【读论文】SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer
论文:https://ieeexplore.ieee.org/document/9812535
如有侵权请联系博主
介绍
关键词
- Swin Transformer
- 长期依赖性、全局信息
- 跨域融合
简单介绍
2022年发表在 IEEE/CAA JOURNAL OF AUTOMA TICA SINICA的一篇文章,该篇论文的作者仍然是我们熟悉的FusionGAN的作者。
简单来说,该篇论文提出了一个基于CNN和Swin Transformer来提取包含局部信息和全局信息的特征并将这些特征进行域内和跨域融合的方法。
这里有几个关键词——局部/全局信息,域内和跨域,我们先来聊聊这几个关键词。
首先是局部信息,论文中使用cnn提取局部信息,之所以提取局部信息是因为CNN在进行卷积时只关注窗口内的信息,所以是局部信息。
其次是全局信息,论文中使用Swin Transformer来提取全局信息,因为Swin Transformer可以提取长期依赖信息,所以每个特征中都包含全局的信息。
域内就是分别在红外图像特征和可视图像特征中进行Swin Transformer操作。
跨域就是使用红外图像特征的K,V与可视图像的Q进行Swin Transformer操作,反之亦然,从而提取到受到可视特征影响的红外特征和收到红外特征影响的可视特征。
接下来我们就来仔细看看作者是怎么实现的。
网络架构
总体架构
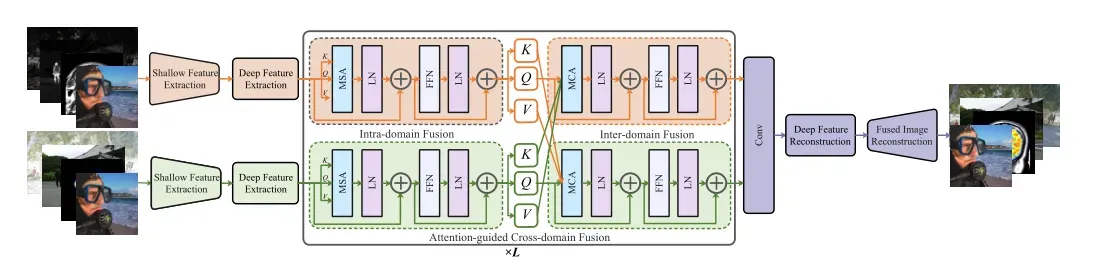
总体架构包含三个部分,分别是特征提取(CNN+Swin Transformer),特征融合(基于Swin Transformer的跨域融合和域内信息提取)和图像重建。
特征提取
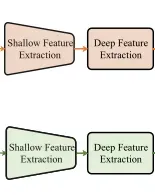
特征提取的网络部分如上图所示
shallow features Extraction包含两个卷积层,其内核大小为3 X 3,步长为1,该层用于提取浅层特征,并且将浅层特征的特征数据映射到高维特征,从而使得后期特征的融合和提取有更好的效果。
Deep Feature Extraction包含4个Swin Transformer层,在shallow features Extraction层的基础上,提取包含全局信息的特征。这里的架构其实很简单,较难的是理解Swin Transformer,详情可看【读论文】Swin Transformer。在看了源码之后,我发现作者好像并没有进行patch的划分,即patch_size大小为1,那swin transformer的早期准备工作就相对简单些。第一步就是将整个图像划分为多个window,这里的窗口大小设置为8 X 8,即每个window包含64个patch,而后在每个window中进行多头自注意力计算,之后在进行移动窗口,移动的距离为window_size的二分之一,而后继续上述操作,直到完成深层特征的提取。
特征融合
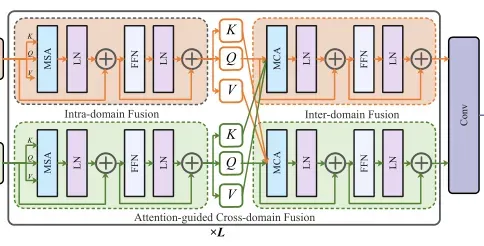
特征融合包含两个块,两个块的结构是相同的,如上图。
每个块中包含两个swin transformer块,MCA和MSA只是名字不同,内部结构是完全相同的,只是MSA输入的KQV都是来自单个图像的特征,而MCA输入的KQV则是来自不同的图像的特征。例如KV来自红外图像的特征,而Q来自可视图像的特征,在经过一波多头注意力的计算之后,此时红外图像的特征信息就受到了可视图像特征信息的影响,从而可以认为两类特征信息发生了融合,这就是论文中的融合模块,也是我认为文章中最惊艳的一部分。
两个块依次进行来完成红外特征和可是特征的融合。
在这之后进入了卷积层,即在包含全局信息的特征中再一次提取局部信息。
图像重建
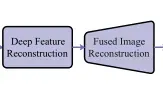
最后一部分,图像重建有两个部分,基于swin transformer的重建模块和基于cnn的重建模块。论文中提到了一个 P Swin Transformer layers,我就浅显的认为这个P就是数量了,作者设置了4个Swin Transformer层来充分获取融合特征的中全局信息,最后设置了三个卷积层用作提取局部信息并且将图像降维到输入的维度,自此图像融合完成。
损失函数
结构损失函数
![]()
纹理损失函数
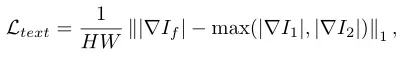
强度损失函数
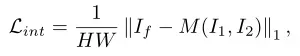
总体损失函数
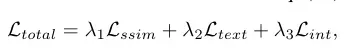
是我们熟悉的几类损失函数,这里就不过多赘述了。
总结
整篇文章读下来,说下我个人觉得很惊艳的点
- 将swin transformer应用到图像融合领域
- 跨域融合这里使用来自不同图像的kv和q进行多头注意力计算
- 纹理损失和强度损失这里均采用最大值的方式,尽可能保留最明显的纹理细节和强度信息
当然,这篇文章不只介绍了红外图像融合,还有其他模态的图像融合,在这篇博客里就不过多解释了,大家有兴趣可以看下原文。
其他融合图像论文解读
==》读论文专栏,快来点我呀《==
【读论文】DIVFusion: Darkness-free infrared and visible image fusion
【读论文】RFN-Nest: An end-to-end residual fusion network for infrared and visible images
【读论文】Self-supervised feature adaption for infrared and visible image fusion
【读论文】FusionGAN: A generative adversarial network for infrared and visible image fusion
【读论文】DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs
【读论文】DenseFuse: A Fusion Approach to Infrared and Visible Images
参考
[1] SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer
文章出处登录后可见!