SG(Scene Graph, 场景图)能够很好地帮助人们对视频场景的理解,SGG(Scene Graph Generation )这一研究方向让我有必要去对这一领域进行全面的了解,先写一部分,后面补全,挑重要的翻译了下,仅用作个人学习记录。
参考论文:
2104.01111.pdf (arxiv.org)![]() https://arxiv.org/pdf/2104.01111.pdf
https://arxiv.org/pdf/2104.01111.pdf
摘要
场景图是对场景的结构化表示,可以清晰地表达场景中的对象、属性和对象之间的关系。随着计算机视觉技术的不断发展,人们不再满足于简单地检测和识别图像中的物体;相反,人们期待对视觉场景有更高层次的理解和推理。例如,给定一张图像,我们不仅要检测和识别图像中的物体,还要了解物体之间的关系(视觉关系检测),并根据图像内容生成文本描述(图像字幕)。或者,我们可能希望机器告诉我们图像中的小女孩在做什么(视觉问答(VQA)),甚至从图像中删除狗并找到类似的图像(图像编辑和检索),等等。这些任务需要对图像视觉任务有更高水平的理解和推理能力。场景图就是一个非常强大的场景理解工具。因此,场景图引起了大量研究者的关注,相关研究往往是跨模态的、复杂的、发展迅速的。本文总结了场景图的一般定义,然后对场景图(SGG)的生成方法以及借助先验知识的SGG进行了全面系统的讨论并总结了最常用的数据集。
1 Introduction
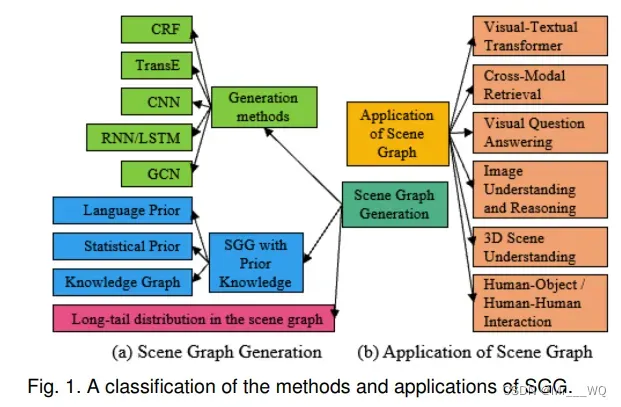
目前,与场景图生成(SGG)相关的工作呈爆炸式增长,但缺乏对SGG的全面、系统的调查。为了填补这一空白,这篇论文(下称论文)主要回顾了SGG的方法和应用。下图显示了论文调查的主要结构。此外,在第6节中,论文总结了场景图中常用的数据集和评估方法,并比较了模型的性能。在第7节中,论文讨论了SGG的未来发展方向并在第8节中作总结。
1.1 Definition
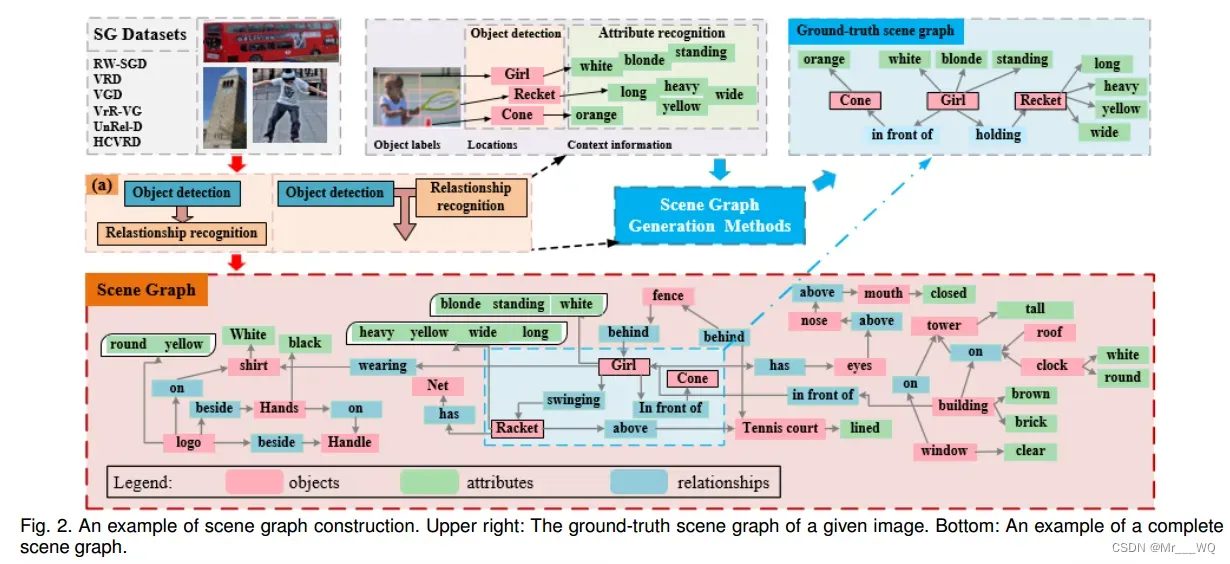
下图总结了构建场景图的总体流程。如图2(下)所示,场景图中的对象实例可以是一个人(女孩)、一个地方(网球场)、一件东西(衬衫)或其他物体的一部分(手臂)。属性用于描述当前对象的状态;这些可能包括球拍的形状(球拍是一条长条)、颜色(女孩的衣服是白色的)和姿势(女孩站着)。关系被用来描述物体对之间的联系,如动作(例如,女孩挥动球拍)和位置(放在女孩前面的锥体)。这种关系通常表示为三元组,可缩写为
。
形式上,场景图SG是一个有向图数据结构。用元组
的形式定义
是图像中检测到的物体的集合,n是物体的数量。每个对象可以记为
,其中
和
分别表示对象的类别和属性
- R表示节点之间的一组关系,其中第i个对象实例和第j个对象实例之间的关系可以表示为
表示对象实例节点和关系节点之间的边,因此初始图中最多有n × n条边。那么,当
被归类为背景或
被归类为不相关时,
被自动移除。也就是说,给定一个图像
作为输入,SGG方法输出一个场景图SG,其中包含被包围框定位在图像中的对象实例以及每个对象对实例之间的关系
- 可以表示为:
1.2 Construction Process
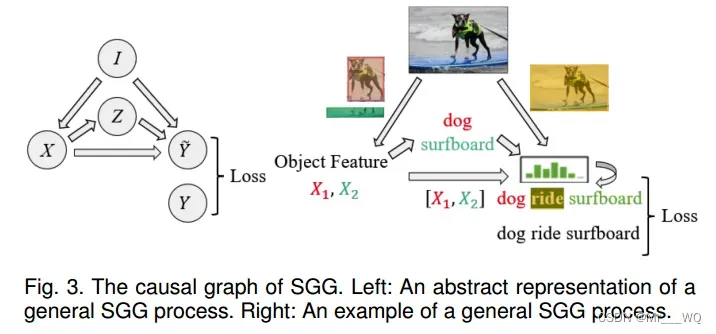
参考《Unbiased scene graph generation from biased training》中的表达式,一个通用的SGG过程如图3所示。图3(左)是这个SGG过程的抽象表示,图3(右)是一个具体的例子。具体来说,节点表示给定的图像,节点
表示对象的特征,节点
表示对象的类别。节点
表示预测谓词的类别和对应的三元组
,它使用融合函数接收来自三个分支的输出,以生成最终的分数。节点
表示真正的三元组标签。对应的环节说明如下:
(Object Feature Extraction)
预训练的Faster R-CNN 常用于提取一组包围框
和对应的特征映射
的输入图像
通过这个过程,每个对象的视觉上下文都被编码了。
(Object Classification)
这个过程可以简单地表示为:
(Object Class Input for SGG)
使用配对的对象标签
,通过组合嵌入层
预测对象对之间的谓词
。这个过程可以表示为:
此处利用了一些先验知识,先验知识的计算可参见原文参考文献
(Object Feature Input for SGG)
配对对象特征的组合
作为输入,预测相应的谓词。这个过程可以表示为:
(Visual Context Input for SGG)
在该环节中提取联合区域
的视觉上下文特征
,并预测相应的三元组。这个过程可以表示为:
Training Loss
大多数模型是通过使用对象标签和谓词标签的传统交叉熵损失来训练的。此外,为了避免任何一个环节自发地主导logits
的生成,有关论文添加了辅助交叉熵损失,分别预测每个分支的损失。
更简洁地说,场景图的生成大致可以分为三个部分:特征提取、情境化、图的构建和推理。
- 特征提取:这个过程主要负责对图像中的对象或对象对进行编码。例如,
- 情景化:它起着关联不同实体的作用,主要用于增强实体之间的上下文信息。例如,
。
- 图的构建和推理:最后,利用这些上下文信息来预测谓词,完成图的构造和推理。例如,节点
另一方面,如图2 (a)所示,从SGG过程来看,目前场景图的生成可分为两种类型:
- 自底向上:第一种方法分为两个阶段,即目标检测和成对关系识别。用来识别被检测对象的类别和属性的第一个阶段通常使用Fast-RCNN实现,这种方法被称为自底向上方法。可以用以下形式表示:
P(B|I)、P(O|B, I)和P(R|B, O, I)分别代表边界框(B)、对象(O)和关系(R)预测模型。
- 自顶向下:另一种方法涉及联合检测和识别对象及其关系,这种方法称为自顶向下方法。对应的概率模型可以表示为:
式中P(O, R|B, I)表示基于对象区域建议的对象及其关系的联合推理模型。
在高层次上,推理任务和其他涉及的视觉任务包括识别对象、预测对象的坐标以及检测识别对象之间的成对关系谓词。因此,目前大多数工作都集中在视觉关系推理这一关键挑战上。
1.3 Challenge
但是值得注意的是,场景图的研究仍然面临着一些挑战。目前,场景图的研究主要集中在试图解决以下三个问题:
- SGG模型的构建。这里的关键问题是如何一步一步地建立一个场景图。不同的学习模型对挖掘视觉文本信息生成的场景图的准确性和完整性有着至关重要的影响。因此,对相关学习模型的研究对于SGG的研究至关重要。
- 先验知识的引入。除了充分挖掘当前训练集中的对象及其相互关系外,一些额外的先验知识对于场景图的构建也是至关重要的。另一个重要的问题是如何充分利用现有的先验知识。
- 视觉关系的长尾分布。谓词的长尾分布在视觉关系识别中是一个关键的挑战。这种长尾分布和模型训练所需的数据平衡构成了一对内在的矛盾,这将直接影响模型的性能。长尾分布问题可以参看Long-Tailed Classification (1) 长尾(不均衡)分布下的分类问题简介 – 知乎 (zhihu.com)
2 SCENE GRAPH GENERATION
场景图是场景的拓扑表示,其主要目标是对对象及其关系进行编码。此外,关键的挑战任务是检测/识别对象之间的关系。目前,SGG方法大致可分为基于CRF的SGG、基于TransE的SGG、基于CNN的SGG、基于RNN/ LSTM的SGG和基于GNN的SGG。在本节中,我们将详细回顾这些方法的每一类。
2.1 CRF-based SGG
在可视关系三元组中,关系谓词和对象对之间存在很强的统计相关性。有效地利用这些信息可以极大地帮助识别视觉关系。CRF(条件随机场)是一个经典的工具,能够将统计关系纳入区分任务。CRF已广泛应用于各种图推理任务,包括图像分割,命名实体识别和图像检索。在视觉关系的上下文中,CRF可以表示为:
其中表示对象对的外观特征和空间构型,
和
分别表示主体和对象的外观特征。一般来说,这些特征大多是ROI池化后的一维张量,大小为1 × N。N为张量的维数,其具体值可由网络参数控制。W为模型参数,Z为归一化常数,
为联合势。类似的CRF被广泛应用于计算机视觉任务,并已被证明在捕获视觉关系中的统计相关性方面有效。图 4 总结了基于CRF的SGG的基本结构,包括目标检测和关系预测两部分。目标检测模型用于获取主体和客体的区域视觉特征,而关系预测模型则利用主体和客体的视觉特征来预测它们之间的关系。其他改进的基于CRF的SGG模型通过采用更合适的目标检测模型和推理能力更强的关系预测模型,获得了更好的性能。如有关论文提出了深度关系网络(DR-Net)和语义兼容网络(SCN)。
 受深度神经网络和CRF模型成功的启发,为了在视觉关系的背景下探索统计关系,DR-Net[选择将统计关系建模纳入深度神经网络框架。DR-Net将关系建模的推理展开为前馈网络。此外,DR-Net不同于以往的CRF。更具体地说,DRNet中的统计推理过程通过迭代展开嵌入到深度关系网络中。改进后的DRNet的性能不仅优于基于分类的方法,而且优于基于深度势的CRF。进一步,SG-CRF (SGG via Conditional Random Fields)可以定义为通过寻找
受深度神经网络和CRF模型成功的启发,为了在视觉关系的背景下探索统计关系,DR-Net[选择将统计关系建模纳入深度神经网络框架。DR-Net将关系建模的推理展开为前馈网络。此外,DR-Net不同于以往的CRF。更具体地说,DRNet中的统计推理过程通过迭代展开嵌入到深度关系网络中。改进后的DRNet的性能不仅优于基于分类的方法,而且优于基于深度势的CRF。进一步,SG-CRF (SGG via Conditional Random Fields)可以定义为通过寻找的最佳预测来最大化以下概率函数:
其中表示第 i 个对象实例的包围框坐标。以往的一些方法往往忽略了实例和关系之间的语义兼容性(即给定节点的所有1跳邻居节点的可能性分布),这导致模型在面对真实数据时性能显著下降。例如,这可能会导致模型错误地将
识别为
。
此外,这些模型忽略了两者的顺序,导致主体和客体之间的混淆,从而可能产生荒谬的预测,例如。为了解决这些问题,SG-CRF提出了一种通过条件随机场构造的端到端场景图来提高SGG的质量。更具体地说,为了学习场景图中节点的语义兼容性,SG-CRF提出了一种新的基于条件随机场的语义兼容性网络。为了区分关系中的主体和客体,SG-CRF提出了一种有效的关系序列层,可以捕获视觉关系中的主体和客体序列。
通常,基于CRF的SGG可以有效地模拟视觉关系中的统计相关性。这种统计相关的信息建模仍然是视觉关系识别任务中的经典工具。
2.2 TransE-based SGG
知识图类似于场景图;它还具有大量的事实三元组,这些多关系数据以的形式表示(缩写为(
)。其中,
分别为头部实体和尾部实体,
为两个实体之间的关系标签。这些实体是场景图中的对象,所以我们用O来表示实体的集合,以避免与E(对象之间的边)混淆。
知识图表示将三元组嵌入到低维向量空间的学习,基于TransE(翻译嵌入)的模型已被证明特别有效。此外,TransE将这种关系视为头实体和尾实体之间的转换。该模型需要学习实体和关系的向量嵌入。也就是说,对于元组,
(
应该是
的最近邻居;否则,它们应该远离彼此)。这种嵌入学习可以通过最小化以下基于边际的损失函数来实现:
其中S代表训练集,d用于测量两个嵌入之间的距离,是一个边缘超参数,
是一个正元组,
是一个负元组,以及
场景图中的关系元组也有相似的定义和属性,这意味着学习这种可视化的关系嵌入对场景图也有很大的帮助。
受TransE在知识库关系表示学习方面的进步的启发,VTransE(基于TransE)探索了如何通过在低维空间中映射对象和谓词的特征来建模视觉关系,是第一个基于TransE的SGG方法,它通过扩展TransE网络来工作。随后,如图6所示,引入注意机制和视觉语境信息,分别设计了MATransE (Multimodal Attentional Translation Embeddings)和UVTransE (Union visual Translation Embedding)。在RLSV (Representation Learning via Jointly Structural and Visual Embedding)和AT(Analogies Transfer)中分别使用TransD和类比变换代替TransE进行视觉关系预测。
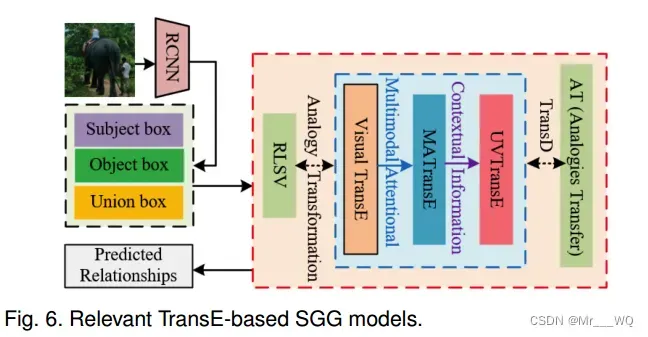
更具体地说,VTransE将实体和谓词映射到低维嵌入向量空间,其中谓词被解释为主题的嵌入特征和对象的边界框区域之间的转换向量。类似于知识图的元组,场景图中的关系被建模为一个简单的向量变换,即,可以看作是基于TransE的SGG方法的一个基本向量变换。虽然这是一个很好的开始,但VTransE只考虑主语和宾语的特征,而不考虑谓词和上下文信息的特征,尽管这些已被证明对识别关系有用。为此,基于VTransE的MATransE方法,结合语言和视觉的互补性,结合注意机制和深度监督,提出了一种多模态注意力翻译嵌入方法。MATransE尝试学习投影矩阵Ws, Wp和Wo,用于
到分数空间的投影,并在注意力模块中使用二进制掩码的卷积特征m。则
为:
MATransE设计了两个独立的分支来直接处理谓词的特征和主客体的特征,取得了很好的效果。
除了极大地改变谓词的视觉外观外,训练集中谓词表示的稀疏性和非常大的谓词特征空间也使得视觉关系检测的任务越来越困难。让我们以斯坦福VRD数据集为例,这个数据集包含100类对象,70类谓词,总共30k个训练关系注释。可能的三元组的数量是1002∗70 = 700k,这意味着大量可能的真实关系甚至没有训练示例。这些看不见的关系不应该被忽视,即使它们不包括在训练集中。图 5 给出了这种情况的示例。然而,VTransE和MATransE并不适合处理这个问题。因此,检测场景中看不见的/新的关系对于构建完整的场景图至关重要。
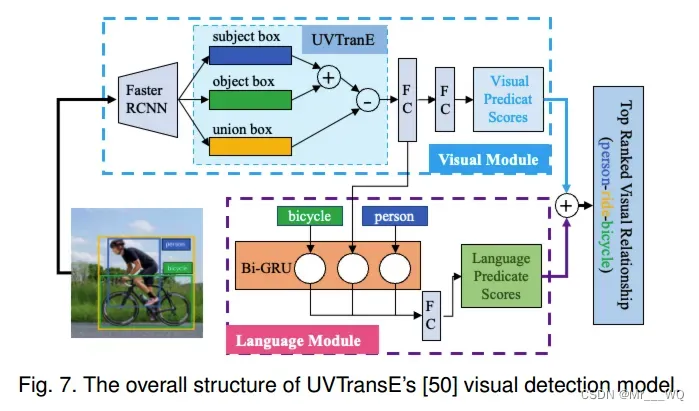
受VTransE的启发,UVTransE的目标是提高罕见或不可见关系的泛化。在VTransE的基础上,UVTransE引入了主客体的联合包围盒或并集特征u,以便更好地捕获上下文信息,并在约束的指导下学习谓词的嵌入。UVTransE引入了主客体的并集,并使用上下文增强翻译嵌入模型来捕获场景中常见和罕见的关系。这种类型的探索对于构建相对完整的场景图非常有益。最后,UVTransE结合视觉、语言和物体检测模块的得分,对三重关系的预测进行排序。UVTRansE的架构细节如图 7 所示。UVTransE将谓词嵌入处理为
。而VTransE通过在低维空间中映射对象和谓词的特征来建模可视化关系,其中关系三元组可以解释为向量平移:
。
基于知识图相关研究的深刻见解,基于TransE的SGG方法得到了迅速发展,引起了研究者的浓厚兴趣。相关研究结果也证明了该方法的有效性。特别是基于transe的SGG方法对于挖掘不可见的视觉关系非常有帮助,这将直接影响场景图的完整性。因此,相关研究仍然很有价值。
2.3 CNN-based SGG (以下部分后续更新,重点关注2.4 2.5)
基于CNN的SGG方法尝试使用卷积神经网络(CNN)提取图像的局部和全局视觉特征,然后通过分类预测主题和对象之间的关系。从大多数基于CNN的SGG方法可以看出,这类SGG方法主要包括三个部分:区域提出、特征学习和关系分类。在这些部分中,特征学习是其中的关键部分,我们可以用下面的公式分别表示主语、谓语和宾语的第 层的特征学习:
其中 * 是,⊗是矩阵向量乘积,
和
是FC或Conv层的参数。随后的基于CNN的SGG方法致力于设计新的模块来学习最优特征
。基于CNN的主流SGG方法如图8所示。通过联合考虑LinkNet中多个对象的局部视觉特征,或在BAR-CNN (Box Attention Relational CNN)中引入盒注意力机制,得到最终用于关系识别的特征。为了提高SGG模型的效率,Rel-PN和IM-SGG (Interpretable Model for SGG)旨在选择最有效的ROI进行可视化关系预测。ViP-CNN (Visual Phrase-guided Convolutional Neural Network, Visual Phrase-guided Convolutional Neural Network)和Zoom-Net更关注局部特征之间的交互。由于CNN在提取图像视觉特征方面表现良好,基于CNN的相关SGG方法得到了广泛的研究。在本部分中,我们将详细介绍这些基于cnn的SGG方法。
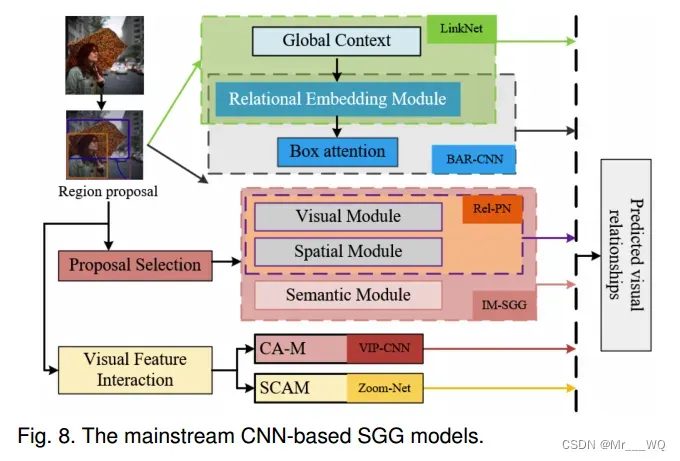
通过分析图像数据集中多个对象之间的关系,生成场景图。因此,有必要尽可能地考虑相关对象之间的联系,而不是孤立地关注单个对象。LinkNet通过显式地建模所有相关对象之间的相互依赖关系来改进SGG。更具体地说,LinkNet设计了一个简单有效的关系嵌入模块,共同学习所有相关对象之间的连接。此外,LinkNet还引入了全局上下文编码模块和几何布局编码模块,从整个图像中提取全局上下文信息和对象建议之间的空间信息,从而进一步提高了算法的性能。具体的LinkNet分为三个主要步骤:边界框提出、对象分类和关系分类。但是,LinkNet考虑所有对象的关系提议,这使得它的计算成本很高。
另一方面,随着深度学习技术的发展,相应的目标检测研究也日趋成熟。相比之下,识别不同实体之间的关联以实现更高层次的视觉任务理解已成为一个新的挑战;这也是场景图构建的关键。如2.2节所分析的,为了检测所有的关系,首先检测所有的单个对象,然后再对所有的关系对进行分类是低效和不必要的,因为二次关系中存在的可视关系非常稀疏。因此,使用视觉短语来表达这种视觉关系可能是一个很好的解决方案。Rel-PN在这方面进行了相应的研究。与区域提议网络(Region Proposal Networks, RPN)提供的对象的区域提议类似,Rel-PN利用提议选择模块选择有意义的主题-对象对用于后续关系预测。该操作将大大降低SGG的计算复杂度。Rel-PN的模型结构如图9(a)所示:
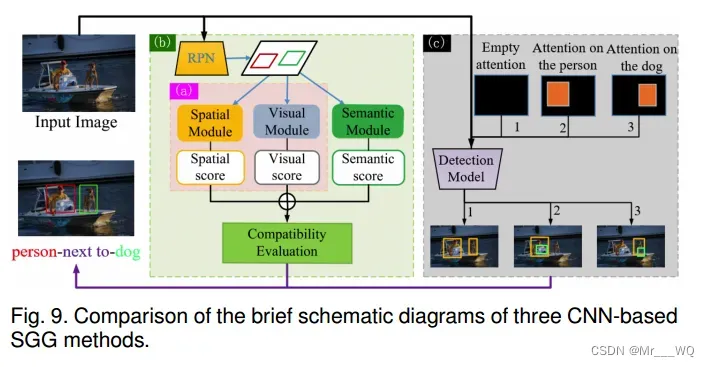
Rel-PN的兼容性评估模块使用两种类型的模块:视觉兼容性模块和空间兼容性模块。视觉兼容模块主要用于分析两个盒子外观的一致性,而空间兼容模块主要用于探索两个盒子的位置和形状。此外,基于RelPN的IM-SGG考虑了视觉、空间和语义三种类型的特征,分别由三种相应的模型提取。随后,类似于Rel-PN,将这三种类型的特征融合在一起,进行最终的关系识别。与Rel-PN不同,IM-SGG利用一个额外的语义模块来捕获谓词的强先验知识,从而获得更好的性能(如图9 (b))。该方法有效地提高了SGG的可解释性。更直接地说,ViP-CNN使用了与Rel-PN类似的方法,也明确地将视觉关系视为包含三个组成部分的视觉短语。ViP-CNN尝试共同学习具体的视觉特征进行交互,以方便考虑视觉依赖性。在ViP-CNN中,提出了短语引导消息传递结构(PMPS, Phrase-guided Message Passing Structure),使用集合广播消息传递流机制对局部视觉特征之间的相互依赖信息进行建模,ViPCNN在速度和准确性上取得了显著的提高。
此外,为了进一步提高SGG的精度,一些方法还研究了不同特征之间的相互作用,目的是更准确地预测不同实体之间的视觉关系。这是因为对单个物体的独立检测和识别在从根本上识别视觉关系方面提供的帮助很少。图10给出了一个例子,在这个例子中,即使是最完美的物体检测器也很难区分站在马旁边的人和喂马的人。因此,不同物体之间的信息交互对于理解视觉关系极为重要。关于这一主题已经发表了许多相关的著作。例如,在Zoom-Net中,检测到的对象对之间的相互作用用于视觉关系识别。Zoom-Net通过使用深度消息传播和局部对象特征与全局谓词特征之间的交互成功地识别复杂的视觉关系,而不使用任何语言先验,从而实现了令人信服的性能。VIP-CNN也使用了类似的功能交互。

关键区别在于,VIP-CNN提出的CA-M (context – appearance Module)试图直接融合成对特征来捕获上下文信息,而Zoom-Net[23]提出的SCA-M (Spatiality-Context-Appearance Module)则执行空间感知的通道级本地和全局上下文信息融合。因此,SCA-M在捕获主语、谓语和宾语特征之间的空间关系和上下文关系时更有优势。图11给出了不进行信息交互的外观模块(A-M)、上下文-外观模块(CA-M)和空间-上下文-外观模块(SCA-M)的结构对比图。
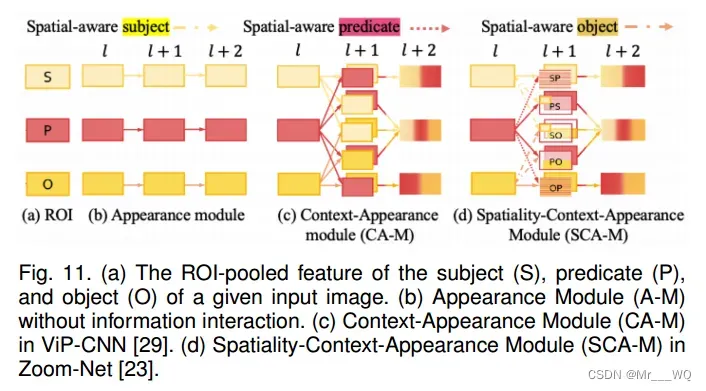
注意机制也是改善视觉关系检测的好工具。BAR-CNN观察到,在最先进的特征提取器中,神经元的接受野可能仍然有限,这意味着该模型可能覆盖整个注意图。为此,BAR-CNN提出了盒子注意机制;这使得视觉关系检测任务可以使用现有的对象检测模型来完成相应的关系识别任务,而无需引入额外的复杂组件。这是一个非常有趣的概念,BAR-CNN也获得了具有竞争力的识别性能。BAR-CNN的示意图如图9(c)所示。
相关的基于cnn的SGG方法已被广泛研究。然而,仍有许多挑战需要进一步研究,包括如何在尽可能降低计算复杂度的同时保证三元组不同特征之间的深度交互,如何处理现实中真实但非常稀疏的视觉关系等。确定这些问题的解决方案将进一步深化基于CNN的SGG方法的相关研究。
2.4 RNN/LSTM-based SGG
场景图是图像的结构化表示。不同物体之间的信息交互以及这些物体的上下文信息对于识别它们之间的视觉关系至关重要。基于RNN和LSTM的模型在获取场景图中的上下文信息和对图结构中的结构化信息进行推理方面具有天然的优势。因此,基于RNN/ LSTM的方法也是一个热门的研究方向。如图12所示,基于标准RNN/LSTM网络,提出了几种改进的SGG模型。例如,IMP (Iterative Message Passing)和MotifNet (Stacked Motif Network)分别考虑了局部上下文信息和全局上下文信息的特征交互。类似地,在PANet (predicate association network)中SGG使用实例级和场景级上下文信息,在SIG (Sketching Image Gist)中SGG也引入了基于注意的RNN。这些基于RNN/LSTM的SGG方法的相应概率解释可以简化为Eq.(7)的条件形式,而这些方法主要利用标准/改进的RNN/LSTM网络,通过优化P(R|B, O, I)来推断关系。
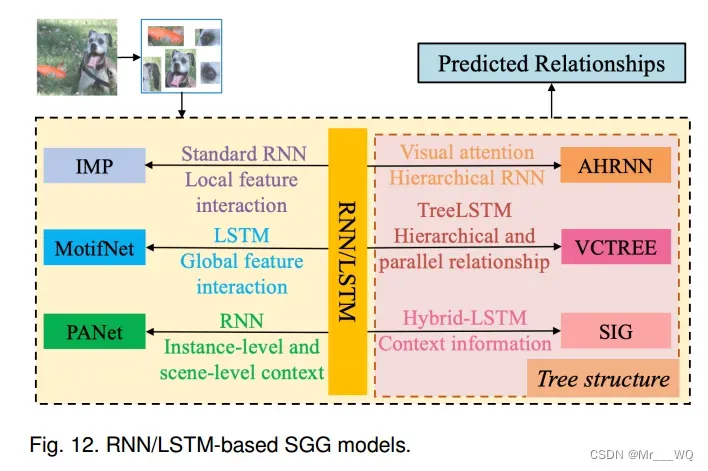
后来,基于RNN/LSTM的模型尝试通过设计结构性RNN/LSTM模块来学习不同类型的上下文信息;例如AHRNN(基于注意的分层RNN) , VCTree(可视化上下文树模型)。这类SGG方法将场景图视为一个层次结构的图形结构,因此需要在区域建议的基础上构造一个层次实体树。然后可以对层次结构上下文信息进行编码:
其中 是构造的层次实体树中输入节点的特征。最后,采用多层感知器(MLP)分类器对谓词p进行预测。
如上所述,为了充分利用图像中的上下文信息来提高SGG的精度,提出了IMP。IMP尝试使用标准RNN解决场景图推理问题,并通过消息传递迭代提高模型的预测性能。该方法的主要亮点在于其新颖的原对偶图,实现了节点信息和边缘信息的双向流动,并迭代更新节点和边缘的两个GRU。这种形式的信息交互有助于模型更准确地识别对象之间的视觉关系。与IMP等局部信息相互作用的情况不同,MotifNet始于局部预测中的强独立性假设限制了全局预测的质量。为此,MotifNet通过循环顺序架构LSTMs (Long – Short-term Memory Networks)对全局上下文信息进行编码。而MotifNet只考虑了对象之间的上下文信息,而没有考虑场景信息。也有一些工作通过交换节点和边之间的上下文来研究关系的分类。然而,上述的SGG方法主要关注场景中的结构语义特征,而忽略了不同谓词之间的相关性。为此,提出了两阶段谓词关联网络(PANet)。第一个阶段的主要目标是提取实例级和场景级上下文信息,而第二个阶段主要用于捕获谓词对齐特征之间的关联。特别地,使用RNN模块来完全捕获对齐特征之间的关联。这种谓词关联分析也取得了很好的效果。
然而,上面讨论的方法通常依赖于对象检测和对象之间的谓词分类。这种方法有两个固有的局限性:首先,通过物体检测方法生成的物体包围框或关系对并不总是生成场景图所必需的;第二,SGG依赖于输出关系的概率排序,这将导致语义冗余关系。为此,AHRNN提出了一种基于视觉注意机制的分层递归神经网络。该方法首先使用视觉注意机制,来解决第一个限制。其次,AHRNN将关系三元组的识别视为使用循环神经网络(RNN)的序列学习问题。特别是,它采用分层RNN对关系三元组建模,更有效地处理长期上下文信息和序列信息,从而避免了对输出关系的概率进行排序。
另一方面,VCTree观察到,前面的场景图要么采用链图,要么采用全连通图。但VCTree提出,这两种先验结构可能不是最优的,因为链结构过于简单,可能只捕获简单的空间信息或共现偏差;此外,全连通图缺乏层次关系和并行关系的区分结构。为了解决这一问题,VCTree提出了复合动态树结构,该结构可以使用TreeLSTM[84]进行高效的上下文编码,从而在可视化关系中有效地表示层次关系和并行关系。这种树结构为场景图表示提供了一个新的研究方向。图13给出了场景图的链式结构、全连通图结构、子图和动态树结构的对比图。
SIG也提出了类似树形结构的场景图;关键的区别来自于观察到,人类在分析场景时倾向于先描述图像中的主体和关键关系,这意味着具有主要和次要顺序的层次分析更符合人类的习惯。为此,SIG提出了一种仿人分层SGG方法。在该方法中,场景由一系列图像区域组成的仿人HET (Hierarchical Entity Tree)来表示,混合长短期记忆(Hybrid Long – ShortTerm Memory)对HET进行解析,从而获得HET中的层次结构和兄弟上下文信息。
2.5 GNN-based SGG
场景图可以看作是一个图结构。因此,一种直观的方法是借助图论来改进场景图的生成。GCN (Graph Convolutional Network)就是这样一种方法。这种方法被设计用来处理图结构数据,局部信息,可以有效地学习相邻节点之间的信息。GCN已被证明在关系推理、图分类、大型图中的节点分类和视觉理解等任务中非常有效。因此,许多研究者直接研究了基于GCN的SGG方法。类似于基于RNN/ lstm的SGG方法的条件形式(Eq.(7)),按照本文中相关变量的表达式形式,基于GCN的SGG过程也可以分解为三个部分:
其中V是节点的集合(图像中的对象),E是图中的边(对象之间的关系)。在此基础上,提出了后续改进的基于GNN的SGG方法。这些方法大多试图通过设计相关模块来优化P(E|V, I)和P(R, O|V, E, I)的项,并针对图标记过程P(R, O|V, E, I)设计了基于gcn的网络。图14给出了一些经典的基于GNN的SGG模型。F-Net (Factorizable Net)通过分解和合并图完成最终的SGG,然后引入注意机制,为SGG设计不同类型的GNN模块,如图R-CNN、GPI和ARN (attention Relational Network)。少镜头训练和多智能体训练分别应用于少镜头SGP[101]和CMAT (Counterfactual critic MultiAgent Training)。针对DG-PGNN设计了概率图网络(PGN),针对SGVST开发了多模态图convNet。此外,还为SGG提出了其他改进的基于gnn的网络模块,我们将详细描述。
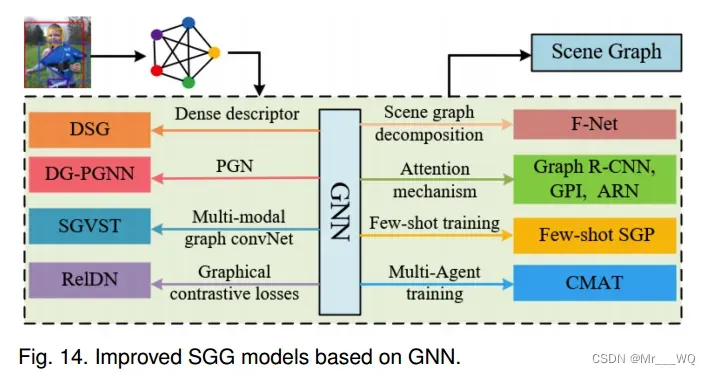
如1.2节所述,目前的SGG方法大致可分为两类:自底向上方法和自顶向下方法。然而,这些类型的框架构建的对象数量是二次的,这很耗时。为此,提出了一种高效的基于子图的SGG框架,称为可分解网(F-Net),以提高场景图的生成效率。使用这种方法,将检测到的对象区域建议配对,以方便构建完整的有向图。然后,将相似并集区域对应的边合并为子图,生成更精确的图;每个子图都有几个对象,它们之间的关系用边表示。可分解网通过将原场景图替换为这些子图,可以获得更高的场景图生成效率。此外,图R-CNN尝试修剪原始场景图(去除那些不太可能的关系),从而生成稀疏的候选图结构。最后,利用注意力图卷积网络(AGCN)对全局上下文信息进行整合,实现更高效、准确的SGG。
基于图的注意机制在场景图生成中也具有重要的研究价值。例如,之前的SGG工作通常需要先验的图结构知识。此外,这些方法往往会忽略整个图像的整体结构和信息,因为它们以循序渐进的方式捕获节点和边缘的表示。此外,对成对区域的视觉关系逐个检测也不太适合描述整个场景的结构。为此,在ARN中提出了语义转换模块,通过将标签嵌入和视觉特征转换到同一空间中产生语义嵌入,而关系推断模块用于预测实体类别和关系作为最终的场景图结果。特别是,为了便于描述整个场景的结构,ARN提出了一个基于图的自注意模型,旨在嵌入一个联合图表示来描述所有的关系。这个模块有助于生成更准确的场景图。另外,一种直觉是,在识别“人骑马”的图像时,人腿与马背之间的相互作用可以为识别谓词提供强有力的视觉证据。因此,RAAL-SGG (Toward Region-Aware Attention Learning For SGG)指出,它仅限于使用粗粒度的包围盒来研究SGG。因此,RAALSGG提出了一种区域感知注意力学习方法,该方法使用对象级注意力图神经网络进行更细粒度的对象区域推理。该模型的概率函数可以表示为:
其中是第n个对象的区域集。与式(7)不同的是,式(17)考虑的对象区域集F比粗粒度的包围框b更细粒度,这有助于模型借助对象交互区域对谓词进行推理。
在预测场景图的视觉关系时,使用RNN/LSTM编码的上下文中实体的读取顺序对SGG也有至关重要的影响。在这些情况下,固定的读取顺序可能不是最佳的。即使存在不同类型的输入,场景图生成器也应该揭示对象之间的联系和关系,以提高预测精度。形式上,给定相同的特征,即使输入被打乱,框架或函数F也应该得到相同的结果。在这种观察的激励下,用于SGG的神经网络架构理想情况下应该对特定类型的输入排列保持不变。Herzig等人据此证明了这一性质,基于这样的架构或框架可以以置换不变的方式从整体图中收集信息。基于这一特点,作者提出了几种常用的体系结构,并获得了具有竞争力的性能。
对于大多数SGG方法,关系的长尾分布仍然是关系特征学习的一个挑战。现有的方法通常无法处理不均匀分布的谓词。因此,Dornadula等尝试通过谓词的少镜头学习构建场景图,该场景图可以扩展到新的谓词。基于少镜头学习的SGG模型尝试在大量数据的关系上充分训练图卷积模型和空间和语义移位函数。对于他们来说,新的移位函数被微调为少数例子的新的、罕见的关系。与传统的SGG方法相比,该模型的新颖之处在于谓词被定义为函数,因此对象表示法对于少射谓词预测非常有用;其中包括将主题表示法转换为对象的前向函数和将对象表示法转换回主题的相应函数。该模型在稀有谓词的学习中取得了较好的效果。
一个全面、准确、连贯的场景图是我们期望达到的,同一节点在不同视觉关系中的语义也应该是一致的。然而,目前广泛使用的基于交叉熵的监督学习范式可能无法保证这种视觉上下文的一致性。
RelDN(关系检测网络)也发现单独应用交叉熵损失可能会对谓词分类产生不利影响;例如,实体实例混淆(同一类型的不同实例之间的混淆)和近端关系模糊(具有相同谓词的不同三元组中的主语-对象配对问题)。RelDN的提出就是为了解决这两个问题。在RelDN中,通过实体相加的方式将语义、视觉和空间关系建议的三种类型的特征组合在一起。然后应用这些特征通过softmax归一化得到谓词标签的分布。然后,专门构造图之间的对比损失来解决上述问题。
场景图为推理任务提供了一种自然的表示方式。不幸的是,由于它们的不可微表示,很难直接使用场景图作为视觉推理任务的中间组件。因此,采用DSG (Differentiable Scene-Graphs)来解决上述障碍。将目标的视觉特征作为输入输入到DSGs的可微场景图生成模块,该模块是一组新的节点特征和边缘特征。DSG架构的新颖之处在于它对场景图组件的分解,使得三元组中的每个元素都可以用密集描述符表示。因此,dsg可以直接用作下游推理任务的中间表示。
虽然我们已经研究了许多基于gnn的SGG方法,但仍然有许多其他相关的方法。例如,提出了一种深度生成概率图神经网络(DG-PGNN)来生成具有不确定性的场景图。SGVST引入了一种基于场景图的方法来从图像流生成故事语句。该方法使用GCN来捕获场景图中对象的局部细粒度区域表示。
综上所述,基于GNN的SGG方法因其明显的结构化信息捕获能力而受到了广泛的研究关注。如前所述,“谓词的识别是相互关联的,上下文信息在场景图的生成中起着至关重要的作用。”为此,研究人员越来越关注基于RNN/LSTM或图形的方法。这主要是因为RNN/LSTM具有更好的关系上下文建模能力。而场景图本身的图结构特性也使得基于GNN的SGG获得了相应的关注。此外,基于TransE的SGG由于其直观的建模方法,使得模型具有很强的可解释性,受到了研究人员的欢迎。由于CNN具有较强的视觉特征学习能力,未来基于CNN的SGG方法仍将是主流SGG方法。
3 SGG WITH PRIOR KNOWLEDGE
对于SGG来说,关系是对象的组合,其语义空间比对象的语义空间更宽。此外,从SGG训练数据中穷尽所有关系是非常困难的。因此,从少量的训练数据中有效地学习关系表示尤为关键。因此,先验知识的引入可以极大地帮助检测和识别视觉关系。因此,为了高效、准确地生成完整的场景图,先验知识(如语言先验、视觉先验、知识先验、上下文等)的引入也是至关重要的。在本节中,我们将在已有知识的基础上介绍SGG的相关工作。
3.1 SGG with Language Prior
语言先验通常利用语义词中嵌入的信息来微调关系预测的可能性,从而提高视觉关系预测的准确性。语言先验可以通过对语义相关对象的观察来帮助识别视觉关系。例如,马和大象可能被安排在语义相似的上下文中,例如,“一个骑着马的人”和“一个骑着大象的人”。因此,虽然在训练集中大象和人同时出现的情况并不常见,但通过引入语言先验,研究更常见的例子(如“一个人骑马”),我们仍然可以很容易地推断出人与大象之间可能是骑马的关系。这一思想如图15所示。这种方法也有助于解决视觉关系中的长尾效应。
许多研究者对语言先验的引入进行了详细的研究。例如,Lu等[建议同时训练一个视觉外观模块和一个语言模块,然后结合这两个分数来推断图像中的视觉关系。特别是,语言先验模块将类语义关系投射到更紧密的嵌入空间中。这有助于模型从“骑马的人”示例中推断出类似的视觉关系(“骑大象的人”)。同样,VRL(深度变异结构强化学习)和CDDN(上下文依赖扩散网络)也使用语言先验来改善视觉关系的预测;区别在于使用语义词嵌入来微调预测关系的可能性,而VRL采用变分结构遍历方案,遍历来自先前语言的有向语义动作图,这意味着后者可以提供比词嵌入更丰富、更紧凑的语义关联表示。此外,CDDN发现相似的物体具有密切的内部相关性,这可以用来推断新的视觉关系。为此,CDDN采用词嵌入获得语义图,同时构建空间场景图对全局上下文相互依赖性进行编码。CDDN通过将先验语义与视觉场景相结合,可以有效地学习视觉关系的潜在表征;此外,考虑到它对图的同构不变性,可以很好地满足视觉关系检测。
另一方面,尽管先验语言可以弥补模型复杂性和数据集复杂性之间的差异,但当语义词嵌入不足时,其有效性也会受到影响。为此,在IMP的基础上进一步引入了一个具有先验谓词分布的关系学习模块,以更好地学习视觉关系。更详细地说,将预先训练好的基于张量的关系模块添加到其中,作为微调关系估计之前的密集关系,而使用带有GRU的迭代消息传递方案作为GCN方法,以更好的特征表示来提高SGG性能。除了使用语言先验,还结合视觉线索来识别图像中的视觉关系和定位短语。就其本身而言,对实体的外观、大小、位置和属性以及由动词或介词连接的对象对之间的空间关系进行建模,并通过自动学习和组合这些线索的权重来共同推断视觉关系。
3.2 SGG with Statistical Prior
统计先验也是SGG广泛使用的一种先验知识形式,因为视觉场景中的物体通常具有很强的结构规律性。例如,人们倾向于穿鞋,而山脉周围往往有水。此外,是常见的,而
和
是非常不可能的。因此,这种关系可以用统计相关的先验知识来表示。建模对象对和关系之间的统计相关性可以帮助我们正确识别视觉关系。
由于关系分布的空间大和长尾性质,简单地使用训练集中包含的注释是不够的。此外,很难收集到足够数量的标记训练数据。因此,LKD(语言学知识蒸馏)不仅使用训练集中的注释,还使用互联网上公开的文本(维基百科)来收集外部语言知识。这主要是通过统计人类用于描述文本中对象对之间关系的词汇和表达式来实现的,然后计算给定一对的谓词的条件概率分布
。一个新颖的贡献是使用知识蒸馏从内部和外部语言数据中获取先验知识,以解决长尾关系问题。
类似地,DR-Net(深度关系网络)也注意到三元组之间的强统计相关性。不同之处在于DR-Net提出了一个深度关系网络来利用这种统计相关性。DR-Net首先提取出每对对象的局部区域和空间掩码,再将它们与单个对象的外观一起输入到深度关系网络中进行联合分析,从而得到最有可能的关系类别。此外,MotifNet在Visual Genome数据集上对关系和对象对的共现进行了统计分析,发现这些统计共现可以为关系预测提供较强的正则化。为此,MotifNet使用LSTM对对象和关系的全局上下文进行编码,从而使场景图能够被解析。然而,虽然上述方法也观察到了三重的统计共出现,但他们设计的深度模型通过消息传输隐式地挖掘了这种统计信息。KERN(知识嵌入式路由网络)也注意到了这种统计上的共存。不同之处在于,KERN以结构图的形式正式表达了这种统计知识,该结构图被纳入深度传播网络作为额外的指导。这样可以有效地正则化可能关系的分布,从而减少预测的模糊性。
此外,类似的统计先验也用于复杂的室内场景分析。统计先验可以有效地提高相应场景分析任务的性能。
3.3 SGG with Knowledge Graph
知识图是一个丰富的知识库,它编码了世界是如何构建的。将常识知识图作为先验知识,有效地帮助场景图的生成。
为此,GB-Net(图桥网络)提出了一种新的视角,将场景图和知识图构建为统一的框架。更具体地说,GB-Net将场景图视为常识知识图的图像条件化实例化。基于这一视角,场景图的生成被重新定义为场景图和常识图之间的桥梁映射。此外,现有标签数据集在对象对和关系标签上的偏差,以及它们所包含的噪声和缺失注释,都增加了开发可靠的场景图预测模型的难度。为此,KB-GAN(知识库和辅助图像生成)提出了一种基于外部知识和图像重建损失的SGG算法来克服数据集中发现的问题。更具体地说,KB-GAN使用ConceptNet的英语子图作为知识图;KB-GAN的基于知识的模块通过对从ConceptNet检索的常识知识篮进行推理来改进特征细化过程。同样,有许多相关的著作使用知识图作为先验知识来辅助关系预测。
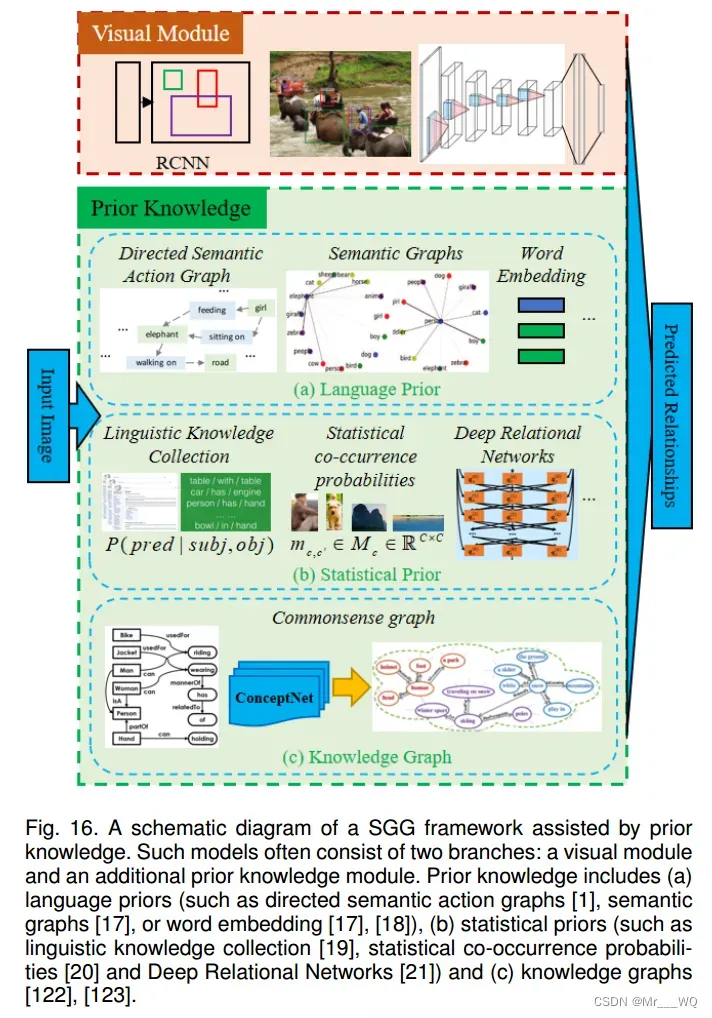
图16给出了不同类型先验知识的SGG模型的管道。先验知识已被证明可以显著提高SGG的质量。现有的方法要么使用外部管理知识库,如ConceptNet,要么使用注释语料库中的统计信息来获得常识性数据。然而,前者受限于不完整的外部知识,而后者往往基于硬编码的启发式算法,如给定类别的同现概率。因此,最新的研究首次尝试将视觉常识作为机器学习任务,直接从数据集中自动获取视觉常识数据,提高场景理解的鲁棒性。虽然这一探索非常有价值,但如何获取和充分利用这些先验知识仍然是一个值得进一步关注的难题。
4 LONG-TAILED DISTRIBUTION ON SGG(有兴趣自行了解)
采用Action Genome数据集有效抑制了长尾分布问题,作为研究方向的首选数据集。
5 DATASETS AND PERFORMANCE EVALUATION
5.1 Datasets
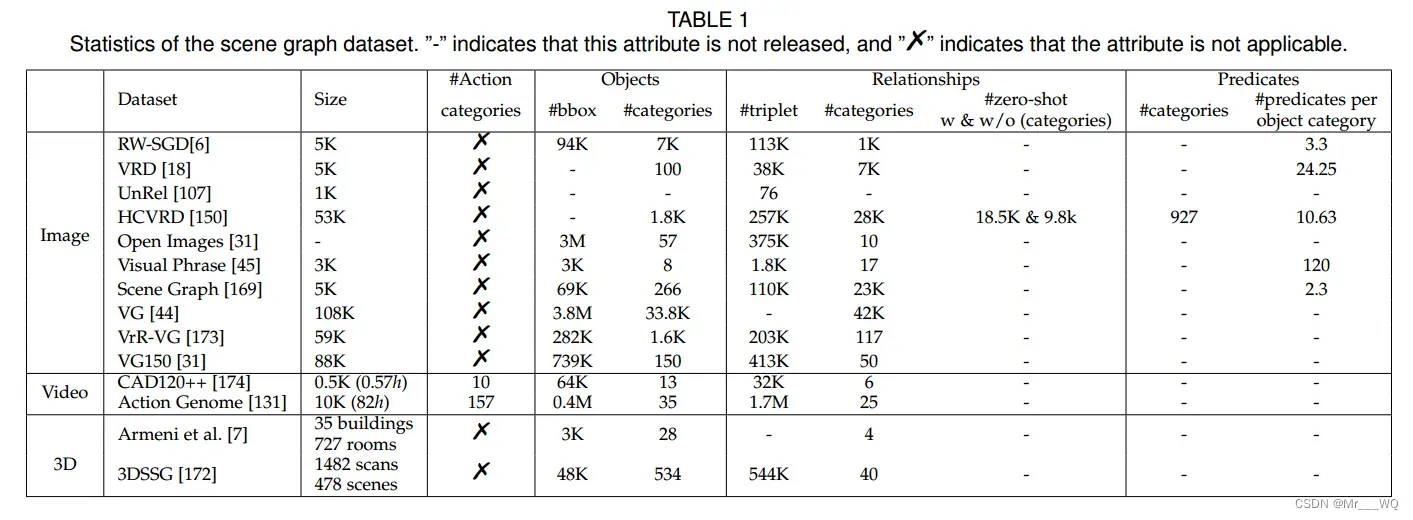
在本节中,我们对SGG任务中常用的数据集进行了详细的总结,以便感兴趣的读者可以据此做出选择。我们总共调查了14个常用的数据集,包括10个静态图像场景图数据集,2个视频场景图数据集和2个3D场景图数据集。
- RW-SGD:是通过从YFCC100m和Microsoft COCO数据集中手动选择5000张图像来构建的,然后使用AMT (Amazon的Mechanical Turk)从这些选定的图像中生成人工生成的场景图。
- 视觉关系数据集(VRD):是为视觉关系预测任务而构建的。VRD的构建突出了不频繁关系的长尾。
- UnRel数据集(UnRel- d):是一个新的具有挑战性的不寻常关系数据集,包含1000多张图像,可以通过76个三元组查询查询。UnRel-D中相对较少的数据和可视化关系使得该数据集中关系的长尾分布不明显。
- HCVRD数据集:包含52,855张图像,1,824个对象类别和927个谓词,以及28,323个关系类型。与VRD类似,HCVRD也具有不频繁关系的长尾分布。
- Open Images:是一个大规模的数据集,它为对象检测和关系检测提供了大量的例子。
- Visual Phrase:是一个包含视觉关系的数据集,主要用于改进对象检测。它包含13种常见的关系类型。
- Scene Graph:是一个包含视觉关系的数据集,旨在改进图像检索任务。尽管它包含23,190个关系类型,但每个对象类别只有2.3个谓词。
- Visual Genome(VG) , VG150和VrR-VG(Visually-Relevant Relationships Dataset)。VG是一个由各种组件组成的大规模可视化数据集,包括对象、属性、关系、问答对等等。VG150和VrR-VG是基于VGD构建的两个数据集。VG150使用VGD来消除注释质量差、边界框重叠和/或对象名称不明确的对象,并保留150个常用的对象类别。VrR-VG是基于VGD构造的,过滤掉视觉上不相关的关系。通过对关系的词向量应用层次聚类算法,从VG中筛选出前1600个对象和500个关系。因此,VrR-VG是一个用于突出视觉相关关系的场景图数据集;在这个数据集中,关系的长尾分布在很大程度上被抑制了。
- CAD120++和Action Genome是两个包含人类日常生活场景的视频动作推理数据集。它们可用于与时空场景图相关的任务分析。
- Armeni和3DSSG是两个大尺度三维语义场景图,包含室内建筑或真实场景的三维重建。它们被广泛用于与3D场景理解相关的研究领域(机器人导航、增强和虚拟现实等)。
这些数据集的信息汇总在表1中。这包括SGG任务中常用的数据集的各种属性。
6.2 Evaluation method and performance comparison
视觉关系检测是SGG的核心。常用的视觉关系检测评价方法有:
- 谓词检测(Predicate Det.)(图19(a))。它需要在给定一组本地化对象和对象标签的对象对之间预测可能的谓词。目标是研究关系预测性能而不受对象检测的限制[184]。
- 短语检测((Phrase Det.)(图19(c))。它需要为给定的图像预测一个
三元组,并为与ground truth box重叠至少0.5IoU的整个关系定位一个边界框。
- 关系检测(Relationship Det.)(图19(d))。它需要输出给定图像的一组三元组,同时对图像中的对象进行本地化。
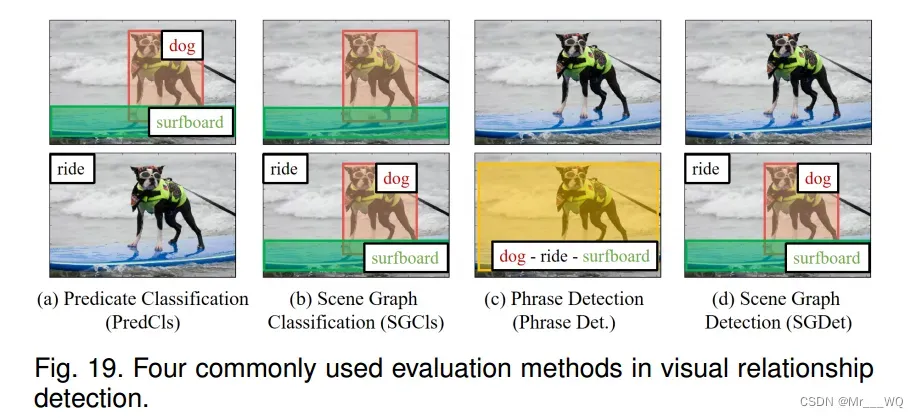
另一方面,上述三种视觉关系检测评价方法都没有考虑真实场景中常见的长尾分布现象和图级相干性。因此进一步完善了SGG的评价方法,即SGG诊断。SGG诊断基于以下三个关键指标:
- 关系检索(RR)。这可以进一步划分为三个子任务。
- 谓词分类(Predicate Classification, PredCls):与谓语检测相同。
- 场景图分类(Scene Graph Classification, SGCls) (Fig.19(b)):其输入为无标签真包围框。
- 场景图检测(SGDet):从头开始检测场景图。这和Relationship Det一样。
- 零镜头关系检索(ZSRR)。ZSRR需要测试的视觉关系在训练集中从未被观察到。与RR类似,ZSRR有三个相同的子任务。
- 句子到图检索(S2GR)。RR和ZSRR都在三元组水平上进行评估。S2RR的目的是在图的层面上评估场景图。它使用图像标题句作为查询来检索由场景图表示的图像。
Recall@K (R@K)通常被用作上述任务的评估指标。此外,由于R@K中存在报告偏差,R@K很容易受到高频谓词的干扰。因此,提出了mean Recall@K (mR@K)。mR@K分别检索每个谓词,然后为所有谓词取R@K的平均值。图形约束也是一个需要考虑的因素。以前的一些工作在计算R@K时仅约束给定对象对的一个关系,而其他工作省略了这个约束,并允许获得多个关系。
目前,现有的SGG方法大多使用RR中带有图约束的三个子任务进行性能评估。参考第2节和第3节中概述的分类,表2总结了相关SGG方法的性能。目前的方法大多采用基于图和RNN/LSTM的SGG方法。与R@K相比,mR@K的价格普遍较低。对于长尾分布明显的数据集,mR@K是一个更公平的评估指标。特别是VTransE、FactorizableNet、IMP、IMP+、Pixels2Graphs、FCSGG、VRF等方法只使用了视觉特征,这些方法的性能普遍较低。相比之下,VCTree、KERN、GPS-Net、GB-NET除了使用视觉特征外,还使用了其他知识(如语言嵌入、统计信息、反事实因果关系等)。这允许这些方法获得更多额外的知识,从而获得更多的性能提升。
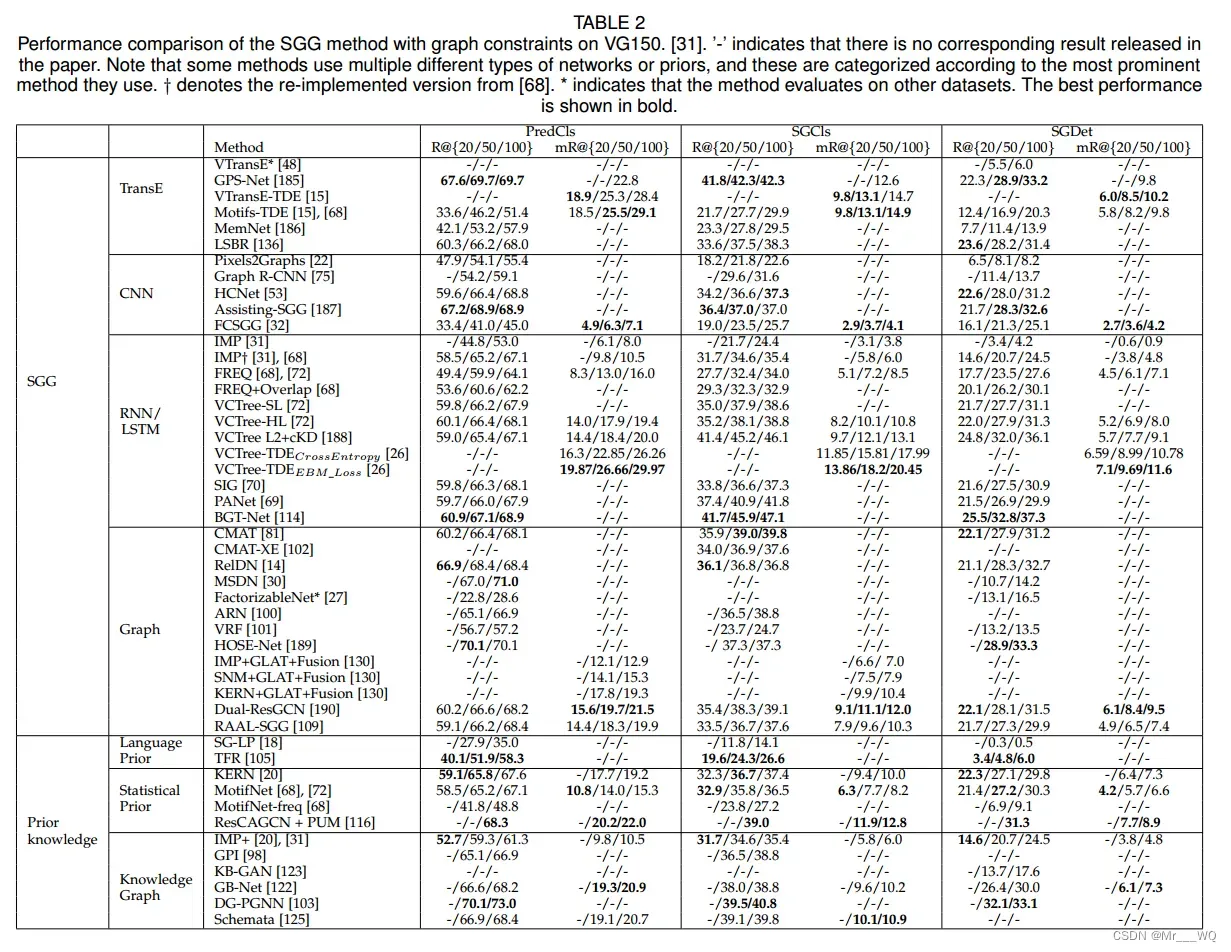 此外,目前几乎所有的方法都提出对象和关系的预测是相互关联的,而不是相互独立的。他们尝试考虑对象之间的上下文信息,或使用GNN,LSTM,消息传递等方法来捕获这种关系。然而,这些方法通常使用交叉熵损失训练,如等式18所示,它本质上是将对象和关系视为独立的实体。在EBM中提出了一种新的基于能量的损失函数。这个精心设计的损失计算对象和关系的联合可能性。与传统的交叉熵损失相比,它在mR@K多个经典模型上取得了一致的改善。同时,EBM是目前研究的算法中性能最好的。此外,ZSRR也是一个重要的任务,但目前大多数方法都无法对ZSRR任务进行评估,关注ZSRR任务的评价,有助于研究场景图的长尾分布。
此外,目前几乎所有的方法都提出对象和关系的预测是相互关联的,而不是相互独立的。他们尝试考虑对象之间的上下文信息,或使用GNN,LSTM,消息传递等方法来捕获这种关系。然而,这些方法通常使用交叉熵损失训练,如等式18所示,它本质上是将对象和关系视为独立的实体。在EBM中提出了一种新的基于能量的损失函数。这个精心设计的损失计算对象和关系的联合可能性。与传统的交叉熵损失相比,它在mR@K多个经典模型上取得了一致的改善。同时,EBM是目前研究的算法中性能最好的。此外,ZSRR也是一个重要的任务,但目前大多数方法都无法对ZSRR任务进行评估,关注ZSRR任务的评价,有助于研究场景图的长尾分布。
7 FUTURE RESEARCH
SGG旨在挖掘图像或场景中物体之间的关系,形成关系图。虽然目前SGG有很多相关研究,但仍有很多值得关注的方向。
- 视觉关系中的长尾分布。视觉关系的不竭性和真实场景的复杂性决定了视觉关系长尾分布的必然性。模型训练所需的数据平衡和真实数据的长尾分布呈现出一对不可避免的矛盾。通过相似对象或跨场景的相似关系进行联想推理可能是一个合适的研究方向,因为它可能在一定程度上有助于解决当前场景图数据集上关系的长尾分布问题。此外,有针对性的长尾分布评估指标或任务设计也是一个潜在的研究方向,因为它可以帮助更公平地评估模型在零/一次/少次背景下的学习能力;然而,相关研究还非常有限。尽管长尾问题已经得到了研究人员的广泛关注(第4节),但场景中仍有大量潜在的、不频繁的、不集中的、甚至看不见的关系有待探索。
- 远距离物体之间的关系检测。目前,场景图的生成是基于大量的小尺度关系图,这些关系图是通过相关的关系预测和推理模型从场景图数据集中的小场景中抽象出来的。场景图中潜在有效关系[60],[61]的选择和最终关系的建立很大程度上依赖于物体之间的空间距离,使得两个距离较远的物体之间不存在任何关系。但在较大的场景中,这样的关系仍然较多。因此,可以在现有的场景图数据集中适当比例地加入大尺度图像,同时在SGG过程中适当考虑相隔较远的物体之间的关系,提高场景图的完整性。
- 基于动态图像的SGG。基于场景图数据集中的静态图像生成场景图,并通过相关推理模型对图像中的静态对象进行对象关系预测。相关的研究工作很少,很少有人关注对象的动态行为在关系的预测和推断中所起的作用。然而,在实践中,通过连续的动作或事件来预测大量的关系可能是必要的;即基于视频场景的关系检测和推理。这是因为,与静态图像相比,动态图像的时空场景图分析显然提供了更广泛的应用场景。因此,我们认为有必要将重点放在基于视频中对象动态动作的关系预测上。
- 视觉推理的模型和方法。对于SGG,目前主流的方法是基于目标检测与识别。然而,由于现有场景图数据集的局限性,以及利用这些数据集导出的关系预测模型的能力有限,现有模型很难不断增强其关系预测能力。因此,我们认为在线学习、强化学习和主动学习可能是相关的方法或策略,可以引入到未来的SGG方法中,因为这将使SGG模型能够通过利用大量不断更新的现实数据集不断增强其关系预测能力。
总体而言,场景图领域的研究发展迅速,具有广阔的应用前景。场景图有望进一步促进对更高层次视觉场景的理解和推理。然而,目前与场景图相关的研究还不够成熟,还需要更多的努力和探索。
以上可能会有表述不准确的地方敬请谅解,此处仅用作后续学习记录。
文章出处登录后可见!