Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
谷歌 2020
论文地址:https://arxiv.org/pdf/1910.10683.pdf
概述
T5是一个统一的模型框架,将各类NLP任务都转化为Text2text任务(即无监督/有监督的文本生成预训练任务),使得这些任务在训练时能够使用相同的目标函数,在测试时使用相同的解码过程。
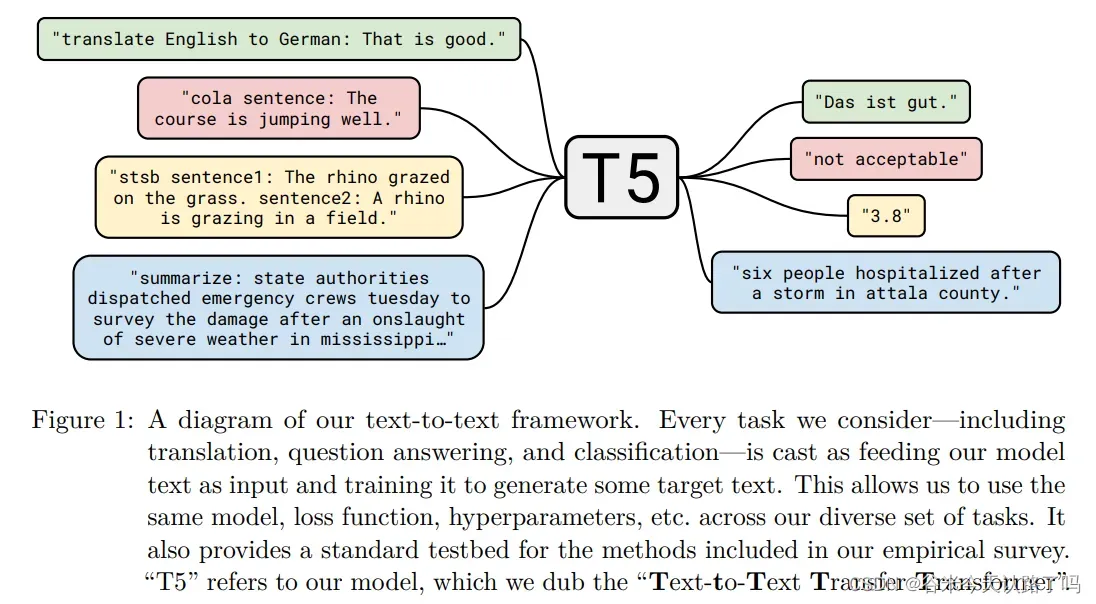
T5模型结构
与Transformer的encoder-decoder结构大致一致。
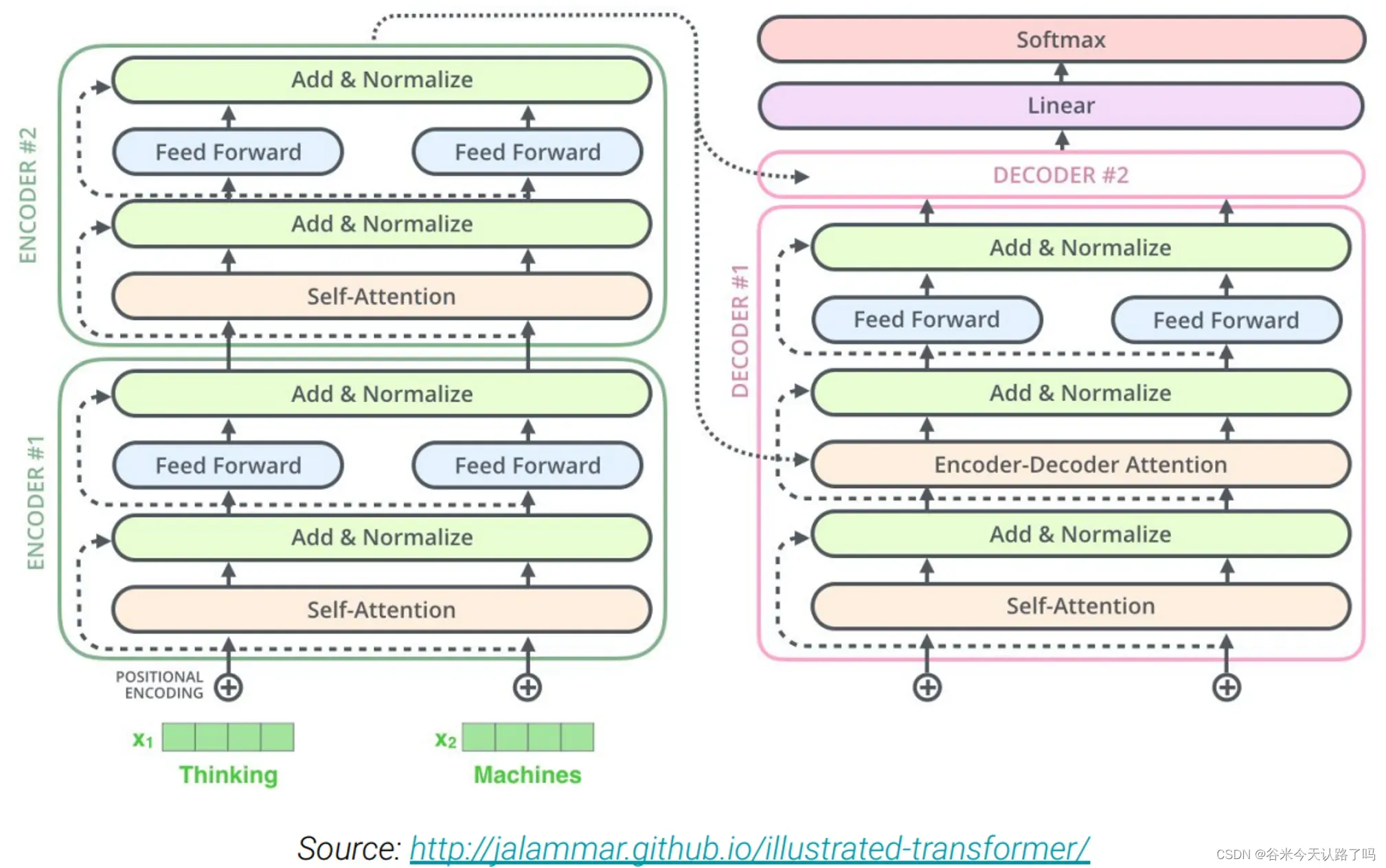
但主要有以下几点不同:
- 删除了LayerNorm中的bias
- 将LayerNorm操作放在了残差连接后面
- 使用了一种相对位置编码的方案
(顺带一提,上述改动是最原始的T5,后续谷歌又对T5做了优化,即T5.1.1)主要升级: - 改进了FFN部分,将relu激活的第一个变换层改为了gelu激活的门控线性单元:

- T5.1.1只让Encoder和Decoder的Embedding层共享,而Decoder最后预测概率分布的Softmax层则用了一个独立的Embedding矩阵(之前是三个层都共享一个Embedding矩阵)
- 在预训练阶段去掉了dropout,只有微调的时候使用dropout
数据集
作者自己构造的数据集 C4: the Colossal Clean Crawled Corpus
输入输出格式
类似于显式prompt的形式,人工设计了前缀来提示T5需要解决的任务类型,如图1所示。
- translate English to German: + [sequence]:翻译任务
- cola sentence: + [sequence]: CoLA语料库,微调BERT模型。
- stsb sentence 1:+[sequence]:语义文本相似基准。自然语言推理和蕴涵是类似的问题。
- summarize + [sequence]:文本摘要问题。
这样的话,NLP任务就被统一成了:
Prefix + sequence A -> sequence B
一系列的实验
最后作者进行了一系列的实验确定了T5模型的最终结构和训练方式(有钱真好):
- 模型架构:类似于Transformer的Encoder-decoder;
- 无监督训练目标:采用span-corruption目标,类似SpanBERT的做法;
- 预训练策略:采用multi-task预训练方式(即无监督任务和有监督任务一起预训练)
参考文献
- https://spaces.ac.cn/archives/7867
- https://www.jianshu.com/p/e44edb65f65e
- https://blog.csdn.net/yangyanbao8389/article/details/121131751
文章出处登录后可见!
已经登录?立即刷新