目录
目录
1. NVIDIA TF32
TensorFloat-32,是NVIDIA在Ampere架构的GPU上推出的专门运用于TensorCore的一种计算格式。
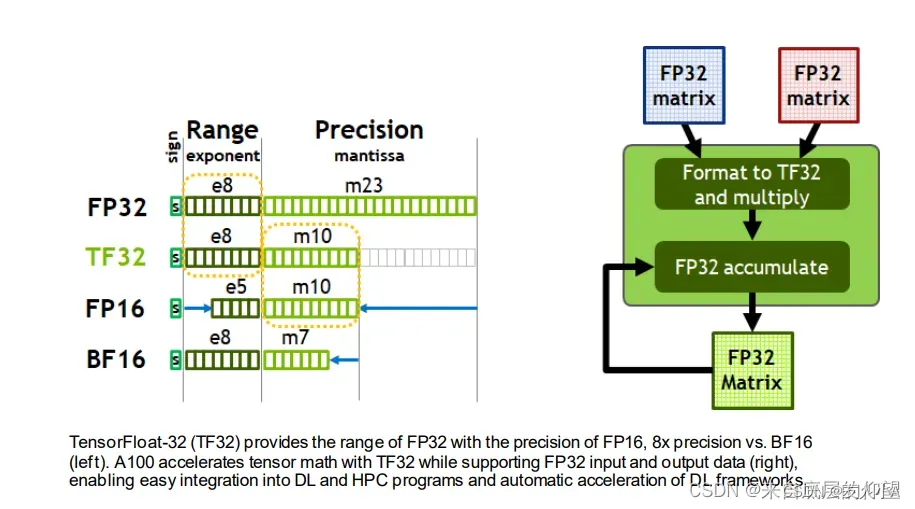
1.1 数据格式比较
TF32仅仅是在使用TensorCore时的一种中间计算格式,它并不是一个完全的数据类型
1.2 使用方法及条件
1.2.1 前置条件
- 矩阵乘法及卷积相关运算,且输入数据类型位FP32,才可以使用TF32作为TensorCore的中间计算类型
- Ampere架构的GPU
| NVIDIA GPU架构 | 路线 | 说明 |
| Fermi 费米 | 图形处理(游戏市场)/计算方向(AI领域) | |
| Kepler 开普勒 | 图形处理(游戏市场)/计算方向(AI领域) | |
| Maxwell 麦克斯韦 | 图形处理(游戏市场)/计算方向(AI领域) | |
| Pascal 帕斯卡 | 图形处理(游戏市场)/计算方向(AI领域) | |
| Volta 沃特 | 计算方向(AI领域) | 第一个专门面向计算方向的GPU架构, 首次使用Tensor Cores |
| Truing 图灵 | 侧重图形处理(游戏市场) | 该架构带来了全新的RTX系列品牌,并衍生出很多消费级GPU图形卡 |
| Ampere 安培 | 计算方向(AI领域/大数据分析/科学计算) | 第三代Tensor Cores,多实例GPU(MIG),第三代NVLink互联技术,细粒度结构稀疏性等新技术的特性组合,使Ampere架构GPU在计算方向统一了大数据分析、科学计算、深度学习训练和推理等主流计算场景。 |
ps: GPU架构最初被用于图像数据处理,随后被发现具有离散化和分布式特征,可以在矩阵运算时替代布尔运算,十分适合处理深度学习所需要的非线性离散数据,尤其在进行深度学习算法训练时非常高效。
1.2.2 调用方式
通常情况下使用TF32,都是由cuBLAS,cuDNN等NVIDIA的计算库来在内部进行调用的。
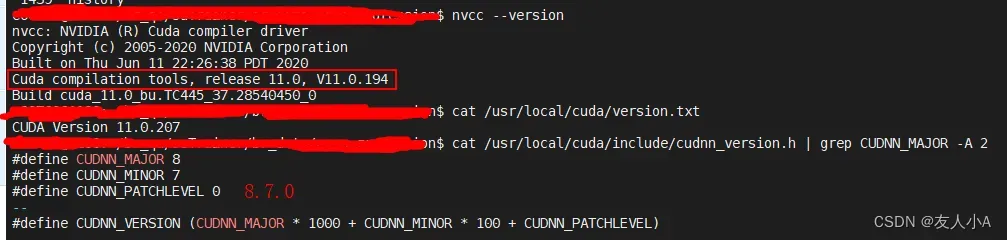
因此无论上层的深度学习框架使用的是什么,必须保证cuBLAS>=11.0,cuDNN>=8.0。
如何查询版本号?
1.3 NVIDIA TF32开关
在Ampere架构的GPU上,默认启用了TF32来进行计算加速,但是并不是每一个矩阵及卷积计算都一定会使用FP32。如果想强制关闭TF32,可以通过设置环境变量:
export NVIDIA_TF32_OVERRIDE=0
2. Pytorch
2.1 Pytorch对NVIDIA TF32的支持
Pytorch 1.7中添加了对TensorFloat32运算的支持,allow_tf32 标志在PyTroch1.7到PyTroch1.11中默认为True,在PyTorch1.12及更高版本中默认为False。
此标志控制PyTorch是否允许使用TensorFloat32 TensorCore。
# The flag below controls whether to allow TF32 on matmul. This flag defaults to False# in PyTorch 1.12 and later.
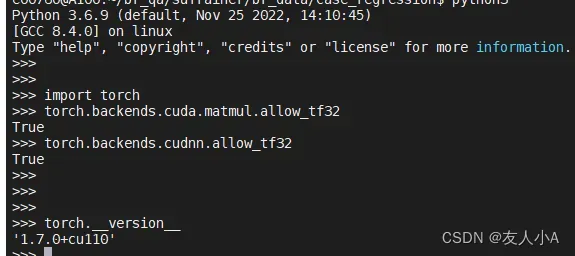
torch.backends.cuda.matmul.allow_tf32=True
# The flag below controls whether to allow TF32 on cuDNN. This flag defaults to True.
torch.backends.cudnn.allow_tf32=True查询开关的默认值
2.2 Pytorch自动混合精度AMP
PyTorch自1.6版本开始增加内置 torch.cuda.amp, 采用Float32和Float16的自动混合运算,注意与TF32计算模式是不同的。
参考
NVIDIA TF32 — DeepRec latest 文档![]() https://deeprec.readthedocs.io/zh/latest/NVIDIA-TF32.html
https://deeprec.readthedocs.io/zh/latest/NVIDIA-TF32.html
CUDA semantics — PyTorch 1.13 documentation![]() https://pytorch.org/docs/stable/notes/cuda.html
https://pytorch.org/docs/stable/notes/cuda.html
https://arxiv.org/pdf/1710.03740.pdf![]() https://arxiv.org/pdf/1710.03740.pdf
https://arxiv.org/pdf/1710.03740.pdf
TF32和AMP训练为何可以保证训练精度收敛_来自底层的仰望的博客-CSDN博客目标自NV的Ampere架构后,越来越多的AI研究者使用TF32或者AMP(混合精度)进行网络训练。在网络训练精度的同时,也极大的提升了训练速度。(其中更多的应用者选择TF32)相对于原先深度学习领域使用FLOAT32进行训练,明明训练中降低了数据表示精度,为什么还能取得满意的训练和推理结果呢?本文主要基于这个基本问题展开讨论。下面先简单看一下A100支持的浮点运算单元和其对应算力。基本数据类型介绍:各数据类型算力介绍:问题解答如果想要解答上面这个问题,最主要还是要探https://blog.csdn.net/weixin_43969854/article/details/124185741
环境:pytorch-gpu源码编译_迷途小书童的Note的博客-CSDN博客
文章出处登录后可见!