文章目录
- 中文语句理解
- “我一把把把把住了”
- “别别别的”
- 藏头诗
- 文案策划
- 组会汇报文档
- 视频文案
- 课程大纲设计
- C++考点设计
- 人工智能引论
- 生活场景
- 旅游计划
- 代码生成与分析
- 样例1:python多进程程序
- 样例2:数据处理程序分析
- 图像理解
- 样例1:太阳图像
- 样例2:军火铺
- 样例3:召回率
- 图像生成
- 样例1:超现实主义
- 样例2:离离原上草
- 插件(其他功能)
- 快读插件
- AI视频助理
- 总结
中文语句理解
其他广泛使用的大语言模型(如ChatGPT)在复杂的中文语句理解上存在一些问题,例如一词多义等。以下使用若干样例对文心一言的中文语句理解能力进行测试。
“我一把把把把住了”

可以看出,文心一言不仅能够准确理解其中每个“把”字的含义,甚至了解这句话本身已经成为了一个“一词多义”带有幽默感的特殊情况。
“别别别的”
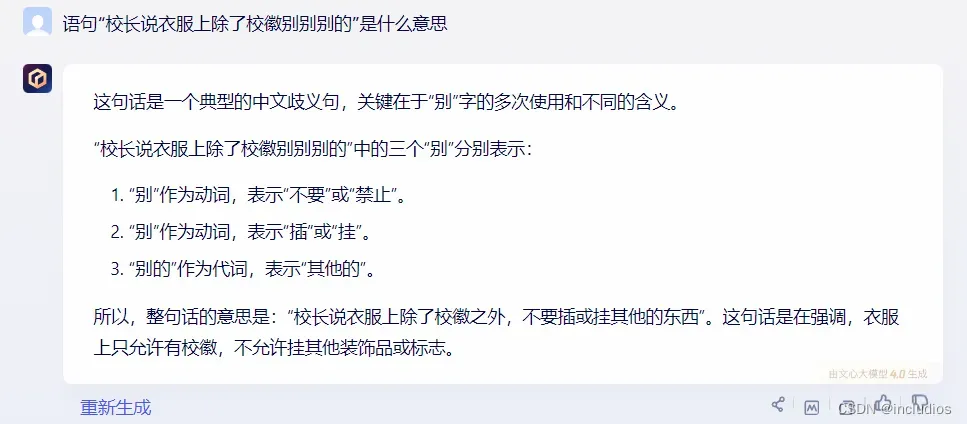
可以看出其同样给出了准确的回答。
藏头诗
可以看出其完成了藏头诗的格式,且诗的内容非常符合藏头的内容
![[图片]](https://aitechtogether.com/wp-content/uploads_new/2023/12/bd5dbd8a-6598-4f5f-84c3-3a12b789fb9a.webp)
文案策划
组会汇报文档



视频文案
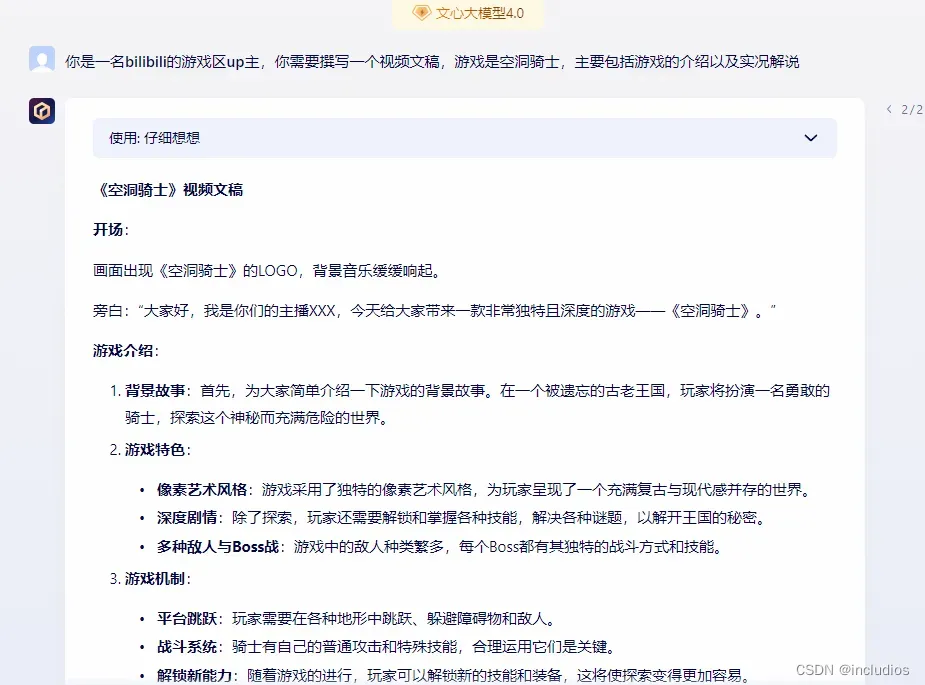
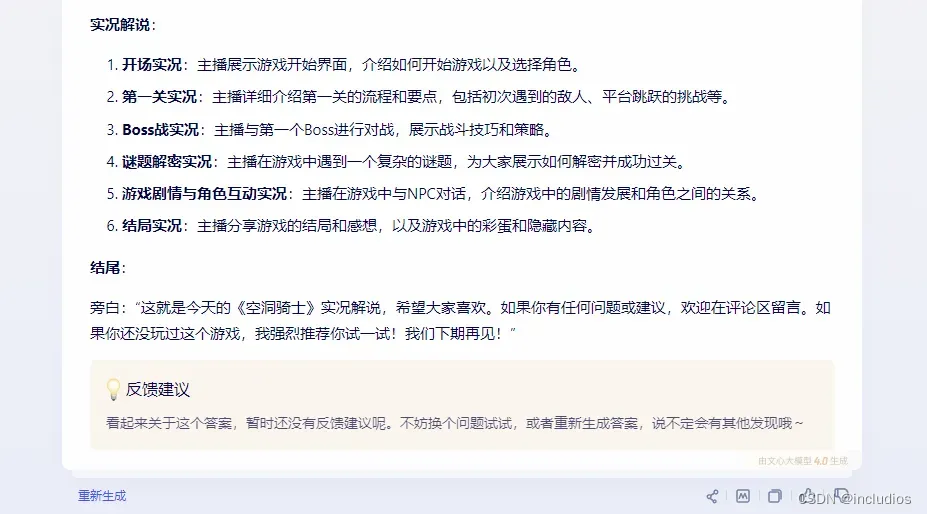
可以看到,在编写视频文案时,文心一言可以很好地对视频内容进行安排,同时也能理解视频的主题,并可以详细地给出视频的流程。
课程大纲设计
C++考点设计

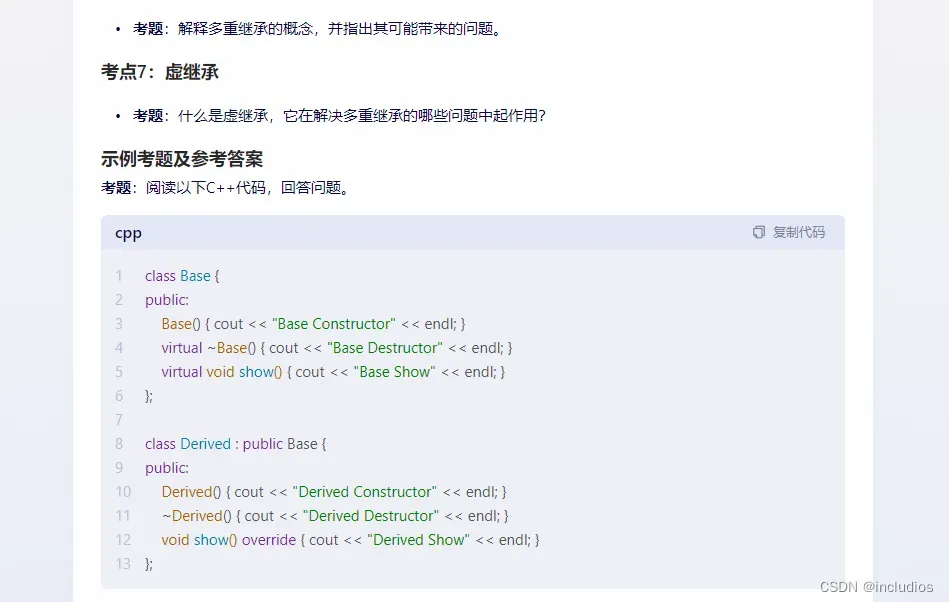
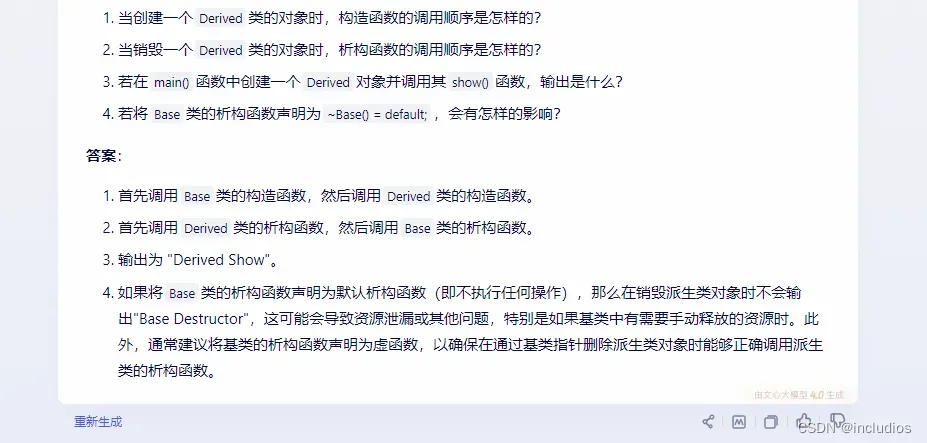
在给出章节名称时,文心一言可以很好地理解对应的课程内容,还能给出该课程的重点难点,并根据考点展示对应的例题。
人工智能引论












可以看到,文心一言可以理解提出的课程“人工智能引论”的主题,同时可以结合课程需要生成初步的课程大纲;当我们提出具体要求时,它可以及时进行反馈;但当我们给出的要求较为开放时,如将两个大纲进行综合时,它的表现较为一般。
生活场景
旅游计划
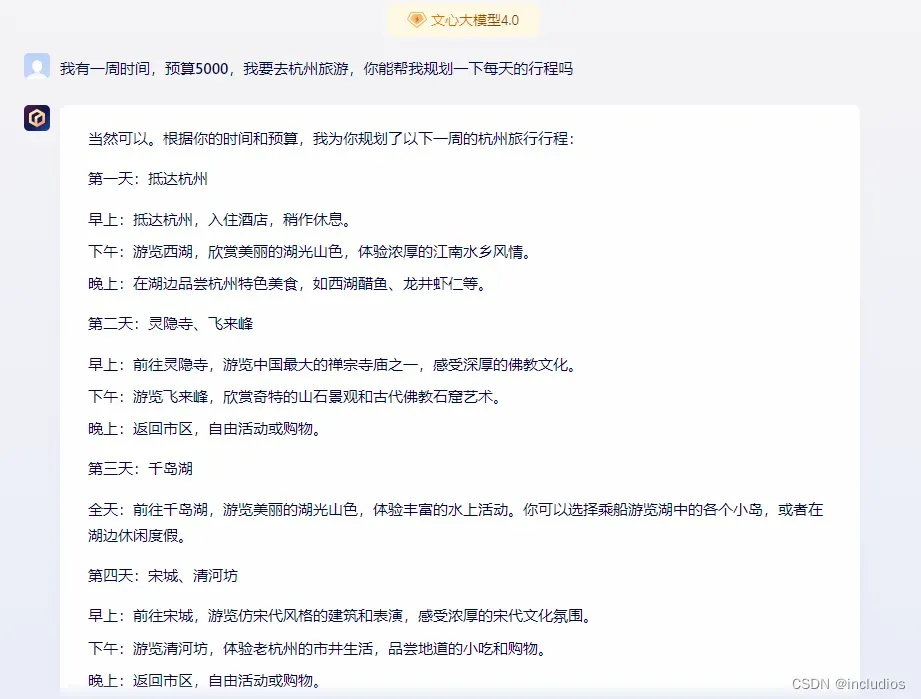
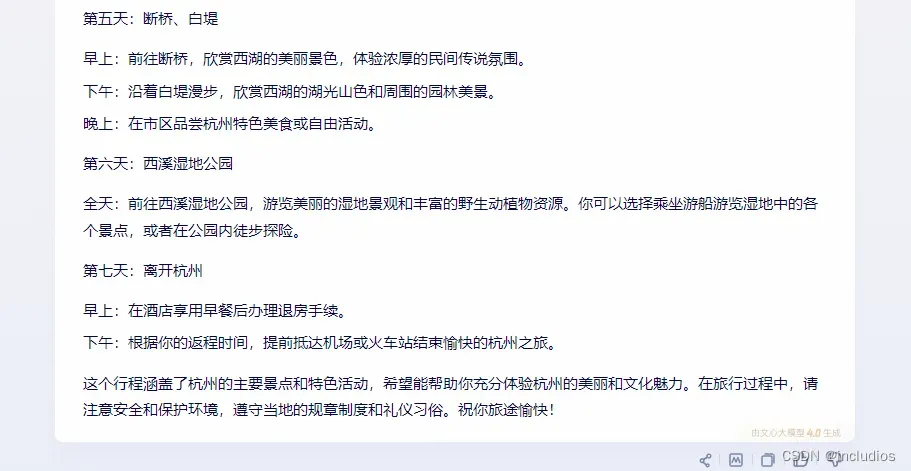
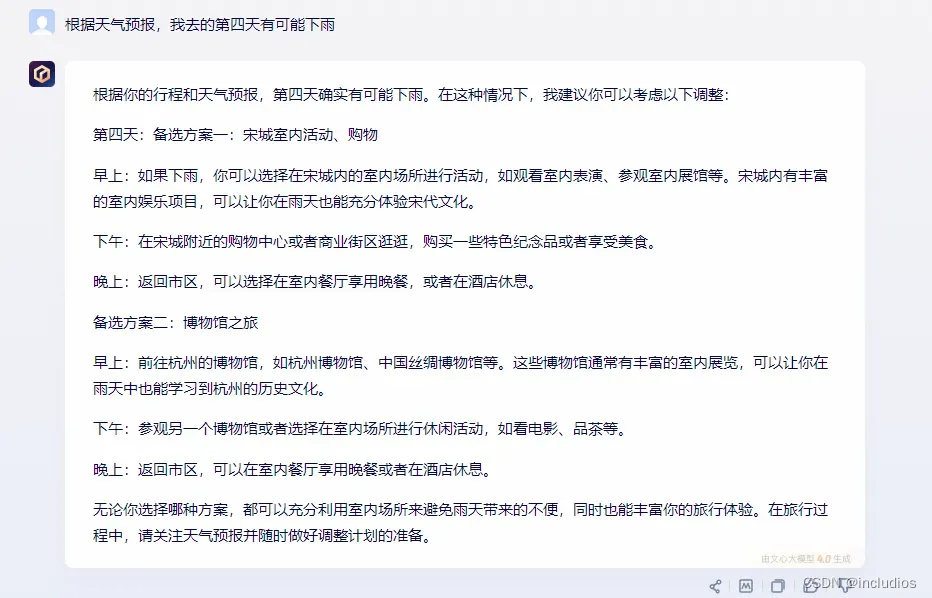
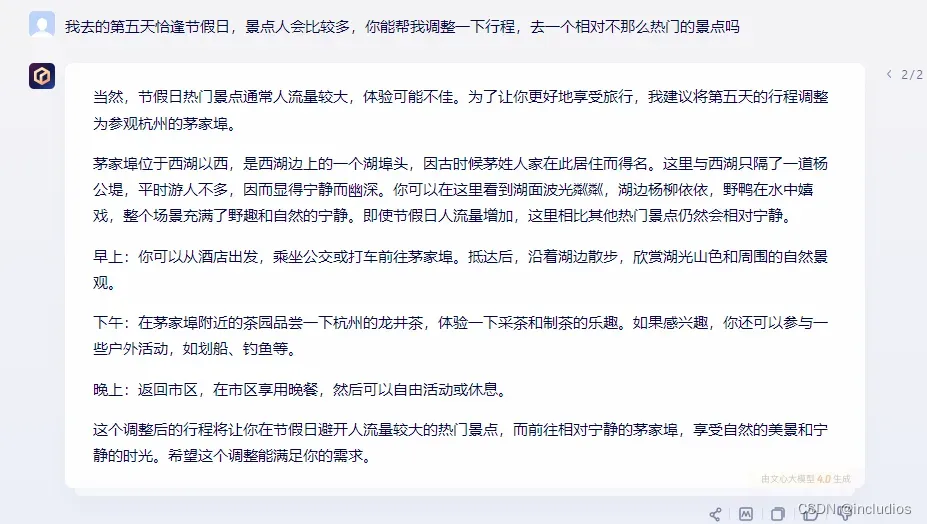
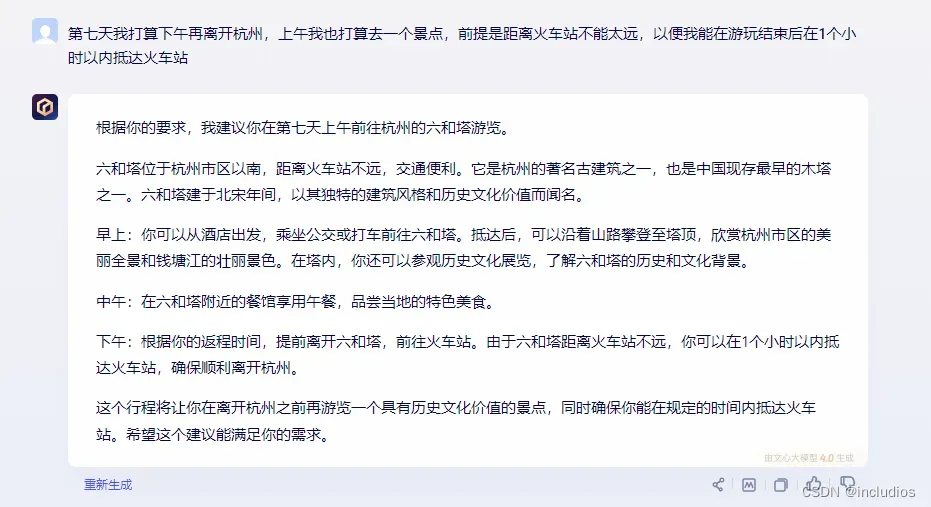
在进行杭州7日游的安排时,文心一言给出的初版答案基本涵盖了杭州的著名景点,美中不足的是第五天的断桥和白堤都在西湖,可归入第一天下午的安排中;我们也可以假设旅途会出现某些特殊情况,从上述的例子中可以看出,针对这些特殊情况,文心一言都能给出不错的应对措施。
代码生成与分析
样例1:python多进程程序
对话及生成的代码如下。整体来说生成的内容还是可以的,主要思路没错,也可以跑通
- 问题1:请编写一个python多进程程序,来处理列表中的1000个样本。每个样本都经过func()函数处理,返回值为处理之后的样本。要求将处理后的样本放到列表中。请提供完整的程序,然后在下面进行解释。其生成的代码如下
import multiprocessing
''
# 定义处理函数
def func(x):
return x * 2
if __name__ == '__main__':
# 创建包含1000个样本的列表
samples = list(range(1000))
# 创建进程池
pool = multiprocessing.Pool()
# 使用map函数将处理函数应用到每个样本上
processed_samples = pool.map(func, samples)
# 关闭进程池
pool.close()
# 等待所有进程完成
pool.join()
# 输出处理后的样本列表
print(processed_samples)
- 问题2:很好,你做的很对。但是我现在需要一个进度条来显示处理数据的情况,请修改以上代码来完成这个功能。其生成的代码如下
import multiprocessing
from tqdm import tqdm
# 定义处理函数
def func(x):
return x * 2
if __name__ == '__main__':
# 创建包含1000个样本的列表
samples = list(range(1000))
# 创建进程池
pool = multiprocessing.Pool()
# 使用map函数将处理函数应用到每个样本上,并使用tqdm显示进度条
processed_samples = list(tqdm(pool.imap(func, samples), total=len(samples)))
# 关闭进程池
pool.close()
# 等待所有进程完成
pool.join()
# 输出处理后的样本列表
print(processed_samples)
- 问题3:我想用32个进程来进行并行操作。其生成的代码如下
import multiprocessing
from tqdm import tqdm
# 定义处理函数
def func(x):
return x * 2
if __name__ == '__main__':
# 创建包含1000个样本的列表
samples = list(range(1000))
# 创建进程池,并指定进程数量为32
pool = multiprocessing.Pool(processes=32)
# 使用map函数将处理函数应用到每个样本上,并使用tqdm显示进度条
processed_samples = list(tqdm(pool.imap(func, samples), total=len(samples)))
# 关闭进程池
pool.close()
# 等待所有进程完成
pool.join()
# 输出处理后的样本列表
print(processed_samples)
样例2:数据处理程序分析
- 问题:作为资深算法工程师,请解释以下代码。
while image_token_indices.numel() > 0:
cur_image_features = image_features[cur_image_idx]
image_token_start = image_token_indices[0]
if getattr(self.config, 'tune_mm_mlp_adapter', False) and getattr(self.config, 'mm_use_im_start_end', False):
cur_new_input_embeds.append(self.get_model().embed_tokens(cur_input_ids[:image_token_start-1]).detach())
cur_new_input_embeds.append(self.get_model().embed_tokens(cur_input_ids[image_token_start-1:image_token_start]))
cur_new_input_embeds.append(cur_image_features)
cur_new_input_embeds.append(self.get_model().embed_tokens(cur_input_ids[image_token_start+1:image_token_start+2]))
if labels is not None:
cur_new_labels.append(cur_labels[:image_token_start])
cur_new_labels.append(torch.full((cur_image_features.shape[0],), IGNORE_INDEX, device=labels.device, dtype=labels.dtype))
cur_new_labels.append(cur_labels[image_token_start:image_token_start+1])
cur_labels = cur_labels[image_token_start+2:]
else:
cur_new_input_embeds.append(self.get_model().embed_tokens(cur_input_ids[:image_token_start]))
cur_new_input_embeds.append(cur_image_features)
if labels is not None:
cur_new_labels.append(cur_labels[:image_token_start])
cur_new_labels.append(torch.full((cur_image_features.shape[0],), IGNORE_INDEX, device=labels.device, dtype=labels.dtype))
cur_labels = cur_labels[image_token_start+1:]
cur_image_idx += 1
if getattr(self.config, 'tune_mm_mlp_adapter', False) and getattr(self.config, 'mm_use_im_start_end', False):
cur_input_ids = cur_input_ids[image_token_start+2:]
else:
cur_input_ids = cur_input_ids[image_token_start+1:]
image_token_indices = torch.where(cur_input_ids == IMAGE_TOKEN_INDEX)[0]
- 文心一言回答如下
这段代码似乎是处理多模态数据(例如文本和图像)的一部分,特别是在文本和图像嵌入的结合中。以下是对代码的详细解释:
- 初始化:
– image_token_indices 似乎是一个包含图像令牌索引的张量。
– image_features 可能是从某种图像模型中提取的图像特征。
– cur_image_idx 是当前处理的图像的索引。
– cur_input_ids 是当前输入(可能是文本)的令牌ID。
– cur_new_input_embeds 是一个列表,用于存储新的输入嵌入,其中包括文本和图像嵌入。
– cur_new_labels 是一个列表,用于存储与 cur_new_input_embeds 对应的标签。
– labels 是输入的标签。
– IGNORE_INDEX 是一个特定的索引值,可能用于在标签中标记要忽略的位置。
2. 主循环:
这段代码使用 while 循环遍历所有的图像令牌索引。在每次迭代中,它都会处理一个图像令牌及其周围的文本令牌。
3. 获取当前图像特征:
cur_image_features = image_features[cur_image_idx]
这行代码从 image_features 中获取当前图像的特征。
4. 处理配置选项:
代码中有两个配置选项 tune_mm_mlp_adapter 和 mm_use_im_start_end,它们似乎控制如何处理图像令牌周围的文本令牌。
1. 构建新的输入嵌入:
根据配置选项的值,代码将文本令牌嵌入和图像特征嵌入组合到 cur_new_input_embeds 中。如果启用了上述配置选项,代码会更细致地处理图像令牌前后的文本令牌。
2. 处理标签:
如果提供了标签,代码会相应地调整它们,为新的输入嵌入生成新的标签列表 cur_new_labels。对于图像令牌的位置,它使用 IGNORE_INDEX 标记。
3. 更新索引和令牌:
在处理完一个图像令牌后,代码会更新 cur_image_idx、cur_input_ids 和 image_token_indices 以进行下一次迭代。
4. 结束条件:
循环会一直执行,直到没有更多的图像令牌要处理(即 image_token_indices.numel() > 0 为假)。
总之,这段代码的主要目的是将文本令牌嵌入和图像特征嵌入组合成一个统一的输入序列,同时相应地调整标签。这种处理对于多模态任务(如视觉问答、图像标注等)是非常有用的。
图像理解
样例1:太阳图像

从上述样例中可以发现,文心一言对自然图像的具有不错的理解能力,且可以生成详尽的图像描述,也能对图片的内容进行分析,完成一些针对图像的问答。不过对于较为专业的问题(例如是否有太阳活动),其仍缺乏对应专业知识。
样例2:军火铺

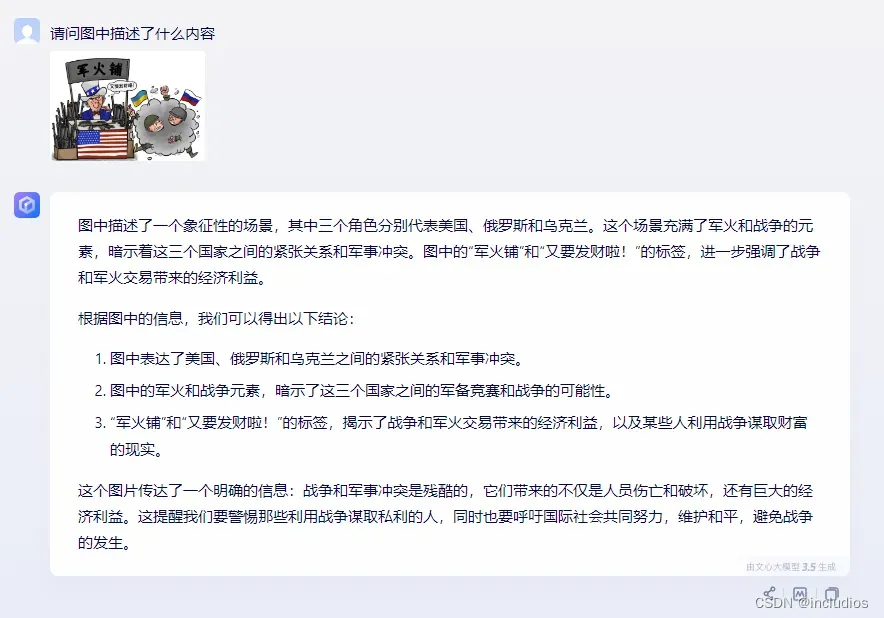
这是一张讽刺俄乌战争的漫画图,可以看到,文心一言很好地理解了漫画的主题,即“战争”,以及图上涉及的三个国家——美国、俄罗斯和乌克兰,它对漫画寓意的理解也十分透彻。
样例3:召回率
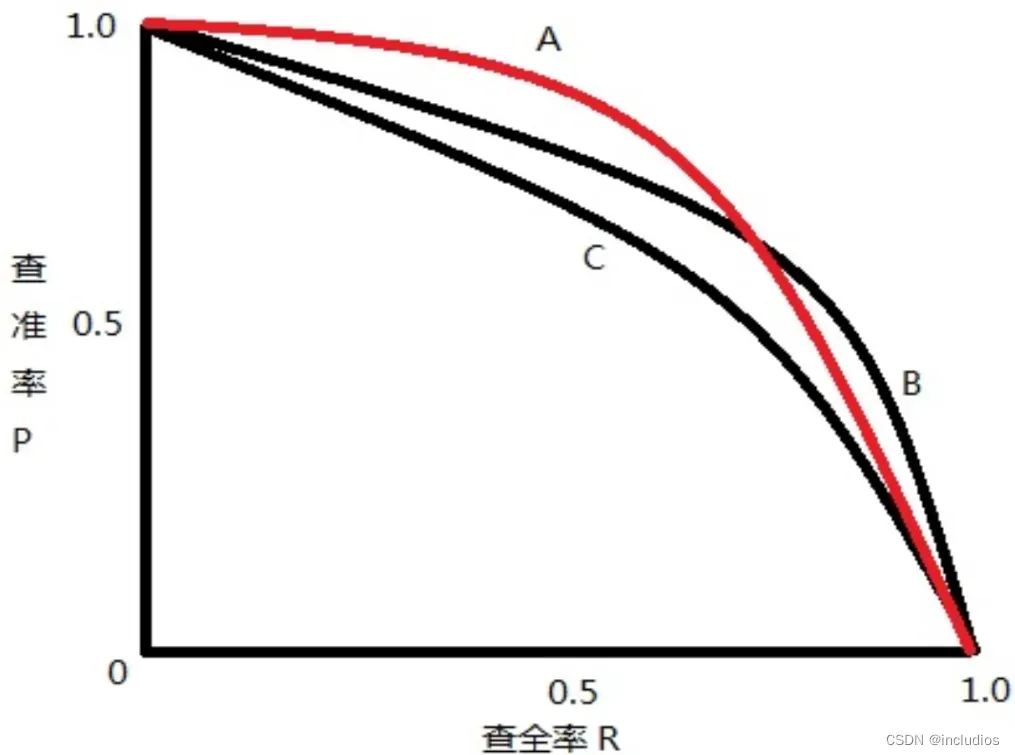
可以看到,文心一言可以很好地理解图像横坐标以及纵坐标的含义,同时也能根据曲线的变化趋势描述查全率和查准率之间的关系。
图像生成
样例1:超现实主义
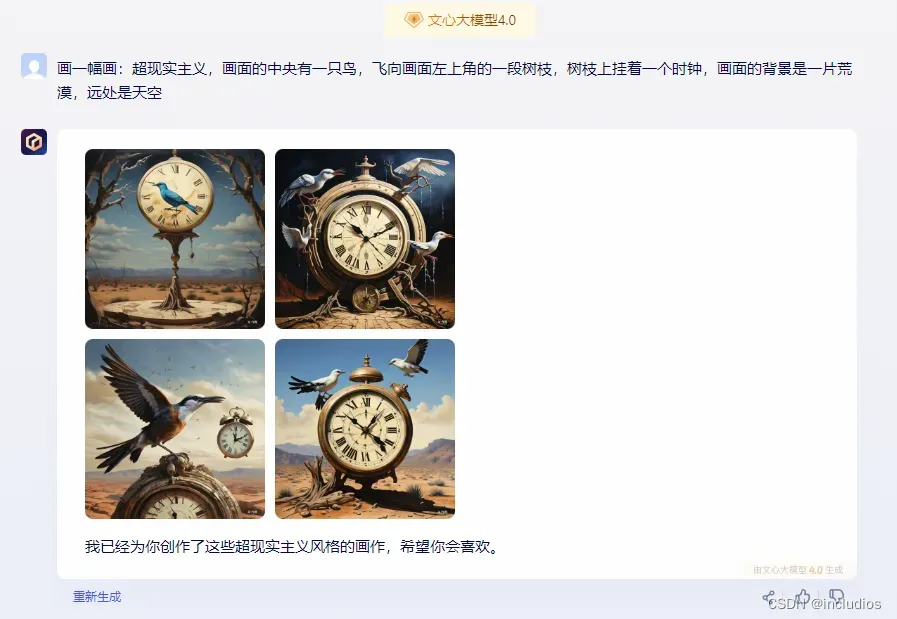
可以看到,文心一言具备基础的绘图能力,它可以理解画面中应该出现的主要元素,即“鸟”、“时钟”、“树枝”、“荒漠”、“天空”,但它对位置信息的理解有些许偏差。
样例2:离离原上草
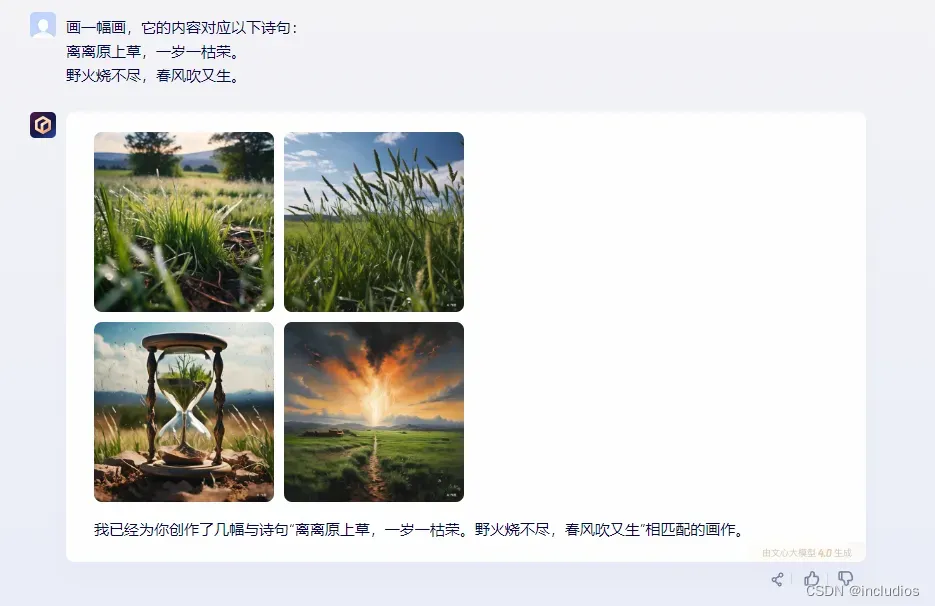
这个例子难度较大,文心一言也是可以理解画面中的主要元素,即“草”,但它对于诗句中后两句的演绎较差,并没有很好地体现“野火”与“春风”这两个元素。
插件(其他功能)
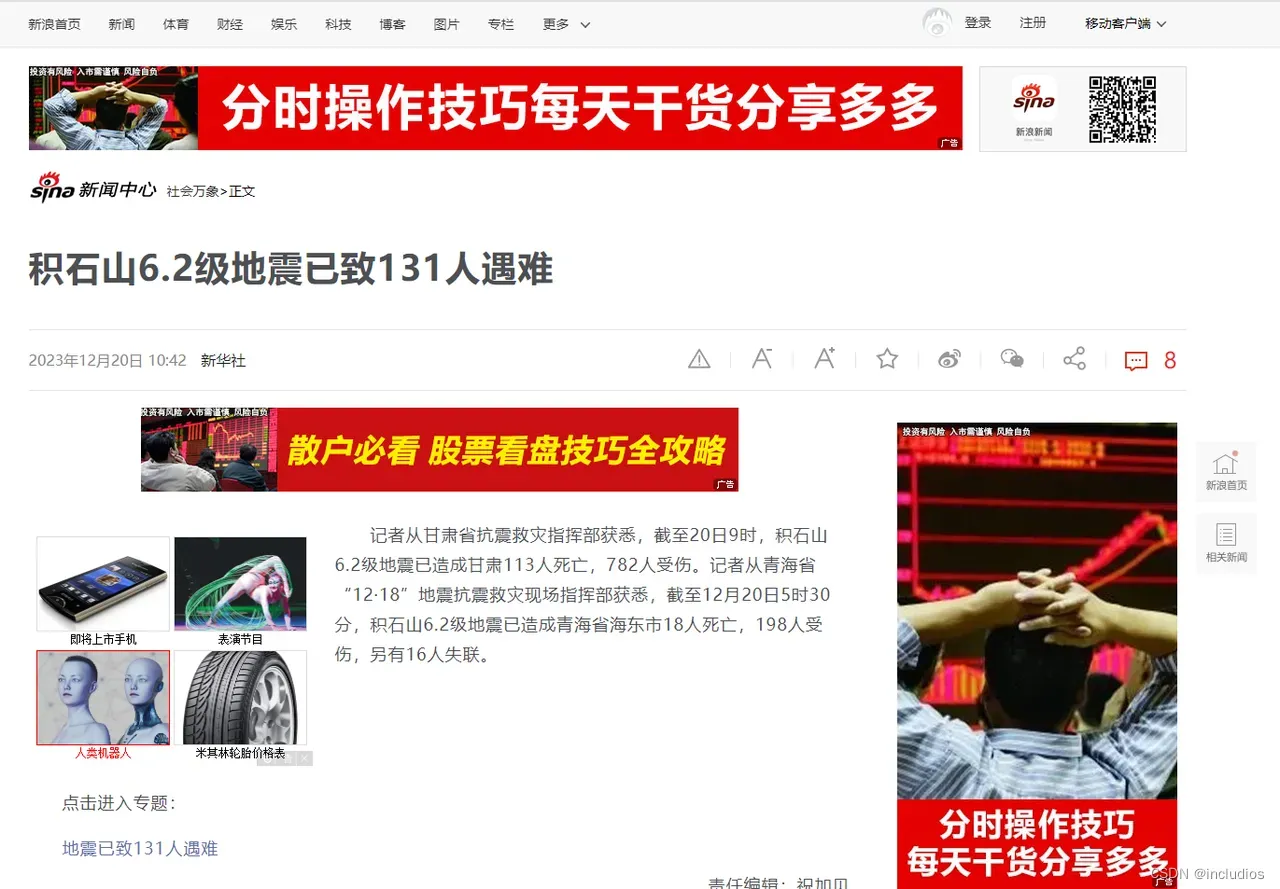
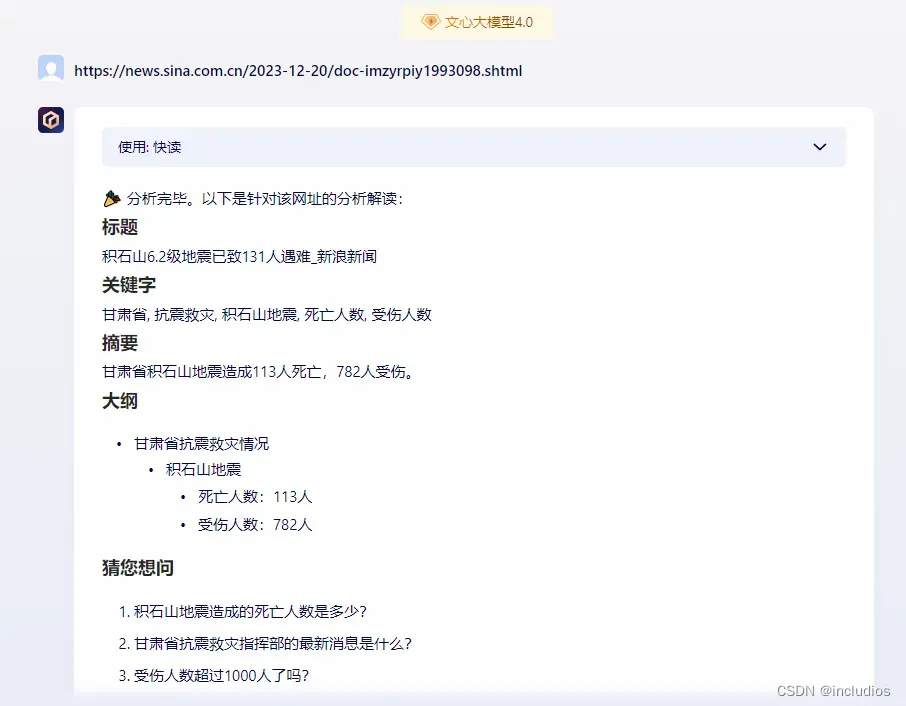
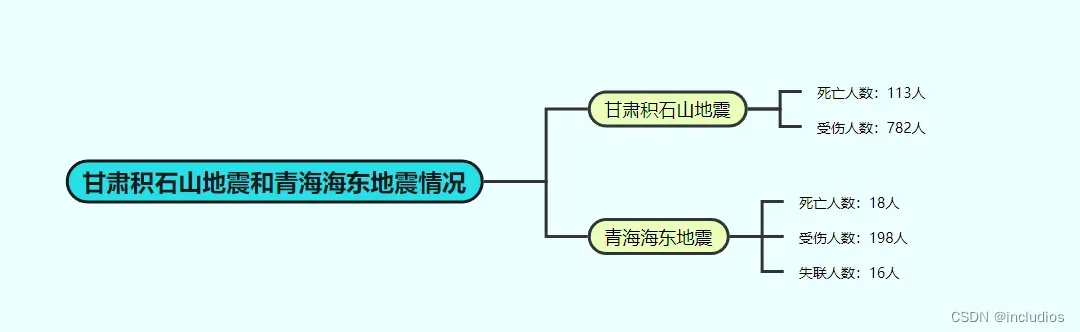
快读插件
快读插件可以通过仅输入网址,提取网页内容的关键词、摘要、大纲以及脑图
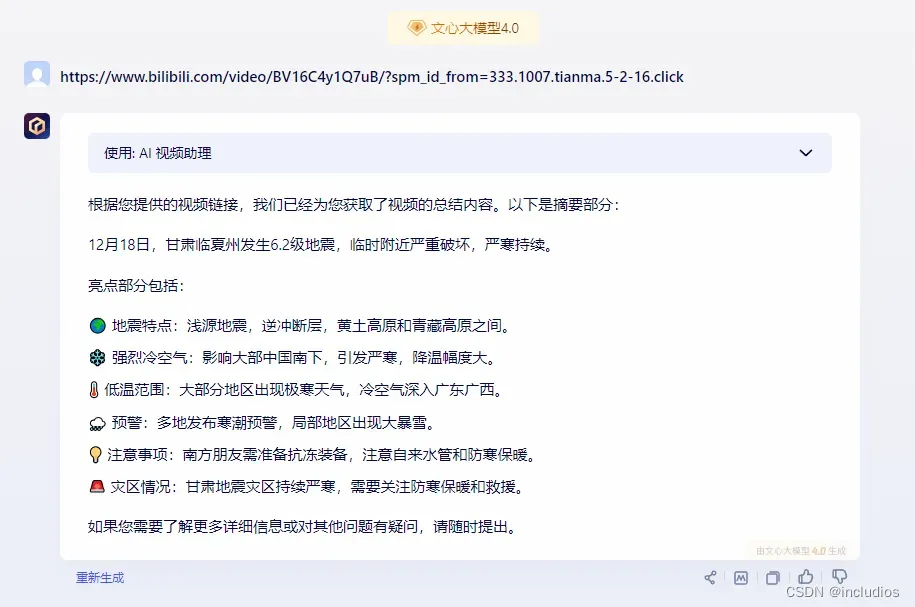
AI视频助理
AI视频助理插件可以通过输入视频链接,自动总结视频内容
总结
从上述样例中可以看出,文心一言4.0在各个场景中均有出色的表现:它涵盖的知识非常丰富,可以解决多个领域的问题,包括日常生活的需要、学术领域的需要,以及更为关键的代码编程需要;它的对话能力非常强大,用户可以通过与之交流,使文心一言的回答越来越接近用户的实际需要;它也配备了强大的推理能力,对于一些需要理解与思考的问题,文言一心可以进行缜密的分析,得出正确的答案;它还具备一定的图像能力,可以理解部分图表的内容以及主题,同时也可以根据用户的要求直接生成相关图片。
在上面这些例子中,可以发现文言一心在中文语句理解方面有着尤为出色的表现,而国外的一些主流模型在这方面的能力较为欠缺。文言一心的一个美中不足之处为它在图像生成任务上表现平平,并不能生成完全符合描述的图片,这一点可能需要稍加改进。另外,在交互设计上,仍然有不够“丝滑”的地方和不一致的问题,例如网页端无法同时输入图片和文字、app端无法根据指令生成图片等。
文章出处登录后可见!