 UMAP。这是一种在降维时可以保留数据的局部和全局结构的技术。保留此结构很重要,因为它包含创建语义相似文档集群所需的信息。
3.3 聚类(Cluster Documents)
降维后,我们可以对数据进行聚类。基于密度的聚类技术 HDBSCAN 可以找到不同形状的簇,并在一定情况下可以识别异常值。因此,我们不会强制文档进入它们可能不属于的集群。这将改进生成的主题表示,因为可以从中提取的噪音更少。
3.4 词袋表示(Bag-of-words)
在开始创建主题表示之前,首先需要选择一种允许 BERTopic 算法模块化的技术。当我们使用 HDBSCAN 作为聚类模型时,我们可能会假设我们的聚类具有不同程度的密度和不同的形状。这意味着基于质心的主题表示技术可能不是最合适的模型。换句话说,我们想要一种主题表示技术,该技术对集群的预期结构几乎不做任何假设。
首先,将一个聚类中的所有文档组合成一个长文档。然后,计算每个词在每个聚类中出现的频率。结果即是词袋表示,其中可以找到每个聚类中每个词的频率。因此,这种词袋表示是在聚类级别而不是文档级别。这种区别很重要,因为我们对主题级别(即集群级别)的单词感兴趣。通过使用词袋表示,没有对聚类的结构做出任何假设。此外,词袋表示是 归一化的,以考虑具有不同大小的聚类。
3.5 主题表示(Topic representation)
从生成的词袋表示中,我们想知道是什么让一个集群与另一个集群不同。哪些词对于集群 是典型的,而对于所有其他集群不是那么多?为了解决这个问题,我们需要修改 TF-IDF,使其考虑主题(即集群)而不是文档。
当您像往常一样在一组文档上应用 TF-IDF 时,您所做的是比较文档之间单词的重要性。现在,如果我们改为将单个类别(例如,一个集群)中的所有文档视为单个文档,然后应用 TF-IDF 怎么办?结果将是集群中单词的重要性分数。聚类中的单词越重要,它就越能代表该主题。换句话说,如果我们提取每个聚类中最重要的词,我们就会得到主题的描述!
该模型称为基于类的 TF-IDF(class-based TF-IDF,c-TF-IDF):
表示在聚类
中单词
的频次。
表示单词
表示每个聚类所包含的平均单词数。
每个集群都被转换为单个文档而不是一组文档。然后,我们提取词 在类
中的频率,其中
指的是我们之前创建的集群。这种表示是
标准化的,以说明主题大小的差异。
然后,我们取 加上每个类别
的平均单词数除以所有类别中单词
的频率的对数。我们在对数中加
以强制值为正。与经典的 TF-IDF 一样,我们然后将
与
相乘以获得每个类别中每个单词的重要性分数。换句话说,这里没有使用经典的
过程,而是使用了算法的修改版本,可以提供更好的表示。
3.6 (可选)最大边际相关性(Maximal Marginal Relevance)
在生成 c-TF-IDF 表示后,我们有一组描述文档集合的词。从技术上讲,这并不意味着这个单词集合描述了一个连贯的主题。在实践中,我们会看到很多词确实描述了一个相似的主题,但有些词在某种程度上会过拟合文档。例如,如果您有一组由同一个人撰写的文档,其签名将出现在主题描述中。
为了提高单词的连贯性,使用最大边际相关性来找到最连贯的单词,而单词本身之间没有太多重叠。这导致删除对主题没有贡献的单词。
您还可以使用此技术使主题表示中生成的单词多样化。有时,同一个词的许多变体可能会出现在主题表示中。为了减少同义词的数量,我们可以增加单词之间的多样性,同时仍然与主题表示相似。
文章出处登录后可见!