Mediapipe手势识别
代码:
import cv2
import mediapipe as mp
import time
mp_drawing = mp.solutions.drawing_utils # 画线函数
mp_hands = mp.solutions.hands
drawing_spec = mp_drawing.DrawingSpec(thickness=2, circle_radius=1)
drawing_spec1 = mp_drawing.DrawingSpec(thickness=2, circle_radius=1, color=(255, 255, 255))
hands = mp_hands.Hands(
min_detection_confidence=0.7, min_tracking_confidence=0.5
)
'''
Hands是一个类,他有四个初始化参数,
static_image_mode:是静态图片还是视频帧
max_num_hands:最多检测几只手
min_detection_confidence:置信度阈值
min_tracking_confidence:追踪阈值
'''
cap = cv2.VideoCapture(0) # 获取视频对象,0是摄像头,也可以输入视频路径
time.sleep(2)
while cap.isOpened():
success, image = cap.read() # success是一个bool类型的,表示是否读取成功,image表示每一帧的图像(BGR存储)
if not success:
print("Ignoring empty camera frame.")
continue
image = cv2.cvtColor(cv2.flip(image, 1), cv2.COLOR_BGR2RGB) # 将图片进行水平反转,并由原来的色彩空间转换成RGB
image.flags.writeable = False
results = hands.process(image) # 处理图片
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) # 再将图片转化为BGR
if results.multi_hand_landmarks: # 该变量非空,表示检测到了手,并且存放了检测到的手的个数
for hand_landmarks in results.multi_hand_landmarks:
'''
如果有两只手,则每一次遍历获得的是每只手经过处理的21个关节点坐标的信息,也可以这么写:hand_0 =
results.multi_hand_landmarks[0]
'''
mp_drawing.draw_landmarks(image, hand_landmarks, mp_hands.HAND_CONNECTIONS,
landmark_drawing_spec=drawing_spec, connection_drawing_spec=drawing_spec1) # 画线
cv2.imshow('MediaPipe Hands', image) # 将图片展示出来
if cv2.waitKey(5) & 0xFF == ord('q'):
break
hands.close()
cap.release()
它训练的时候是使用了两个模型,第一个是手掌检测,第二个是在手掌范围内进行关节点的检测。这里面的三维坐标中的Z轴并不是绝对意义上的Z轴,而是相对于手腕的位置,正值说明在手腕的前方,负值在手腕的后方。x和y都是0~1之间的数字(经过归一化后的数字,用这个数字乘图像的长度和宽度就得到了绝对的位置坐标)。各个关节点的索引:

设计一个合理的根据Z轴数值计算画线半径的函数,可以得到距离摄像头越近,关节点越大,否则关节点越小的效果,还可以设计不同的颜色,增加可玩性。
**思考:**result.multi_hand_landmarks中包含了检测到的所有手的关节点的坐标信息,可以将这些信息当作另外一个模型的输入,或者先将输出保存下来,制作数据集,然后进行下游任务训练。而且mediapipe这个工具底层是使用C++语言编写的,而且进行了加速优化,速度非常快,完全可以用它进行数据获取。
MediaPipe原文献:“MediaPipe Hands: On-device Real-time Hand Tracking论文阅读”
论文主要贡献:
- 提出了一个高效的实时的两阶段手部姿势追踪工作流。
- 通过输入彩色图像,可以获得一个2.5D的手部关节点。(深度是手部与手腕的深度,并且是猜出来的,并不是真实距离)
- 开箱即用的手部追踪工作流,并且支持多个平台,包括IOS、安卓、Web,桌面PC。
模型结构:
包含了两个机器学习工作流,第一个是手掌检测器,输出的是手掌的bounding box(包含了手掌的位置区域)。第二个是手部关节点检测的模型,输入是手掌的bounding box的图像,返回的是高质量的2.5D的21个关节点的坐标。
对于实时的关节点检测,它是从上一帧的关节点提取出来一个bounding box作为下一帧的输入,所以不需要重复进行手掌检测。什么时候进行手掌检测?第一帧以及画面中没有检测到手的时候。这样大大节省了时间,提升了效率。
手掌检测模型结构:

第一,训练了一个手掌检测器代替手检测器。因为手掌或者拳头有着更加简单的形状相比于手指。
第二,使用了一个encoder-decoder的特征提取器,类似于FPN。
第三,损失函数使用了focal loss。
关节点检测模型:

把刚刚提取到的手掌提取器框,输入到关节点检测模型中,得到21个关节点的2.5D坐标。
由于得到的是数值,因此是一个回归问题。该模型有三个输出:
- x、y、z坐标
- 手的置信度
- 左手还是右手
x,y的坐标是通过真实世界的手的照片进行标注得到的,也有一部分电脑生成的假手的图像。
z坐标是只通过电脑生成的图像进行训练的。(真实世界无法获得相对深度信息)
为了防止错误,还设置了一个置信度,如果置信度低于某个阈值,则手掌检测器会被重新启动。
对于左手和右手的判断对AR/VR有着极其重要的作用,
数据集
构建了三个子数据集:
- 真实世界的照片:包含六千张,不包含手的复杂动作。
- 实验室的数据集:特定条件下拍的,包含一万张。
- 电脑三维模型生成的图片,可以知道深度的标签。使用模型生成视频,再截取十万张图片。
MediaPipe的实现
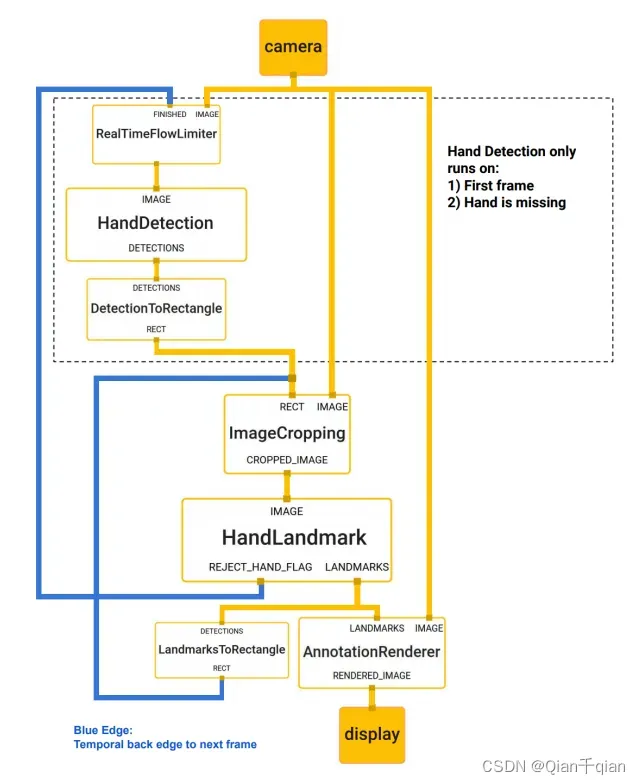
摄像机获取一张图片先送给HandDetection,检测到手掌之后裁剪出来,再送给HandLandmark,这个部分生成一个新的手掌区域送给下一帧,同时输出这一帧的结果。如果某一帧置信度低于某个阈值(检测不到手的存在),则重新使用摄像机捕捉。
文章出处登录后可见!