1. 摘要:
在这篇文章中,我们将介绍如何从零开始使用Python建立你的第一个人工智能模型。无论你是刚接触编程的新手,还是有经验的开发者想进一步探索人工智能领域,这篇文章都将为你提供清晰、详细的指南。我们将一步步探索数据预处理、模型建立、训练和测试的过程,以及如何解读模型的结果。

2. 引言
Python在人工智能开发中的地位,以及为什么选择Python作为开始学习人工智能编程的语言。
随着科技的不断发展,人工智能(Artificial Intelligence, AI)已经成为了当今最热门的话题之一。AI 的应用领域包括但不限于自动驾驶、医疗诊断、金融预测、智能家居等等。而在这个日新月异的领域中,Python凭借其易学易用的特性和丰富的库支持,已经成为了人工智能开发的首选语言。
Python是一种解释型、面向对象、动态数据类型的高级程序设计语言。它的语法简单明了,代码可读性强,且拥有广泛的标准库和开源库,这些特性使得Python成为了开发者们的宠儿,特别是在数据科学和人工智能领域。
Python在人工智能开发中的地位尤为重要。这主要是由于Python拥有众多针对AI应用的强大的开源库,例如:NumPy和Pandas用于数据处理,Matplotlib用于数据可视化,Sci-kit Learn提供了大量的预处理方法和机器学习算法,TensorFlow和PyTorch则是深度学习领域的重要工具。这些库大大降低了开发难度,使得Python在AI领域的地位无可替代。
同时,Python语言的易学易用也是其受欢迎的重要原因。Python的语法结构简单,让初学者更容易上手,提供了一个友好的学习环境。对于初学者来说,Python是一个非常好的起点。掌握了Python语言,你就打开了通往AI世界的大门。
因此,无论你是刚入门的新手,还是有一定基础的开发者,都可以选择Python作为学习AI的工具。接下来的文章将为你详细展示如何利用Python的强大功能,步入AI的世界。

3. 数据预处理:解释数据预处理的重要性,并演示如何在Python中进行数据清洗和预处理。
在AI和机器学习中,数据预处理是一个非常重要的步骤。可以说,好的数据预处理工作是建立一个高效模型的基础。这是因为AI和机器学习模型的工作原理基于数据驱动,因此数据的质量直接影响模型的性能。干净、整洁和准确的数据可以帮助模型更好地学习和预测,而嘈杂的、缺失的或错误的数据则可能导致模型性能下降。
数据预处理主要包括数据清洗、数据转换和数据规范化。数据清洗主要包括处理缺失值、去除异常值和重复值等;数据转换涉及数据的类型转换、离散化等;数据规范化则包括将数据缩放到一定范围内、进行归一化或标准化等。
在Python中,Pandas和NumPy是常用的数据预处理库。以下是一个简单的数据清洗和预处理示例:
import pandas as pd
import numpy as np
# 假设我们有一个简单的数据集
data = pd.DataFrame({
'name': ['John', 'Anna', 'Peter', 'Linda'],
'age': [28, np.nan, 35, 32],
'gender': ['M', 'F', 'M', np.nan]
})
# 处理缺失值,这里我们选择用平均值填充年龄,众数填充性别
data['age'].fillna(data['age'].mean(), inplace=True)
data['gender'].fillna(data['gender'].mode()[0], inplace=True)
# 数据转换,将性别的M和F转为0和1
data['gender'] = data['gender'].map({'M': 0, 'F': 1})
# 数据规范化,将年龄规范到0-1之间
data['age'] = (data['age'] - data['age'].min()) / (data['age'].max() - data['age'].min())
print(data)
以上的代码首先使用Pandas创建了一个简单的数据集,然后使用fillna函数处理缺失值,用map函数进行数据转换,最后将年龄数据进行归一化处理。这只是数据预处理的一个非常简单的例子,实际中的数据预处理可能会涉及到更复杂的操作,但总的来说,Pandas和NumPy为我们提供了非常强大的工具来进行这些操作。
总的来说,数据预处理是AI和机器学习中至关重要的一步,我们应该花足够的时间和精力来进行这项工作。
4. 模型建立:介绍几种常见的人工智能模型(如决策树、神经网络等)
在人工智能和机器学习中,有多种模型可以用于处理不同的问题。这些模型包括但不限于:决策树(Decision Trees)、支持向量机(Support Vector Machines, SVM)、朴素贝叶斯(Naive Bayes)、线性回归(Linear Regression)、逻辑回归(Logistic Regression)和神经网络(Neural Networks)等。
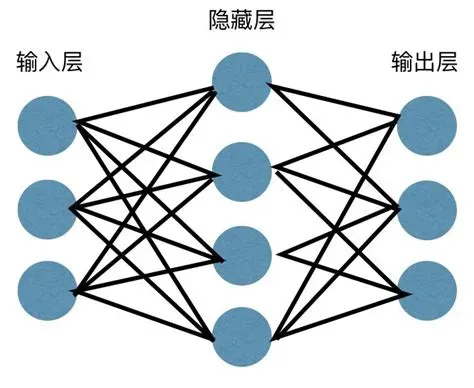
每种模型都有其独特的优点和适用情况。例如,决策树和朴素贝叶斯在处理分类问题时表现优秀,而线性回归和逻辑回归则广泛应用于预测问题。神经网络,特别是深度神经网络,由于其强大的表示学习能力,已经在图像识别、自然语言处理等领域取得了令人瞩目的成就。
在这篇文章中,我们将以神经网络为例,进行详细的讲解。神经网络是由大量的神经元(也称为节点或单元)按照一定的结构相连的网络。最简单的神经网络结构是前馈神经网络,它由输入层、隐藏层和输出层组成。每一层的节点与下一层的节点相连,但不与同层的其他节点或其他层的节点相连。神经网络通过学习输入数据的特征,调整网络中的权重和偏置,使得对于给定的输入,网络的输出尽可能接近期望的输出。
以下是使用Python和PyTorch库建立一个简单神经网络的例子:
import torch
import torch.nn as nn
# 定义神经网络结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(16, 32) # 输入层到隐藏层
self.fc2 = nn.Linear(32, 1) # 隐藏层到输出层
def forward(self, x):
x = torch.relu(self.fc1(x)) # 在隐藏层使用ReLU激活函数
x = self.fc2(x)
return x
# 初始化神经网络
net = Net()
print(net)
以上代码定义了一个简单的全连接神经网络,输入层有16个神经元,隐藏层有32个神经元,输出层有1个神经元。在隐藏层中我们使用了ReLU激活函数。
请注意,以上的神经网络结构非常简单,实际应用中的神经网络可能会包含更多的层和神经元,并使用不同类型的层(例如卷积层、池化层、循环层等)和不同的激活函数。
总的来说,模型的选择应根据实际问题和数据的特性进行,理解每种模型的工作原理和适用情况,对于构建有效的AI系统至关重要。
5. 模型训练和测试
在模型建立之后,我们需要使用训练数据集来进行模型训练。训练的目的是找到最佳的模型参数,使模型在训练数据上的预测尽可能接近真实值。这个过程通常涉及到优化算法(如梯度下降)和损失函数,优化算法的任务是寻找能使损失函数值最小的参数。
以我们上一部分建立的神经网络为例,以下是如何进行模型训练的示例:
import torch.optim as optim
# 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失函数
optimizer = optim.SGD(net.parameters(), lr=0.01) # 随机梯度下降优化器
# 假设我们有一些输入数据x和对应的真实值y(在实际应用中,x和y通常来自于训练数据集)
x = torch.randn(10, 16)
y = torch.randn(10, 1)
# 模型训练
for epoch in range(100): # 训练100个epoch
optimizer.zero_grad() # 梯度清零
outputs = net(x) # 前向传播
loss = criterion(outputs, y) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
在模型训练完成之后,我们需要使用测试数据集来测试模型的性能。这是为了评估模型对未见过的数据的泛化能力。测试过程通常是这样的:我们将测试数据输入模型,得到模型的预测结果,然后将预测结果与真实结果进行比较,计算出某种性能指标(例如准确率、精度、召回率、F1值、AUC值等)。
以上就是模型的训练和测试过程。记住,虽然训练可能会让模型在训练数据上表现得很好,但最终我们关心的是模型在未见过的数据上的表现,所以我们应该尽可能优化模型在测试数据集上的性能。
6. 解读模型结果
解读模型的预测结果并不总是一个简单的任务,这需要对模型的工作原理、性能指标以及预测的具体场景有深入的理解。具体来说,解读模型结果需要关注以下几个方面:
-
性能指标:根据模型预测的任务(例如分类、回归、聚类等),我们可能会关注不同的性能指标。例如在分类问题中,我们可能关注准确率、精度、召回率、F1值等;在回归问题中,我们可能关注均方误差、均方根误差、R-squared等。
-
预测误差:模型在测试数据集上的预测结果与真实值之间的差距(即预测误差)可以帮助我们了解模型的泛化能力。如果预测误差过大,我们可能需要调整模型的参数或者更换更复杂的模型。
-
模型解释性:某些模型(如决策树和线性回归)可以提供预测的解释,这可以帮助我们理解模型是如何进行预测的。而对于那些”黑箱”模型(如神经网络),我们可能需要借助于一些模型解释工具(如LIME和SHAP)来解读预测结果。
一旦我们解读了模型的预测结果,我们就可以根据这些信息来改进模型。具体来说,可能包括以下几个方面:
-
数据预处理:**如果我们发现模型在某些特殊的数据上预测效果较差,我们可能需要重新考虑数据预处理阶段的策略,例如是否需要更复杂的数据清洗,或者是否需要引入新的特征。
-
模型选择和调整:**如果我们发现模型的性能未达到预期,我们可能需要尝试其他的模型,或者调整模型的参数。
-
训练策略:**我们也可以调整模型的训练策略,例如更改优化器、损失函数或者学习率等。
在这个过程中,我们需要时刻保持对模型的理解,并结合具体的业务背景和数据情况来进行决策。这就是解读和改进模型的艺术。
7. 结语
通过这篇文章,我们一起学习了使用Python进行人工智能编程的全过程,从数据预处理,到模型建立,再到模型训练和测试,最后我们还学习了如何解读模型结果并据此改进模型。每一步都是为了更好地理解数据,更好地建立和优化模型,以使模型能在解决实际问题中发挥最大的价值。
Python在人工智能开发中的地位无可替代,其丰富的库和友好的语法使得编程变得更加简单和高效。学习和应用Python进行人工智能编程,不仅可以让我们更好地理解人工智能的原理和工作机制,也能让我们在解决实际问题时有更多的工具和方法可供选择。
然而,需要强调的是,编程和算法只是工具,真正的价值在于如何应用这些工具解决实际问题。这需要我们结合具体的业务背景和数据情况,进行恰当的模型选择和参数调整,以及准确的结果解读。
总的来说,学习和应用Python进行人工智能编程,可以提升我们的问题解决能力和创新能力,为我们开拓一个新的世界,带来无限可能。希望这篇文章能为你的学习之路提供一些帮助,也期待看到更多使用Python和人工智能解决问题的实例。
让我们一起探索这个由数据驱动的世界,让人工智能在我们的手中释放出它的最大潜力!!!
文章出处登录后可见!