Do not blindly trust anything I say, try to make your own judgement.
目录
1. Definition
1) Internet AI: 用互联网数据比如wiki, youtube等预训练大模型(foundation model),然后将预训练的大模型应用到下游的CV和NLP任务,经典模型如GPT-3,CLIP。(pretraining + finetune)
2) Embodied AI (具象化AI): 将互联网数据上预训练好的大模型,应用到具象化对象上,使其能够与开放世界(open-ended world)交互,并从中学习行为策略,经典任务如玩minecraft,robotic navigation and manipulation。(增加decision making模块)
2. Survey
2.1 (2022) SayCan:Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
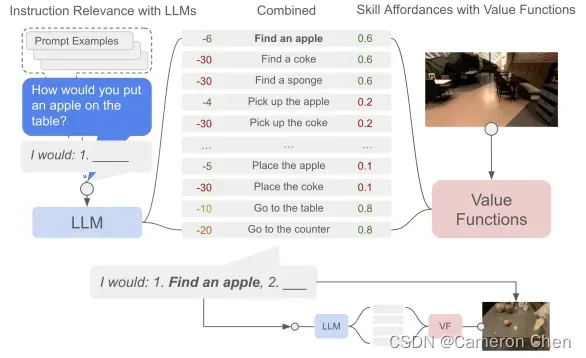
这篇是谷歌的工作。它的故事是这样的,NLP的研究成果可以使embodied agent能够支持高层次的语义指令,一个应用的方式就是把高层的指令用LLM拆解成多个sub-tasks,比如论文中的例子,如果告诉机器人“I spilled my drink, can you help me?”,这时给定prompt就可以用LLM输出先做什么,再做什么。但这样的应用方式并没有考虑机器人当前自身以及环境的状态,比如可能LLM输出第一步是找个抹布,但实际场景中并没有,即没有和open world做交互。因此,作者们提出借鉴RL中的value function作为一个afforcane function,在拆解高层指令时用上视觉信息,考虑了机器人自身和环境当前的状态。整体流程如下:

这个value function 和执行sub-tasks的language conditioned policy model就用Behavior Cloning或Reinforcement Learning来训练,从而完成整个流程的闭环。
2.2 (2022) LM-Nav:Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action
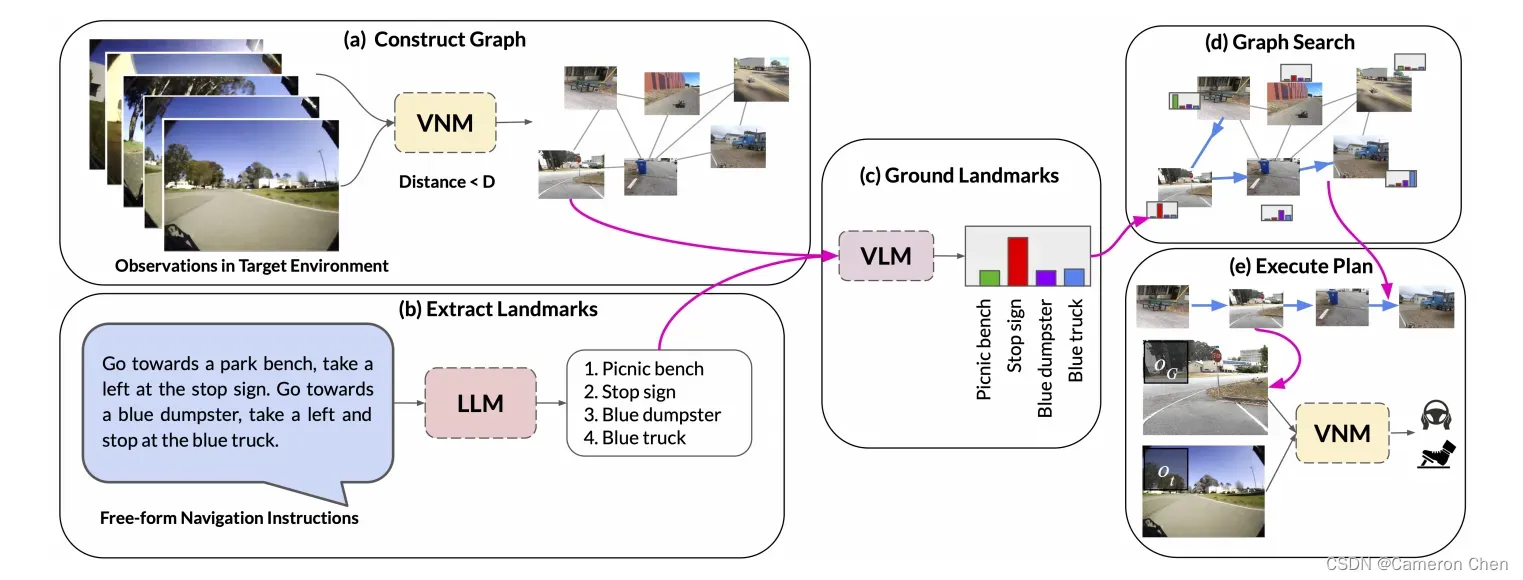
这篇论文是谷歌和伯克利合作的工作,它设计了一个把LLM,VLM,VNM三个大模型统一起来的漂亮框架,但实际上每一环之间还是独立的,VNM中并没有考虑指令信息。
整体pipeline如上图所示,第一步先用VNM中的distance function在采集的数据上建一个拓扑图,图中每个节点是小车经过该位置时采集的一张图片,每条边表示两个节点间是否可达;第二步给定文本指令,用LLM(GPT-3)提取其中的landmarks;第三步用VLM(CLIP)将提取的landmarks grounding到拓扑图中,这样在图中定位了路径点就可以规划一条路径;第四部用VNM中的pose function估计路径中相邻两点间的相对位姿,从而执行规划,同时用distance function做基于视觉相似度匹配的实时定位。
该论文用的VNM是这篇论文一作Dhruv Shah在21年的工作ViNG,它其实就是在18年的SPTM上加了graph pruning和negative mining两个工程上的tricks,算法上没有创新,论文里说他的亮点是第一个在真实小车上实现这个模型的工作,而且只需要用离线数据做监督学习,不需要仿真器训RL。但值得注意的是,ViNG和SPTM里用到的pose function,本质上就是一个Inverse Dynamic Model,IDM可以学习玩电玩也同样可以学习机器人导航任务。
2.3 (2022) VPT:Video PreTraining Learning to Act by Watching Unlabeled Online Videos
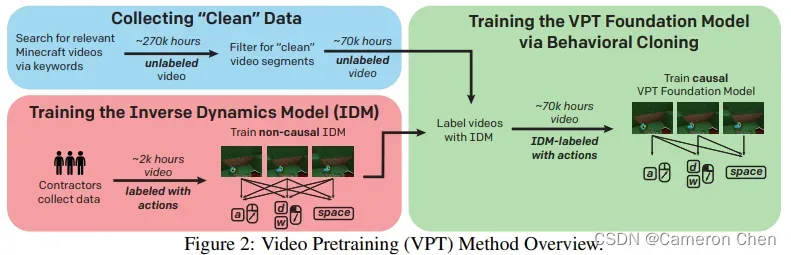
这篇论文是openai的工作,它研究如何用网上的unlabled videos训练模型玩Minecraft。具体的做法是先人工标注一小部分数据,标注的是两帧图片之间的action,以此训练一个Inverse Dynamic Model(IDM),然后用IDM去给所有的videos标注每一步所执行的动作,再加上一些数据清洗,最终就有了专家数据,这样就可以用imitation learning+reinforcement learning训练一个policy model了。
2.4 (2022) MineDOJO:Building Open-Ended Embodied Agents with Internet-Scale Knowledge
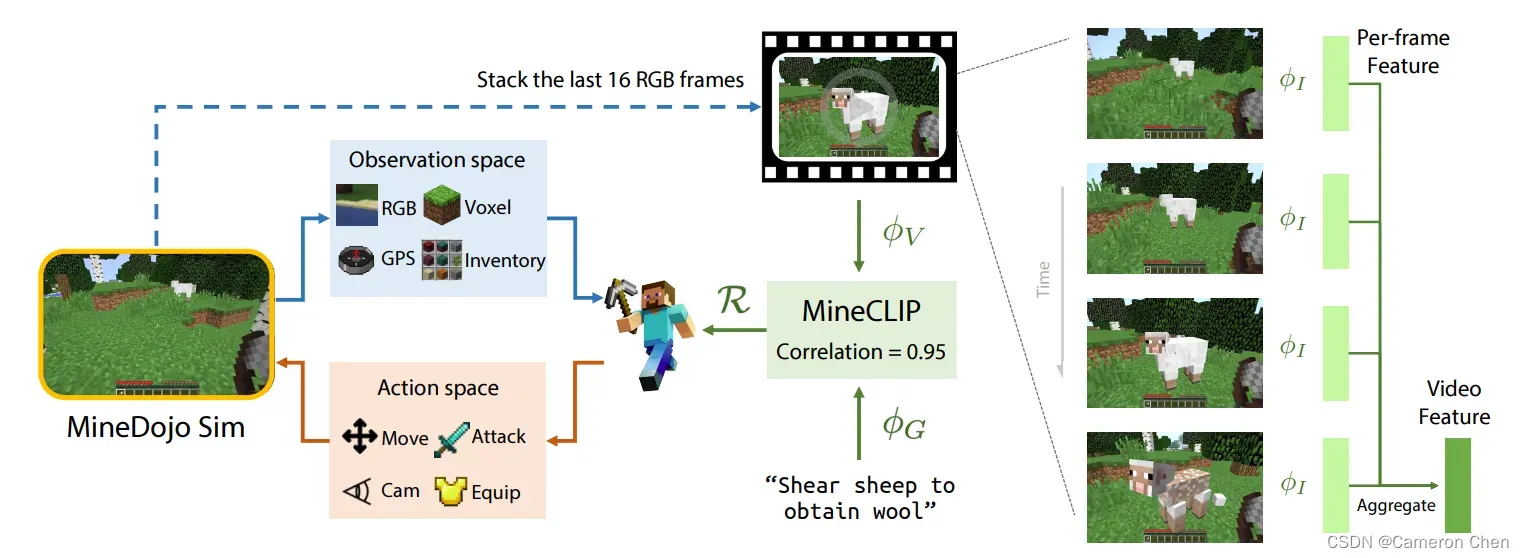
这篇是NVIDIA的工作,它同样探讨如何将NLP中的large-scale pre-training范式应用到embodied AI 的任务中,具体的思考切入点是1)如何让embodied agents在与环境中交互学习时能够用大规模的互联网数据作为knowledge base,2)如何设计用于玩Minecraft的reward function。
具体而言,作者们搜集了互联网上关于玩Minecraft的wiki描述、videos、人类玩家的攻略和评论等等,制作成大规模数据集,在该数据集上训练一个CLIP模型,在videos和对应的text描述之间做contrastive learning,预测它们之间的correlation scores,这个scores可以直接作为reward function作为真实Minecraft中的反馈,而不需要任何domain adaptation。
有了这个reward function,就可以用RL(PPO)+self imitation learning交替训练,其中self imitation learning就是用当前训练的PPO模型做rollout,其中成功了的轨迹作为专家轨迹用于imitation learning,是一个提高RL训练的sample efficiency的trick。
这个MineCLIP的模型同样做的是把policy conditioned on vision and language。其中用网络数据训reward function的思想其实和ChatGPT异曲同工,相当于以reward function的形式构造一个teacher,指导一个能够适应人类习惯的policy模型。
2.5 (2022) LID:Pre-Trained Language Models for Interactive Decision-Making
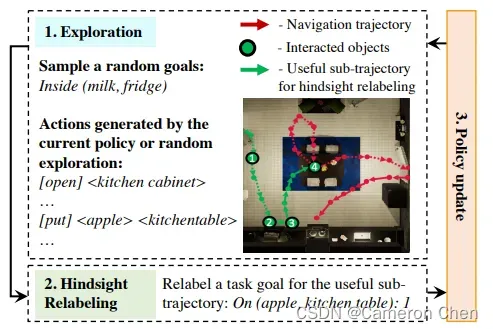
这篇NVIDIA的工作研究如何将预训练的语言模型应用到embodied agent的决策任务中,通过实验验证了预训练作为初始化+微调的范式能够给策略模型提供很强的zero-shot泛化能力;此外还研究了如何在没有专家数据的情况下主动采集数据用于策略模型的训练,做法就是借鉴强化学习里的hindsight experience replay(2017),给agent执行的轨迹打上合适的标签,即使失败的经验,通过把label改成它当前所做的事情,也能从错误的经验中拿来训练。
2.6 (2022) LATTE: LAnguage Trajectory TransformEr
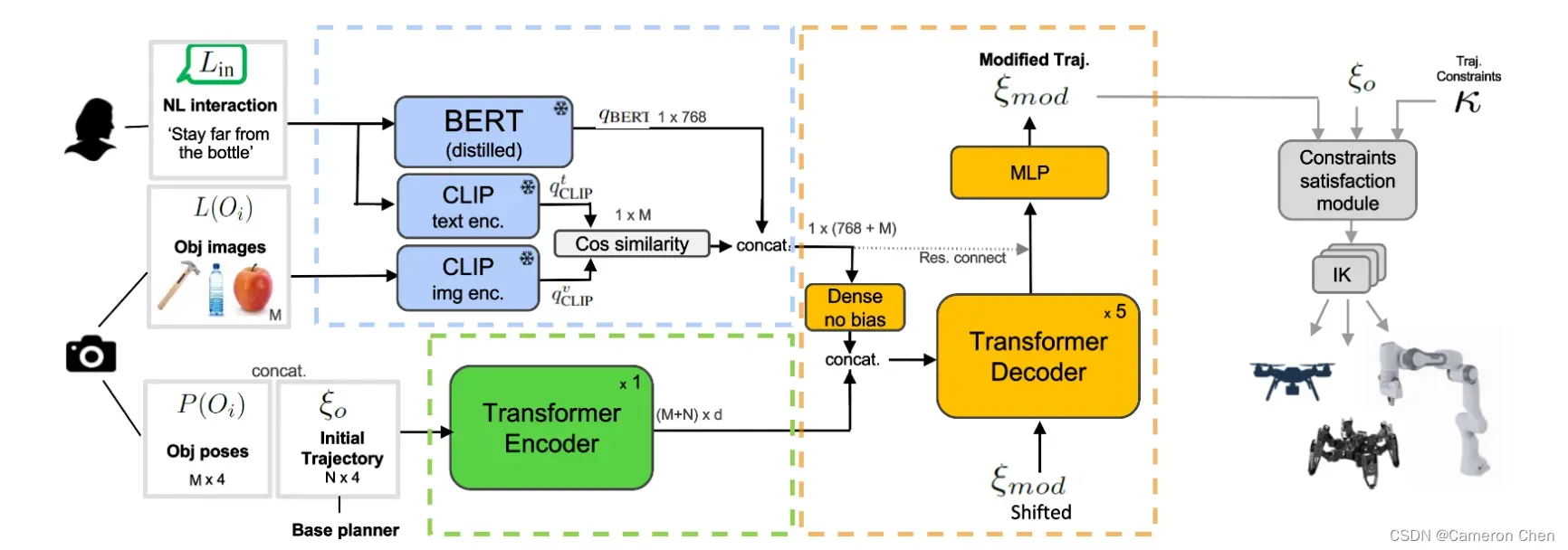
这篇论文是微软的工作,它研究的问题是让机械臂能够根据语言指令修正轨迹。简单来说,给定一个目标物体,它先用传统算法如A*,MPC等产生一条轨迹,再结合语言指令如‘go closer to xxx’, ‘stay far from xxx’, ‘drive a bit away from xxx’ 等,用transformer decoder输出修正后的轨迹。
传统算法生成的轨迹用transfomer encoder编码,输入的语言指令和当前视觉图像由预训练好的BERT和CLIP模型编码,最终后者与前者一起输入到transformer decoder中,通过cross attention将轨迹conditioned在语言和视觉信息上,并序列化输出新的轨迹。模型的训练采用imitation learning。
这篇工作也是典型地将policy conditioned在特定的视觉和语言信息上。整体框架虽然采用了transformer的结构,但其实也很常见,主要还是提出了一个将预训练模型应用到人机交互过程的范式。
2.7 (2022) VIMA: GENERAL ROBOT MANIPULATION WITH MULTIMODAL PROMPTS
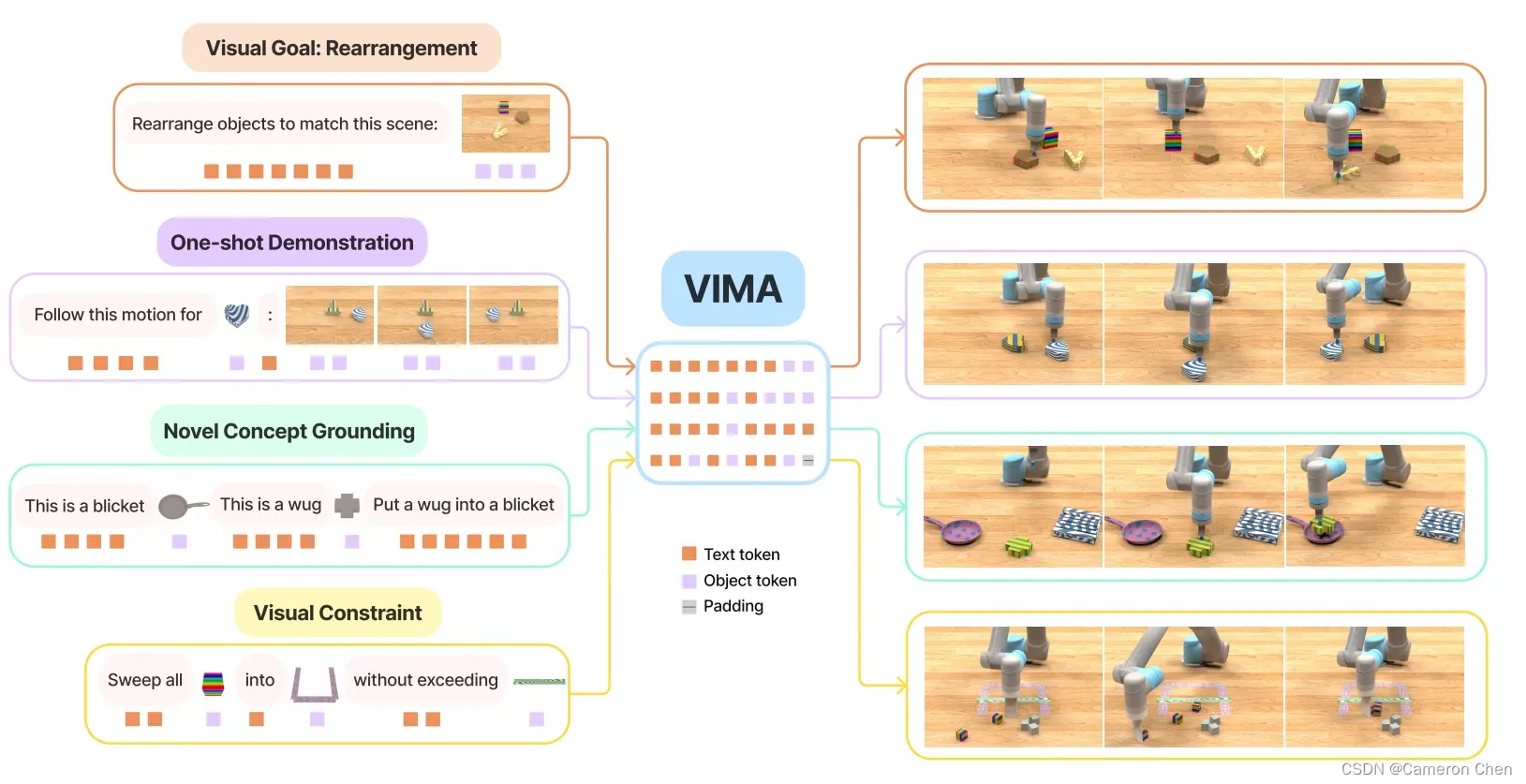
这篇NVIDIA的工作同样在研究一个通用robot agent的人机交互接口应该是怎样的。一个有意思的发现是人类指令文本prompt可以由文本和图像的交替(interleave)构成,而不是纯文本,这样的好处是可以通过特定物体的图像指定更为特定和准确的指令,比如下图左侧展示的把指令文本中的objects直接换成当前场景中该物体的图像;另一个观察是,过去要让机器人完成不同的操作任务需要在不同的数据集上训练不同的policy model,不能完成模型的统一,而如果改成这种多模态的prompt,则可以更好地迁移对物体和对动作的理解与策略。厉害的点在于它能够超过GATO的zero-shot能力。
该算法用的是经典的在transformer中交替做self-attention和cross-attention的技术,同样借鉴自NLP的研究成果。首先把语言文本进行分词得到word token,然后用Mask RCNN把当前场景中的物体检测出来,输送到ViT中得到object token,这样把两者结合就得到多模态prompt,并将其输入到预训练的T5模型的得到embeddings,最后通过cross attention的方式注入到动作策略中。这里动作的生成同样用的Transformer decoder做序列化决策。
2.8 (2022) RT-1: Robotics Transformer for real-world control at scale
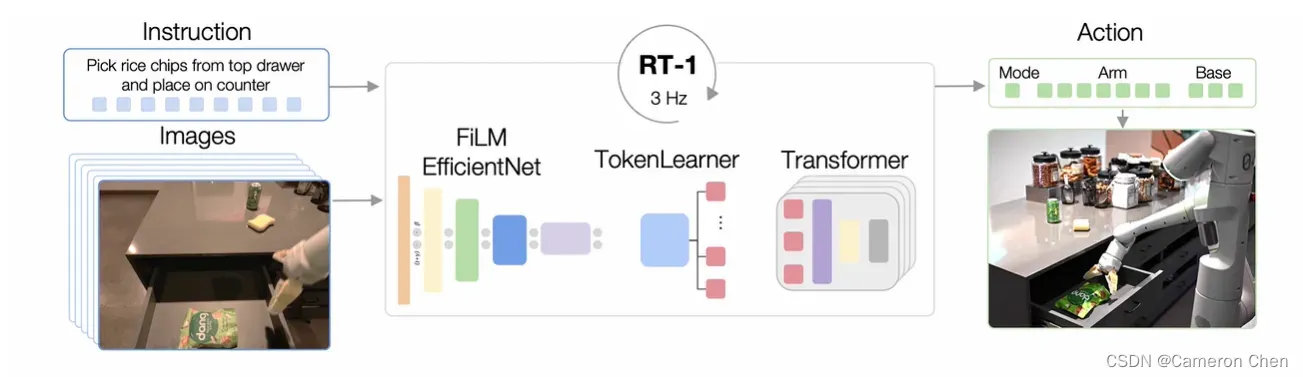
一个端到端输出控制策略的大模型,sequence of images和instruction分别作为输入,没有作为multi-modal prompt。
2.9 (2023) Chatgpt for Robotics

Microsoft的原文对流程也写的很直接简单,它定义了新的robotics工程范式,用chatgpt帮忙写代码。具体方法就是先预定义一些API(相当于Import xxx),然后写一些prompt描述任务,以及说明哪些api可以用,从而让chatgpt自己调用API来写代码,然后人对代码给出反馈,chatgpt基于反馈不断纠正代码,最后用来给机器人执行。
这个就有点抽象了,一是人去写prompt需要先熟悉prompt engineering,而且语文表述不清楚还会影响代码质量;二是人如何去评估算法性能,没有像做算法题那样有测试数据或者实际去运行代码,单靠肉眼很难看出来有没问题。
2.10 (2023) PaLM-E: An Embodied Multimodal Language Model
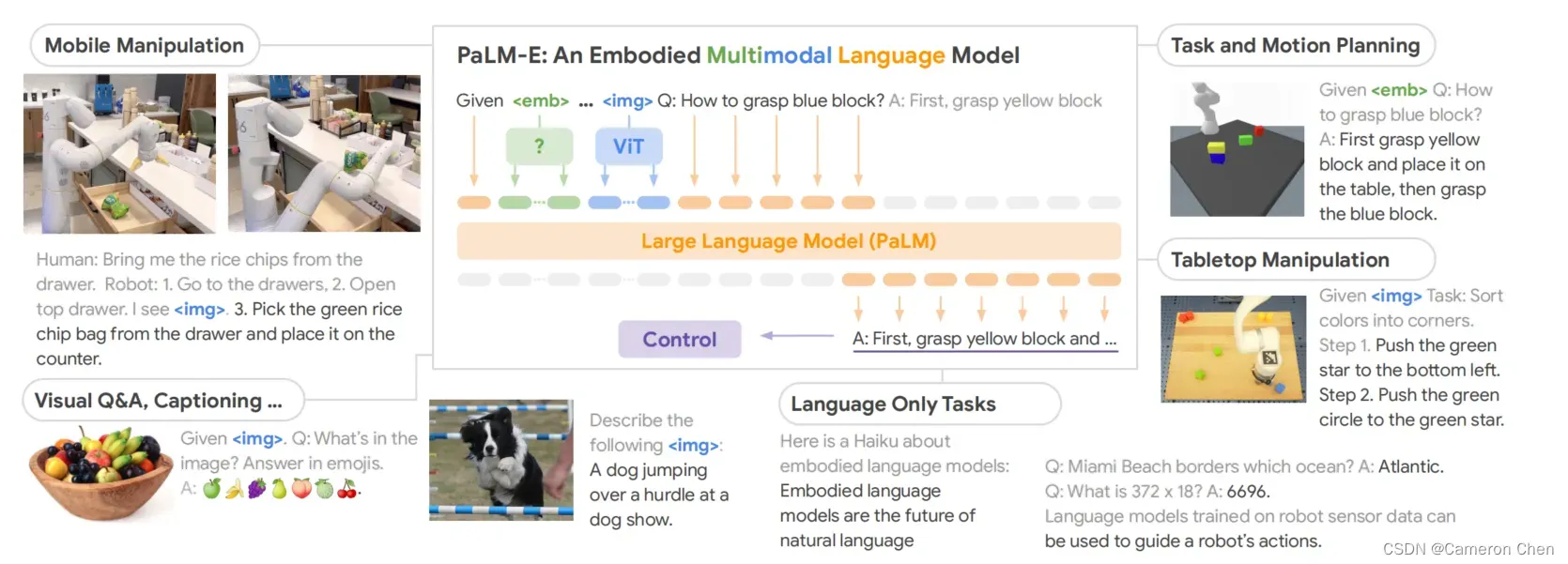
这篇3月6日新出的谷歌工作,其实就是saycan和vima的结合版。它同样像saycan一样用LLM(PaLM)对人类指令做拆解,输出的是文本形式的task planning结果,比如“先做什么再做什么”之类的;而给模型的指令由saycan中的纯文本形式改成了类似vima那种自由动态的多模态interleave形式,与vima不同的是PaLM-E的模态更多,包括了image-level的语义表征、object-level的表征集、物体或机器人的连续的位姿信号,以及用prompt给同一场景多个相同物体做了标识(referrals);另一个与vima的不同点是vima输出的直接是control(low-level) policy,而PaLM-E输出的是high-level policy,PaLM-E的low-level policy则直接用预训练好的RT-1,一个基于观测输出控制指令的端到端模型。
总结:
从表征设计的角度,PaLM-E在使用多模态输入的PaLM完成Visual Q&A任务的同时接了一个适用于embodied 领域的low-level policy来实现loop closure,使其能够让输出的high-level policy condition在当前的观测和长时序的规划中,反过来也借助VQA的能力让模型对当前的观测有了更加深入的理解(开始尝试让模型理解观测中的物理学:原文Figure2中的Physical prediction)。
从训练方式的角度,PaLM-E的创新点是实验验证了multi-task transfer learning能用大量用Internet vision-language数据加极少(8.9%)的robot相关样本就能训到好的效果。
3. Summary
Embodied AI不算是新领域,但近年来NLP的预训练模型的成功让该领域掀起了新一轮的浪潮,各大高校和公司都在布局这个方向,可以预见,CV+NLP+RL的大一统就在不远的将来。目前的研究还处在新一轮浪潮的初级阶段,研究点主要有:
1)如何将NLP中的预训练模型+微调的范式应用到embodied agent的决策任务中([2][3][4][5]),其中预训练一般是在互联网数据比如videos、或者仿真器中生成的专家经验、或者用hindsight relabelling从自己的历史轨迹中生成数据;embodied agent的决策任务也分为high-level policy做子任务拆解和直接端到端输出low-level policy两种;此外,还要考虑预训练语言模型如何与现实环境交互的问题([1][4][7]),也就是将策略condition在当前机器人自身状态和环境状态上,即affordance。
2)如何设计一个支持通用决策大模型的人机交互接口([6][7]),一般做法是基于NLP的transformer框架,用cross attention的方式引入人类给定的语言文本指令和当前视觉图像信息。
3. Reference
Blogs:
最近一些Embodied AI工作的总结(SayCan/LM-Nav/WebShop/Gato/VPT/MINEDOJO) – 知乎
PR Perspective Ⅰ:Embodied AI 的新浪潮 —— new generation of AI – 知乎
GitHub – YaoMarkMu/Awesome-Pretrained-RL
Papers:
2022 LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action
2022 MINEDOJO: Building Open-Ended Embodied Agents with Internet-Scale Knowledge
2022 VPT: Video PreTraining Learning to Act by Watching Unlabeled Online Videos
2022 Pre-Trained Language Models for Interactive Decision-Making
2022 Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
2022 LATTE: LAnguage Trajectory TransformEr
2022 VIMA: GENERAL ROBOT MANIPULATION WITH MULTIMODAL PROMPTS
2022 RT-1: Robotics Transformer for real-world control at scale
2023 ChatGPT for Robotics: Design Principles and Model Abilities
2023 PaLM-E: An Embodied Multimodal Language Model
文章出处登录后可见!